Ab Initio tiene muchas transformaciones clásicas e inusuales que se pueden extender con su propia PDL. Para una pequeña empresa, es probable que una herramienta tan poderosa sea redundante, y la mayoría de sus capacidades pueden ser costosas e innecesarias. Pero si su escala está cerca de la de Sberbank, entonces Ab Initio puede ser interesante para usted.
Ayuda a la empresa a acumular conocimiento a nivel mundial y a desarrollar el ecosistema, y al desarrollador, a desarrollar sus habilidades en ETL, a obtener conocimiento en el shell, brinda la oportunidad de dominar el lenguaje PDL, brinda una imagen visual de los procesos de carga, simplifica el desarrollo debido a la abundancia de componentes funcionales.
En esta publicación hablaré sobre las capacidades de Ab Initio y daré características comparativas de su trabajo con Hive y GreenPlum.
- MDW GreenPlum
- Ab Initio Hive GreenPlum
- Ab Initio GreenPlum Near Real Time
La funcionalidad de este producto es muy amplia y requiere mucho tiempo para aprender. Sin embargo, con las habilidades y la configuración de rendimiento adecuadas, los resultados del procesamiento de datos son bastante impresionantes. Usar Ab Initio para un desarrollador puede darle una experiencia interesante. Esta es una nueva versión del desarrollo ETL, un híbrido entre un entorno visual y el desarrollo de descargas en un lenguaje similar a un script.
Las empresas desarrollan sus ecosistemas y esta herramienta es más útil que nunca. Con la ayuda de Ab Initio, puede acumular conocimiento sobre su negocio actual y utilizarlo para expandir negocios antiguos y nuevos. Se pueden llamar alternativas a Ab Initio desde los entornos de desarrollo visual Informatica BDM y desde entornos no visuales: Apache Spark.
Descripción de Ab Initio
Ab Initio, como otras herramientas ETL, es un conjunto de productos.

Ab Initio GDE (Graphical Development Environment) es un entorno para un desarrollador en el que configura transformaciones de datos y los conecta con flujos de datos en forma de flechas. En este caso, este conjunto de transformaciones se denomina gráfico:

las conexiones de entrada y salida de componentes funcionales son puertos y contienen campos calculados dentro de las transformaciones. Varios gráficos conectados por secuencias en forma de flechas en el orden de su ejecución se denominan plan.
Hay varios cientos de componentes funcionales, que es mucho. Muchos de ellos son altamente especializados. Ab Initio tiene una gama más amplia de transformaciones clásicas que otras herramientas ETL. Por ejemplo, Join tiene múltiples salidas. Además del resultado de la conexión de conjuntos de datos, puede obtener los registros de salida de los conjuntos de datos de entrada, mediante las teclas de las cuales no fue posible conectarse. También puede obtener rechazos, errores y un registro de la operación de transformación, que puede leerse en la misma columna que un archivo de texto y procesarse por otras transformaciones:

o, por ejemplo, puede materializar el receptor de datos en forma de una tabla y leer datos de él en la misma columna.
Hay transformaciones originales. Por ejemplo, la transformación Escanear tiene la misma funcionalidad que las funciones analíticas. Hay transformaciones con nombres que se explican por sí mismos: Crear datos, Leer Excel, Normalizar, Ordenar dentro de Grupos, Ejecutar programa, Ejecutar SQL, Unirse con DB, etc. Los gráficos pueden usar parámetros de tiempo de ejecución, incluida la transferencia de parámetros desde el sistema operativo o el sistema operativo ... Los archivos con un conjunto de parámetros ya preparados que se pasan al gráfico se denominan conjuntos de parámetros (conjuntos).
Como se esperaba, Ab Initio GDE tiene su propio repositorio llamado EME (Enterprise Meta Environment). Los desarrolladores tienen la capacidad de trabajar con versiones locales del código y registrar sus desarrollos en el repositorio central.
Es posible, durante la ejecución o después de la ejecución del gráfico, hacer clic en cualquier flujo que conecte las transformaciones y mirar los datos que pasaron entre estas transformaciones:

también es posible hacer clic en cualquier flujo y ver los detalles de seguimiento: en cuántos paralelos funcionó la transformación, cuántas líneas y bytes en cuál de se cargan paralelos:

es posible dividir la ejecución del gráfico en fases y marcar que algunas transformaciones deben realizarse primero (en la fase cero), luego en la primera fase, siguiendo en la segunda fase, etc.
Para cada transformación, puede elegir el llamado diseño (donde se ejecutará): sin paralelos o en subprocesos paralelos, cuyo número se puede establecer. Al mismo tiempo, los archivos temporales creados por Ab Initio durante el trabajo de las transformaciones se pueden colocar tanto en el sistema de archivos del servidor como en HDFS.
En cada transformación, basada en la plantilla predeterminada, puede crear su propio script en el lenguaje PDL, que es un poco como un shell.
Con la ayuda del lenguaje PDL, puede ampliar la funcionalidad de las transformaciones y, en particular, puede generar dinámicamente (en tiempo de ejecución) fragmentos de código arbitrarios dependiendo de los parámetros de tiempo de ejecución.
Además, Ab Initio tiene una integración bien desarrollada con el sistema operativo a través del shell. Específicamente, Sberbank usa linux ksh. Puede intercambiar variables con shell y usarlas como parámetros gráficos. Puede llamar a la ejecución de gráficos Ab Initio desde el shell y administrar Ab Initio.
Además de Ab Initio GDE, la entrega incluye muchos otros productos. Hay un Sistema de Co> Operación con un reclamo para ser llamado un sistema operativo. Hay Control> Centro donde puede programar y monitorear transmisiones de descargas. Hay productos para desarrollar a un nivel más primitivo que Ab Initio GDE.
Descripción del marco MDW y trabajo en su personalización para GreenPlum
Junto con sus productos, el proveedor suministra el producto MDW (Metadata Driven Warehouse), que es un configurador gráfico diseñado para ayudar con las tareas típicas de llenar depósitos de datos o bóvedas de datos.
Contiene analizadores de metadatos personalizados (específicos del proyecto) y generadores de código listos para usar.
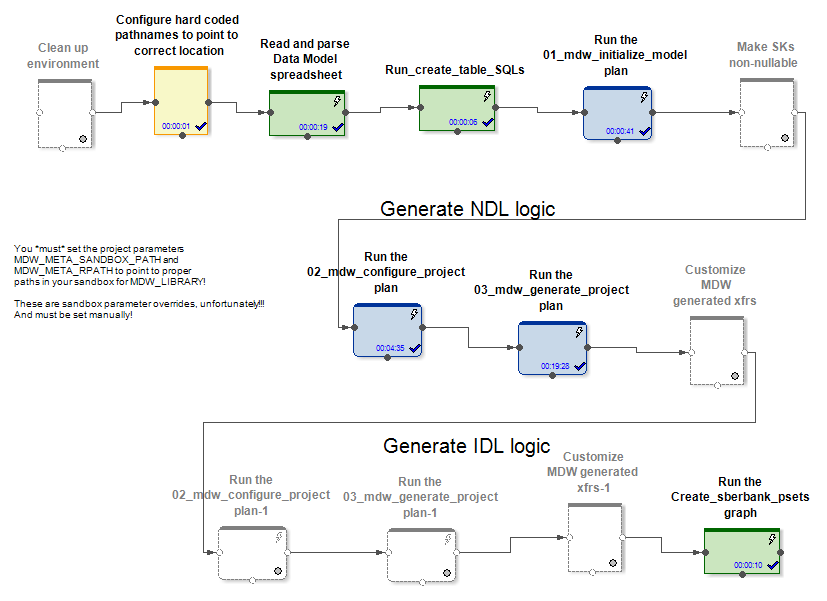
En la entrada, MDW recibe un modelo de datos, un archivo de configuración para configurar una conexión de base de datos (Oracle, Teradata o Hive) y algunas otras configuraciones. La parte específica del proyecto, por ejemplo, implementa el modelo en la base de datos. La parte en caja del producto genera gráficos y archivos de configuración para ellos al cargar datos en las tablas del modelo. Esto crea gráficos (y conjuntos) para varios modos de inicialización y trabajo incremental en la actualización de entidades.
En los casos Hive y RDBMS, se generan diferentes gráficos de actualización de datos incrementales y de inicialización.
En el caso de Hive, los datos delta entrantes se unen por Ab Initio Join a los datos que estaban en la tabla antes de la actualización. Los cargadores de datos en MDW (tanto en Hive como en RDBMS) no solo insertan datos nuevos del delta, sino que también cierran los períodos de validez de los datos para los cuales las claves primarias recibieron el delta. Además, debe reescribir la parte no modificada de los datos. Pero esto debe hacerse, ya que Hive no tiene operaciones de eliminación o actualización.
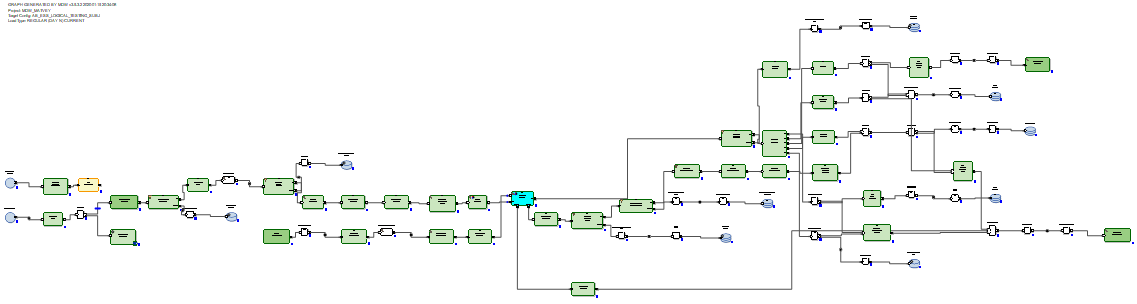
En el caso de RDBMS, los gráficos de actualización de datos incrementales se ven más óptimos porque los RDBMS tienen capacidades de actualización reales.
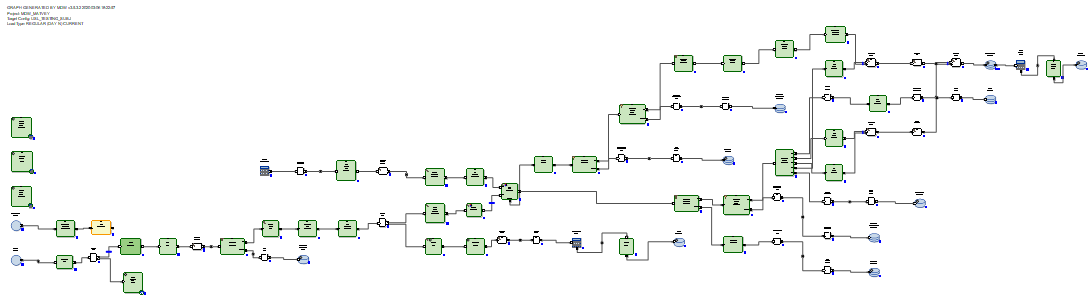
El delta recibido se carga en una tabla de etapas en la base de datos. Después de eso, el delta se conecta a los datos que estaban en la tabla antes de la actualización. Y esto se realiza mediante SQL a través de la consulta SQL generada. Luego, utilizando los comandos SQL borrar + insertar, se insertan nuevos datos del delta en la tabla de destino y se cierran los períodos de relevancia de los datos, de acuerdo con las claves principales de las cuales se recibió el delta.
No hay necesidad de reescribir datos sin cambios.
Por lo tanto, llegamos a la conclusión de que en el caso de Hive, MDW debería ir a reescribir toda la tabla, porque Hive no tiene una función de actualización. Y nada mejor que una reescritura completa de los datos cuando no se inventa la actualización. En el caso de RDBMS, por el contrario, los creadores del producto consideraron necesario confiar la conexión y actualización de tablas usando SQL.
Para un proyecto en Sberbank, creamos una nueva implementación reutilizable del cargador de bases de datos GreenPlum. Esto se realizó en función de la versión que MDW genera para Teradata. Fue Teradata, no Oracle, quien surgió mejor y más cercano para esto. También es un sistema MPP. La forma de trabajar, así como la sintaxis de Teradata y GreenPlum, resultó ser similar.
Ejemplos de diferencias críticas para MDW entre diferentes RDBMS son los siguientes. En GreenPlum, a diferencia de Teradata, al crear tablas, debe escribir una cláusula
distributed byTeradata escribe
delete <table> all, y en GreenePlum escriben
delete from <table>Oracle escribe para fines de optimización
delete from t where rowid in (< t >), y Teradata y GreenPlum escriben
delete from t where exists (select * from delta where delta.pk=t.pk)También notamos que para que Ab Initio funcione con GreenPlum, fue necesario instalar el cliente GreenPlum en todos los nodos del clúster Ab Initio. Esto se debe a que nos hemos conectado a GreenPlum simultáneamente desde todos los nodos de nuestro clúster. Y para que la lectura de GreenPlum sea paralela y cada hilo paralelo de Ab Initio lea su propia porción de datos de GreenPlum, fue necesario poner una construcción entendida por Ab Initio en la sección "dónde" de las consultas SQL
where ABLOCAL()y determinar el valor de esta construcción especificando la lectura de parámetros de la base de datos de transformación
ablocal_expr=«string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))»que compila algo como
mod(sk,10)=3es decir tienes que decirle a GreenPlum un filtro explícito para cada partición. Para otras bases de datos (Teradata, Oracle), Ab Initio puede hacer esta paralelización automáticamente.
Características comparativas de rendimiento de Ab Initio para trabajar con Hive y GreenPlum
Se realizó un experimento en Sberbank para comparar el rendimiento de los gráficos generados por MDW en relación con Hive y en relación con GreenPlum. Como parte del experimento, en el caso de Hive, había 5 nodos en el mismo grupo que Ab Initio, y en el caso de GreenPlum, había 4 nodos en un grupo separado. Aquellos. Hive tenía alguna ventaja de hardware sobre GreenPlum.
Observamos dos pares de gráficos que realizan la misma tarea de actualizar datos en Hive y GreenPlum. Se lanzaron los gráficos generados por el configurador MDW:
- carga de inicialización + carga incremental de datos generados aleatoriamente en la tabla Hive
- carga de inicialización + carga incremental de datos generados aleatoriamente en la misma tabla de GreenPlum
En ambos casos (Hive y GreenPlum) se lanzaron descargas en 10 subprocesos paralelos en el mismo clúster Ab Initio. Ab Initio guardó datos intermedios para cálculos en HDFS (en términos de Ab Initio, se utilizó el diseño MFS usando HDFS). Una línea de datos generados aleatoriamente ocupaba 200 bytes en ambos casos.
El resultado es así:
Colmena:
| Inicializando carga en Hive | |||
| Filas insertadas | 6,000,000 | 60,000,000 | 600,000,000 |
| Duración de la
carga de inicialización en segundos |
41 | 203 | 1 601 |
| Carga incremental en colmena | |||
| El número de filas en la
tabla de destino al comienzo del experimento. |
6,000,000 | 60,000,000 | 600,000,000 |
| Número de filas delta aplicadas a la
tabla de destino durante el experimento |
6,000,000 | 6,000,000 | 6,000,000 |
| Duración de
descarga incremental en segundos |
88 | 299 | 2541 |
GreenPlum:
| GreenPlum | |||
| 6 000 000 | 60 000 000 | 600 000 000 | |
|
|
72 | 360 | 3 631 |
| GreenPlum | |||
| ,
|
6 000 000 | 60 000 000 | 600 000 000 |
| ,
|
6 000 000 | 6 000 000 | 6 000 000 |
|
|
159 | 199 | 321 |
Vemos que la velocidad de inicialización de la descarga en Hive y GreenPlum depende linealmente de la cantidad de datos y, por razones de mejor hardware, es algo más rápido para Hive que para GreenPlum.
La carga incremental en Hive también depende linealmente de la cantidad de datos cargados previamente en la tabla de destino y es bastante lenta al aumentar el volumen. Esto se debe a la necesidad de sobrescribir completamente la tabla de destino. Esto significa que aplicar pequeños cambios a tablas enormes no es un buen caso de uso para Hive.
La carga incremental en GreenPlum depende débilmente de la cantidad de datos cargados previamente disponibles en la tabla de destino y es bastante rápida. Esto sucedió gracias a SQL Joins y la arquitectura GreenPlum, que permite la operación de eliminación.
Entonces, GreenPlum inyecta delta usando el método eliminar + insertar, mientras que Hive no tiene operaciones de eliminación o actualización, por lo que toda la matriz de datos se vio obligada a reescribir toda la matriz de datos durante una actualización incremental. Lo más indicativo es la comparación de las celdas resaltadas en negrita, ya que corresponde a la variante más frecuente de la operación de descargas intensivas en recursos. Vemos que GreenPlum ganó 8 veces sobre Hive en esta prueba.
Ab Initio con GreenPlum en tiempo casi real
En este experimento, probaremos la capacidad de Ab Initio para actualizar la tabla GreenPlum con fragmentos de datos generados aleatoriamente en tiempo casi real. Considere la tabla GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval, con la que trabajaremos.
Utilizaremos tres gráficos Ab Initio para trabajar con él:
1) Gráfico Create_test_data.mp: crea archivos con datos en HDFS para 6,000,000 de líneas en 10 flujos paralelos. Los datos son aleatorios, su estructura está organizada para su inserción en nuestra tabla
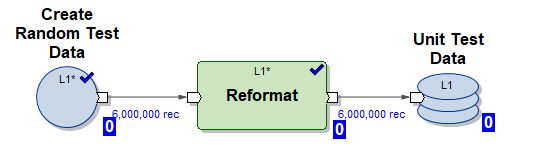

2) Gráfico mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset: gráfico MDW generado para inicializar la inserción de datos en nuestra tabla en 10 hilos paralelos (utilizando datos de prueba generados por el gráfico (1))

3) Gráfico mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset: gráfico MDW generado para la actualización incremental de nuestra tabla en 10 subprocesos paralelos utilizando una porción de datos entrantes nuevos (delta) generados por el gráfico (1)

Ejecute el siguiente script en modo NRT:
- generar 6,000,000 líneas de prueba
- hacer la carga de inicialización inserte 6,000,000 líneas de prueba en una tabla vacía
- repita la descarga incremental 5 veces
- generar 6,000,000 líneas de prueba
- realice una inserción incremental de 6,000,000 filas de prueba en la tabla (en este caso, los datos antiguos se sellan con el tiempo de vencimiento valid_to_ts y se insertan datos más recientes con la misma clave primaria)
Tal escenario emula el modo de operación real de un determinado sistema empresarial: una porción bastante grande de datos nuevos aparece en tiempo real e inmediatamente se vierte en GreenPlum.
Ahora veamos el registro del script:
Comience Create_test_data.input.pset en 2020-06-04 11:49:11
Termine Create_test_data.input.pset en 2020-06-04 11:49:37
Comience mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset en 04/06/2020 11:49:37
mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset Acabado en 06/04/2020 11:50:42
Inicio Create_test_data.input.pset en 04/06/2020 11:50:42
Finalizar Create_test_data.input.pset en 2020-06-04 11:51:06
Inicie mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset en 2020-06-04 11:51:06
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:53:41
Start Create_test_data.input.pset at 2020-06-04 11:53:41
Finish Create_test_data.input.pset at 2020-06-04 11:54:04
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:54:04
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:56:51
Start Create_test_data.input.pset at 2020-06-04 11:56:51
Finish Create_test_data.input.pset at 2020-06-04 11:57:14
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:57:14
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:59:55
Inicie Create_test_data.input.pset en 2020-06-04 11:59:55 Finalice
Create_test_data.input.pset en 2020-06-04 12:00:23
Inicie mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset en 2020-06-04 12:00:23 Finalice
mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset en 2020-06-04 12:03:23
Inicie Create_test_data.input.pset en 2020-06-04 12:03:23
Finalice Create_test_data.input.pset en 2020-06-04 12:03:49
Inicie mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset en 2020-06-04 12:03:49
Finalice mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset en 2020-06-04 12:53 : 46 La
imagen se ve así:
| Grafico | Hora de inicio | Tiempo de finalización | Longitud |
|---|---|---|---|
| Create_test_data.input.pset | 06/04/2020 11:49:11 | 06/04/2020 11:49:37 | 00:00:26 |
| mdw_load.day_one.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:49:37 | 06/04/2020 11:50:42 | 00:01:05 |
| Create_test_data.input.pset | 06/04/2020 11:50:42 | 06/04/2020 11:51:06 | 00:00:24 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:51:06 | 06/04/2020 11:53:41 | 00:02:35 |
| Create_test_data.input.pset | 06/04/2020 11:53:41 | 06/04/2020 11:54:04 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:54:04 | 06/04/2020 11:56:51 | 00:02:47 |
| Create_test_data.input.pset | 06/04/2020 11:56:51 | 06/04/2020 11:57:14 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:57:14 | 06/04/2020 11:59:55 | 00:02:41 |
| Create_test_data.input.pset | 06/04/2020 11:59:55 | 06/04/2020 12:00:23 | 00:00:28 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:00:23 | 06/04/2020 12:03:23 PM | 00:03:00 |
| Create_test_data.input.pset | 06/04/2020 12:03:23 PM | 06/04/2020 12:03:49 PM | 00:00:26 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:03:49 PM | 06/04/2020 12:06:46 PM | 00:02:57 |
Vemos que se procesan 6,000,000 de líneas de incremento en 3 minutos, lo cual es bastante rápido.
Los datos en la tabla de destino resultaron distribuirse de la siguiente manera:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2;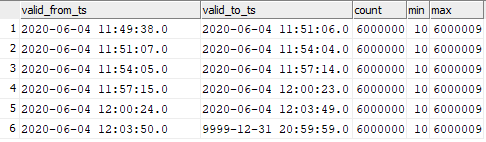
Puede ver la correspondencia de los datos insertados con los momentos del lanzamiento del gráfico.
Esto significa que puede comenzar la carga incremental de datos en GreenPlum en Ab Initio con una frecuencia muy alta y observar una alta velocidad de inserción de estos datos en GreenPlum. Por supuesto, no será posible comenzar una vez por segundo, ya que Ab Initio, como cualquier herramienta ETL, toma tiempo para "balancearse" al inicio.
Conclusión
Ahora Ab Initio se utiliza en Sberbank para construir la capa de datos semánticos unificados (ESS). Este proyecto implica la construcción de una versión única del estado de varias entidades comerciales bancarias. La información proviene de varias fuentes, cuyas réplicas se preparan en Hadoop. Según las necesidades de la empresa, se prepara un modelo de datos y se describen las transformaciones de datos. Ab Initio carga información en el ECC y los datos descargados no solo son de interés para el negocio en sí, sino que también sirven como fuente para construir los data marts. Al mismo tiempo, la funcionalidad del producto le permite utilizar varios sistemas (Hive, Greenplum, Teradata, Oracle) como receptor, lo que permite preparar sin esfuerzo los datos para las empresas en los diversos formatos que requiere.
Las capacidades de Ab Initio son amplias, por ejemplo, el marco MDW incluido hace posible construir datos históricos técnicos y comerciales de forma inmediata. Para los desarrolladores, Ab Initio brinda la oportunidad de "no reinventar la rueda", sino de utilizar muchos de los componentes funcionales disponibles, que son, de hecho, bibliotecas necesarias cuando se trabaja con datos.
El autor es experto de la comunidad profesional Sberbank SberProfi DWH / BigData. La comunidad profesional SberProfi DWH / BigData es responsable del desarrollo de competencias en áreas tales como el ecosistema Hadoop, Teradata, Oracle DB, GreenPlum, así como las herramientas de BI Qlik, SAP BO, Tableau, etc.