
Aquí encontrará una lista de materiales publicados en junio en inglés. Todos ellos están escritos sin excesivo academismo, contienen ejemplos de código y enlaces a repositorios no vacíos. La mayoría de las tecnologías mencionadas son de dominio público y no requieren hardware pesado para las pruebas.
Imagen GPT
Open AI decidió que, dado que un modelo de transformador entrenado en texto puede generar oraciones completas coherentes, si el modelo está entrenado en secuencias de píxeles, puede generar imágenes aumentadas. La IA abierta demuestra cómo el muestreo de alta calidad y la clasificación precisa de las imágenes permiten que el modelo generado compita con los mejores modelos convolucionales en entornos de aprendizaje no supervisados.

Face depixelizer
Hace un mes tuvimos la oportunidad de jugar con la herramienta, que utiliza un modelo de aprendizaje automático para transformar los retratos en hermosos píxeles. Es divertido, pero aún es difícil imaginar el uso generalizado de esta tecnología. Pero la herramienta que produce el efecto contrario inmediatamente se interesó mucho en el público. Con la ayuda de un depixelizer facial, en teoría, será posible establecer la identidad de una persona mediante la grabación de video desde cámaras de vigilancia al aire libre.

Cara ProfundaDibujo
Si trabajar con imágenes de píxeles no es suficiente y necesita componer una fotografía con un retrato de una persona a partir de un boceto primitivo, entonces ya apareció una herramienta basada en DNN. Tal como lo concibieron los creadores, solo se necesitan esquemas generales, y no bocetos profesionales: el modelo restaurará la cara de la persona, que coincidirá con el boceto. El sistema fue creado utilizando el marco Jittor, como prometen los creadores, el código fuente de Pytorch pronto se agregará al repositorio del proyecto.
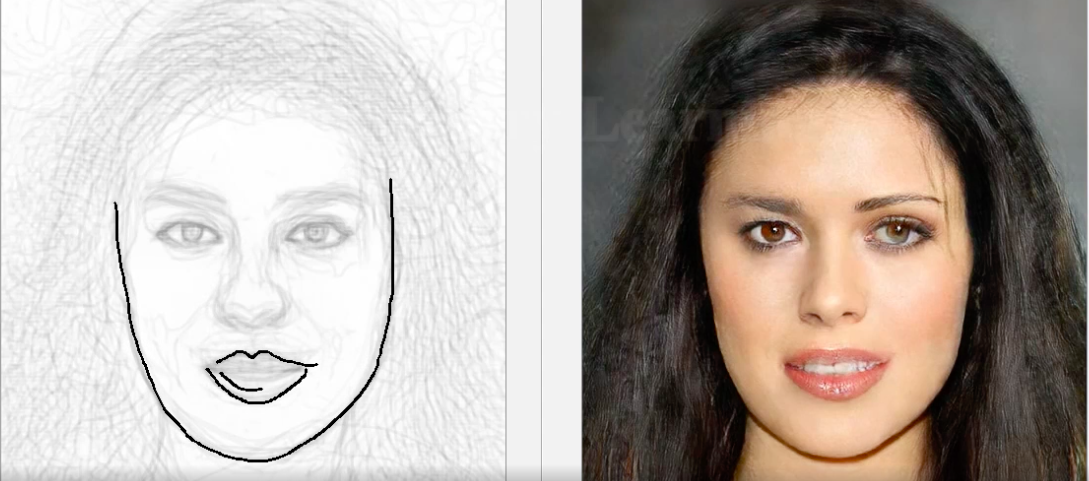
PIFuHD
Con las reconstrucciones faciales resueltas, ¿qué pasa con el resto del cuerpo? Gracias al desarrollo de DNN, fue posible modelar en 3D una figura humana basada en una foto bidimensional. La principal limitación se debió al hecho de que las predicciones precisas requieren el análisis de un contexto más amplio y la fuente de datos en alta resolución. La arquitectura en capas del modelo y las capacidades de aprendizaje de extremo a extremo ayudarán a resolver este problema. En el primer nivel, para ahorrar recursos, toda la imagen se analiza en baja resolución. Luego se forma el contexto y, en un nivel más detallado, el modelo evalúa la geometría analizando la imagen de alta resolución.

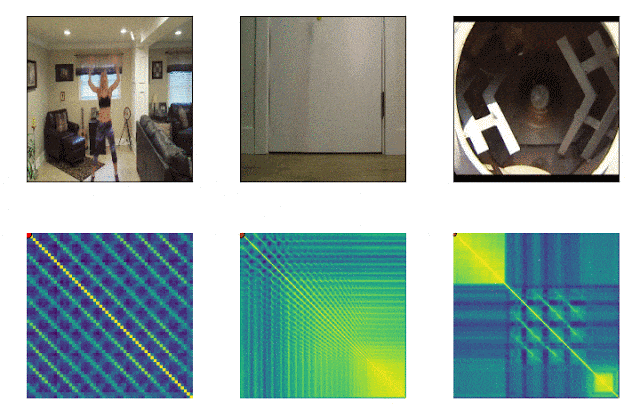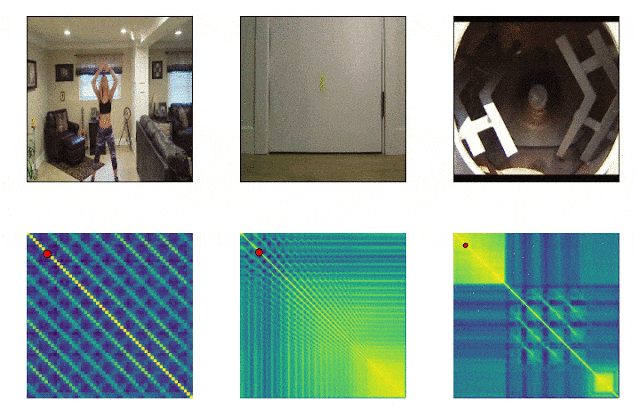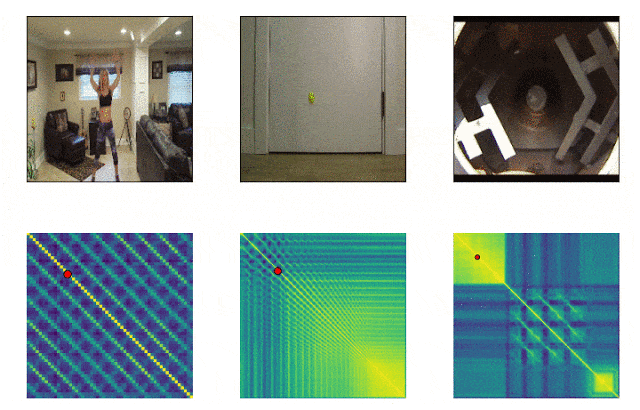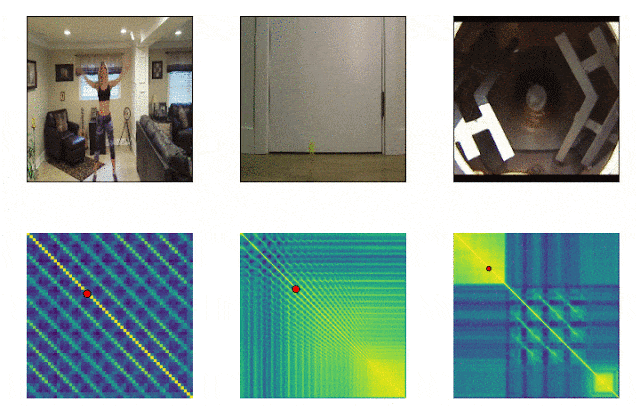
RepNet
Muchas cosas que nos rodean consisten en ciclos de diferente frecuencia. A menudo, para comprender la esencia de un fenómeno, es necesario analizar información sobre sus manifestaciones recurrentes. Teniendo en cuenta las posibilidades de grabación de video, ya no es difícil arreglar las repeticiones, el problema estaba en contarlas. El método de comparación cuadro por cuadro de la densidad de píxeles en el cuadro a menudo no era adecuado debido al movimiento de la cámara o la obstrucción de los objetos, así como a una gran diferencia en la escala y la forma al acercar y alejar. Un modelo desarrollado por Google ahora resuelve este problema. Identifica acciones repetitivas en el video, incluidas aquellas que no se usaron en el entrenamiento. Como resultado, el modelo devuelve datos sobre la frecuencia de acciones repetidas reconocidas en el video. Colab ya está disponible .
Modelo SPICE
Anteriormente, tenía que confiar en algoritmos sofisticados de procesamiento de señal para determinar el tono. El mayor desafío fue separar el sonido en estudio del ruido de fondo o el sonido de los instrumentos que lo acompañan. Un modelo pre-entrenado ahora está disponible para esta tarea que detecta frecuencias altas y bajas. El modelo está disponible para su uso en la web y dispositivos móviles.
Detector de distanciamiento social
El caso de crear un programa con el que puedas rastrear si las personas observan el distanciamiento social. El autor cuenta en detalle cómo eligió un modelo pre-entrenado, cómo hizo frente a la tarea de reconocer a las personas y cómo, usando OpenCV, transformó la imagen en una proyección ortográfica para calcular la distancia entre las personas. También puede familiarizarse con el código fuente del proyecto.

Reconocimiento de documentos tipicos
Hoy en día, existen miles de variaciones de los documentos de plantilla más comunes, como recibos, facturas y cheques. Sistemas automatizados existentes que están diseñados para funcionar con un tipo de plantilla muy limitado. Google sugiere usar el aprendizaje automático para esto. El artículo analiza la arquitectura del modelo y los resultados de los datos obtenidos. La herramienta pronto se convertirá en parte del servicio Document AI .
Cómo crear una tubería escalable para el desarrollo y la implementación de algoritmos de aprendizaje automático para el comercio minorista sin contacto
La startup israelí Trigo comparte su experiencia de usar el aprendizaje automático y la visión por computadora para el comercio minorista para llevar. La compañía es un proveedor de un sistema que permite a las tiendas operar sin una caja registradora. Los autores cuentan qué tareas enfrentaron y explican por qué eligieron PyTorch como marco para el aprendizaje automático, y Allegro AI Trains para infraestructura y cómo lograron establecer el proceso de desarrollo.
Eso es todo, ¡gracias por su atención!