En X5, el sistema que rastreará los productos etiquetados e intercambiará datos con el gobierno y los proveedores se llama "Markus". Digamos en orden cómo y quién lo desarrolló, qué tipo de tecnología tiene y por qué tenemos algo de qué estar orgullosos.
Real HighLoad
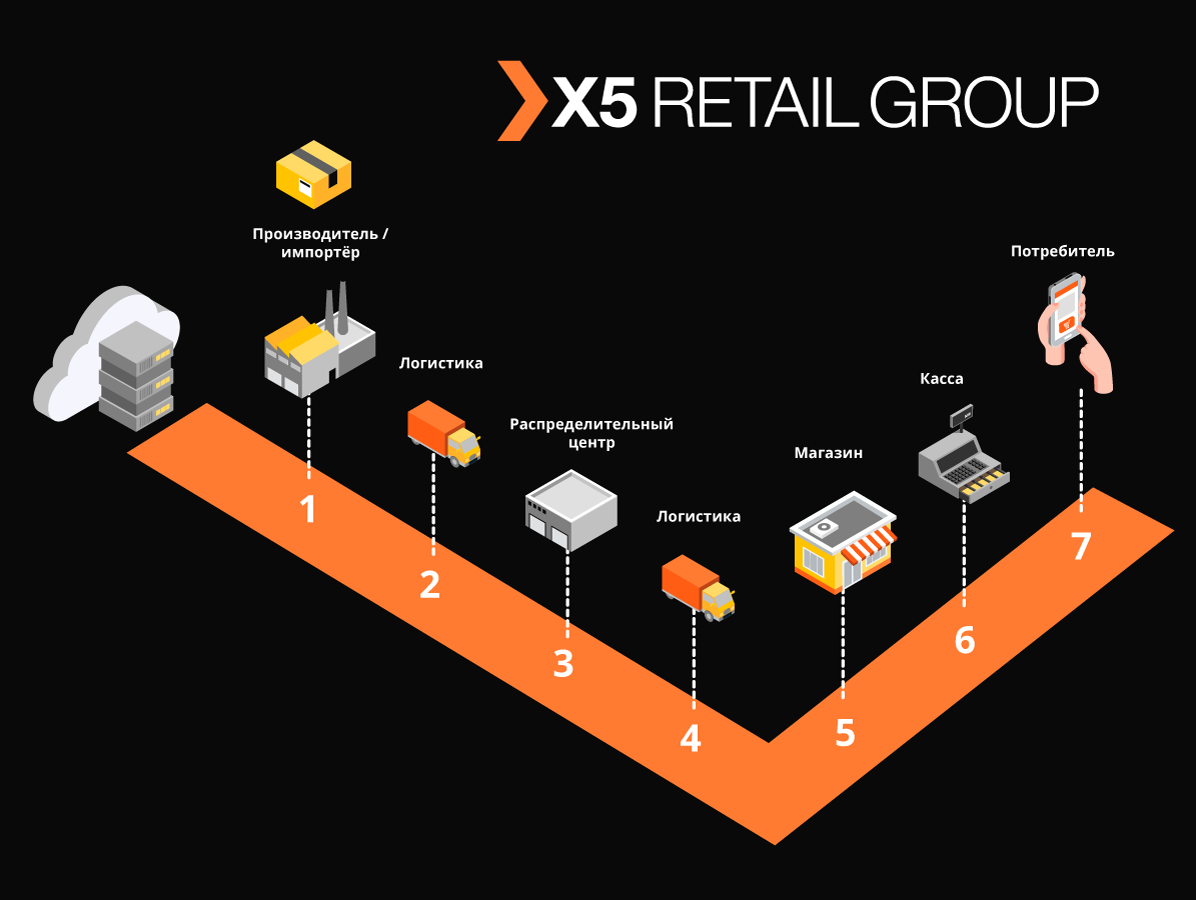
"Markus" resuelve muchos problemas, el principal de los cuales es la interacción de integración entre los sistemas de información X5 y el sistema de información estatal de productos etiquetados (GIS MP) para rastrear el movimiento de los productos etiquetados. La plataforma también almacena todos los códigos de marcado que recibimos y toda la historia del movimiento de estos códigos a través de los objetos, ayuda a eliminar la reordenación de los productos marcados. En el ejemplo de los productos de tabaco, que se incluyeron en los primeros grupos de productos etiquetados, solo un camión de cigarrillos contiene alrededor de 600,000 paquetes, cada uno de los cuales tiene su propio código único. Y la tarea de nuestro sistema es rastrear y verificar la legalidad de los movimientos de cada paquete entre almacenes y tiendas, y finalmente verificar la admisibilidad de su implementación para el cliente final. Y registramos transacciones en efectivo de aproximadamente 125,000 por hora,y también es necesario registrar cómo cada paquete llegó a la tienda. Por lo tanto, teniendo en cuenta todos los movimientos entre objetos, esperamos decenas de miles de millones de registros por año.
Equipo m
A pesar de que "Markus" se considera un proyecto dentro del X5, se está implementando de acuerdo con el enfoque del producto. El equipo trabaja en Scrum. El inicio del proyecto fue el verano pasado, pero los primeros resultados llegaron solo en octubre: su propio equipo estaba completamente ensamblado, se desarrolló la arquitectura del sistema y se compró el equipo. Ahora el equipo tiene 16 personas, seis de las cuales participan en el desarrollo de backend y frontend, tres en el análisis del sistema. Seis personas más están involucradas en pruebas manuales, de carga, automatizadas y soporte de productos. Además, tenemos un especialista en SRE.
El código de nuestro equipo está escrito no solo por los desarrolladores, sino que casi todos los muchachos saben cómo programar y escribir autotests, cargar scripts y scripts de automatización. Prestamos especial atención a esto, ya que incluso el soporte del producto requiere un alto nivel de automatización. Siempre tratamos de asesorar y ayudar a nuestros colegas que no han programado antes, a dar algunas tareas pequeñas para trabajar.
En relación con la pandemia de coronavirus, transferimos a todo el equipo al trabajo remoto, la disponibilidad de todas las herramientas de gestión de desarrollo, el flujo de trabajo integrado en Jira y GitLab facilitaron el paso por esta etapa. Los meses pasados en una ubicación remota mostraron que la productividad del equipo no sufrió esto, para muchos, la comodidad en el trabajo aumentó, lo único es que no hay suficiente comunicación en vivo.
Reunión del equipo antes de la distancia.

Reuniones remotas
Pila de tecnología de solución
El repositorio estándar y la herramienta CI / CD para X5 es GitLab. Lo usamos para almacenamiento de código, pruebas continuas, implementación para probar y servidores de producción. También utilizamos la práctica de revisión de código, cuando al menos 2 colegas necesitan aprobar los cambios realizados por el desarrollador en el código. Los analizadores de código estático SonarQube y JaCoCo nos ayudan a mantener el código limpio y proporcionan el nivel requerido de cobertura de prueba unitaria. Todos los cambios en el código deben pasar por estas verificaciones. Todos los scripts de prueba que se ejecutan manualmente se automatizan posteriormente.
Para la ejecución exitosa de los procesos de negocio por parte de "Markus" tuvimos que resolver una serie de problemas tecnológicos, cada uno en orden.
Tarea 1. La necesidad de escalabilidad horizontal del sistema
Para resolver este problema, hemos elegido un enfoque de microservicio para la arquitectura. Era muy importante comprender las áreas de responsabilidad de los servicios. Intentamos dividirlos en operaciones comerciales, teniendo en cuenta los detalles de los procesos. Por ejemplo, la aceptación en un almacén no es muy frecuente, pero es una operación muy voluminosa, durante la cual es necesario obtener del regulador estatal lo antes posible información sobre las unidades de mercancías recibidas, cuyo número en una entrega alcanza 600,000, verifique la admisibilidad de aceptar este producto en el almacén y entregue todo información necesaria para el sistema de automatización del almacén. Pero el envío desde almacenes tiene una intensidad mucho mayor, pero al mismo tiempo opera con pequeñas cantidades de datos.
Implementamos todos los servicios en el principio de apatridia e incluso intentamos dividir las operaciones internas en pasos, utilizando lo que llamamos temas personales de Kafka. Esto es cuando un microservicio se envía un mensaje a sí mismo, lo que permite equilibrar la carga para operaciones más intensivas en recursos y simplifica el mantenimiento del producto, pero más sobre eso más adelante.
Decidimos separar los módulos para la interacción con sistemas externos en servicios separados. Esto permitió resolver el problema del cambio frecuente de API de sistemas externos, prácticamente sin impacto en los servicios con funcionalidad empresarial.
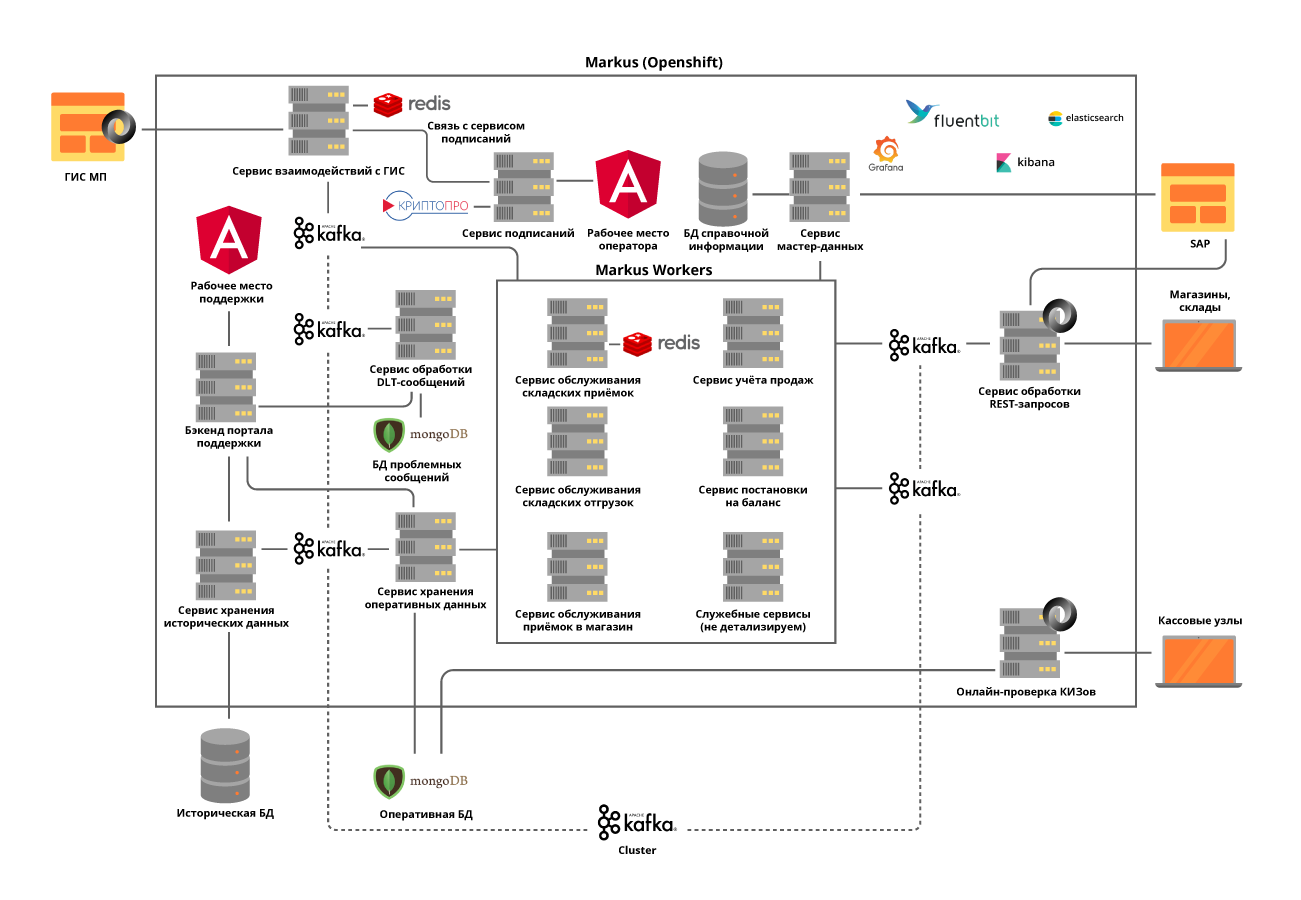
Todos los microservicios se implementan en el clúster OpenShift, lo que resuelve el problema de escalar cada microservicio y nos permite no usar herramientas de descubrimiento de servicios de terceros.
Tarea 2. La necesidad de mantener una carga elevada y un intercambio de datos muy intenso entre los servicios de la plataforma: solo en la fase de lanzamiento del proyecto, se realizan alrededor de 600 operaciones por segundo. Esperamos que este valor aumente hasta 5000 op / seg a medida que los objetos comerciales se conectan a nuestra plataforma.
Esta tarea se resolvió implementando un clúster de Kafka y abandonando casi por completo la comunicación sincrónica entre los microservicios de la plataforma. Esto requiere un análisis muy cuidadoso de los requisitos del sistema, ya que no todas las operaciones pueden ser asíncronas. Al mismo tiempo, no solo transmitimos eventos a través del intermediario, sino que también transmitimos toda la información comercial requerida en el mensaje. Por lo tanto, el tamaño del mensaje puede ser de varios cientos de kilobytes. La limitación en el volumen de mensajes en Kafka requiere que predijamos con precisión el tamaño de los mensajes y, si es necesario, los dividimos, pero la división es lógica, asociada con las operaciones comerciales.
Por ejemplo, los productos llegaron al automóvil, los dividimos en cajas. Para operaciones síncronas, se asignan microservicios separados y se realizan rigurosas pruebas de carga. Usar Kafka planteó otro desafío para nosotros: probar nuestro servicio con la integración de Kafka hace que todas nuestras pruebas unitarias sean asíncronas. Resolvimos este problema escribiendo nuestros propios métodos utilitarios utilizando el Broker Kafka incorporado. Esto no elimina la necesidad de escribir pruebas unitarias para métodos individuales, pero preferimos probar casos complejos usando Kafka.
Prestamos mucha atención al rastreo de los registros para que su TraceId no se pierda cuando ocurre una excepción durante la operación de los servicios o cuando se trabaja con el lote Kafka. Y si no hubo preguntas especiales con la primera, entonces en el segundo caso nos vemos obligados a registrar todo el TraceId con el que vino el lote y seleccionar uno para continuar el seguimiento. Luego, cuando busque el TraceId inicial, el usuario descubrirá fácilmente con qué rastreo continuó el rastreo.
Objetivo 3. La necesidad de almacenar una gran cantidad de datos: más de mil millones de etiquetas por año para el tabaco solo se envían a X5. Requieren acceso constante y rápido. En total, el sistema debe procesar unos 10 mil millones de registros sobre la historia del movimiento de estos productos marcados.
Para resolver el tercer problema, se eligió la base de datos MongoDB NoSQL. Hemos construido un fragmento de 5 nodos y en cada nodo un conjunto de réplica de 3 servidores. Esto le permite escalar el sistema horizontalmente, agregar nuevos servidores al clúster y garantizar su tolerancia a fallas. Aquí nos enfrentamos a otro problema: garantizar la transaccionalidad en el clúster mongo, teniendo en cuenta el uso de microservicios escalables horizontalmente. Por ejemplo, una de las tareas de nuestro sistema es detectar intentos de revender productos con los mismos códigos de marcado. Aquí las superposiciones aparecen con escaneos erróneos o con operaciones de cajero erróneas. Descubrimos que tales duplicados pueden ocurrir tanto dentro de un lote procesado en Kafka como dentro de dos lotes procesados en paralelo. Por lo tanto, la búsqueda de duplicados al consultar la base de datos no dio nada.Para cada uno de los microservicios, resolvimos el problema por separado en función de la lógica empresarial de este servicio. Por ejemplo, para los recibos, agregamos un cheque dentro del lote y un procesamiento separado para la aparición de duplicados cuando se insertan.
Para que el trabajo de los usuarios con el historial de operaciones no afecte lo más importante: el funcionamiento de nuestros procesos comerciales, separamos todos los datos históricos en un servicio separado con una base de datos separada, que también recibe información a través de Kafka. Por lo tanto, los usuarios trabajan con un servicio aislado sin afectar los servicios que procesan datos en las operaciones actuales.
Tarea 4. Reprocesamiento de colas y monitoreo:
En los sistemas distribuidos, inevitablemente surgen problemas y errores en la disponibilidad de bases de datos, colas y fuentes de datos externas. En el caso de Markus, la fuente de tales errores es la integración con sistemas externos. Era necesario encontrar una solución que permitiera solicitudes repetidas de respuestas erróneas con un tiempo de espera especificado, pero que al mismo tiempo no dejara de procesar solicitudes exitosas en la cola principal. Para esto, se eligió el llamado concepto de "reintento basado en temas". Para cada tema principal, se crean uno o varios temas de reintento, a los cuales se envían mensajes erróneos y, al mismo tiempo, se elimina la demora en el procesamiento de mensajes del tema principal. Esquema de interacción
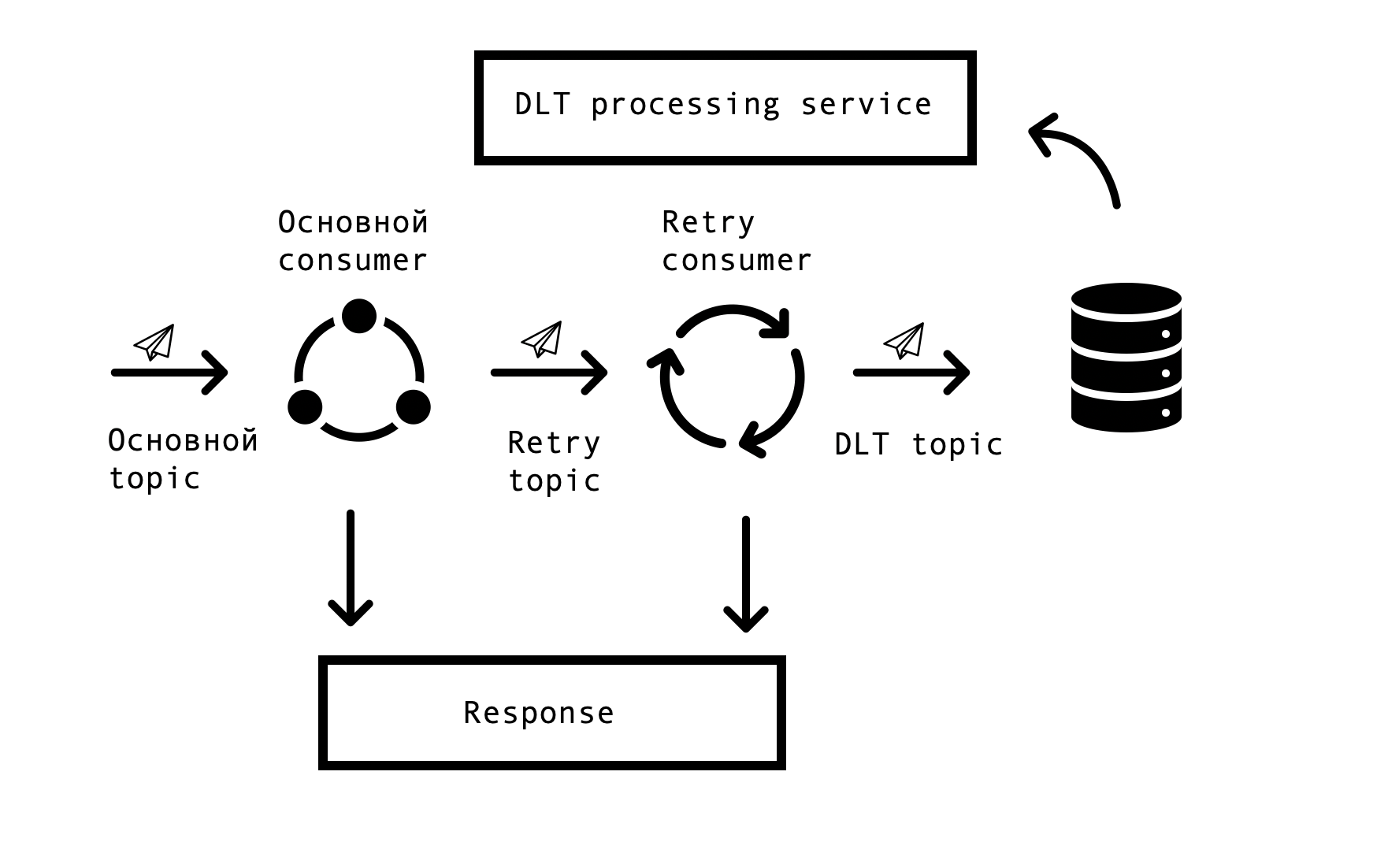
Para implementar dicho esquema, necesitábamos lo siguiente: integrar esta solución con Spring y evitar la duplicación de código. En la inmensidad de la red, encontramos una solución similar basada en Spring BeanPostProccessor, pero nos pareció innecesariamente engorrosa. Nuestro equipo creó una solución más simple que nos permite integrarnos en el ciclo de creación de consumidores de Spring y, además, agregar Reintentar consumidores. Ofrecimos un prototipo de nuestra solución al equipo de Spring, puede verlo aquí . La cantidad de Reintentar consumidores y la cantidad de intentos para cada consumidor se configura a través de parámetros, dependiendo de las necesidades del proceso comercial, y para que todo funcione, todo lo que queda es poner la anotación org.springframework.kafka.annotation.KafkaListener, que es familiar para todos los desarrolladores de Spring.
Si el mensaje no se pudo procesar después de todos los intentos de reintento, se envía al DLT (tema de letra muerta) utilizando Spring DeadLetterPublishingRecoverer. A pedido de soporte, hemos expandido esta funcionalidad e hicimos un servicio separado que le permite ver mensajes, stackTrace, traceId y otra información útil sobre ellos que ingresó a DLT. Además, se agregaron monitoreo y alertas a todos los temas de DLT, y ahora, de hecho, la aparición de un mensaje en un tema de DLT es una razón para analizar y establecer un defecto. Esto es muy conveniente: por el nombre del tema, entendemos de inmediato en qué paso del proceso surgió el problema, lo que acelera significativamente la búsqueda de su causa raíz.

Más recientemente, hemos implementado una interfaz que nos permite reenviar mensajes con nuestro soporte, después de eliminar sus causas (por ejemplo, restaurar la operatividad del sistema externo) y, por supuesto, establecer el defecto correspondiente para el análisis. Aquí es donde nuestros temas personales fueron útiles, para no reiniciar una larga cadena de procesamiento, puede reiniciarla desde el paso deseado.
Operación de plataforma
La plataforma ya está en operación productiva, todos los días realizamos entregas y envíos, conectamos nuevos centros de distribución y tiendas. Como parte del piloto, el sistema trabaja con los grupos de bienes "Tabaco" y "Zapatos".
Todo nuestro equipo está involucrado en la realización de pruebas piloto, analizando problemas emergentes y haciendo propuestas para mejorar nuestro producto, desde la mejora de los registros hasta los procesos cambiantes.
Para no repetir nuestros errores, todos los casos encontrados durante el piloto se reflejan en pruebas automatizadas. La presencia de una gran cantidad de pruebas automáticas y pruebas unitarias le permite realizar pruebas de regresión y poner una revisión en solo unas pocas horas.
Ahora continuamos desarrollando y mejorando nuestra plataforma, y constantemente enfrentamos nuevos desafíos. Si está interesado, le informaremos sobre nuestras soluciones en los siguientes artículos.