Para una visión general, tomamos las actas de CHI: Conferencia sobre Factores Humanos en Sistemas de Computación durante 10 años, y con la ayuda de PNL y análisis de redes sociales, analizamos temas y áreas en la intersección de disciplinas.

En Rusia, el enfoque es especialmente fuerte en los problemas aplicados del diseño UX. Muchos de los eventos que ayudaron al crecimiento de HCI en el extranjero no tuvieron lugar en nuestro país: iSchools no apareció , muchos especialistas que estaban involucrados en aspectos relacionados con la psicología de la ingeniería dejaron la ciencia, etc. Como resultado, la profesión reapareció, a partir de problemas aplicados e investigación. Uno de los resultados de esto es visible incluso ahora: es la representación extremadamente baja del trabajo ruso de HCI en conferencias clave.
Pero fuera de Rusia, HCI se ha desarrollado de maneras muy diferentes, centrándose en una variedad de temas y áreas. Sobre el programa de maestría " Sistemas de información e interacción humano-computadora»En St. Petersburg HSE, entre otras cosas, discutimos, con estudiantes, colegas, graduados de especialidades similares de universidades europeas, socios que ayudan a desarrollar el programa, lo que pertenece al campo de la interacción humano-computadora. Y estas discusiones muestran la heterogeneidad de la dirección en la que cada especialista tiene su propia imagen incompleta del campo.
De vez en cuando escuchamos preguntas sobre cómo se relaciona esta dirección (y si está conectada) con el aprendizaje automático y el análisis de datos. Para responderlas, recurrimos a una investigación reciente presentada en la conferencia CHI .
En primer lugar, le diremos lo que está sucediendo en áreas como xAI e iML (Inteligencia Artificial eXplainable y aprendizaje automático interpretable) desde el punto de vista de las interfaces y los usuarios, así como de cómo en HCI estudian los aspectos cognitivos del trabajo de los científicos de datos, y daremos ejemplos de trabajos interesantes en los últimos años en cada área.
xAI e iML
Las técnicas de aprendizaje automático están experimentando un desarrollo intensivo y, lo que es más importante desde el punto de vista del área en discusión, se están implementando activamente en la toma de decisiones automatizada. Por lo tanto, los investigadores discuten cada vez más las siguientes preguntas: ¿cómo interactúan los usuarios de aprendizaje no automático con los sistemas donde se utilizan algoritmos similares? Una de las preguntas importantes de esta interacción: ¿cómo hacer que los usuarios confíen en las decisiones tomadas por los modelos? Por lo tanto, cada año los temas del aprendizaje automático interpretado (Interpretable Machine Learning - iML) y la inteligencia artificial explicable (Inteligencia Artificial eXplainable - XAI) son cada vez más candentes.
Al mismo tiempo, si en conferencias tales como NeurIPS, ICML, IJCAI, KDD, se discuten los algoritmos y los medios de iML y XAI, el CHI se centra en varios temas relacionados con las características de diseño y la experiencia de uso de estos sistemas. Por ejemplo, en CHI-2020, se dedicaron varias secciones a este tema a la vez, incluyendo "AI / ML y ver a través de la caja negra" y "Hacer frente a la IA: ¡no de nuevo!". Pero incluso antes de la aparición de secciones separadas, había muchos de esos trabajos. Hemos identificado cuatro áreas en ellos.
Diseño de sistemas interpretativos para resolver problemas aplicados.
La primera dirección es el diseño de sistemas basados en algoritmos de interpretabilidad en varios problemas aplicados: médicos, sociales, etc. Tales trabajos surgen en áreas muy diferentes. Por ejemplo, trabajar en CHI-2020 CheXplain: permitir a los médicos explorar y comprender el análisis de imágenes médicas basado en datos y habilitado por IA describe un sistema que ayuda a los médicos a examinar y explicar los resultados de las radiografías de tórax. Ofrece explicaciones textuales y visuales adicionales, así como imágenes con el mismo resultado y opuesto (ejemplos de apoyo y conflictivos). Si el sistema predice que una enfermedad es visible en la radiografía, mostrará dos ejemplos. El primer ejemplo de apoyo es una instantánea de los pulmones de otro paciente que ha confirmado la misma enfermedad. El segundo ejemplo contradictorio es una instantánea en la que no hay enfermedad, es decir, una instantánea de los pulmones de una persona sana. La idea principal es reducir los errores obvios y reducir el número de consultas externas en casos simples para hacer un diagnóstico más rápido.
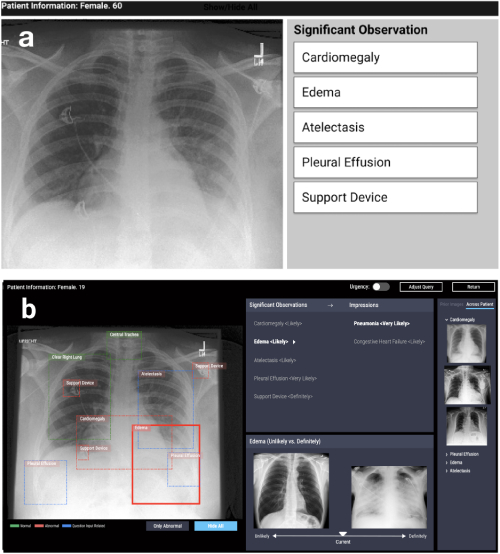
CheXpert: selección de región automatizada + ejemplos (poco probable frente a definitivamente)
Desarrollo de sistemas para la investigación de modelos de aprendizaje automático.
La segunda dirección es el desarrollo de sistemas que ayudan a comparar o combinar de manera interactiva varios métodos y algoritmos. Por ejemplo, en el trabajo de Silva: Evaluación interactiva de la equidad del aprendizaje automático usando la causalidad en CHI-2020, se presentó un sistema que construye varios modelos de aprendizaje automático sobre los datos del usuario y ofrece la posibilidad de su posterior análisis. El análisis incluye la construcción de un gráfico causal entre variables y el cálculo de una serie de métricas que evalúan no solo la precisión, sino también la equidad del modelo (diferencia de paridad estadística, diferencia de igualdad de oportunidades, diferencia de probabilidades promedio, impacto disperso, índice Theil), que ayuda a encontrar el sesgo en predicciones

Silva : gráfico de relaciones entre variables + gráficos para comparar métricas de equidad + resaltado de color de variables influyentes en cada grupo
Problemas generales de la interpretabilidad del modelo.
La tercera área es la discusión de enfoques al problema de la interpretabilidad de los modelos en general. En la mayoría de los casos, se trata de revisiones, críticas de enfoques y preguntas abiertas: por ejemplo, qué se entiende por "interpretabilidad". Aquí me gustaría señalar la revisión en CHI-2018 Tendencias y trayectorias para sistemas explicables, responsables e inteligibles: una agenda de investigación de HCI, en el cual los autores revisaron 289 artículos principales sobre explicaciones en inteligencia artificial, y 12,412 publicaciones que los citaron. Mediante el análisis de redes y el modelado temático, identificaron cuatro áreas de investigación clave 1) Sistemas inteligentes y ambientales (I&A), 2) IA explicable: algoritmos justos, responsables y transparentes (FAT) y Aprendizaje automático interpretable (iML), 3) Teorías de Explicaciones: Causalidad y psicología cognitiva, 4) Interactividad y capacidad de aprendizaje. Además, los autores describieron las principales tendencias de investigación: aprendizaje interactivo e interacción con el sistema.
Investigación de usuarios
Finalmente, la cuarta área es la investigación del usuario sobre algoritmos y sistemas que interpretan modelos de aprendizaje automático. En otras palabras, se trata de estudios sobre si en la práctica los nuevos sistemas se están volviendo más claros y transparentes, qué dificultades enfrentan los usuarios cuando trabajan con modelos interpretativos en lugar de modelos originales, cómo determinar si el sistema se está utilizando según lo planeado (o si se ha encontrado un nuevo uso para él) - quizás incorrecto), cuáles son las necesidades de los usuarios y si los desarrolladores les ofrecen lo que realmente necesitan.
Existen muchas herramientas y algoritmos de interpretación, por lo que surge la pregunta: ¿cómo entender qué algoritmo elegir? Al cuestionar la IA: informar prácticas de diseño para experiencias de usuario de IA explicablesSe discuten los temas de motivación para el uso de algoritmos explicativos y se identifican problemas que, con toda la variedad de métodos, aún no se han resuelto lo suficiente. Los autores llegan a una conclusión inesperada: la mayoría de los métodos existentes están construidos de tal manera que responden la pregunta "por qué" ("por qué obtuve ese resultado"), mientras que los usuarios también necesitan una respuesta a la pregunta "por qué no" ("por qué no otro ") y, a veces," qué hacer para cambiar el resultado ".
El documento también dice que los usuarios necesitan comprender cuáles son los límites de aplicabilidad de los métodos, qué limitaciones tienen, y esto debe implementarse explícitamente en las herramientas propuestas. Este problema se muestra más claramente en el artículo.Interpretación de la interpretabilidad: comprensión de los datos que usan los científicos de las herramientas de interpretación para el aprendizaje automático . Los autores realizaron un pequeño experimento con especialistas en el campo del aprendizaje automático: mostraron los resultados de varias herramientas populares para interpretar modelos de aprendizaje automático y les pidieron que respondieran preguntas relacionadas con la toma de decisiones basadas en estos resultados. Resultó que incluso los expertos confían demasiado en tales modelos y no toman los resultados de manera crítica. Como cualquier herramienta, los modelos explicativos pueden ser mal utilizados. Al desarrollar el kit de herramientas, es importante tener esto en cuenta, utilizando el conocimiento acumulado (o especialistas) en el campo de la interacción humano-computadora para tener en cuenta las características y necesidades de los usuarios potenciales.
Data Science, Notebooks, Visualization
Otra área interesante de HCI está en el análisis de los aspectos cognitivos del trabajo con datos. Recientemente, la ciencia ha planteado la cuestión de cómo los "grados de libertad" del investigador (las características de la recopilación de datos, el diseño experimental y la elección de métodos analíticos) afectan los resultados de la investigación y su reproducibilidad. Si bien gran parte de la discusión y las críticas están relacionadas con la psicología y las ciencias sociales, muchos problemas se refieren a la fiabilidad de las conclusiones en el trabajo de los analistas de datos en general, así como a las dificultades para comunicar estos hallazgos a los consumidores de análisis.
Por lo tanto, el tema de esta área de HCI es el desarrollo de nuevas formas de visualizar la incertidumbre en las predicciones del modelo, la creación de sistemas para comparar los análisis realizados de diferentes maneras, así como el análisis del trabajo de los analistas con herramientas como los cuadernos Jupyter.
Visualizando incertidumbre
La visualización de incertidumbre es una de las características que distingue los gráficos científicos de la presentación y la visualización comercial. Durante bastante tiempo, el principio de minimalismo y el enfoque en las principales tendencias se consideraron la clave en este último. Sin embargo, esto lleva a un exceso de confianza de los usuarios en una estimación puntual de una magnitud o pronóstico, que puede ser crítico, especialmente si tenemos que comparar pronósticos con diferentes grados de incertidumbre. Las pantallas de incertidumbre en el trabajo que utilizan puntos de puntos cuantiles o CDF mejoran la toma de decisiones de tránsitoexamina cómo la visualización de la incertidumbre en la predicción de diagramas de dispersión y funciones de distribución acumulativa ayuda a los usuarios a tomar decisiones más racionales utilizando el ejemplo del problema de estimar el tiempo de llegada de un bus a partir de los datos de una aplicación móvil. Lo que es especialmente bueno es que uno de los autores mantiene el paquete ggdist para R con varias opciones para visualizar la ambigüedad.

Ejemplos de visualización de incertidumbre ( https://mjskay.github.io/ggdist/ )
Sin embargo, a menudo hay problemas para visualizar posibles alternativas, por ejemplo, para secuencias de acción del usuario en análisis web o análisis de aplicaciones. Work Visualizing Uncertainty and Alternatives in Event Sequence Predictions analiza cómo una representación gráfica de las alternativas basada en el modelo Red neuronal recurrente consciente del tiempo (TRNN ) ayuda a los expertos a tomar decisiones y confiar en ellas.
Comparación de modelos
Tan importante como visualizar la incertidumbre, un aspecto del trabajo de los analistas es comparar cómo, a menudo oculto, la elección del investigador de diferentes enfoques para modelar en todas sus etapas puede conducir a diferentes resultados analíticos. En psicología y ciencias sociales, el prerregistro del diseño de la investigación y una clara separación de los estudios exploratorios y confirmatorios están ganando popularidad. Sin embargo, en tareas donde la investigación se basa más en datos, una alternativa puede ser herramientas que le permitan evaluar los riesgos ocultos del análisis mediante la comparación de modelos. Trabajando para aumentar la transparencia de los trabajos de investigación con análisis de múltiples universos explorablessugiere utilizar la visualización interactiva de varios enfoques de análisis en artículos. En esencia, el artículo se convierte en una aplicación interactiva donde el lector puede evaluar qué cambiará en los resultados y conclusiones si se aplica un enfoque diferente. Esta parece ser una idea útil para el análisis práctico también.
Trabajar con herramientas para organizar y analizar datos.
El último bloque de trabajo está relacionado con el estudio de cómo trabajan los analistas con sistemas como Jupyter Notebooks, que se han convertido en una herramienta popular para organizar el análisis de datos. La Exploración y explicación de artículos en cuadernos computacionales analiza las contradicciones entre la investigación y la explicación de los objetivos de aprendizaje que se encuentran en los documentos interactivos de Github, y la gestión de problemas en los cuadernos computacionaleslos autores analizan cómo evolucionan las notas, las piezas de código y las visualizaciones en un flujo de trabajo iterativo de analistas, y sugieren posibles adiciones a las herramientas para respaldar este proceso. Finalmente, ya en CHI 2020, los principales problemas de los analistas en todas las etapas del trabajo, desde la carga de datos hasta la transferencia de un modelo a la producción, así como las ideas para mejorar las herramientas, se resumen en el artículo ¿Qué hay de malo en las computadoras portátiles? Puntos de dolor, necesidades y oportunidades de diseño .
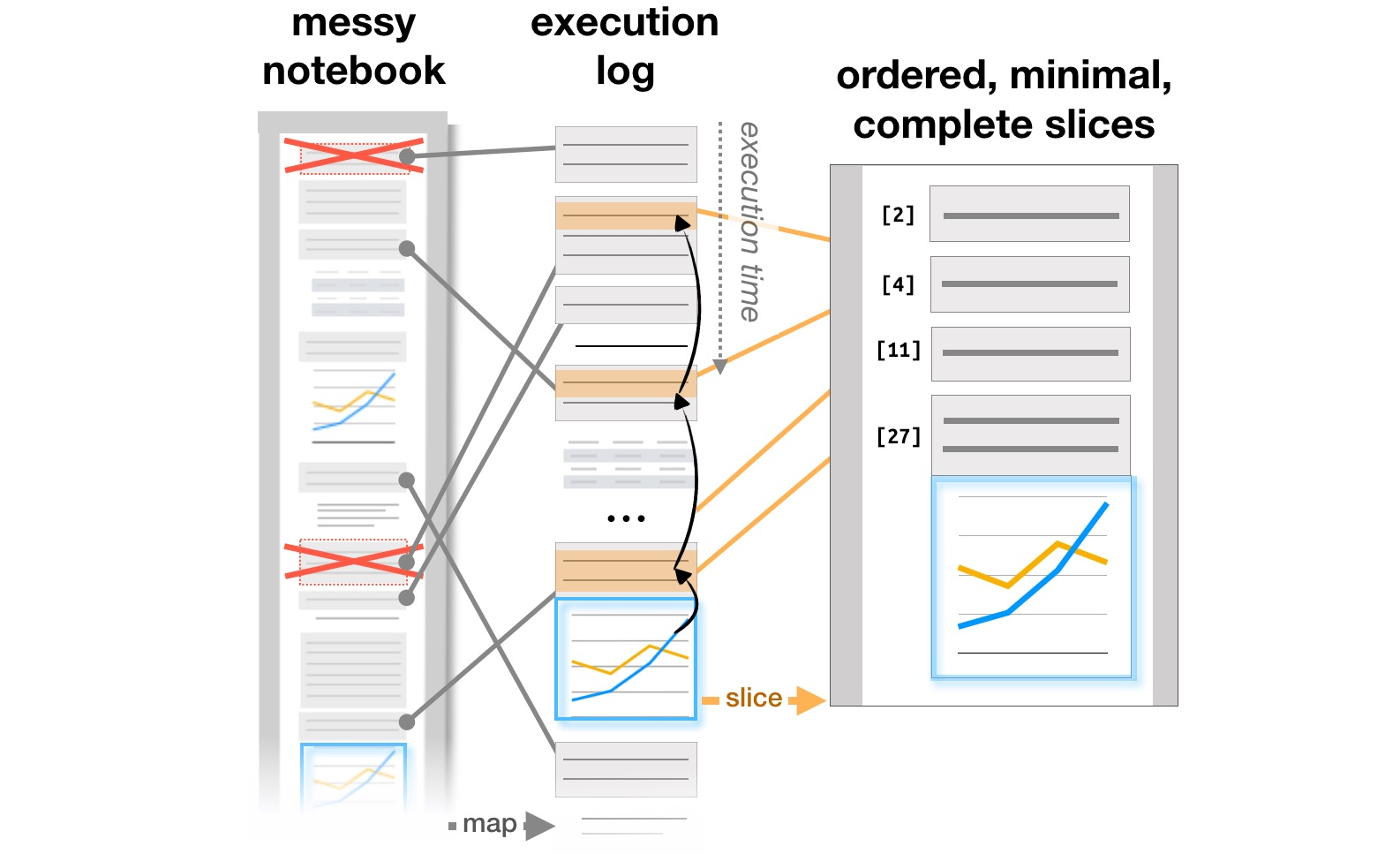
Transformación de la estructura de informes basada en registros de ejecución ( https://microsoft.github.io/gather/ )
Resumiendo
Concluyendo la parte de la discusión "qué hace HCI" y "por qué un especialista en HCI conoce el aprendizaje automático", quisiera reiterar la conclusión general de la motivación y los resultados de estos estudios. Tan pronto como una persona aparece en el sistema, esto lleva inmediatamente a una serie de preguntas adicionales: cómo simplificar la interacción con el sistema y evitar errores, cómo el usuario cambia el sistema, si el uso real difiere del planificado. Como resultado, necesitamos a aquellos que entiendan cómo funciona el proceso de diseño de sistemas con inteligencia artificial y que sepan tener en cuenta el factor humano.
Enseñamos todo esto en el programa de maestría " Sistemas de información e interacción humano-computadora". Si está interesado en la investigación de HCI, revise la luz (la campaña de admisiones acaba de comenzar ). O siga nuestro blog: le diremos más sobre los proyectos en los que los estudiantes han estado trabajando este año.