
En uno de los artículos anteriores , cubrimos algunos puntos clave de la configuración de un clúster de Amazon EKS multiempresa (en adelante multiempresa ) . En cuanto a la seguridad, este es un tema muy extenso. Es importante comprender que la seguridad no se trata solo del clúster de aplicaciones, sino también del almacén de datos. AWS como plataforma para soluciones SaaS tiene una gran variabilidad para el almacenamiento de datos. Pero, como en otros lugares, la configuración de seguridad competente, el desarrollo de una arquitectura multiempresa para ella, la configuración de varios niveles de aislamiento requieren cierto conocimiento y comprensión de los detalles del trabajo.
Almacén de datos de múltiples inquilinos
Es conveniente administrar datos de múltiples inquilinos utilizando silos, Silo . La característica principal es la separación de los datos de alquiler (en adelante, inquilino ) en soluciones SaaS multiusuario . Pero antes de hablar sobre casos específicos, tocaremos un poco de teoría general.
Texto oculto
«» IT-, , « ».
Solo un inquilino debe tener acceso
La seguridad de los datos es una prioridad para las soluciones SaaS . Es necesario proteger los datos no solo de intrusiones externas, sino también de la interacción con otros inquilinos . Incluso en el caso de que dos inquilinos cooperen entre sí y el acceso a los datos comunes se controle y configure de acuerdo con la lógica empresarial.
Estándares de la industria para cifrado y seguridad
Los estándares de los inquilinos pueden variar según la industria. Algunos requieren encriptación de datos con una frecuencia de cambio de clave bien definida, mientras que otros requieren otros orientados a los inquilinos en lugar de claves compartidas . Al identificar conjuntos de datos con inquilinos específicos , se pueden aplicar diferentes estándares de cifrado y configuraciones de seguridad a inquilinos individuales como excepción.
Ajuste de rendimiento basado en suscripción de inquilino
Por lo general, los proveedores de SaaS recomiendan un flujo de trabajo común para todos los inquilinos . Desde un punto de vista práctico, esto puede no ser siempre conveniente en relación con la lógica empresarial específica. Por lo tanto, se puede hacer de manera diferente. A cada inquilino se le asigna un conjunto diferente de propiedades y límites de rendimiento basados en el estándar TIER . Para que los clientes obtengan el rendimiento que se establece en el acuerdo de SaaS , los proveedores deben controlar el uso del inquilino individual . Esto brinda a todos los clientes el mismo acceso a los recursos.
Texto oculto
, . , , .
Gestión de datos
A medida que crecen los servicios SaaS , también lo hace el número de inquilinos . Si el cliente cambia de proveedor, la mayoría de las veces quiere que todos los datos se carguen en otro recurso y que los antiguos se eliminen. Si el primer deseo puede ser cuestionado, entonces el cumplimiento del segundo está garantizado por las Reglas Generales de Protección de Datos de la UE. Para la correcta ejecución de las reglas, el proveedor de SaaS debe identificar inicialmente los conjuntos de datos de los inquilinos individuales .
Texto oculto
?! , , . . .
Cómo convertir un Data Warehouse normal en multiusuario
Me gustaría señalar de inmediato que no hay un código mágico. No puede simplemente recoger y configurar un contenedor de datos del inquilino . Deben considerarse los siguientes aspectos:
- Acuerdo de servicio
- Patrones de acceso para leer y escribir;
- Cumplimiento de las normas;
- Gastos.
Pero hay una serie de prácticas generalmente aceptadas para separar y aislar datos. Veamos estos casos utilizando la base de datos relacional de Amazon Aurora como ejemplo .
Particionar datos de inquilinos en repositorios e instancias compartidas
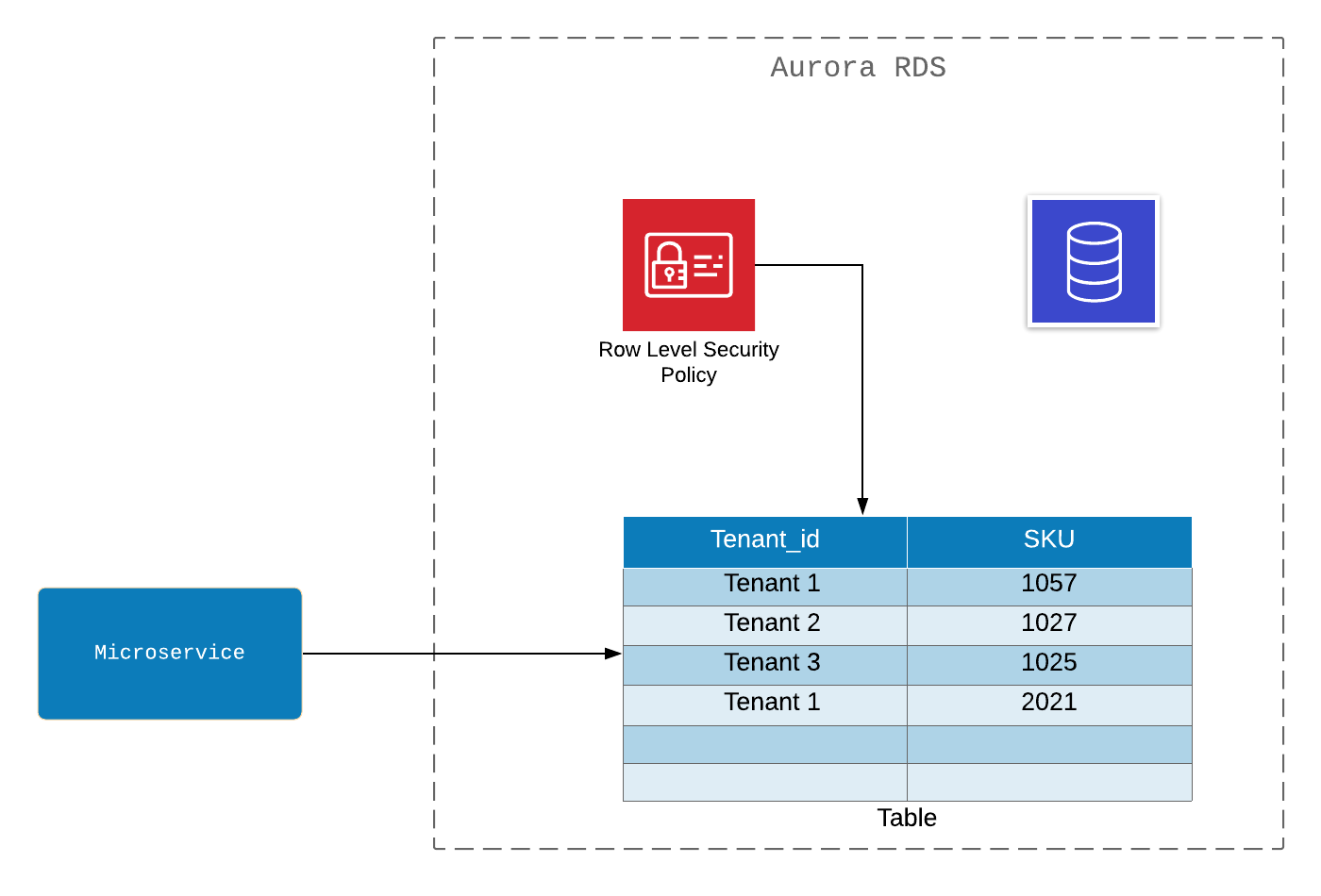
La tabla es utilizada por todos los inquilinos . Los datos individuales están separados e identificados por la clave tenant_id . La autorización de la base de datos relacional se implementa en la seguridad de nivel de fila . El acceso a la aplicación funciona según la política de acceso y tiene en cuenta un inquilino específico .
Pros:
- No es caro.
Desventajas:
- Autorización a nivel de base de datos. Esto implica varios mecanismos de autorización dentro de la solución: AWS IAM y Políticas de base de datos;
- Para identificar al inquilino, deberá desarrollar la lógica de la aplicación;
- Sin un aislamiento completo, no es posible hacer cumplir el acuerdo de servicio TIER ;
- La autorización de nivel de base de datos limita el seguimiento de acceso con AWS CloudTrail . Esto solo se puede compensar agregando información del exterior. Mejor hacer seguimiento y solución de problemas.
Aislamiento de datos en instancia compartida

El arrendamiento ( tenencia ) sigue siendo rassharivat en el nivel de instancia. Pero al mismo tiempo, el almacenamiento de datos se produce a nivel de base de datos. Esto permite la autenticación y autorización de AWS IAM.
Pros:
- No es caro;
- AWS IAM es totalmente responsable de la autenticación y autorización;
- AWS IAM le permite mantener una pista de auditoría en AWS CloudTrail sin muletas como aplicaciones separadas.
Desventajas:
- Instancias básicas DB sharyatsya entre el inquilino , en relación con la posible salida de recursos que no cumple completamente el acuerdo TIER sobre el servicio.
Aislamiento de instancia de base de datos para inquilino

El diagrama muestra la implementación de una base de datos de inquilinos , por ejemplo, el aislamiento. Hoy, esta es probablemente la mejor solución que combina seguridad y confiabilidad. Hay AWS IAM , auditoría de AWS CloudTrail y aislamiento total de inquilinos .
Pros:
- AWS IAM proporciona autenticación y autorización;
- Hay una auditoría completa;
- tenant.
:
- tenant — .
multitenant
Asegurar que las aplicaciones tengan el acceso correcto a los datos es más importante que almacenar datos en un modelo de inquilino que cumpla con los requisitos comerciales. No es difícil si usa AWS IAM para el control de acceso (consulte los ejemplos anteriores). Las aplicaciones que proporcionan acceso de inquilinos a los datos también pueden usar AWS IAM . Esto se puede ver con Amazon EKS como ejemplo .
Para proporcionar acceso al IAM a nivel de pod en el EKS , se adapta perfectamente el OpenID the Connect (OIDC) , con anotaciones para dar cuenta de Kubernetes . Como resultado, el JWT se intercambiará conSTS , que creará acceso temporal para aplicaciones a los recursos de nube necesarios. Con este enfoque, no necesita ingresar permisos extendidos para los nodos de trabajo básicos de Amazon EKS . En su lugar, puede configurar solo los permisos de IAM para la cuenta relacionada con el pod . Esto se realiza en función de los permisos reales de la aplicación que se ejecuta como parte del pod . Como resultado, obtenemos el control total de los permisos de aplicaciones y pod .
Texto oculto
, AWS CloudTrail EKS pod API, .
La integración de IAM admite un sistema de autorización integral para el acceso de los inquilinos a los almacenes de datos. En este caso, el acceso a la base de datos se controla solo a través de la autenticación, lo que significa que se debe introducir otro nivel de seguridad.
Amazon EKS accede a la base de datos multiusuario AWS DynamoDB
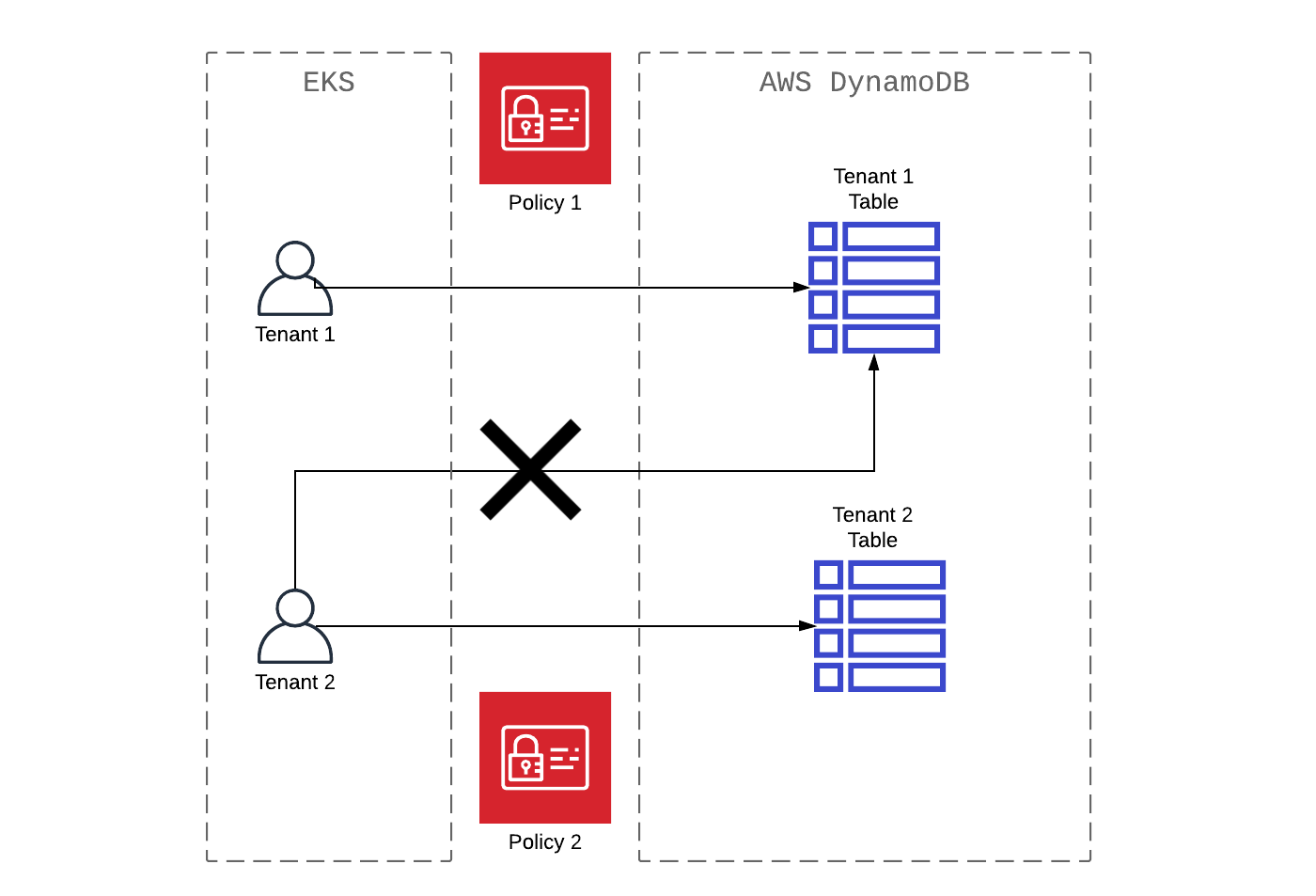
Una mirada más cercana a la multitenant acceso, tanto una aplicación que se ejecuta en EKS de Amazon , se accede a multiusuario base de datos de DynamoDB de Amazon . En muchos casos, multitenant procesos en Amazon DynamoDB se implementan en el nivel de la mesa (en un 1: 1 mesa para inquilino relación ). Como ejemplo, considere el principio AWS IAM ( aws-dynamodb-tenant1-policy ), que ilustra perfectamente el patrón de acceso, donde todos los datos están asociados con Tenant1 .
{
...
"Statement": [
{
"Sid": "Tenant1",
"Effect": "Allow",
"Action": "dynamodb:*",
"Resource": "arn:aws:dynamodb:${region}-${account_id}:table/Tenant1"
}
]
}El siguiente paso es asociar este rol con una cuenta de clúster de EKS que usa OpenID .
eksctl utils associate-iam-oidc-provider \
--name my-cluster \
--approve \
--region ${region}
eksctl create iamserviceaccount \
--name tenant1-service-account \
--cluster my-cluster \
--attach-policy-arn arn:aws:iam::xxxx:policy/aws-dynamodb-tenant1-policy \
--approve \
--region ${region}
La definición de pod , que contiene la especificación de serviceAccountName requerida , lo ayudará a usar la nueva cuenta de servicio tenant1-service-account .
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
serviceAccountName: tenant1-service-account
containers:
- name: tenant1
…Si bien la política y la cuenta del inquilino de IAM están orientadas, son estáticas y se administran con herramientas como Terraform y Ansible , la especificación de pod puede configurarse dinámicamente. Si está utilizando un generador de plantillas como Helm , serviceAccountName se puede establecer como una variable para las cuentas de inquilinos de servicio apropiadas . Como resultado, cada inquilino tendrá su propia implementación dedicada de la misma aplicación. De hecho, cada inquilino debe tener un espacio de nombres dedicado, donde se ejecutarán las aplicaciones.
Texto oculto
Amazon Aurora Serverless, Amazon Neptune Amazon S3.
Conclusión
Para los servicios SaaS , es importante pensar detenidamente sobre cómo se accederá a los datos. Considere los requisitos de almacenamiento, cifrado, rendimiento y administración de inquilinos . En multitenant tiene uno de los métodos preferidos de partición de datos. La ventaja de ejecutar multitenant AWS cargas de trabajo es AWS IAM , que se puede utilizar para simplificar el control de acceso para los datos de los inquilinos. Además, AWS IAM lo ayudará a configurar el acceso de la aplicación a los datos en modo dinámico.
Las características y técnicas descritas que pueden ser útiles tocaron una pequeña teoría. Pero en casos especiales siempre es necesario analizar de forma independiente la información de origen y crear una solución personalizada.