Solía ser un líder de equipo, y estaba a cargo de un par de servicios críticos. Y si algo salía mal en ellos, se detenían los procesos comerciales reales. Por ejemplo, los pedidos dejaron de ir al ensamblaje en el almacén.
Recientemente me convertí en líder de dirección y ahora estoy a cargo de tres equipos en lugar de uno. Cada uno de ellos ejecuta un sistema de TI. Quiero entender qué está sucediendo en cada sistema y qué puede romperse.
En este artículo hablaré sobre
- lo que monitoreamos
- como monitoreamos
- y lo más importante, qué hacemos con los resultados de estas observaciones.

Lamoda tiene muchos sistemas. Todos se liberan, algo cambia en ellos, algo le sucede a la técnica. Y quiero tener al menos la ilusión de que podemos localizar fácilmente el desglose. Me bombardean constantemente con alertas que trato de descifrar. Para escapar de las abstracciones e ir a detalles, te diré el primer ejemplo.
De vez en cuando, algo explota: crónicas de un incendio
Una cálida mañana de verano sin declarar la guerra, como suele ser el caso, el monitoreo funcionó para nosotros. Usamos Icinga como alerta. Alert dijo que nos quedan 50 GB de disco duro en el servidor DBMS. Lo más probable es que 50 gigabytes sean una gota en el océano, y terminará muy rápidamente. Decidimos ver cuánto espacio libre quedaba. Debe comprender que no se trata de máquinas virtuales, sino de servidores de hierro, y la base está bajo una gran carga. Hay un SSD de 1.5 terabytes. Pronto este recuerdo pronto llegará a su fin: durará de 20 a 30 días. Esto es muy poco, necesita resolver rápidamente el problema.
Luego, también verificamos cuánta memoria se consumió realmente en 1-2 días. Resulta que 50 gigabytes durarán unos 5-7 días. Después de eso, el servicio que funciona con esta base finalizará previsiblemente. Comenzamos a pensar en las consecuencias: qué archivaremos con urgencia, qué datos eliminaremos. El departamento de análisis de datos tiene todas las copias de seguridad, por lo que puede eliminar de forma segura todo lo anterior a 2015.
Intentamos eliminarlo y recordar que MySQL no funcionará así desde media patada. Los datos eliminados son geniales, pero el tamaño del archivo asignado para la tabla y para la base de datos no cambia. MySQL luego usa este lugar. Es decir, el problema no se ha resuelto, no hay más espacio.
Probar un enfoque diferente: migrar etiquetas de SSD que caducan rápidamente a otras más lentas. Para hacer esto, seleccionamos las placas que pesan mucho, pero con poca carga, y utilizamos el monitoreo de Percona. Movimos las tablas y ya estamos pensando en mover los servidores. Después del segundo movimiento, los servidores ocupan no 1.5, sino 4 terabytes de SSD.
Apagamos este incendio: organizamos un movimiento y, por supuesto, un monitoreo fijo. Ahora la advertencia se activará no a 50 gigabytes, sino a medio terabyte, y el valor de monitoreo crítico, a 50 gigabytes. Pero en realidad, esto es solo una manta que cubre la parte trasera. Por algún tiempo será suficiente. Pero si permitimos una repetición de la situación, sin dividir la base en partes y sin pensar en fragmentar, todo terminará mal.
Supongamos que además cambiamos los servidores. En algún momento, fue necesario reiniciar el maestro. Probablemente, aparecerán errores en este caso. En nuestro caso, el tiempo de inactividad fue de aproximadamente 30 segundos. Pero las solicitudes están llegando, no hay ningún lugar para escribir, los errores han llegado, el monitoreo ha funcionado. Usamos el sistema de monitoreo Prometheus, y vemos que la métrica de 500 errores o el número de errores al crear un pedido saltaron. Pero no conocemos los detalles: qué tipo de orden no se creó, etc.
A continuación, le diré cómo trabajamos con el monitoreo para no caer en tales situaciones.
Revisión de monitoreo y descripción clara para atención al cliente
Tenemos varias áreas e indicadores que estamos observando. Hay televisores en todas partes en la oficina, en los cuales hay muchas etiquetas técnicas y comerciales diferentes, que, además de los desarrolladores, son monitoreadas por el servicio de soporte.
En este artículo, hablo sobre cómo lo tenemos y agrego a lo que queremos llegar. Esto también se aplica a las revisiones de monitoreo. Si regularmente realizáramos un inventario de nuestra "propiedad", podríamos actualizar todo desactualizado y arreglarlo, evitando la repetición del fakap. Esto requiere una lista coherente.
Tenemos configuraciones de hielo con alertas en el repositorio, donde ahora hay 4678 líneas. De esta lista es difícil entender de qué está hablando cada monitoreo específico. Digamos que nuestra métrica se llama db_disc_space_left. El servicio de soporte no entenderá de inmediato de qué se trata. Algo sobre el espacio libre, genial.
Queremos cavar más profundo. Observamos la configuración de este monitoreo y entendemos de dónde viene.
pm_host: "{{ prometheus_server }}"
pm_query: ”mysql_ssd_space_left"
pm_warning: 50
pm_critical: 10 pm_nanok: 1
Esta métrica tiene un nombre, sus propias limitaciones, cuándo incluir el monitoreo de advertencia, una alerta para informar una situación crítica. Utilizamos una convención de nomenclatura métrica. Al comienzo de cada métrica está el nombre del sistema. Gracias a esto, el área de responsabilidad queda clara. Si la persona responsable del sistema inicia la métrica, queda inmediatamente claro a quién acudir.
Las alertas se vierten en telegramas o se aflojan. El servicio de soporte es el primero en responder a ellos 24/7. Los chicos miran qué explotó exactamente, si esta es una situación normal. Tienen instrucciones:
- los que están siendo reemplazados,
- e instrucciones que se fijan en confluencia de manera continua. Por el nombre de la supervisión explotada, puede encontrar lo que significa. Para los más críticos, se describe qué está roto, cuáles son las consecuencias, quién necesita ser criado.
También tenemos turnos de turno en los equipos responsables de los sistemas clave. Cada equipo tiene alguien que está constantemente disponible. Si algo sucede, lo recogen.
Cuando se activa la alerta, el equipo de soporte debe encontrar rápidamente toda la información clave. Sería bueno tener un enlace a la descripción de monitoreo adjunto al mensaje de error. Por ejemplo, para que haya tal información:
- descripción de este monitoreo en términos claros y relativamente simples;
- la dirección donde se encuentra;
- una explicación de lo que es la métrica;
- consecuencias: cómo terminará si no corregimos el error;
- , , . , , . -, .
También sería conveniente ver de inmediato la dinámica del tráfico en la interfaz de Prometheus.
Me gustaría hacer tales descripciones para cada monitoreo. Le ayudarán a construir su revisión y hacer ajustes. Estamos implementando esta práctica: la configuración de formación de hielo ya contiene un enlace para confluir con esta información. He estado trabajando en un sistema durante casi 4 años, básicamente no hay tales descripciones para él. Por lo tanto, ahora estoy recopilando conocimiento juntos. Las descripciones también resuelven el problema de la ignorancia del equipo.
Tenemos instrucciones para la mayoría de las alertas, donde está escrito lo que conduce a un cierto impacto comercial. Es por eso que debemos resolver rápidamente la situación. La gravedad de los posibles incidentes está determinada por el servicio de asistencia junto con la empresa.
Daré un ejemplo: si se activa la supervisión del consumo de RAM en el servidor RabbitMQ del servicio de procesamiento de pedidos, esto significa que el servicio de cola puede bloquearse en unas pocas horas o incluso minutos. Esto, a su vez, detendrá muchos procesos comerciales. Como resultado, los clientes esperarán sin éxito pedidos, notificaciones SMS / push, cambios de estado y mucho más.
Las discusiones sobre monitoreo con negocios a menudo ocurren después de incidentes graves. Si algo se rompe, recaudamos una comisión con representantes de la dirección, que fue enganchada por nuestra liberación o incidente. En la reunión, analizamos las razones del incidente, cómo asegurarnos de que nunca vuelva a ocurrir, qué daño sufrimos, cuánto dinero perdimos y en qué.
Sucede que necesita conectar una empresa para resolver los problemas creados para los clientes. Discutimos acciones proactivas allí: qué tipo de monitoreo debe tener para que esto no vuelva a suceder.
El servicio de soporte monitorea los valores de las métricas usando un bot de telegramas. Cuando aparece un nuevo monitoreo, el personal de soporte necesita una herramienta simple que le permita saber dónde se rompió y qué hacer al respecto. El enlace a la descripción en la alerta resuelve este problema.
Veo el fakap como en realidad: usar Sentry para debriefing
No es suficiente conocer el error, desea ver los detalles. Nuestro caso de uso estándar es el siguiente: implementamos la versión y recibimos alertas de la pila K8S. Gracias a la supervisión, observamos el estado de los pods: qué versiones de la aplicación se implementaron, cómo terminó la implementación, todo está bien.
Luego nos fijamos en el RMM, que tenemos con la base y con la carga. Para Grafana y tableros, observamos la cantidad de conexiones a Rabbit. Es genial, pero sabe cómo fluir cuando se acaba la memoria. Monitoreamos estas cosas, y luego revisamos el Centinela. Le permite ver en línea cómo se desarrolla la próxima debacle con todos los detalles. En este caso, el monitoreo posterior al lanzamiento informa qué está roto y cómo.
En proyectos PHP, utilizamos un cliente raven, que además enriquece con datos. Sentry está muy bien agregado. Y vemos la dinámica de cada fakap, con qué frecuencia sucede. Y también miramos ejemplos, qué solicitudes fallaron, qué solicitudes salieron.
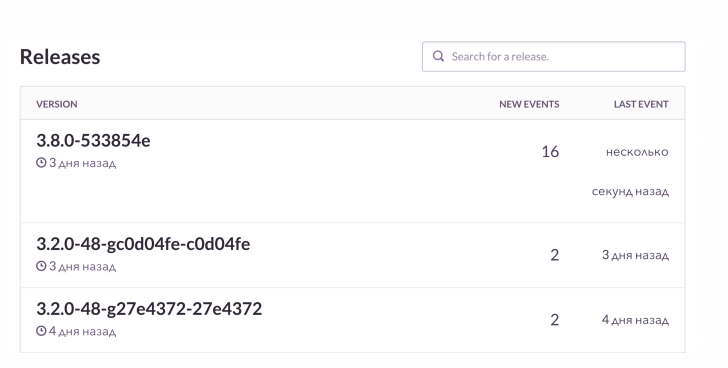
Esto es aproximadamente como se ve. Veo que en la próxima versión hay más errores de lo habitual. Comprobaremos qué está roto exactamente. Y luego, si es necesario, obtendremos las órdenes fallidas en el contexto y las arreglaremos.
Tenemos algo genial: vinculante para Jira. Este es un rastreador de tickets: hizo clic en un botón y se creó un error de tarea en Jira con un enlace a Sentry y un seguimiento de la pila de este error. La tarea está marcada con etiquetas específicas.
Uno de los desarrolladores trajo una iniciativa sensata: "Proyecto limpio, centinela limpio". Durante la planificación, cada vez que lanzamos al sprint al menos 1-2 tareas creadas desde Sentry. Si algo se rompe en el sistema todo el tiempo, entonces Sentry está plagado de millones de pequeños errores estúpidos. Los limpiamos regularmente para no perder inadvertidamente los realmente serios.
Incendios por cualquier motivo: nos deshacemos de la supervisión, en la que todos están metidos
- Acostumbrarse a los errores
Si algo parpadea constantemente y parece roto, da la sensación de una norma falsa. El servicio de soporte puede estar equivocado al pensar que la situación es adecuada. Y cuando algo serio se descompone, será ignorado. Como en una fábula sobre un niño que grita: "¡Lobos, lobos!".
Un caso clásico es nuestro proyecto responsable del procesamiento de pedidos. Funciona con el sistema de automatización del almacén y transfiere datos allí. Este sistema generalmente se lanza a las 7 am, después de lo cual comenzamos a monitorear. Todos están acostumbrados y puntúan, lo que no es muy bueno. Sería prudente ajustar estos controles. Por ejemplo, para vincular el lanzamiento de un sistema específico y algunas alertas a través de Prometheus, simplemente no active la señalización innecesaria.
- El monitoreo no considera métricas comerciales
El sistema de procesamiento de pedidos transfiere los datos al almacén. Hemos agregado monitores a este sistema. Ninguno de ellos disparó, y parece que todo está bien. El contador indica que los datos se están yendo. Este caso usa jabón. En realidad, el contador puede verse así: la parte verde es intercambios entrantes, la parte amarilla es saliente.
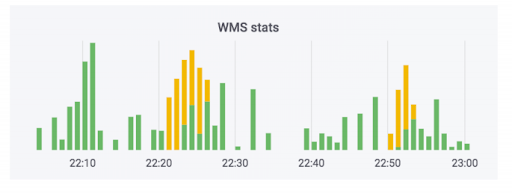
Tuvimos un caso cuando los datos realmente lo hicieron, pero curvas. Los pedidos no se pagaron, pero se marcaron como pagados. Es decir, el comprador podrá recogerlos de forma gratuita. Parece que da miedo. Pero lo contrario es más divertido: una persona viene a recoger un pedido pagado y se le pide que pague nuevamente debido a un error en el sistema.
Para evitar esta situación, observamos no solo la tecnología, sino también las métricas del negocio. Tenemos un monitoreo específico que monitorea la cantidad de pedidos que requieren el pago al recibirlos. Cualquier salto serio en esta métrica mostrará si algo salió mal.
El monitoreo de los indicadores comerciales es algo obvio, pero a menudo se olvidan cuando se lanzan nuevos servicios, incluidos nosotros. Todos difunden nuevos servicios con métricas puramente técnicas relacionadas con los discos, porcentaje, lo que sea. Como tienda en línea, tenemos una cosa crítica: la cantidad de pedidos creados. Sabemos cuánto suele comprar la gente, ajustada a las promociones de marketing. Por lo tanto, monitoreamos este indicador durante los lanzamientos.
Otra cosa importante: cuando un cliente ordena repetidamente la entrega a la misma dirección, no lo atormentamos comunicándonos con el centro de atención telefónica, sino que confirmamos automáticamente el pedido. Un bloqueo del sistema tiene un gran impacto en la experiencia del cliente. También seguimos esta métrica, ya que las versiones de diferentes sistemas pueden afectarla en gran medida.
Estamos viendo el mundo real: nos preocupamos por un sprint saludable y nuestro rendimiento
Para que la empresa realice un seguimiento de los diferentes indicadores, escribimos un pequeño sistema de Tablero de instrumentos en tiempo real. Inicialmente, se hizo con un propósito diferente. El negocio tiene un plan para la cantidad de pedidos que queremos vender en un día específico del próximo mes. Este sistema muestra el cumplimiento de los planes con lo que se hizo de hecho. Para el gráfico, toma datos de la base de datos de producción y los lee sobre la marcha.
Una vez que nuestra réplica se vino abajo. No hubo monitoreo, por lo que no tuvimos tiempo de averiguarlo. Pero el negocio vio que no estábamos cumpliendo el plan para 10 unidades convencionales de pedidos y comenzó a hacer comentarios. Comenzamos a descubrir las razones. Resultó que se estaban leyendo datos irrelevantes de la réplica rota. Este es un caso en el que una empresa observa indicadores interesantes y nos ayudamos mutuamente cuando surgen problemas.
Te contaré sobre otro monitoreo del mundo real, que ha estado en desarrollo durante mucho tiempo y que cada equipo está constantemente ajustando. Tenemos un visor Jira: le permite monitorear el proceso de desarrollo. El sistema es extremadamente simple: el framework PHP de Symfony, que se ejecuta en Jira Api y recoge datos sobre tareas, sprints, etc., dependiendo de lo que se le haya dado a la entrada. Jira Viewer escribe regularmente métricas relacionadas con los equipos y sus proyectos en Prometeus. Allí son monitoreados, alertas, y desde allí se muestran en Grafana. Gracias a este sistema, seguimos el trabajo en progreso.
- Monitoreamos cuánto tiempo ha estado trabajando una tarea desde el momento en progreso hasta su implementación. Si el número es demasiado grande, en teoría, esto indica un problema con los procesos, el equipo, las descripciones de tareas, etc. La vida de una tarea es una métrica importante, pero no suficiente en sí misma.
- . , , . , .
- – ready for release, . - - , « ».
- : , . .
- . 400 150. , , .
- Supervisé en mi equipo la cantidad de solicitudes de extracción de los desarrolladores fuera del horario laboral. Particularmente después de las 8pm. Y cuando la métrica se dispara, esta es una señal alarmante: una persona no tiene tiempo para algo o invierte demasiado esfuerzo y tarde o temprano simplemente se agotará.
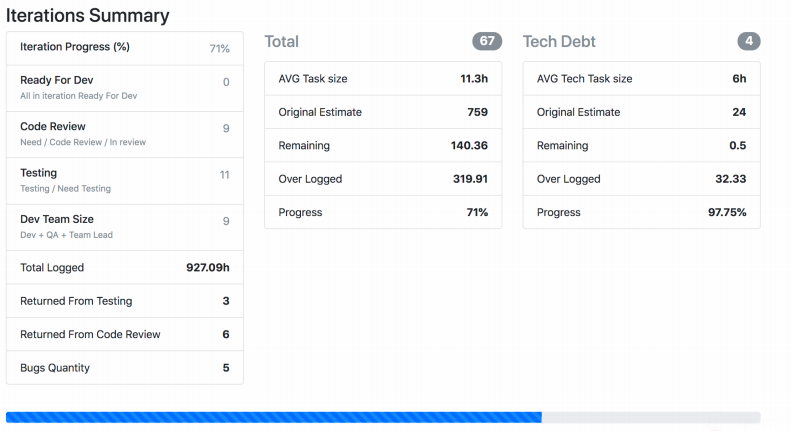
La captura de pantalla muestra cómo Jira Viewer muestra los datos. Esta es una página donde hay un resumen de los estados de las tareas del sprint, cuánto pesa cada uno y cosas similares. Tales cosas también se reúnen y vuelan a Prometeo.
No solo métricas técnicas: lo que ya monitoreamos, lo que podemos monitorear y por qué todo esto es necesario
Para poner todo esto junto, propongo monitorear juntos tanto la tecnología como las métricas relacionadas con los procesos, el desarrollo y los negocios. Las métricas técnicas por sí solas no son suficientes.
- , -, Grafana-. . , , .
- : , . , , crontab supervisor. . , , .
- – , , .
- : , - , . , .
- , . – Sentry . - , . - , . Sentry , , .
- . , , .
- , . , - , - . .