
Mirando hacia atrás, puedo decir que todas las acciones de colocación desde entonces son movimientos forzados. Y solo ahora, en el decimoquinto año, podemos configurar la infraestructura de la manera que la necesitamos.
Ahora estamos parados en 4 centros de datos físicamente diferentes conectados por un anillo óptico oscuro, colocando 5 grupos de recursos independientes allí. Y sucedió que si un meteorito golpea una de las cruces, entonces 3 de estos estanques se caerán inmediatamente, y los dos restantes no tirarán de la carga. Entonces comenzamos un reequilibrio completo para poner las cosas en orden.
Primer centro de datos
Al principio no había ningún centro de datos. Había un viejo sistemaista en el dormitorio de la Universidad Estatal de Moscú. Luego, casi de inmediato - alojamiento compartido en Masterhost (todavía están vivos, demonios). El tráfico del sitio web con un horario de trenes se duplicó cada 4 semanas, por lo que muy pronto cambiamos a KVM-VPS, sucedió alrededor de 2005. En algún momento, nos topamos con restricciones de tráfico, porque entonces era necesario mantener un equilibrio entre entrantes y salientes. Tuvimos dos instalaciones y cambiamos un par de archivos pesados de uno a otro todas las noches para mantener las proporciones requeridas.
En marzo de 2009 solo había VPS... Esto es algo bueno, decidimos cambiar a colocación. Compramos un par de servidores físicos de hierro (uno de ellos es el de la pared, cuyo cuerpo almacenamos como memoria). Pusieron a Fiord en el centro de datos (y todavía están vivos, pequeños demonios). ¿Por qué? Como no estaba lejos de la oficina de entonces, me recomendó un amigo, y tuve que levantarme rápidamente. Además, era relativamente barato.
Compartir la carga entre los servidores era simple: cada uno tenía un back-end, MySQL con replicación maestro-esclavo, el frente estaba en el mismo lugar que la réplica. Bueno eso es casi sin división por tipo de carga. Muy pronto también comenzaron a extrañarse, compraron un tercero.
Alrededor del 1 de octubre de 2009, nos dimos cuenta de que ya hay más servidores, pero tendremos un nuevo año.. Las previsiones de tráfico mostraron que la capacidad posible se cortará con un margen. Y nos basamos en el rendimiento de la base de datos. Hubo un mes y medio para prepararse antes del crecimiento del tráfico. Este fue el momento de las primeras optimizaciones. Compramos un par de servidores exclusivamente para la base de datos. Se centraron en discos rápidos con una velocidad de rotación de 15krpm (no recuerdo la razón exacta por la que no usamos SSD, pero lo más probable es que tuvieran un límite bajo en el número de escrituras, y al mismo tiempo cuestan como un avión). Dividimos las bases de datos frontales, posteriores, modificamos la configuración de nginx, MySQL, realizamos una resección para optimizar las consultas SQL. Sobrevivió.

Ahora estamos en un par de centros de datos Tier-III y en Tier-II por UI (con un swing en T3, pero sin certificados) Pero Fiord nunca fue un T-II. Tuvieron problemas con la capacidad de supervivencia, hubo situaciones de la categoría "todos los cables de alimentación están en un colector, y hay un incendio, y el generador estuvo funcionando durante tres horas". En general, decidimos mudarnos.
Eligió otro centro de datos, Caravan... Reto: ¿cómo mover servidores sin tiempo de inactividad? Decidimos vivir en dos centros de datos por un tiempo. El beneficio del tráfico dentro del sistema en ese momento no era tanto como ahora, era posible conducir el tráfico VPN entre ubicaciones durante algún tiempo (especialmente fuera de temporada). Hizo un equilibrio de tráfico. Poco a poco aumentamos la participación de la Caravana, después de un tiempo nos mudamos completamente allí. Y ahora nos queda un centro de datos. Y necesitamos dos, ya entendimos esto, gracias a las fallas en Fiord. Mirando hacia atrás en esos tiempos, puedo decir que TIER III tampoco es una panacea, la supervivencia será de 99.95, pero la accesibilidad es otra. Por lo tanto, un centro de datos definitivamente no es suficiente para una disponibilidad de 99.95 y superior. Stordata fue
elegida segunda, y ya existía la posibilidad de un enlace óptico con el sitio de Caravan. Logramos estirar la primera vena. Acaba de comenzar a cargar un nuevo centro de datos, ya que la Caravana anunció que tenían un trasero. Tuvieron que abandonar el sitio porque el edificio está siendo demolido. Ya. ¡Sorpresa! Hay un nuevo sitio, proponen extinguir todo, levantar los bastidores con equipos con grúas (entonces ya teníamos 2.5 bastidores de hierro), traducir, encenderlo y todo funcionará ... 4 horas para todo ... cuentos de hadas ... Ya estoy en silencio porque incluso tenemos una hora de tiempo de inactividad no encajaba, pero aquí la historia se habría prolongado durante al menos un día. Y todo esto se presentó en el espíritu de "¡Todo se ha ido, se retira el yeso, el cliente se va!". El 29 de septiembre es la primera llamada, y el 10 de octubre querían recoger todo y tomarlo. Durante 3-5 días tuvimos que desarrollar un plan de mudanza, y en 3 etapas,apagando 1/3 del equipo a la vez con total preservación del servicio y tiempo de actividad, transporte los autos a Stordata. Como resultado, el tiempo de inactividad fue de 15 minutos en uno de los servicios no más críticos.
Así que nuevamente nos quedamos con un centro de datos.
En este momento, estamos cansados de pasar el rato con los servidores bajo el brazo y jugar motores. Además, cansado de lidiar con el hardware en el centro de datos. Comenzaron a mirar hacia las nubes públicas.
De 2 a 5 (casi) centros de datos
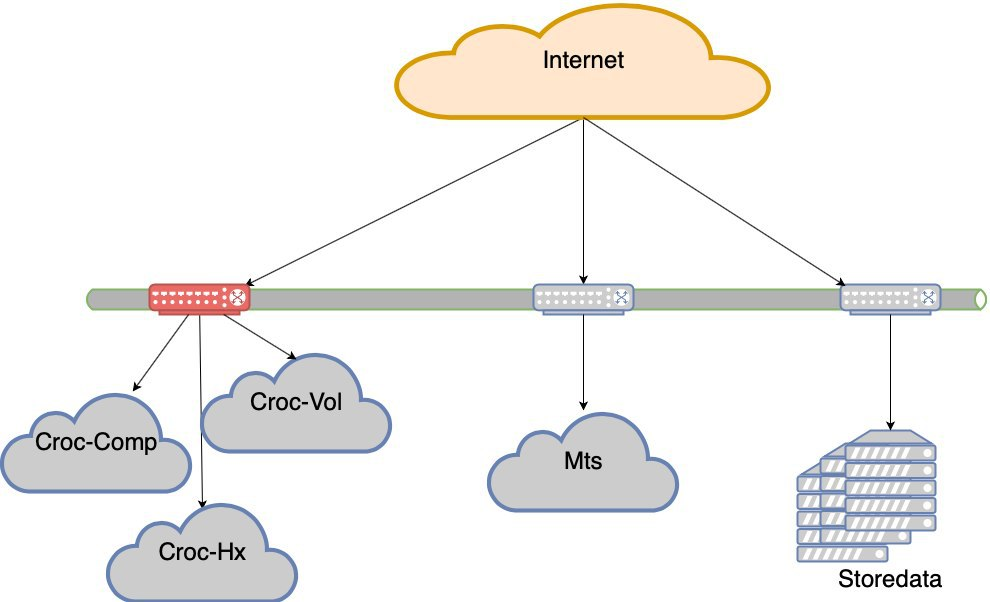
Comenzamos a buscar opciones con nubes. Fuimos a Krok, probamos, probamos, acordamos las condiciones. Entramos en la nube, que está en el centro de datos de Compressor. Hicieron un anillo de óptica oscura entre Stordata, Compressor y la oficina. En todas partes su propio enlace ascendente y dos brazos de óptica. Cortar cualquiera de los rayos no destruye la red. La pérdida de un enlace ascendente no destruye la red. Tiene estado de LIR, tiene su propia subred, anuncios de BGP, redundancia de red, belleza. No describiré exactamente cómo entraron en la nube desde el punto de vista de la red, pero hubo matices.
Entonces tenemos 2 centros de datos.
Krok también tiene un centro de datos en Volochaevskaya, expandieron su nube allí y ofrecieron transferir parte de nuestros recursos allí. Pero al recordar la historia de la Caravana, que, de hecho, nunca se recuperó después de la demolición del centro de datos, quise tomar recursos en la nube de diferentes proveedores para reducir el riesgo de que la compañía dejara de existir (el país es tal que no se puede ignorar ese riesgo). Por lo tanto, no se involucraron con Volochaevskaya en ese momento. Bueno, el segundo vendedor también hace magia con los precios. Porque cuando puede recoger y salir elásticamente, le da una fuerte posición negociadora sobre los precios.
Analizamos diferentes opciones, pero la elección recayó en #CloudMTS. Hubo varias razones para esto: la nube en las pruebas demostró ser buena, los chicos también saben cómo trabajar con la red (operador de telecomunicaciones, después de todo) y la política de marketing muy agresiva de capturar el mercado, como resultado, precios interesantes.
Total 3 centros de datos.
Luego, de todos modos, también conectamos Volochaevskaya: se necesitaban recursos adicionales y en Compressor ya estaba un poco abarrotado. En general, redistribuimos la carga entre las tres nubes y nuestro equipo en el Stordat.
4 centros de datos. Y ya en términos de supervivencia, T3 está en todas partes. Parece que no todos tienen certificados, pero no lo diré con certeza.
MTS tenía un matiz. Nada más que MGTS podría ir allí la última milla. Al mismo tiempo, no fue posible extraer la óptica oscura de MGTS por completo del centro de datos al centro de datos (durante un tiempo largo y costoso, y si no lo confundo, no proporcionan dicho servicio). Tuve que hacerlo con una junta, emitir dos haces desde el centro de datos a los pozos más cercanos, donde está nuestro proveedor de óptica oscura Mastertel. Tienen una extensa red de ópticas en toda la ciudad y, en todo caso, solo sueldan la ruta deseada y te dan una veta. Mientras tanto, la Copa del Mundo llegó a la ciudad, inesperadamente, como la nieve en invierno, y el acceso a los pozos en Moscú estaba cerrado. Estábamos esperando que este milagro terminara, y podemos lanzar nuestro enlace. Parecería que era necesario abandonar el centro de datos MTS con la óptica en la mano, silbando para alcanzar la escotilla deseada y bajarla allí. Condicionalmente Hicieron tres meses y medio. Más precisamente, el primer rayo se hizo bastante rápido,a principios de agosto (recuerdo que la Copa del Mundo terminó el 15 de julio). Pero tuve que jugar con mi segundo hombro: la primera opción implicaba que teníamos que cavar la carretera Kashirskoye, por lo que tuvimos que bloquearla durante una semana (había un túnel en la reconstrucción donde había algunas comunicaciones, tuvimos que cavar). Afortunadamente, encontramos una alternativa: otra ruta, la misma geoindependiente. Resultó dos vetas de este centro de datos a diferentes puntos de nuestra presencia. El anillo óptico se ha convertido en un anillo con asa.Resultó dos vetas de este centro de datos a diferentes puntos de nuestra presencia. El anillo óptico se ha convertido en un anillo con asa.Resultó dos vetas de este centro de datos a diferentes puntos de nuestra presencia. El anillo óptico se ha convertido en un anillo con asa.
Corriendo un poco más adelante, diré que nos lo pusieron de todos modos. Afortunadamente, al comienzo de la operación, cuando se transfirió poco. Se produjo un incendio en un pozo, y mientras los instaladores juraban en espuma, en el segundo pozo alguien sacó un conector para mirar (de alguna manera era un nuevo diseño, me pregunto). Matemáticamente, la probabilidad de una falla simultánea fue insignificante. De hecho, lo atrapamos. En realidad, tuvimos suerte en el fiordo: la comida principal se cortó allí y, en lugar de volver a encenderla, alguien mezcló el interruptor y apagó la línea de respaldo.
No solo había requisitos técnicos para distribuir la carga entre ubicaciones: no hay milagros, y una política de comercialización agresiva con buenos precios implica una cierta tasa de crecimiento en el consumo de recursos. Así que tuvimos en cuenta el porcentaje de recursos que deben enviarse a MTS. Redistribuimos todo lo demás entre otros centros de datos de manera más o menos uniforme.
Tu plancha otra vez
La experiencia de usar nubes públicas nos ha demostrado que son convenientes de usar cuando necesita agregar recursos rápidamente, para experimentos, para un piloto, etc. Cuando se usa bajo carga constante, resulta más costoso que torcer su plancha. Pero ya no podíamos abandonar la idea de contenedores, migraciones sin problemas de máquinas virtuales dentro de un clúster, etc. Escribieron automatización para extinguir algunos de los autos por la noche, pero aún así la economía no funcionó. No teníamos suficiente competencia para soportar una nube privada, tuvimos que hacerla crecer.
Estábamos buscando una solución que le permitiera obtener una nube en su hardware con relativa facilidad. En ese momento, nunca trabajamos con servidores Cisco, solo con una pila de red, esto era un riesgo. En Dells, es un hierro simple y conocido, confiable como un rifle de asalto Kalashnikov. Hemos tenido esto durante años, y todavía existe en alguna parte. Pero la idea detrás de Hyperflex es que admite hiperconvergencia de la solución final lista para usar. Y en Della todo vive en enrutadores ordinarios, y hay matices. En particular, el rendimiento no es tan bueno como en las presentaciones debido a la sobrecarga. Quiero decir, se pueden configurar correctamente y será súper, pero decidimos que este no es nuestro negocio y dejamos que Dell esté preparado por aquellos que consideran esta vocación. Como resultado, elegimos Cisco Hyperflex. Esta opción ganó en conjunto como la más interesante: menos hemorroides en configuración y operación,y durante las pruebas todo estuvo bien. En el verano de 2019, lanzamos el clúster a la batalla. Teníamos un estante medio vacío en el compresor, ocupado en su mayor parte solo con equipos de red, y lo colocamos allí. Por lo tanto, obtuvimos el quinto "centro de datos": físicamente cuatro, pero cinco por los grupos de recursos.
Tomaron, calcularon el volumen de la carga constante y el volumen de la variable. Permanente convertido en una carga sobre su hierro. Pero para que a nivel de equipo proporcione ventajas en la nube en tolerancia a fallas y redundancia.
La recuperación del proyecto de hierro está en los precios promedio de nuestras nubes para el año.
Estás aquí
En este momento, terminamos los movimientos forzados. Como puede ver, no teníamos muchas opciones económicas, y cargamos constantemente lo que teníamos que defender por alguna razón. Esto condujo a una situación extraña de que la carga es desigual. La falla de cualquier segmento (y el segmento con los centros de datos de Croc está en manos de dos Nexuses en un cuello de botella) es una pérdida de la experiencia del usuario. Es decir, el sitio se preservará, pero habrá dificultades obvias con la accesibilidad.
Hubo una falla en MTS con todo el centro de datos. Había dos más en los otros. De vez en cuando, se caían las nubes, o los controladores de la nube, o surgía algún problema complejo de red. En resumen, perdemos centros de datos de vez en cuando. Sí, brevemente, pero aún desagradable. En algún momento, se dio por sentado que los centros de datos se están cayendo.
Decidimos optar por la tolerancia a fallas a nivel del centro de datos.
Ahora no nos acostaremos si falla uno de los 5 centros de datos. Pero si perdemos el hombro de Croc, habrá desventajas muy serias. Así nació el proyecto de tolerancia a fallas de los centros de datos. El objetivo es este: si el DC muere, la red muere antes o el equipo muere, el sitio debe funcionar sin intervención manual. Además, después del accidente, tenemos que recuperarnos regularmente.
¿Cuáles son las trampas?
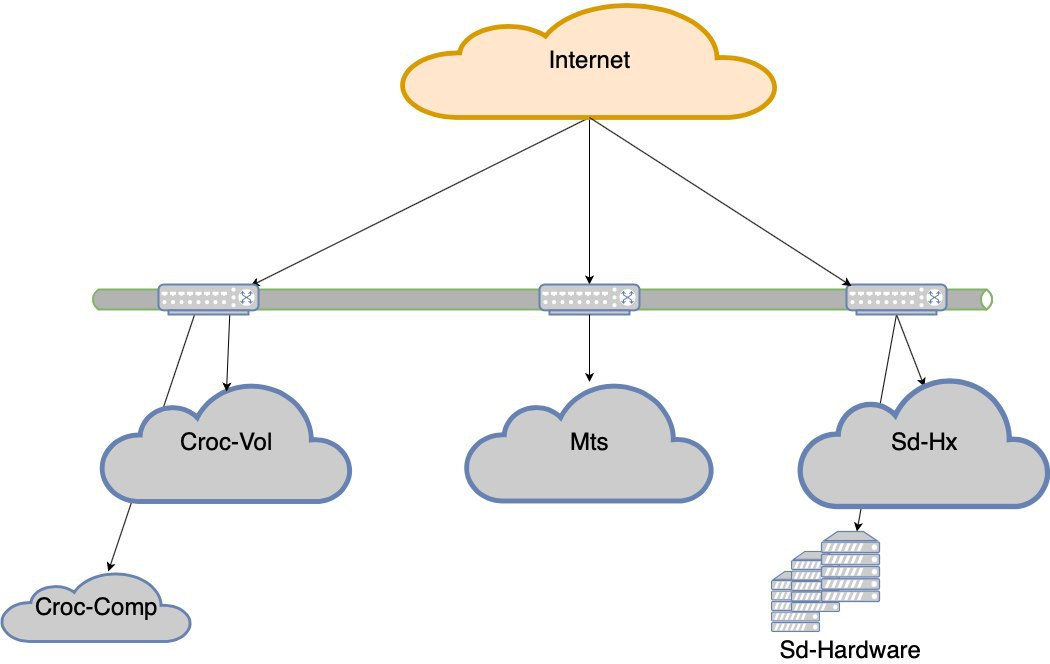
Ahora:
Necesitar:
Ahora:
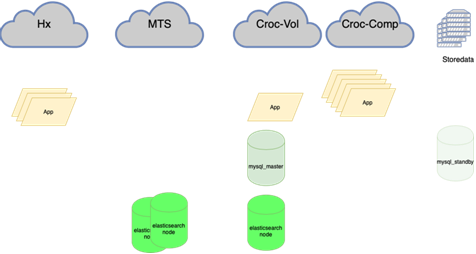
Necesitar:
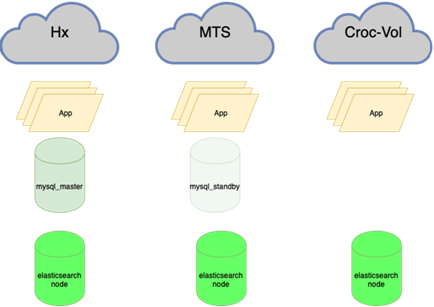
El elástico es resistente a la pérdida de un nodo:
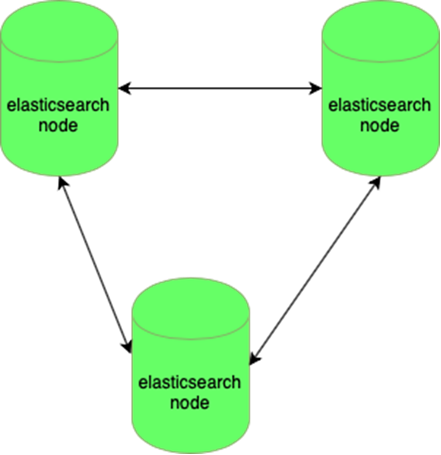
Las bases de datos MySQL (muchas pequeñas) son difíciles de administrar:
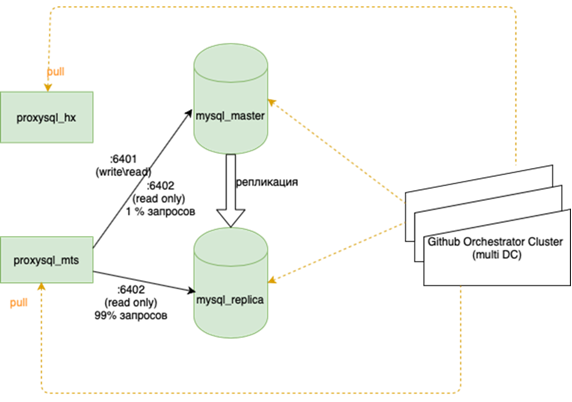
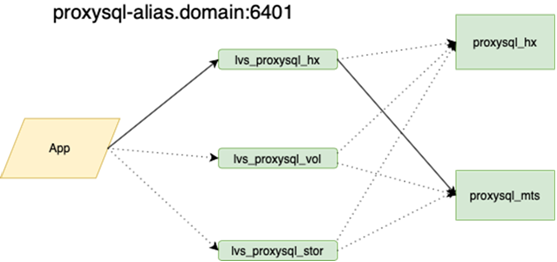
Acerca de esto está mejor escrito con más detalle por mi colega que hizo el balance. Lo importante es que antes de colgarlo, si perdimos al maestro, teníamos que ir a la reserva con nuestras manos y marcar la casilla r / o = 0, reconstruir todas las réplicas con este conjunto, y hay más de dos en la guirnalda principal docenas, cambie las configuraciones de la aplicación, luego despliegue las configuraciones y espere las actualizaciones. Ahora la aplicación se ejecuta en un anycast-ip, que analiza el equilibrador LVS. La configuración permanente no cambia. Toda la topología de bases en la orquesta.
Ahora, la óptica oscura se extiende entre nuestros centros de datos, lo que nos permite acceder a cualquier recurso dentro de nuestro anillo como local. El tiempo de respuesta entre los centros de datos y el tiempo dentro de más o menos son los mismos. Esta es una diferencia importante con respecto a otras compañías que construyen geoclusters. Estamos muy vinculados a nuestro hardware y nuestra red, y no intentamos localizar solicitudes dentro del centro de datos. Esto es genial, por un lado, y por otro lado, si queremos ir a Europa o China, no sacaremos nuestra óptica oscura.
Esto significa reequilibrar casi todo, principalmente las bases de datos. Hay muchos esquemas, cuando el maestro activo retiene toda la carga tanto para leer como para escribir, y al lado hay una réplica sincrónica para un cambio rápido (no escribimos en dos a la vez, pero replicamos, de lo contrario no funciona muy bien). La base principal está en un centro de datos y la réplica está en otro. También puede haber copias parciales en el tercero para aplicaciones individuales. Hay de 10 a 15 casos, dependiendo de la temporada. Orchestrator es un clúster extendido entre centros de datos y 3 centros de datos. Aquí le diremos más en detalle cuando tenga la fuerza para describir cómo suena toda esta música.
Tendrá que profundizar en las aplicaciones. Esto ahora es necesario: a veces sucede que si la conexión se interrumpe, es correcto cancelar la antigua, abrir una nueva. Pero a veces las solicitudes a una conexión ya perdida se repiten en un bucle hasta que el proceso muere. Lo último que se captó fue la tarea de la corona, no se escribió un recordatorio sobre el tren.
En general, aún queda mucho por hacer, pero el plan es claro.