¿Qué es el habla humana? Estas son palabras, cuyas combinaciones le permiten expresar esta o aquella información. Surge la pregunta, ¿cómo sabemos cuándo termina una palabra y comienza otra? La pregunta es bastante extraña, muchos pensarán, porque desde el nacimiento escuchamos el discurso de las personas que nos rodean, aprendemos a hablar, escribir y leer. El equipaje acumulado de conocimiento lingüístico, por supuesto, juega un papel importante, pero además existen redes neuronales del cerebro que dividen el flujo del habla en palabras componentes y / o sílabas. Hoy nos reuniremos con usted en un estudio en el que científicos de la Universidad de Ginebra (Suiza) crearon un modelo de neurocomputadora para decodificar el habla prediciendo palabras y sílabas. Qué procesos cerebrales se convirtieron en la base del modelo, lo que se entiende por la gran palabra "predicción",y qué tan efectivo es el modelo creado? Las respuestas a estas preguntas nos esperan en el informe de los científicos. Vamos.
Bases de investigacion
Para nosotros los humanos, el habla humana es bastante comprensible y articulada (con mayor frecuencia). Pero para un automóvil, esto es solo un flujo de información acústica, una señal continua que debe decodificarse antes de ser entendida.
El cerebro humano actúa de la misma manera, simplemente sucede de manera extremadamente rápida e imperceptible para nosotros. Los científicos creen que la base de este y muchos otros procesos cerebrales son ciertas oscilaciones neuronales, así como sus combinaciones.
En particular, el reconocimiento de voz se asocia con una combinación de oscilaciones theta y gamma, ya que permite coordinar jerárquicamente la codificación de fonemas en sílabas sin conocimiento previo de su duración y ocurrencia temporal, es decir. procesamiento ascendente * en tiempo real.
* (bottom-up) — , .El reconocimiento de voz natural también depende en gran medida de las señales contextuales para predecir el contenido y la estructura temporal de la señal de voz. Estudios previos han demostrado que el mecanismo de predicción juega un papel importante durante la percepción del habla continua. Este proceso está asociado con las vibraciones beta.
Otro componente importante del reconocimiento de las señales del habla puede llamarse codificación predictiva, cuando el cerebro genera y actualiza constantemente el modelo mental del entorno. Este modelo se utiliza para generar predicciones táctiles que se comparan con la entrada táctil real. La comparación de la señal predicha y la real conduce a la identificación de errores que sirven para actualizar y revisar el modelo mental.
En otras palabras, el cerebro siempre está aprendiendo algo nuevo, actualizando constantemente el modelo del mundo circundante. Este proceso se considera crítico en el procesamiento de señales de voz.
Los investigadores señalan que muchos estudios teóricos respaldan tanto el enfoque ascendente como el descendente * para el procesamiento del habla.
Procesamiento de arriba hacia abajo * (de arriba hacia abajo ): análisis del sistema en sus componentes para tener una idea de sus subsistemas de composición mediante ingeniería inversa.Un modelo de neurocomputadora desarrollado previamente, que involucra la combinación de redes theta y gamma excitatorias / inhibidoras realistas, fue capaz de preprocesar el habla para que luego pudiera decodificarse correctamente.
Otro modelo, basado únicamente en la codificación predictiva, podría reconocer con precisión elementos del habla individuales (como palabras u oraciones completas si se consideran como un solo elemento del habla).
Por lo tanto, ambos modelos funcionaron, solo en diferentes direcciones. Uno se centró en el aspecto del análisis del habla en tiempo real y el otro se centró en el reconocimiento de segmentos de habla aislados (no se requiere análisis).
Pero, ¿qué pasa si combinamos los principios básicos de estos modelos radicalmente diferentes en uno? Según los autores del estudio que estamos considerando, esto mejorará el rendimiento y aumentará el realismo biológico de los modelos de procesamiento del habla por neurocomputadora.
En su trabajo, los científicos decidieron probar si un sistema de reconocimiento de voz basado en codificación predictiva puede obtener algún beneficio de los procesos de las oscilaciones neuronales.
Desarrollaron el modelo de computadora neural Precoss (a partir de la codificación predictiva y las oscilaciones para el habla ) basado en la estructura de codificación predictiva, que agregó funciones theta y gamma-vibracionales para hacer frente a la naturaleza continua del habla natural.
El propósito específico de este trabajo fue encontrar la respuesta a la pregunta de si una combinación de codificación predictiva y oscilaciones neuronales puede ser beneficiosa para la identificación rápida de componentes silábicos de oraciones naturales. En particular, se consideraron los mecanismos por los cuales las ondas theta pueden interactuar con los flujos de información aguas arriba y aguas abajo, y se evaluó el impacto de esta interacción en la eficiencia del proceso de decodificación de sílabas.
Modelos de arquitectura Precoss
Una función importante del modelo es que debe ser capaz de usar las señales temporales / información presente en el habla continua para determinar los límites de la sílaba. Los científicos han sugerido que los modelos generativos internos, incluidas las predicciones temporales, deberían beneficiarse de tales señales. Para acomodar esta hipótesis, así como los procesos repetitivos que ocurren durante el reconocimiento de voz, se utilizó un modelo de codificación predictiva continua.
El modelo desarrollado separa claramente "qué" y "cuándo". "Qué" se refiere a la identidad de una sílaba y su representación espectral (no temporal, sino secuencia ordenada de vectores espectrales); "Cuando" se refiere a predecir el tiempo y la duración de las sílabas.
Como resultado, los pronósticos toman dos formas: el comienzo de una sílaba, señalada por el módulo theta; y duración de la sílaba, señalada por oscilaciones theta exógenas / endógenas, que definen la duración de la secuencia unitaria sincronizada con rayos gamma (diagrama a continuación).
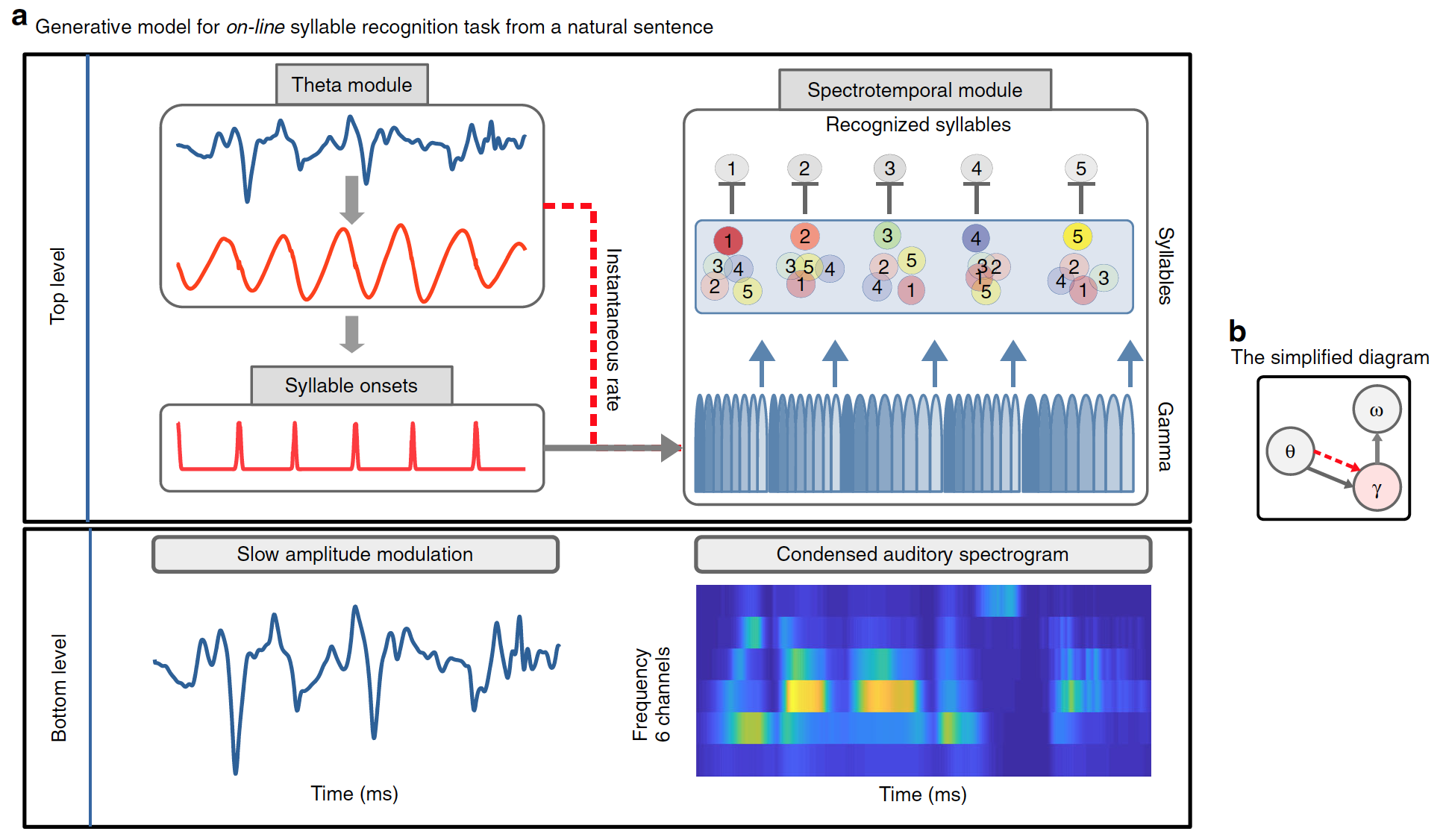
Imagen # 1
Precoss extrae una señal sensorial de las representaciones internas de su fuente al referirse a un modelo generativo. En este caso, la entrada táctil corresponde a la modulación de amplitud lenta de la señal de voz y al espectrograma auditivo de 6 canales de la oración natural completa, que el modelo genera internamente a partir de cuatro componentes:
- theta swing;
- bloque de modulación de amplitud lenta en el módulo theta;
- conjunto de unidades de sílabas (tantas sílabas como están presentes en la oración introductoria natural, es decir, de 4 a 25);
- banco de ocho unidades gamma en el módulo espectrotemporal.
Juntas, las unidades de sílabas y la forma de onda gamma generan predicciones de arriba hacia abajo sobre el espectrograma de entrada. Cada una de las ocho unidades gamma representa una fase en una sílaba; se activan secuencialmente y se repite toda la secuencia de activación. Por lo tanto, cada unidad de una sílaba está asociada con una secuencia de ocho vectores (uno por unidad gamma) con seis componentes cada uno (uno por canal de frecuencia). El espectrograma acústico de una sílaba individual se genera activando la unidad de sílaba correspondiente a lo largo de la duración de la sílaba.
Mientras que el bloque de sílabas codifica un patrón acústico específico, los bloques gamma utilizan temporalmente la predicción espectral correspondiente durante la duración de la sílaba. La onda theta proporciona información sobre la longitud de una sílaba, ya que su velocidad instantánea afecta la velocidad / duración de la secuencia gamma.
Finalmente, los datos acumulados en la sílaba prevista deben eliminarse antes de procesar la siguiente sílaba. Para hacer esto, el último (octavo) bloque gamma, que codifica la última parte de la sílaba, restablece todas las unidades de sílaba a un bajo nivel general de activación, lo que le permite recopilar nuevas pruebas.
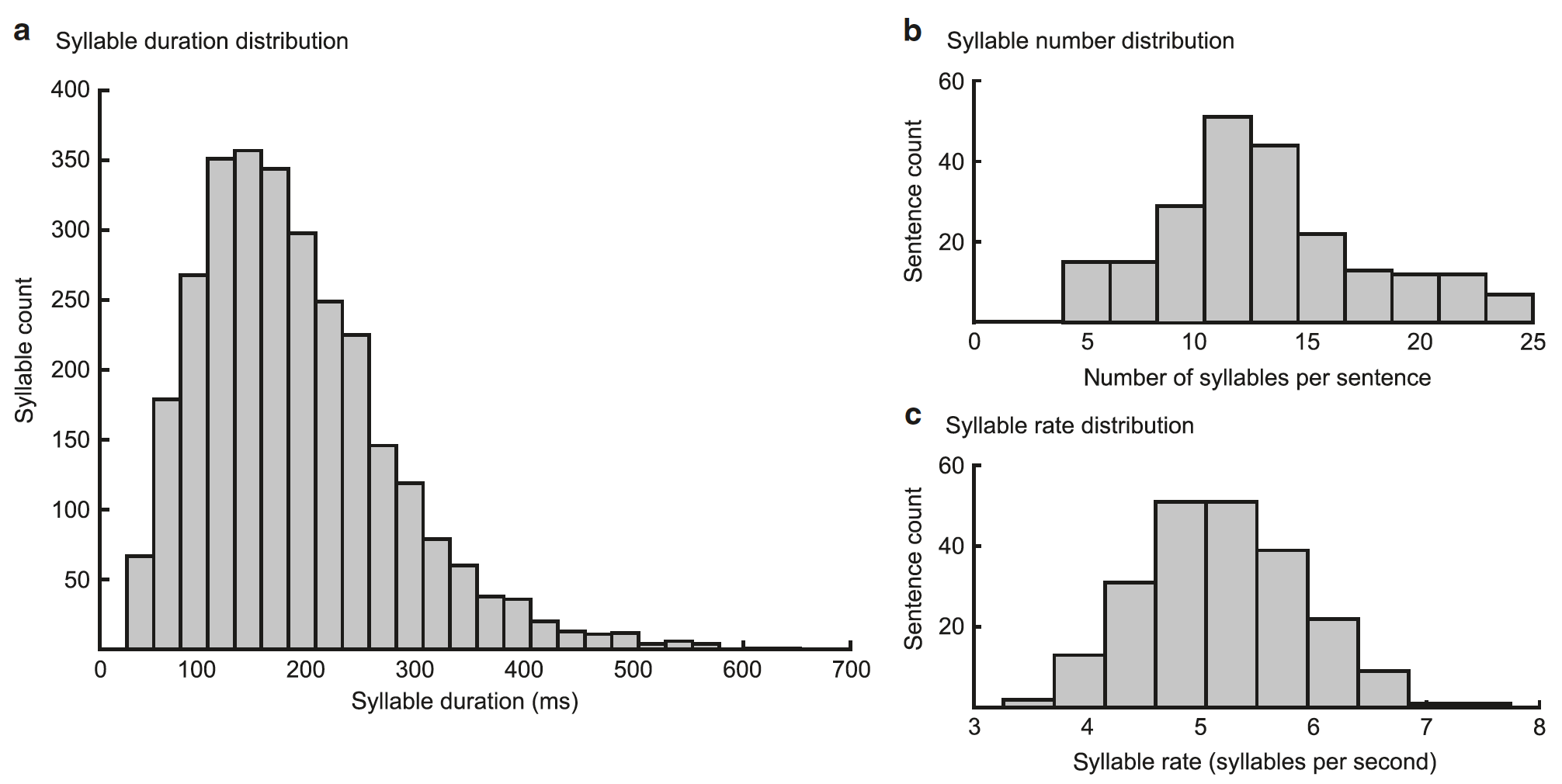
Imagen No. 2
El rendimiento del modelo depende de si la secuencia gamma coincide con el comienzo de una sílaba y si su duración coincide con la duración de una sílaba (50–600 ms, promedio = 182 ms).
La evaluación del modelo en relación con la secuencia de sílabas es proporcionada por unidades de sílabas que, junto con las unidades gamma, generan los patrones espectral-temporales esperados (el resultado del modelo), que se comparan con el espectrograma introductorio. El modelo actualiza sus estimaciones sobre la sílaba actual para minimizar la diferencia entre el espectrograma generado y el real. El nivel de actividad aumenta en aquellas unidades de sílabas cuyo espectrograma corresponde a la entrada sensorial, y disminuye en otras. Idealmente, minimizar el error de predicción en tiempo real conduce a una mayor actividad en una unidad distinta de la sílaba correspondiente a la sílaba de entrada.
Resultados de la simulación
El modelo presentado anteriormente incluye oscilaciones theta motivadas fisiológicamente, que se controlan mediante modulaciones de amplitud lenta de la señal de voz y transmiten información sobre el comienzo y la duración de la sílaba al componente gamma.
Esta relación theta-gamma proporciona una alineación temporal de las predicciones generadas internamente con los límites de las sílabas que se encuentran en los datos de entrada (opción A en la imagen # 3).
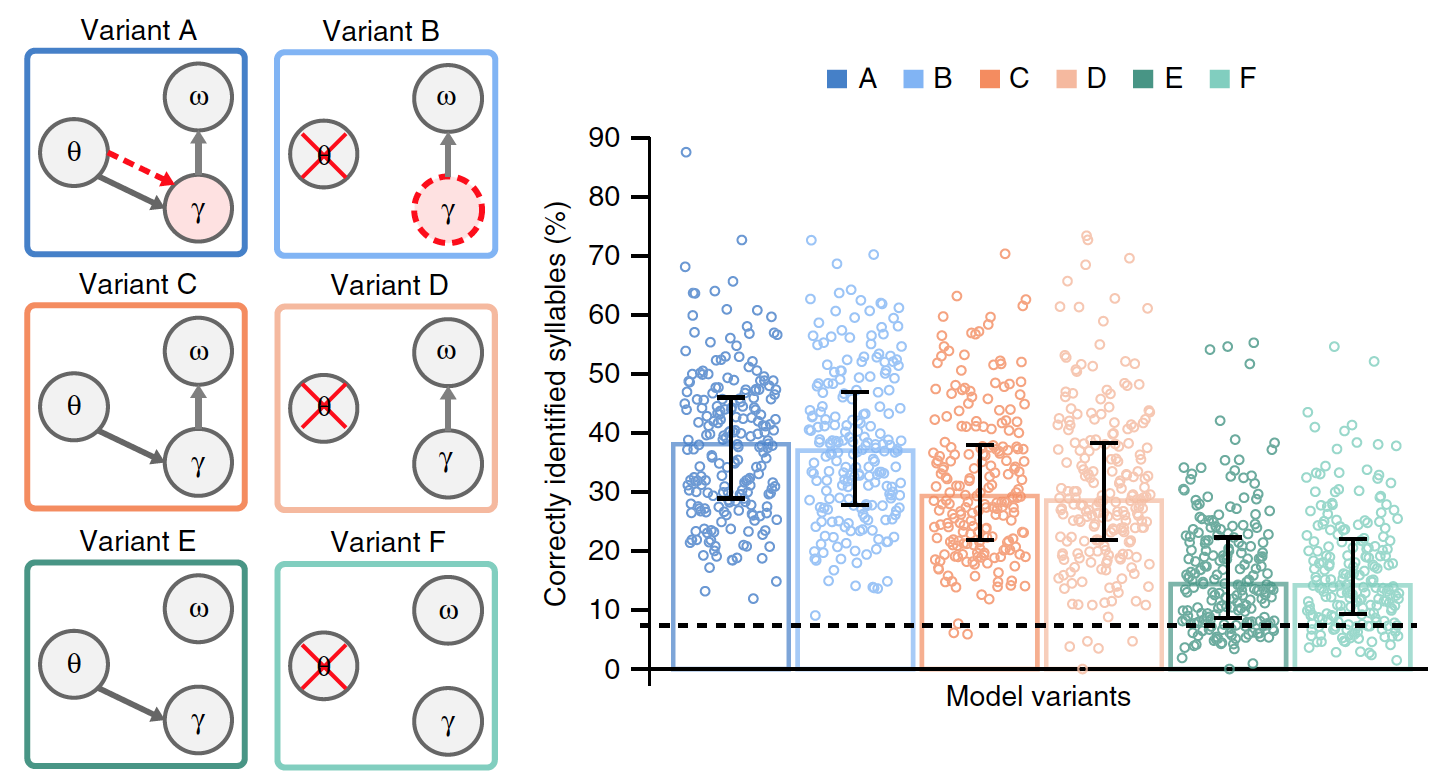
Imagen No. 3
Para evaluar la relevancia de la sincronización de sílabas basada en la modulación de amplitud lenta, comparamos el modelo A con la variante B, en la que la actividad theta no está modelada por oscilaciones, sino que surge de la auto-repetición de la secuencia gamma.
En el modelo B, la duración de la secuencia gamma ya no se controla de manera exógena (debido a factores externos) por oscilaciones theta, sino que utiliza endógenamente (debido a factores internos) la frecuencia gamma preferida, que, cuando se repite la secuencia, conduce a la formación de un ritmo theta interno. Como en el caso de las oscilaciones theta, la duración de la secuencia gamma tiene una tasa preferida en el rango theta, que puede adaptarse potencialmente a diferentes longitudes de sílabas. En este caso, es posible probar el ritmo theta que surge de la repetición de la secuencia gamma.
Para evaluar con mayor precisión los efectos específicos de la theta gamma de la composición y el vertido de datos acumulados en unidades de sílaba, se realizaron versiones adicionales de los modelos anteriores A y B.
Las opciones C y D no tenían una tasa de gamma preferida. Las opciones E y F también diferían de las opciones C y D en ausencia de restablecer los datos acumulados en las sílabas.
De todas las variantes del modelo, solo A tiene una verdadera relación theta-gamma, donde la actividad gamma está determinada por el módulo theta, mientras que en el modelo B, la frecuencia gamma se establece de forma endógena.
Fue necesario establecer cuál de las variantes del modelo es la más efectiva, para lo cual se compararon los resultados de su trabajo en presencia de datos de entrada comunes (oraciones naturales). El gráfico en la imagen de arriba muestra el rendimiento promedio de cada uno de los modelos.
Hubo diferencias significativas entre las opciones. En comparación con los modelos A y B, el rendimiento fue significativamente menor en los modelos E y F (23% en promedio) y C y D (15%). Esto indica que borrar los datos acumulados sobre la sílaba anterior antes de procesar la nueva sílaba es un factor crítico en la codificación del flujo de sílabas en el habla natural.
La comparación de las opciones A y B con las opciones C y D mostró que la conexión theta-gamma, ya sea estímulo (A) o endógeno (B), mejora significativamente el rendimiento del modelo (un promedio de 8.6%).
En términos generales, los experimentos con diferentes versiones de los modelos mostraron que funcionaba mejor cuando las unidades de sílaba se restablecían después de cada secuencia de unidades gamma (en base a la información interna sobre la estructura espectral de la sílaba), y cuando la tasa de radiación gamma se determinaba mediante el acoplamiento theta-gamma.
El rendimiento del modelo con oraciones naturales, por lo tanto, no depende de la señalización precisa del inicio de las sílabas por oscilaciones theta impulsadas por estímulos, ni del mecanismo preciso de la relación theta-gamma.
Como los propios científicos admiten, este es un descubrimiento bastante sorprendente. Por otro lado, la ausencia de diferencias en el rendimiento entre la vinculación theta-gamma impulsada por estímulos y endógena refleja el hecho de que la duración de las sílabas en el habla natural está muy cerca de las expectativas del modelo, en cuyo caso no habrá ventaja para la señal theta impulsada directamente por los datos de entrada.
Para comprender mejor un giro de eventos tan inesperado, los científicos realizaron otra serie de experimentos, pero con señales de voz comprimidas (x2 y x3). Como muestran los estudios de comportamiento, la comprensión del habla comprimida x2 prácticamente no cambia, pero disminuye drásticamente cuando se comprime 3 veces.
En este caso, la conexión estimulada theta-gamma puede ser extremadamente útil para analizar y decodificar sílabas. Los resultados de la simulación se presentan a continuación.

Imagen # 4
Como se esperaba, el rendimiento general disminuyó a medida que aumentó la relación de compresión. Para comprimir x2, todavía no había una diferencia significativa entre el estímulo y los enlaces theta-gamma endógenos. Pero en el caso de la compresión x3 hay una diferencia significativa. Esto sugiere que la oscilación theta impulsada por el estímulo, que conduce el enlace theta-gamma, fue más beneficiosa para el proceso de codificación de sílabas que la velocidad theta establecida endógenamente.
Se deduce que el habla natural puede procesarse usando un generador theta endógeno relativamente fijo. Pero para las señales de voz de entrada más complejas (es decir, cuando la velocidad de la voz cambia constantemente), se requiere un generador theta controlado que transmita información de tiempo precisa sobre las sílabas al codificador gamma (comienzo de la sílaba y duración de la sílaba).
La capacidad del modelo para reconocer con precisión las sílabas en la oración de entrada no tiene en cuenta la complejidad variable de los diversos modelos que se comparan. Por lo tanto, se evaluó un Criterio de Información Bayesiano (BIC) para cada modelo. Este criterio determina cuantitativamente el compromiso entre la precisión y la complejidad del modelo (imagen No. 5).
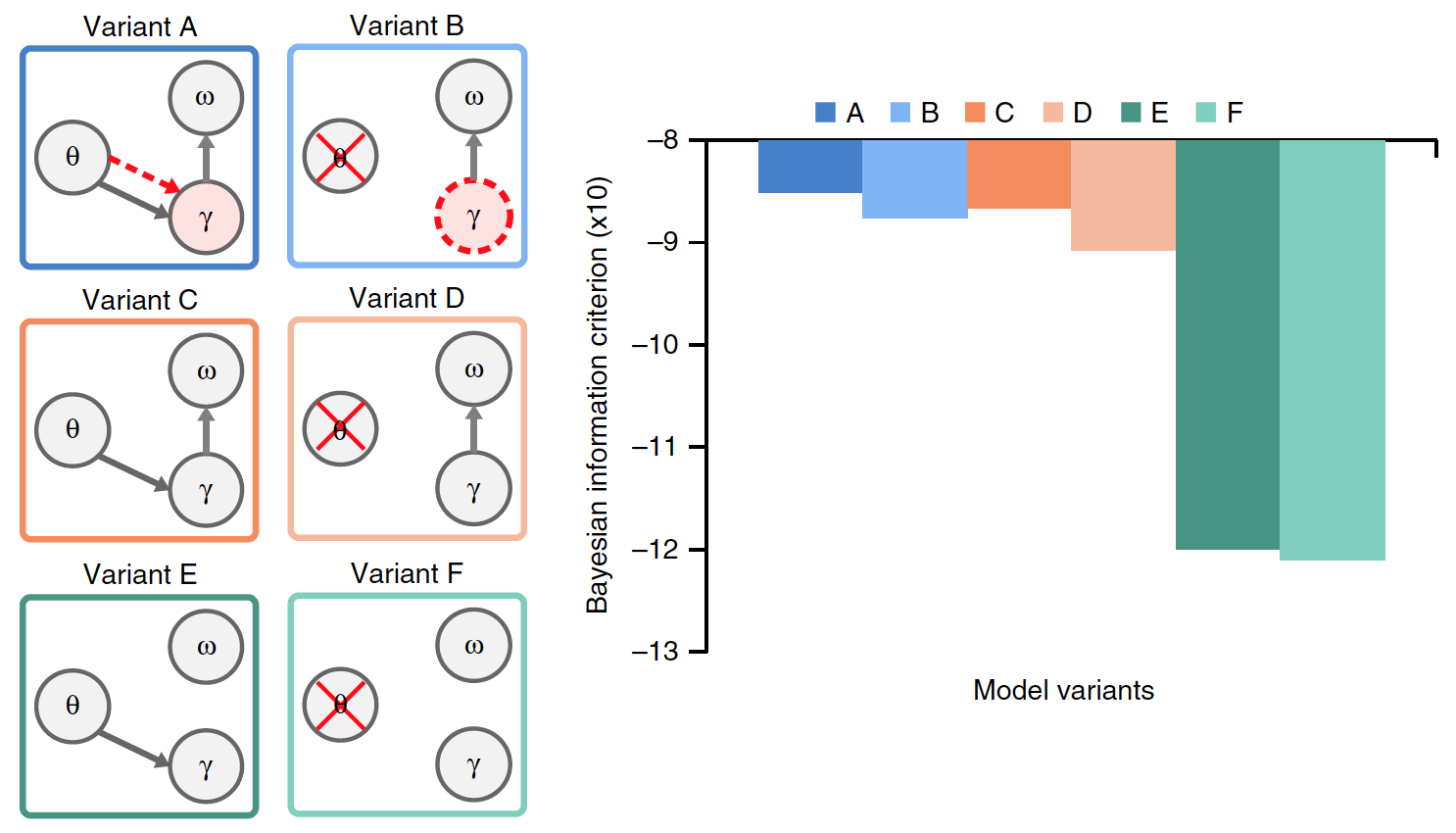
Imagen No. 5 La
opción A mostró los valores BIC más altos. Una comparación previa de los modelos A y B no pudo distinguir con precisión entre su rendimiento. Sin embargo, gracias al criterio BIC, quedó claro que la variante A proporciona un reconocimiento de sílaba más seguro que el modelo sin oscilaciones theta impulsadas por estímulos (modelo B).
Para un conocimiento más detallado de los matices del estudio, recomiendo consultar el informe de los científicos ymateriales adicionales a la misma.
Epílogo
Resumiendo los resultados anteriores, podemos decir que el éxito del modelo depende de dos factores principales. El primero y más importante es el restablecimiento de los datos acumulados en función de la información del modelo sobre el contenido de la sílaba (en este caso, es su estructura espectral). El segundo factor es la relación entre los procesos theta y gamma, lo que garantiza que la actividad gamma se incluya en el ciclo theta, correspondiente a la duración esperada de una sílaba.
En esencia, el modelo desarrollado imita el trabajo del cerebro humano. El sonido que ingresó al sistema fue modulado por una onda theta que se asemeja a la actividad de las neuronas. Esto le permite definir los límites de las sílabas. Además, las ondas gamma más rápidas ayudan a codificar la sílaba. En el proceso, el sistema sugiere posibles variantes de sílabas y corrige la elección si es necesario. Saltando entre el primer y el segundo nivel (theta y gamma), el sistema detecta la versión correcta de la sílaba y luego se pone a cero para comenzar el proceso para la siguiente sílaba.
Durante las pruebas prácticas, fue posible descifrar con éxito 2888 sílabas (se usaron 220 oraciones de habla natural, inglés).
Este estudio no solo combinó dos teorías opuestas, poniéndolas en práctica como un solo sistema, sino que también permitió comprender mejor cómo nuestro cerebro percibe las señales del habla. Nos parece que percibimos el discurso "como es", es decir sin ningún proceso de soporte complicado. Sin embargo, dados los resultados de la simulación, resulta que las oscilaciones theta neurales y gamma permiten que nuestro cerebro haga pequeñas predicciones sobre qué sílaba escuchamos, sobre la base de qué percepción del habla se forma.
Quien dice algo, pero el cerebro humano a veces parece mucho más misterioso e incomprensible que los rincones inexplorados del universo o las profundidades desesperadas de los océanos.
Gracias por su atención, tengan curiosidad y tengan una buena semana de trabajo, muchachos. :)
Algo de publicidad
Gracias por estar con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más contenido interesante? Apóyenos haciendo un pedido o recomendando a amigos, VPS en la nube para desarrolladores desde $ 4.99 , un análogo único de servidores de nivel de entrada, que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor correctamente? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd es 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡Desde $ 99! Lea sobre Cómo construir la infraestructura de bldg. clase con el uso de servidores Dell R730xd E5-2650 v4 que cuesta 9000 euros por un centavo?