La nota describe un experimento para crear una copia pequeña de un almacén de datos empresariales con especificaciones muy limitadas. A saber, basado en una computadora de placa única Raspberry Pi.
El modelo y la arquitectura se simplificarán, pero serán similares al almacenamiento empresarial. El resultado es una evaluación de la viabilidad del uso de Raspberry Pi en el procesamiento y análisis de datos.

# 1
La máquina Exadata X5 (una unidad) de Oracle Corporation desempeñará el papel de un jugador experimentado y fuerte.
El proceso de procesamiento de datos incluye los siguientes pasos:
- Lectura de un archivo de 10,3 GB: 350 millones de registros en 90 minutos.
- Procesamiento y limpieza de datos: 2 consultas SQL y 15 minutos (con cifrado de datos personales 180 minutos).
- Mediciones de carga - 10 minutos.
- Descarga de tablas de hechos con 20 millones de registros nuevos: 5 consultas SQL y 35 minutos.
Integración total de 350 millones de registros en 2.5 horas, lo que equivale a 2.3 millones de registros por minuto o aproximadamente 39 mil registros de datos brutos por segundo.
# 2
El oponente experimental será el Raspberry Pi 3 Modelo B + con un procesador de 4 núcleos a 1,4 GHz.
Sqlite3 se usa como almacenamiento, los archivos se leen usando PHP. Los archivos y la base de datos se encuentran en una tarjeta SD de clase 10 de 32 GB en el lector incorporado. La copia de seguridad se crea en una unidad flash de 64 GB conectada a USB.
El modelo de datos en la base de datos relacional sqlite3 y los informes se describen en el artículo sobre almacenamiento pequeño .
Modelo de datos
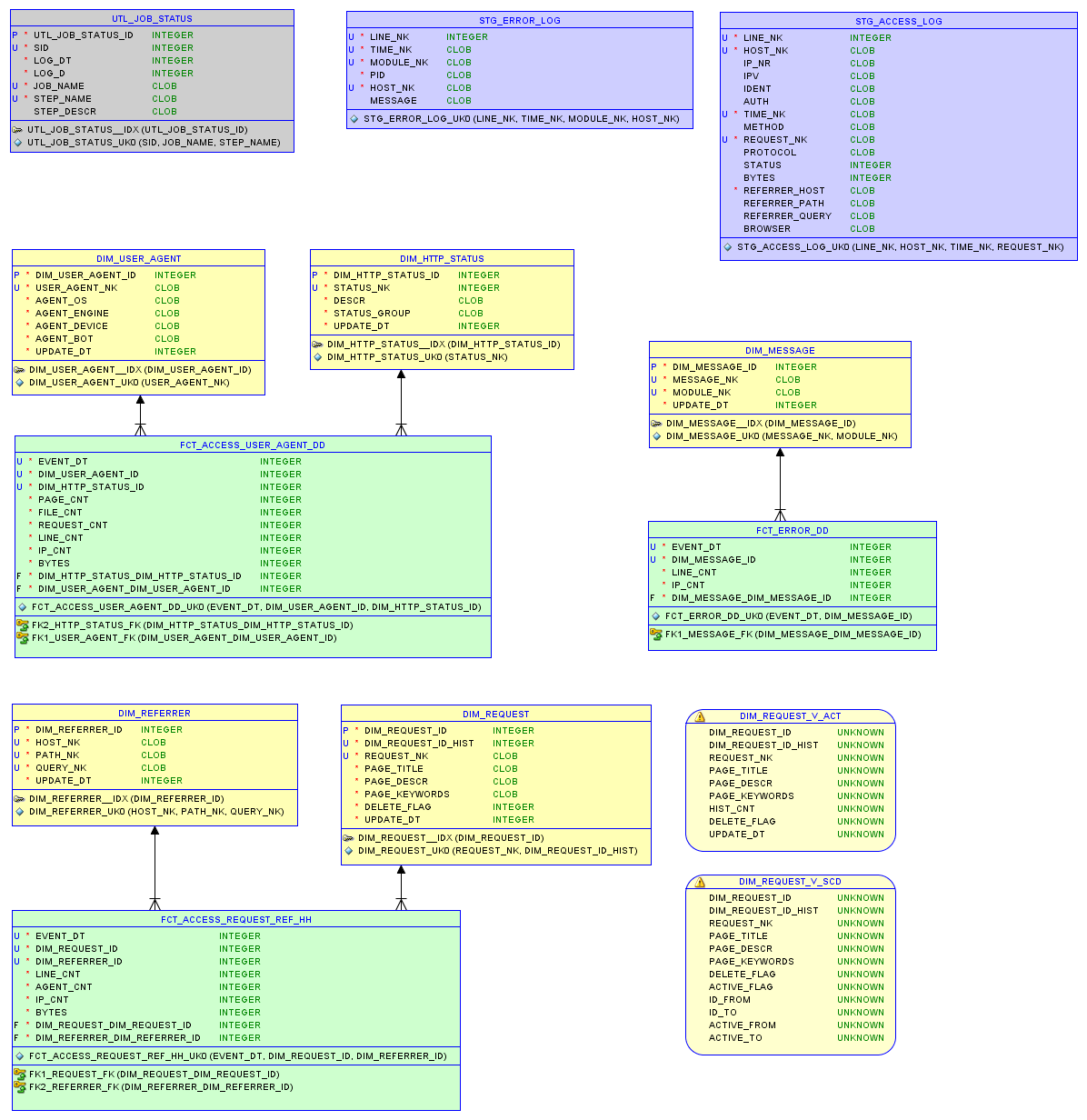
Prueba uno
El archivo fuente access.log es de 37 MB con 200 mil entradas.
- Le llevó 340 segundos leer el registro y escribir en la base de datos.
- La carga de mediciones con 5 mil registros tomó 5 segundos.
- Cargando tablas de hechos con 90 mil nuevos registros: 32 segundos.
En total , la integración de 200 mil registros tomó casi 7 minutos, lo que equivale a 28 mil registros por minuto o 470 registros de datos de origen por segundo. La base de datos es de 7.5 MB; solo 8 consultas SQL para el procesamiento de datos.
Prueba segundo
Un archivo de sitio más activo. El archivo original access.log es 67MB con 290K entradas.
- Le llevó 670 segundos leer el registro y escribir en la base de datos.
- Las mediciones de carga con 25 mil registros duraron 8 segundos.
- Cargando tablas de hechos con 240 mil nuevos registros: 80 segundos.
En total , la integración de 290 mil registros tomó un poco más de 12 minutos, lo que equivale a 23 mil registros por minuto o 380 registros de datos de origen por segundo. La base de datos ocupa 22.9 MB
Salida
Para obtener datos en forma de un modelo que permita un análisis efectivo, se requieren recursos computacionales y materiales significativos, y tiempo en cualquier caso.
Por ejemplo, una unidad Exadata cuesta más de 100K. Una Raspberry Pi cuesta 60 unidades.
No se pueden comparar linealmente, ya que Con el aumento de los volúmenes de datos y los requisitos de fiabilidad, surgen dificultades.
Sin embargo, si imaginamos un caso en el que mil Raspberry Pi trabajan en paralelo, entonces, según el experimento, procesarán alrededor de 400 mil registros de datos sin procesar por segundo.
Y si la solución para Exadata está optimizada para 60 o 100 mil registros por segundo, entonces esto es notablemente inferior a 400 mil. Esto confirma la sensación interna de que los precios de las soluciones empresariales son demasiado altos.
En cualquier caso, la Raspberry Pi es excelente para manejar datos y modelos relacionales de la escala adecuada.
Enlace
La Raspberry Pi doméstica se ha configurado como un servidor web. Describiré este proceso en la siguiente nota.
Puede experimentar con el rendimiento de Raspberry Pi y el archivo access.log usted mismo en . El modelo de base de datos (DDL), los procedimientos de carga (ETL) y la propia base de datos se pueden descargar desde allí. La idea es obtener rápidamente una idea del estado del sitio a partir del registro con datos de las últimas semanas.
Cambios
Gracias a los comentarios, se corrigió el error al cargar el archivo Exadata y se corrigieron los números en la nota. Sqlloader se usa para leer, algunos errores han eliminado los parámetros BINDSIZE y ROWS. Debido a la carga inestable desde un disco remoto, se eligió el método convencional en lugar de la ruta directa, lo que podría aumentar la velocidad en otro 30-50%.