
Robot factory de lucart
MLflow es una de las herramientas más estables y ligeras que permite a los científicos de datos gestionar el ciclo de vida de los modelos de aprendizaje automático. Es una herramienta útil con una interfaz simple para ver experimentos y herramientas poderosas para la gestión de envases y la implementación de modelos. Le permite trabajar con casi cualquier biblioteca de aprendizaje automático.
Soy Alexander Volynsky, arquitecto de la plataforma en la nube Mail.ru Cloud Solutions. En el último artículo, cubrimos Kubeflow. MLflow es otra herramienta para crear MLOps que no requiere que Kubernetes funcione.
Hablé en detalle sobre MLOps en el último artículo, ahora solo mencionaré brevemente las tesis principales.
- MLOps son las siglas de Machine Learning DevOps.
- Ayuda a estandarizar el proceso de desarrollo del modelo de aprendizaje automático.
- Reduce el tiempo que lleva implementar modelos en producción.
- Incluye tareas de seguimiento de modelos, control de versiones y monitoreo.
Todo esto permite que la empresa obtenga más valor de los modelos de aprendizaje automático.
Entonces, en el transcurso de este artículo, nosotros:
- Implementaremos servicios en la nube que actúan como backend para MLflow.
- Instale y configure MLflow Tracking Server.
- Implementemos JupyterHub y configurémoslo para que funcione con MLflow.
- Probamos el registro manual y automático de parámetros y métricas de experimentos.
- Probemos diferentes formas de publicar modelos.
Es importante que hagamos esto lo más cerca posible de la versión de producción. La mayoría de las instrucciones en Internet sugieren implementar MLflow en una máquina local o desde una imagen de la ventana acoplable. Estas opciones están bien para la familiarización y la experimentación rápida, pero no para la producción. Usaremos servicios confiables en la nube.
Si prefiere los tutoriales en vídeo, puede ver el seminario web “ MLflow en la nube. Una forma sencilla y rápida de poner en producción modelos de AA ".
MLflow: propósito y componentes principales
MLflow es una plataforma de código abierto para la gestión del ciclo de vida de los modelos de aprendizaje automático. También resuelve los problemas de reproducción de experimentos, publicación de modelos e incluye un registro central de modelos.
A diferencia de Kubeflow, MLflow puede ejecutarse sin Kubernetes. Pero al mismo tiempo, MLflow sabe cómo empaquetar modelos en imágenes de Docker para que luego puedan implementarse en Kubernetes.
MLflow consta de varios componentes.
Seguimiento de MLflow... Esta es una interfaz de usuario conveniente donde puede ver artefactos: gráficos, datos de muestra, conjuntos de datos. También puede ver las métricas y los parámetros de los modelos. MLflow Tracking tiene una API para diferentes lenguajes de programación con la que puede registrar métricas, parámetros y artefactos. Se admiten Python, Java, R, REST.
Hay dos conceptos importantes en MLflow Tracking: ejecuciones y experimentos.
- Ejecutar es una sola iteración del experimento. Por ejemplo, estableces los parámetros del modelo y lo ejecutas para entrenamiento. Para este lanzamiento único, aparecerá una nueva entrada en MLflow Tracking. Cuando cambien los parámetros del modelo, se creará una nueva ejecución.
- Experiment le permite agrupar varias ejecuciones en una entidad para que pueda verlas fácilmente.
Puede implementar MLflow Tracking en varios escenarios. Usaremos la variante más cercana a la producción: escenario # 4 (como se llama en la documentación oficial de MLflow ).
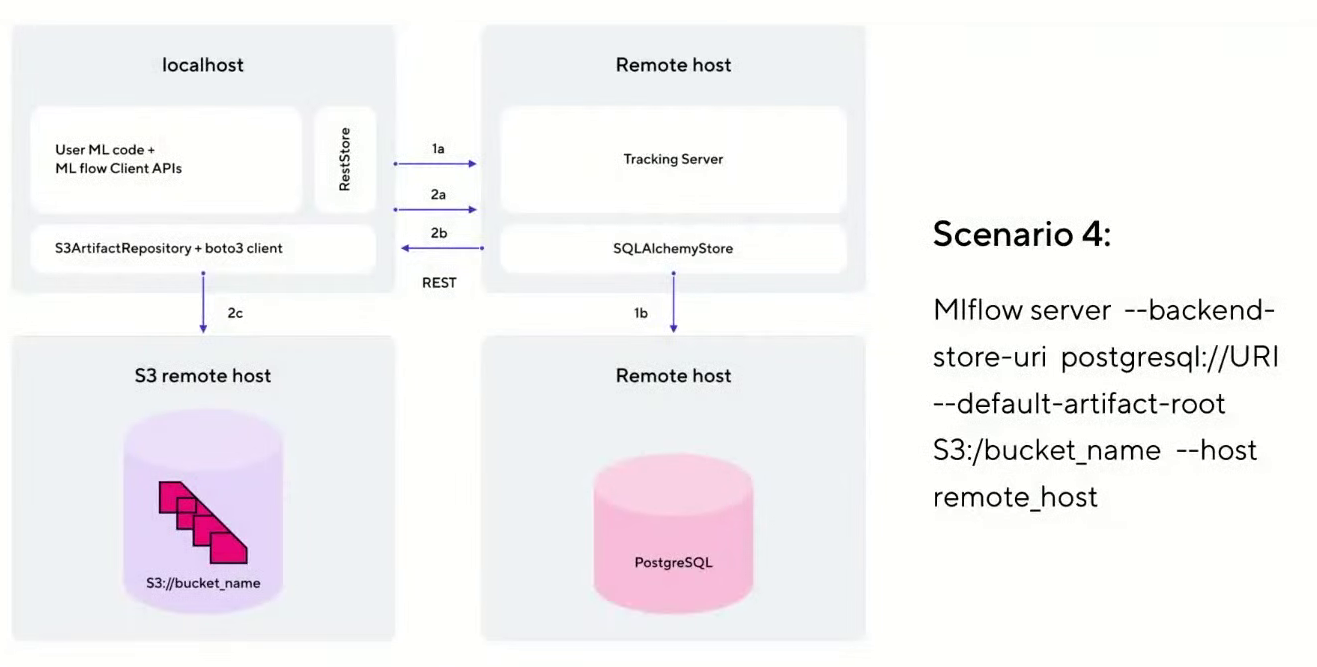
Esta opción tiene un host en el que se implementa JupyterHub. Se comunica con el servidor de seguimiento alojado en una máquina virtual separada en la nube. Para almacenar metadatos sobre experimentos se utiliza PostgreSQL, que implementaremos como servicio en la nube. Y todos los artefactos y modelos se almacenan por separado en S3 Object Storage.
Modelos MLflow . Este componente es responsable de empaquetar, almacenar y publicar modelos. Representa el concepto de sabor. Este es un tipo de contenedor que le permite usar el modelo en varias herramientas y marcos sin la necesidad de integraciones adicionales. Por ejemplo, puede usar modelos de Scikit-learn, Keras, TenserFlow, Spark MLlib y otros marcos.
MLflow Models también le permite hacer que los modelos estén disponibles a través de la API REST y empaquetarlos en una imagen de Docker para su uso posterior en Kubernetes.
Registro MLflow . Este componente es el repositorio central de modelos. Incluye una interfaz de usuario que le permite agregar etiquetas y descripciones para cada modelo. También le permite comparar diferentes modelos entre sí, por ejemplo, para ver las diferencias en los parámetros.
MLflow Registry gestiona el ciclo de vida de un modelo. En el contexto de MLflow, hay tres etapas del ciclo de vida: puesta en escena, producción y archivado. También hay soporte para el control de versiones. Todo esto le permite gestionar cómodamente todo el despliegue de modelos.
Proyectos MLflow... Es una forma de organizar y describir su código. Cada proyecto es un directorio con un conjunto de archivos, la mayoría de las veces son canalizaciones. Cada proyecto se describe mediante un archivo MLProject independiente en formato yaml. Especifica el nombre del proyecto, el entorno y los puntos de entrada. Esto permite reproducir el experimento en un entorno diferente. También hay una CLI y una API para Python.
Con MLflow Projects, puede crear módulos que son pasos reutilizables. Luego, estos módulos se pueden incrustar en tuberías más complejas, lo que les permite estandarizarlos.
Instrucciones para instalar y configurar MLflow
Paso 1: implementar servicios en la nube que actúen como backend
Primero, crearemos una máquina virtual en la que implementaremos MLflow Tracking Server. Haremos esto en nuestra plataforma en la nube Mail.ru Cloud Solutions (los nuevos usuarios aquí reciben 3000 rublos adicionales para las pruebas, para que pueda registrarse y repetir todo lo que se describe aquí).
Antes de comenzar a trabajar, debe configurar la red, generar y descargar una clave SSH para conectarse a la máquina virtual. Puede configurar la red usted mismo de acuerdo con las instrucciones .
Vaya al panel de MCS, sección " Computación en la nube - Máquinas virtuales " y haga clic en el botón "Agregar". A continuación, configuramos los parámetros de la nueva máquina virtual. Por ejemplo, tomaremos una configuración con 4 CPU y 8 GB de RAM. Elijamos el sistema operativo: Ubuntu 18.04.
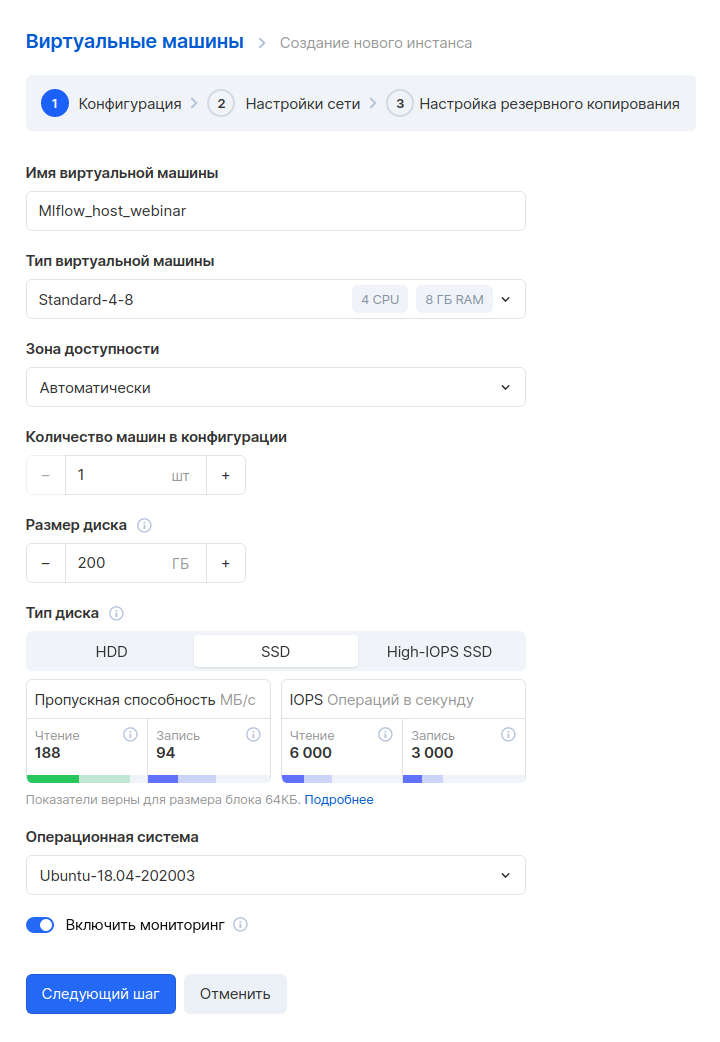
El siguiente paso es configurar la red. Como ya hemos creado una red de antemano, aquí solo tiene que seleccionarla. Tenga en cuenta que se especifica una regla personalizada en la configuración del Firewall: only_my_ip. Esta regla está ausente por defecto, la creamos nosotros mismos para que solo una dirección específica pueda conectarse a una máquina virtual. Le recomendamos que haga lo mismo para mejorar la seguridad. A continuación, le indicamos cómo crear sus propias reglas.
También debe asignar una IP externa para poder conectarse a la máquina desde Internet.
En el siguiente paso, configuramos una copia de seguridad. Puede dejar la configuración predeterminada si lo desea.
Creamos una instancia y esperamos unos minutos. Cuando la máquina virtual esté lista, deberá anotar sus direcciones internas y externas, serán útiles más adelante.

A continuación, creemos una base de datos. Vaya a la sección " Bases de datos " y haga clic en el botón "Agregar". Seleccionamos PostgreSQL 12 en la configuración maestro-esclavo.
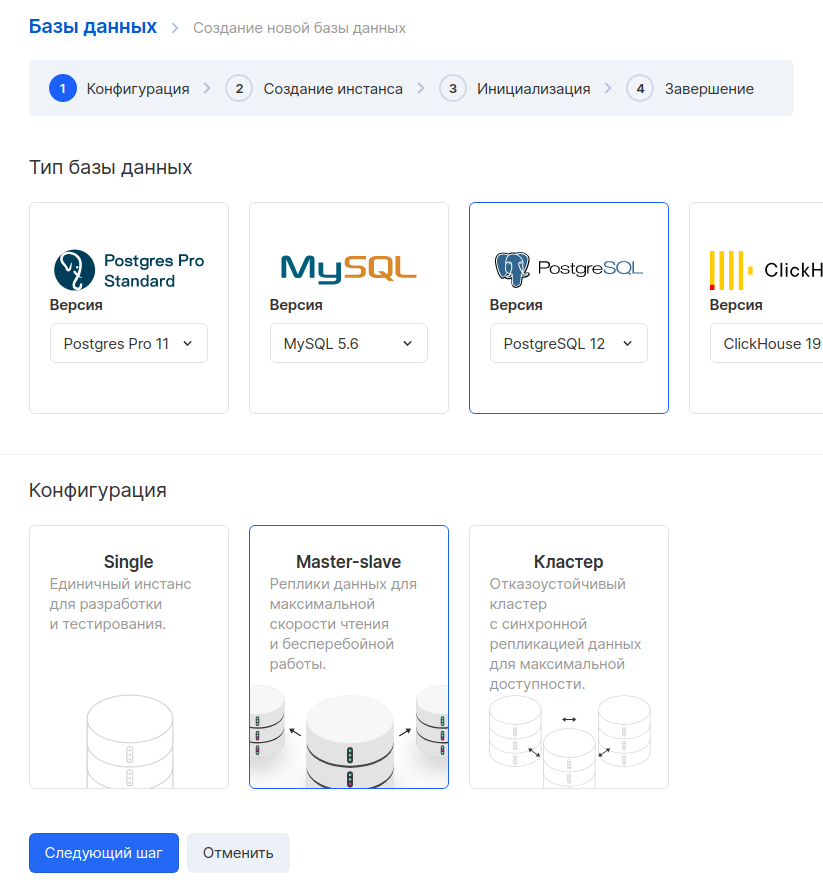
En el siguiente paso, configuramos los parámetros de la máquina virtual. Como ejemplo, tomamos una configuración con 1 CPU y 2 GB de RAM. La IP externa se puede omitir, porque solo accederemos a esta máquina desde la red interna. Es importante seleccionar la misma red que elegimos para la máquina virtual del servidor de seguimiento.

El siguiente paso es generar el nombre de la base de datos, el usuario y la contraseña. Es una buena práctica crear una base de datos separada y un usuario separado para cada servicio.
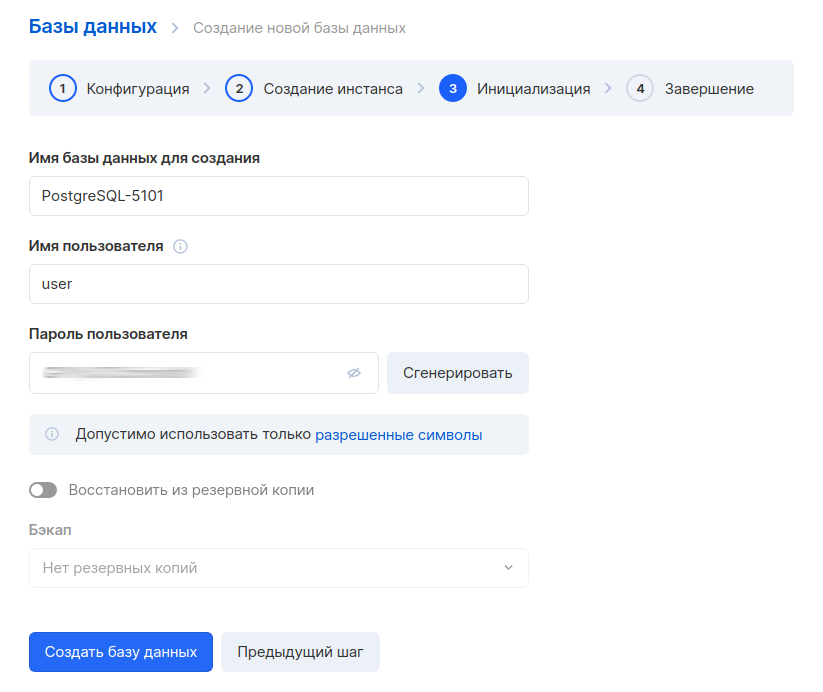
Después de crear la base de datos, también debe escribir la dirección interna. Lo necesitará para configurar una conexión a MLflow.
A continuación, debe crear un nuevo depósito en el almacenamiento de objetos. Vaya a la sección " Almacenamiento de objetos: depósitos " y cree un depósito nuevo. Al crear, especifique el nombre y el tipo: Hotbox.

Crea un directorio dentro del depósito. Para hacer esto, ingrese a él y haga clic en "Crear carpeta". De forma predeterminada, la instrucción MLflow usa el nombre de la carpeta de artefactos, por lo que usaremos el mismo nombre.
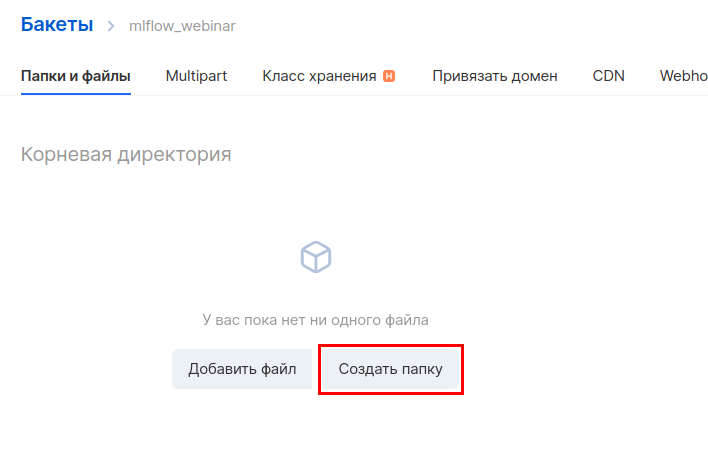
A continuación, debe crear una cuenta separada para acceder a este depósito. En la sección "Almacenamiento de objetos", vaya a la subsección " Cuentas " y haga clic en "Agregar cuenta".
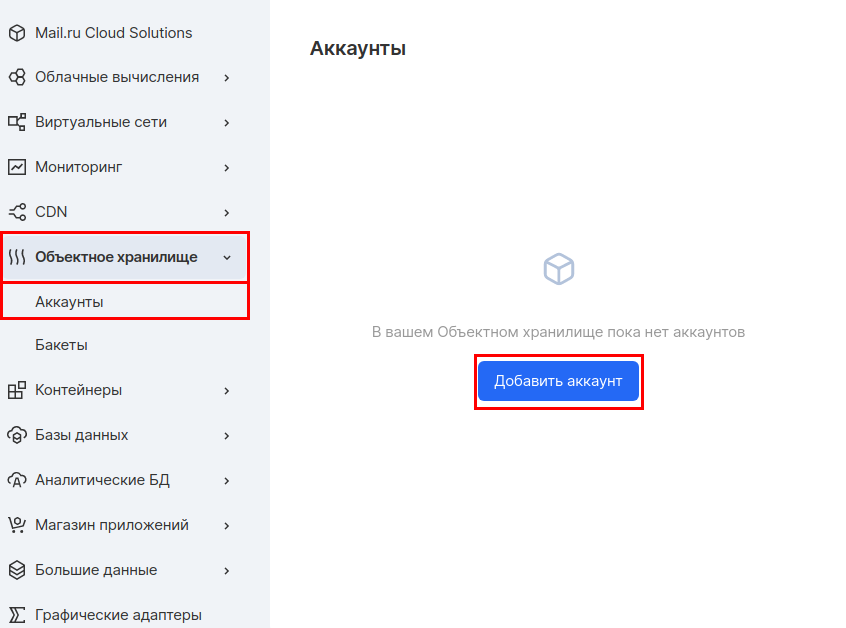
Usaremos el nombre de la cuenta: mlflow_webinar. Después de la creación, anote el ID de la clave de acceso y la clave secreta. La clave secreta es especialmente importante, porque ya no estará visible y, en caso de pérdida, tendrá que volver a crearla.

Eso es todo, hemos preparado la infraestructura para el backend.
Todos los servicios están en una red virtual. Por lo tanto, para la comunicación entre ellos, usaremos direcciones internas en todas partes. Si desea utilizar direcciones externas, debe configurar el Firewall correctamente.
Paso 2: instale y configure MLflow Tracking Server en una máquina virtual dedicada
Nos conectamos vía SSH a la máquina virtual que creamos al principio. He aquí cómo hacerlo.
Primero, instalemos conda , que es un administrador de paquetes para Python, R y otros lenguajes.
curl -O https://repo.anaconda.com/archive/Anaconda3-2020.11-Linux-x86_64.sh
bash Anaconda3-2020.11-Linux-x86_64.sh
exec bash
A continuación, creemos y activemos un entorno separado para MLflow.
conda create -n mlflow_env conda activate mlflow_env
Instale las bibliotecas necesarias:
conda install python pip install mlflow pip install boto3 sudo apt install gcc pip install psycopg2-binary
A continuación, debe crear variables de entorno para acceder a S3. Abra el archivo para editarlo:
sudo nano /etc/environment
Y establecemos variables en él. En lugar de REPLACE_WITH_INTERNAL_IP_MLFLOW_VM, debe sustituir la dirección de su máquina virtual:
MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com MLFLOW_TRACKING_URI=http://REPLACE_WITH_INTERNAL_IP_MLFLOW_VM:8000
MLflow se comunica con S3 utilizando la biblioteca boto3, que de forma predeterminada busca credenciales en la carpeta ~ / .aws. Por lo tanto, necesitamos crear un archivo:
mkdir ~/.aws nano ~/.aws/credentials
En este archivo escribiremos las credenciales de acceso a S3, que recibimos después de crear el depósito:
[default] aws_access_key_id = REPLACE_WITH_YOUR_KEY aws_secret_access_key = REPLACE_WITH_YOUR_SECRET_KEY
Finalmente, aplicamos la configuración del entorno:
conda activate mlflow_env
Ahora puede iniciar Tracking Server. Sustituya los parámetros de conexión de PostgreSQL y S3 en el comando:
mlflow server --backend-store-uri postgresql://pg_user:pg_password@REPLACE_WITH_INTERNAL_IP_POSTGRESQL/db_name --default-artifact-root s3://REPLACE_WITH_YOUR_BUCKET/REPLACE_WITH_YOUR_DIRECTORY/ -h 0.0.0.0 -p 8000
Lanzamiento de MLflow:

Ahora abramos la GUI y comprobemos que todo funciona como debería. Para ello, diríjase a la dirección IP externa de la máquina virtual con MLflow Tracking Server, puerto 8000. En nuestro caso será 37.139.41.57 : 8000
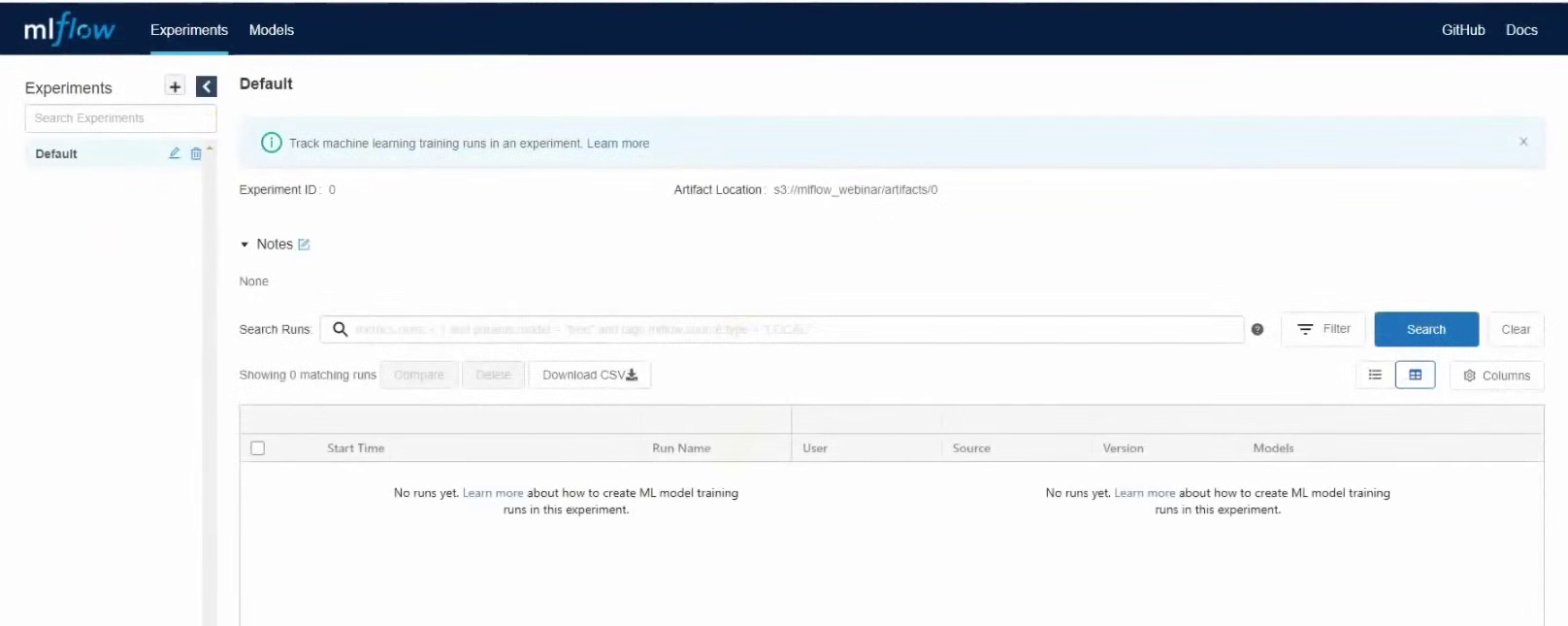
MLflow inició
Pero ahora hay un pequeño problema en nuestro esquema. El servidor funciona mientras la terminal esté funcionando. Si cierra la terminal, MLflow se detendrá. Además, no se reiniciará automáticamente si reiniciamos el servidor. Para solucionar este problema, iniciaremos el servidor MLflow como un servicio systemd.
Entonces, creemos dos directorios para almacenar registros y errores:
mkdir ~/mlflow_logs/ mkdir ~/mlflow_errors/
A continuación, creemos un archivo de servicio:
sudo nano /etc/systemd/system/mlflow-tracking.service
A continuación, agregue el código. No olvide sustituir sus parámetros para conectarse a la base de datos y al S3, como lo hizo al iniciar el servidor manualmente:
[Unit]
Description=MLflow Tracking Server
After=network.target
[Service]
Environment=MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com
Restart=on-failure
RestartSec=30
StandardOutput=file:/home/ubuntu/mlflow_logs/stdout.log
StandardError=file:/home/ubuntu/mlflow_errors/stderr.log
User=ubuntu
ExecStart=/bin/bash -c 'PATH=/home/ubuntu/anaconda3/envs/mlflow_env/bin/:$PATH exec mlflow server --backend-store-uri postgresql://PG_USER:PG_PASSWORD@REPLACE_WITH_INTERNAL_IP_POSTGRESQL/DB_NAME --default-artifact-root s3://REPLACE_WITH_YOUR_BUCKET/REPLACE_WITH_YOUR_DIRECTORY/ -h 0.0.0.0 -p 8000'
[Install]
WantedBy=multi-user.target
Ahora iniciamos el servicio, activamos la carga automática al inicio del sistema y verificamos que el servicio esté funcionando:
sudo systemctl daemon-reload
sudo systemctl enable mlflow-tracking
sudo systemctl start mlflow-tracking
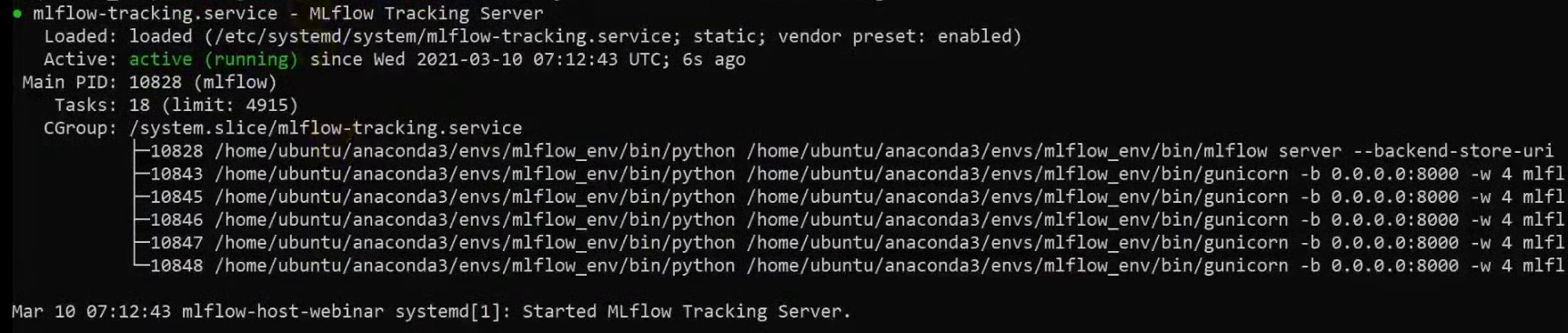
sudo systemctl status mlflow-tracking
Vemos que el servicio ha comenzado:
Además, podemos verificar los registros, todo está bien allí también:
head -n 95 ~/mlflow_logs/stdout.log

Abra la interfaz web nuevamente y vea que el servidor MLflow se está ejecutando. Eso es todo, MLflow Tracking Server está instalado y listo para funcionar.
Paso 3: implemente JupyterHub en la nube y configúrelo para que funcione con MLflow
Implementaremos JupyterHub en una máquina virtual separada para que luego este host se pueda proporcionar a equipos de ingenieros de datos o científicos de datos. De esta forma pueden trabajar con JupyterHub, pero no pueden afectar al servidor MLflow. Usaremos nuestro servicio Machine Learning in the Cloud, que le permite obtener rápidamente un entorno listo para usar con JupyterHub, conda y otras herramientas útiles instaladas.
En el panel de MCS, vaya a la sección Aprendizaje automático y cree un entorno de aprendizaje.
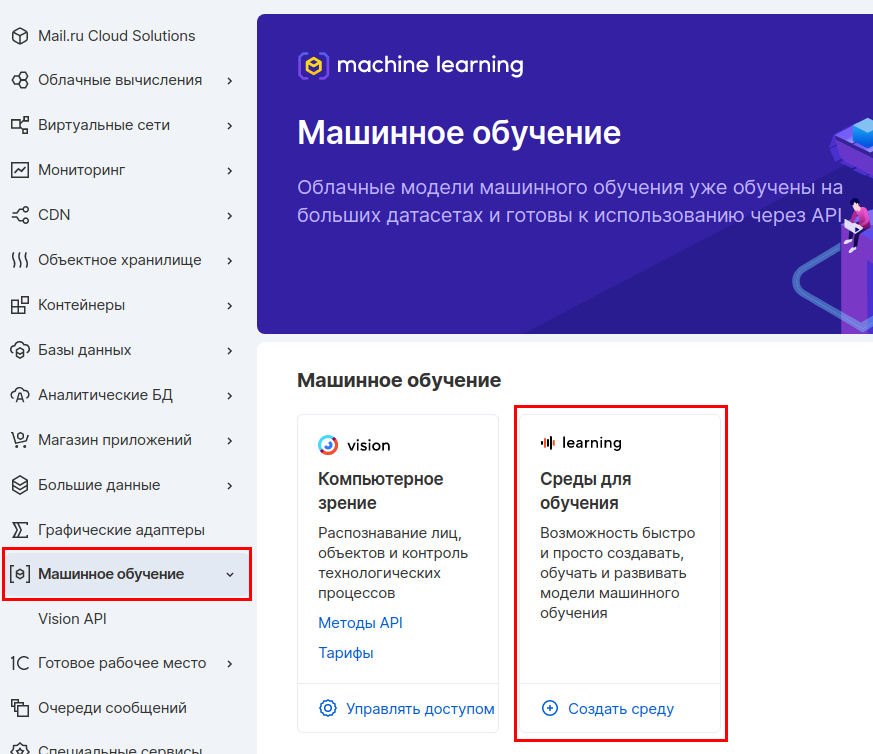
Seleccionamos los parámetros de la máquina virtual. Tomaremos 4 CPU y 8 GB de RAM.
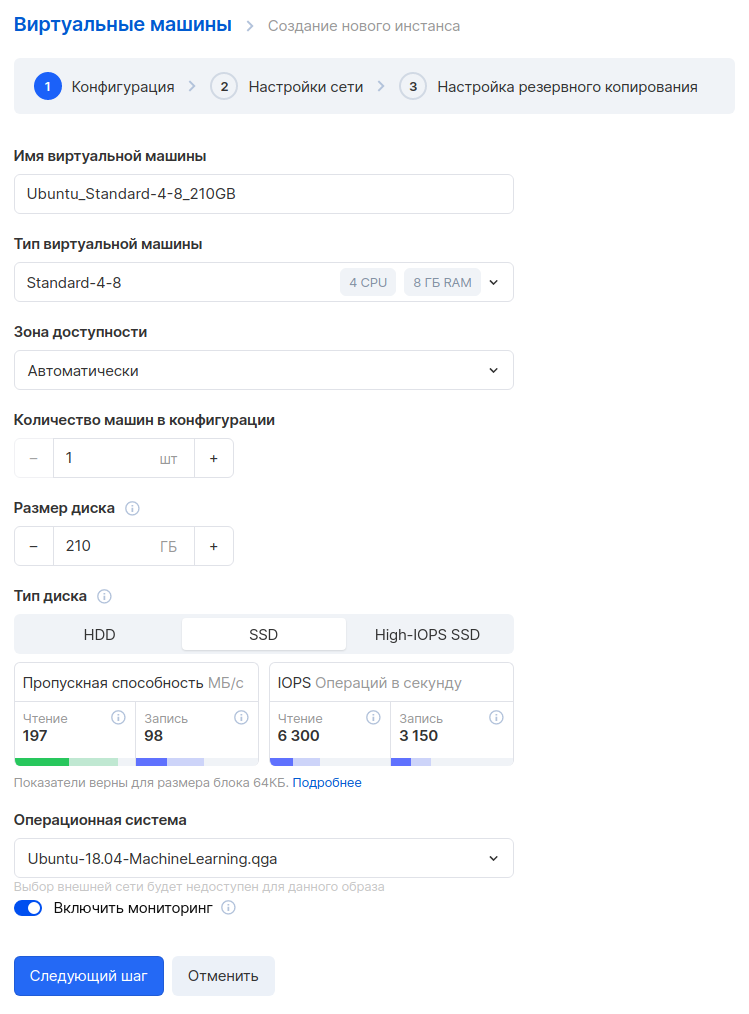
En el siguiente paso, configuramos la red. Asegúrese de que la red sea la misma para que esta máquina pueda comunicarse con el resto de servidores de la red interna. Seleccionamos la opción "Asignar IP externa" para que posteriormente podamos conectarnos a esta máquina desde Internet.

El último paso es configurar su copia de seguridad. Puede dejar las opciones predeterminadas.
Una vez creada la máquina virtual, debe escribir su dirección IP externa: nos será útil más adelante.

Ahora nos conectamos a esta máquina a través de SSH y activamos el JupyterHub instalado. Usaremos la utilidad tmux para poder desconectarnos de la pantalla y ejecutar otros comandos.
tmux
jupyter-notebook --ip '*'
Usar tmux no es una solución de producto. Ahora haremos esto como parte de un proyecto de prueba y, para las soluciones de productos, recomendamos usar systemd, como hicimos para lanzar MLflow Tracking Server.
Después de activar JupyterHub, la consola tendrá una URL a la que debe ir e iniciar sesión en JupyterHub. En esta línea, debe sustituir la dirección IP externa de la máquina virtual.

Vaya a esta dirección y vea la interfaz de JupyterHub:
Ahora tenemos que dejar el servidor en ejecución, pero al mismo tiempo ejecutar otros comandos. Por tanto, nos desconectaremos de esta instancia de terminal y la dejaremos ejecutándose en segundo plano. Para hacer esto, presione la combinación de teclas ctrl + b d.
La carga directa de artefactos en el almacenamiento de artefactos se realizará desde este host. Por lo tanto, necesitamos configurar la interoperabilidad de JupyterHub con MLflow y S3. Primero, configuremos algunas variables de entorno. Abramos el archivo / etc / environment:
sudo nano /etc/environment
Y escriba las direcciones del servidor de seguimiento y del punto final para S3 en él:
MLFLOW_TRACKING_URI=http://REPLACE_WITH_INTERNAL_IP_MLFLOW_VM:8000 MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com
También necesitamos volver a crear las credenciales para acceder a S3. Creemos un archivo y un directorio:
mkdir .aws nano ~/.aws/credentials
Escribamos la clave de acceso y la clave secreta allí:
[default] aws_access_key_id = REPLACE_WITH_YOUR_KEY aws_secret_access_key = REPLACE_WITH_YOUR_SECRET_KEY
Ahora instalemos MLflow para usar su lado del cliente. Para hacer esto, creemos un entorno y un kernel separados:
conda create -n mlflow_env
conda activate mlflow_env
conda install python
pip install mlflow
pip install matplotlib
pip install sklearn
pip install boto3
conda install -c anaconda ipykernel
python -m ipykernel install --user --name ex --display-name "Python (mlflow)"
Paso 4: registrar parámetros y métricas de experimentos
Ahora trabajaremos directamente con el código. Vaya a la interfaz web de JupyterHub nuevamente, inicie la terminal y clone el repositorio:
git clone https://github.com/stockblog/webinar_mlflow/ webinar_mlflow
A continuación, abra el archivo mlflow_demo.ipynb e inicie secuencialmente las celdas.
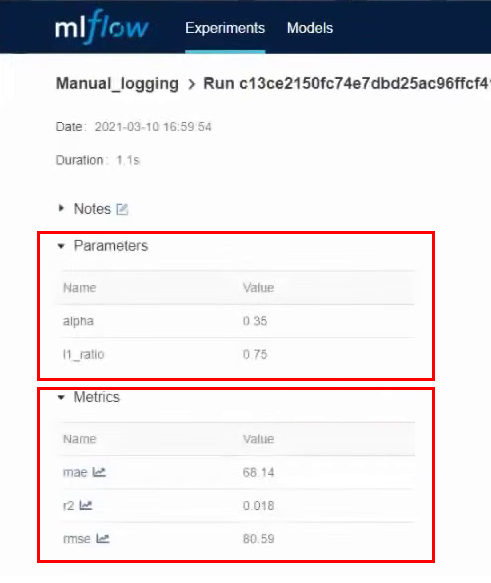
En la celda número 3, probaremos el registro manual de parámetros y métricas. La celda indica claramente los parámetros que queremos asegurar. Lanzamos la celda y una vez que funciona, vamos a la interfaz de MLflow. Aquí vemos que se ha creado un nuevo experimento: Manual_logging.

Entramos en los detalles de este experimento y vemos los parámetros y métricas que indicamos durante el registro:
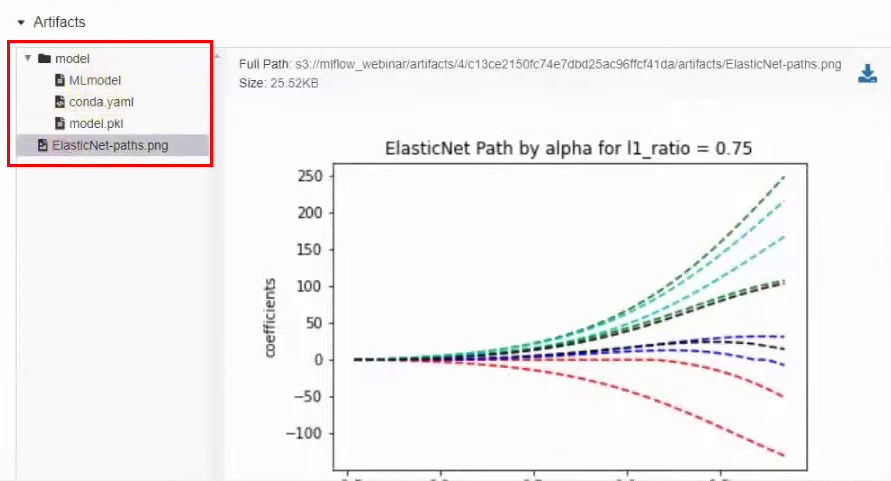
En la misma ventana a continuación, hay artefactos que están directamente relacionados con el modelo, por ejemplo, un gráfico:
Ahora intentemos registrar todos los parámetros automáticamente. En la siguiente celda, usamos el mismo modelo, pero activamos el registro automático. La línea es responsable de esto:
mlflow.sklearn.autolog(log_input_examples=True)
Necesitamos especificar el sabor que usaremos, en nuestro caso es sklearn. También especificamos log_input_examples = True en los parámetros de la función autolog. Al mismo tiempo, se registrarán automáticamente ejemplos de datos de entrada para el modelo: qué columnas, qué significan y cómo se ven los datos de entrada. Esta información se encontrará en artefactos. Esto puede resultar útil cuando un equipo está trabajando en varios experimentos al mismo tiempo. Porque no siempre es posible tener en cuenta todos los modelos y todos los ejemplos de datos correspondientes.
En esta celda, hemos eliminado todas las líneas asociadas con el registro manual de métricas y parámetros. Pero el registro de artefactos permanece en modo manual.
Lanzamos la celda, luego de su ejecución, se crea un nuevo experimento. Vamos a la interfaz de MLflow, vamos al experimento de Auto_logging y vemos que ahora hay muchos más parámetros y métricas que con la recopilación manual:

Ahora, si cambiamos los parámetros en la celda y la ejecutamos nuevamente, aparecerán líneas con nuevos lanzamientos en experimentos en MLflow. Por ejemplo, hicimos tres lanzamientos con diferentes parámetros:
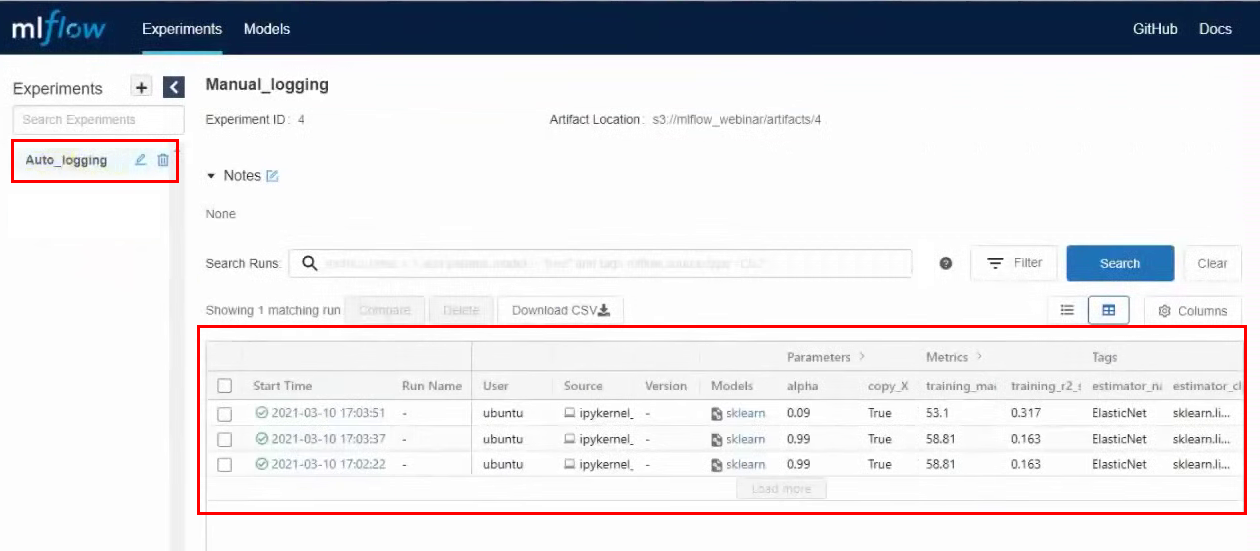
También en los artefactos puede encontrar un ejemplo de cómo usar este modelo en particular. Hay una ruta de modelo en S3 y ejemplos para diferentes marcos.
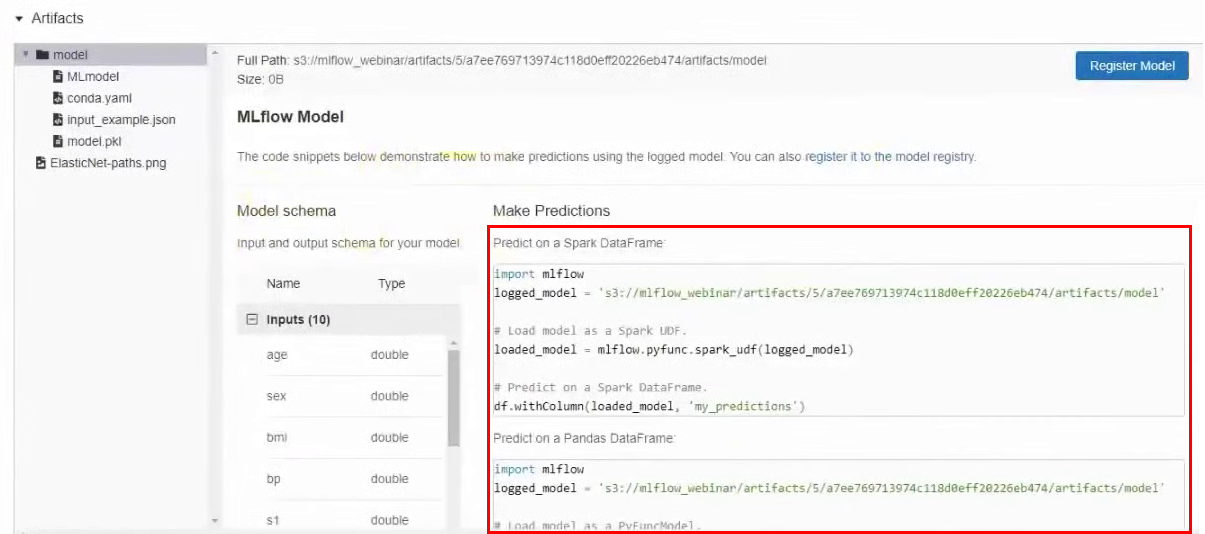
Paso 5: probar formas de publicar modelos de AA
Entonces, hicimos los experimentos y ahora publicaremos el modelo. Veremos dos formas de hacer esto.
Método de publicación n. ° 1: acceda al repositorio de S3 directamente. Copie la dirección del modelo en el almacenamiento S3 y publíquelo usando mlflow serve:
mlflow models serve -m s3://BUCKET/FOLDER/EXPERIMENT_NUMBER/INTERNAL_MLFLOW_ID/artifacts/model -h 0.0.0.0 -p 8001
En este comando, especificamos el host y el puerto en el que estará disponible el modelo. Usamos la dirección 0.0.0.0, que significa el host actual. No hay errores en el terminal, lo que significa que se ha publicado el modelo:

Ahora probémoslo. En una nueva ventana de terminal, conéctese a través de SSH al mismo servidor e intente llegar al modelo usando curl. Si está utilizando el mismo conjunto de datos, puede copiar completamente el comando sin cambios:
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"], "data":[[0.0453409833354632, 0.0506801187398187, 0.0606183944448076, 0.0310533436263482, 0.0287020030602135, 0.0473467013092799, 0.0544457590642881, 0.0712099797536354, 0.133598980013008, 0.135611830689079]]}' http://0.0.0.0:8001/invocations
Después de ejecutar el comando, vemos el resultado:

También se puede acceder al modelo desde la interfaz de JupyterHub. Para hacer esto, ejecute la celda apropiada , pero antes de eso, cambie la dirección IP a la suya.
Método de publicación n. ° 2: registre el modelo en MLflow. También podemos registrar el modelo en MLflow, y luego estará disponible a través de la interfaz de usuario. Para hacer esto, regrese a los resultados del experimento, en la sección Artefactos, haga clic en el botón Registrar modelo y en la ventana que aparece, asígnele un nombre.
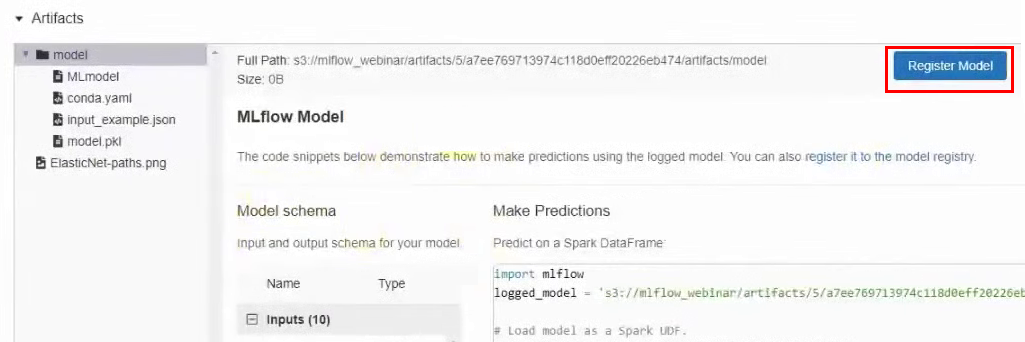
Ahora en el menú superior, vaya a la pestaña Modelos. Y vemos que en la lista de modelos tenemos un modelo nuevo:
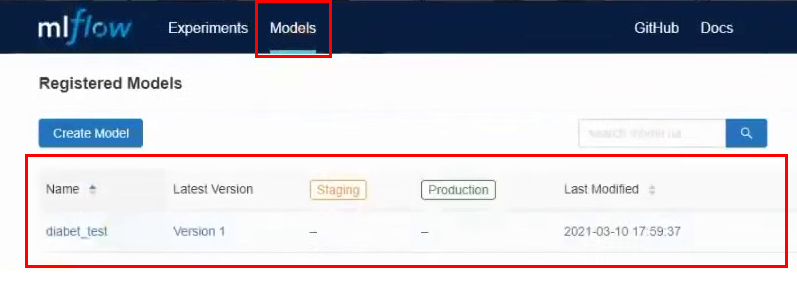
Entremos en ello. En esta interfaz, puede transferir el modelo a diferentes etapas, ver los parámetros de entrada y los resultados. También puede proporcionar una descripción del modelo, que será útil si varias personas están trabajando en él. Convertiremos nuestro modelo a Staging.
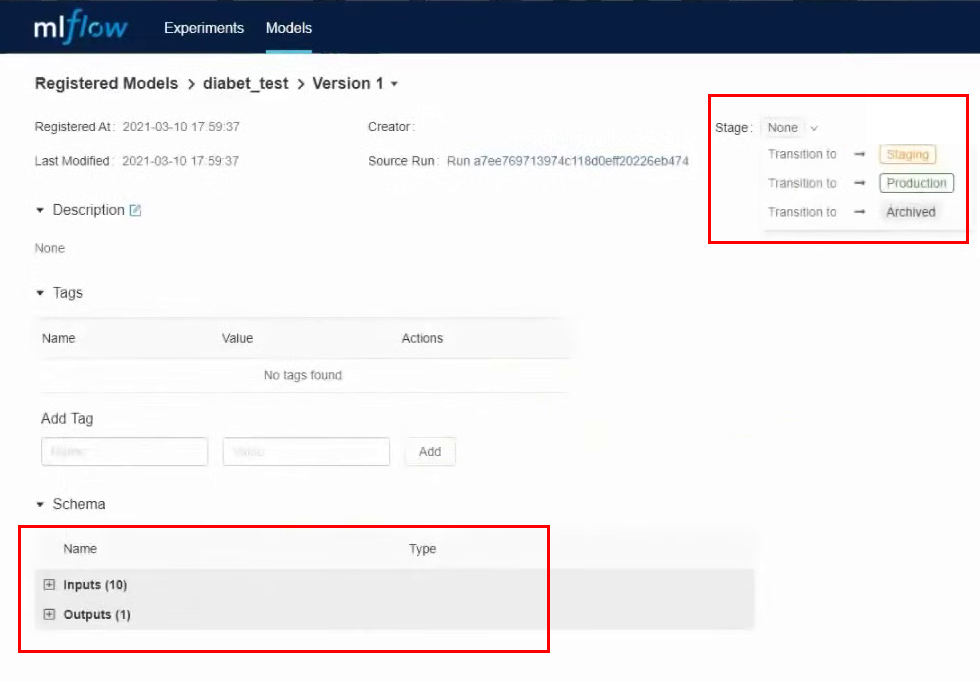
Realizamos casi todas las acciones a través de la interfaz, pero de la misma manera puedes trabajar a través de la API y CLI. Todas estas acciones se pueden automatizar: registrar modelos, transferir a otra etapa, desplegar modelos y todo lo demás.
Ahora también usaremos el comando serve para publicar el modelo, pero en lugar de la ruta larga en S3, solo especificaremos el nombre del modelo:
mlflow models serve -m "models:/YOUR_MODEL_NAME/STAGE"
Tenga en cuenta que esta vez no especificamos el puerto y el modelo predeterminado se publicó en el puerto 5000:

Ahora, usando curl, intentamos alcanzar el modelo nuevamente:
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"], "data":[[0.0453409833354632, 0.0506801187398187, 0.0606183944448076, 0.0310533436263482, 0.0287020030602135, 0.0473467013092799, 0.0544457590642881, 0.0712099797536354, 0.133598980013008, 0.135611830689079]]}' http://0.0.0.0:5000/invocations
El resultado es el mismo:
Pero si intentamos acceder al modelo desde otro servidor, fallaremos. Porque ahora el modelo solo está disponible dentro del host donde está publicado. Para solucionar esto, publiquemos el modelo con el parámetro -h:
mlflow models serve -m "models:/YOUR_MODEL_NAME/STAGE" -h 0.0.0.0
Probemos el acceso al modelo usando la misma celda en JupyterHub, pero cambiemos el puerto a 5000. El modelo devuelve un resultado. Difiere ligeramente del resultado anterior, porque durante el seminario web cambiamos algunos parámetros.

También se puede acceder al modelo usando Python. Se puede encontrar un ejemplo en otra celda .
Pero en ambas versiones de la publicación del modelo hay una peculiaridad. El modelo está disponible siempre que la terminal se ejecute con el comando de servicio. Cuando cerramos el terminal o reiniciamos el servidor, se perderá el acceso al modelo. Para evitar esto, publicaremos el modelo usando el servicio systemd, como hicimos para lanzar MLflow Tracking Server.
Creemos un nuevo archivo de servicio:
sudo nano /etc/systemd/system/mlflow-model.service
E insertaremos estos comandos en él, habiendo reemplazado previamente las variables con las nuestras.
[Unit]
Description=MLFlow Model Serving
After=network.target
[Service]
Restart=on-failure
RestartSec=30
StandardOutput=file:/home/ubuntu/mlflow_logs/stdout.log
StandardError=file:/home/ubuntu/mlflow_errors/stderr.log
Environment=MLFLOW_TRACKING_URI=http://REPLACE_WITH_INTERNAL_IP_MLFLOW_VM:8000
Environment=MLFLOW_CONDA_HOME=/home/ubuntu/anaconda3/
Environment=MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com
ExecStart=/bin/bash -c 'PATH=/home/ubuntu/anaconda3/envs/REPLACE_WITH_MLFLOW_ENV_OF_MODEL/bin/:$PATH exec mlflow models serve -m "models:/YOUR_MODEL_NAME/STAGE" -h 0.0.0.0 -p 8001'
[Install]
WantedBy=multi-user.target
Hay una nueva variable que no hemos usado antes: REPLACE_WITH_MLFLOW_ENV_OF_MODEL. Este es un entorno de MLflow individual que se crea automáticamente para cada modelo. Para ver en qué entorno se está ejecutando su modelo, observe el resultado del comando de servicio cuando ejecutó el modelo. Hay este identificador ahí:

Ahora comencemos y activemos este servicio para que el modelo se publique cada vez que se inicie el host:
sudo systemctl daemon-reload
sudo systemctl enable mlflow-model
sudo systemctl start mlflow-model
Comprobando el estado:
sudo systemctl status mlflow-model
Vemos que apareció un error al inicio:

Usando su ejemplo, analizaremos cómo puede encontrar y eliminar errores. Para comprender lo que sucedió realmente, revisemos los registros. Están en una carpeta que creamos específicamente para los registros.
head -n 95 ~/mlflow_logs/stdout.log
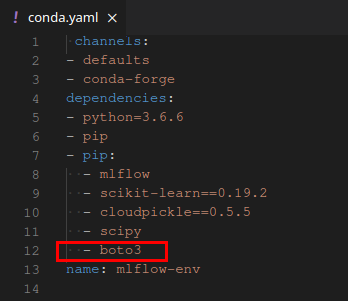
En nuestro ejemplo, al final del registro, puede ver que MLflow no puede encontrar la biblioteca boto3, que es necesaria para acceder a S3:

Hay dos opciones para resolver el problema:
- Instale la biblioteca a mano en el entorno de MLflow. Pero este es un método de muleta, no lo consideraremos.
- Registre la biblioteca en dependencias en el archivo yaml. Consideraremos este método.
Necesitamos encontrar la carpeta en el depósito donde se almacena este modelo. Para hacer esto, vuelva a la interfaz de MLflow y, en los resultados del experimento, vaya a la sección con artefactos. Recordamos el camino:
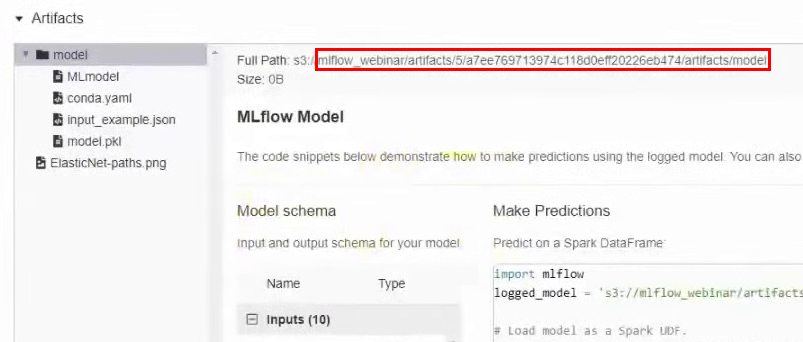
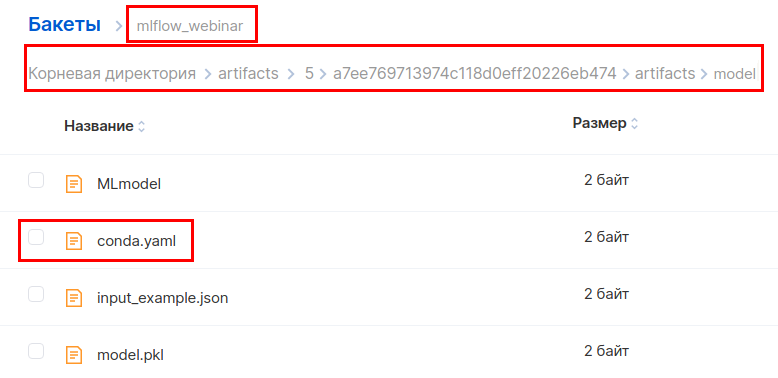
En la interfaz de MCS, vaya al depósito a lo largo de esta ruta y descargue el archivo conda.yaml.
Agregue la biblioteca boto3 a la sección con dependencias y cargue el archivo nuevamente.
Intentemos iniciar el servicio systemd nuevamente:
sudo systemctl start mlflow-model
Todo está bien ahora, el modelo ha comenzado. Puede volver a intentar comunicarse con ella de diferentes maneras, como lo hicimos antes. Tenga en cuenta que 8001 debe especificarse de nuevo como el puerto.
Ahora creemos una imagen de la ventana acoplable con este modelo para que se pueda migrar fácilmente a otro entorno. Para hacer esto, Docker debe estar instalado en el host. No consideraremos el proceso de instalación, sino que simplemente proporcionaremos un enlace a las instrucciones oficiales .
Ejecutemos el comando:
mlflow models build-docker -m "models:/YOUR_MODEL_NAME/STAGE" -n "DOCKER_IMAGE_NAME"
En el parámetro -n, especificamos el nombre deseado para la imagen de la ventana acoplable. Resultado:

Probémoslo. Lanzamos el contenedor, ahora el modelo estará disponible en el puerto 5001:
docker run -p 5001:8080 YOUR_MODEL_NAME
El modelo ahora debería estar disponible y activo de inmediato. Vamos a revisar:
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"], "data":[[0.0453409833354632, 0.0506801187398187, 0.0606183944448076, 0.0310533436263482, 0.0287020030602135, 0.0473467013092799, 0.0544457590642881, 0.0712099797536354, 0.133598980013008, 0.135611830689079]]}' http://127.0.0.1:5001/invocations
También puede comprobar la disponibilidad desde JupyterHub. Al mismo tiempo, en la terminal donde lanzamos la imagen de la ventana acoplable, vemos que las solicitudes provienen de dos hosts diferentes, local y JupyterHub:

Eso es todo, la imagen de la ventana acoplable está ensamblada, probada y lista para funcionar.
Que hemos aprendido
Entonces, nos familiarizamos con MLflow y aprendimos cómo implementarlo en la nube. La mayoría de las instrucciones en la red se limitan a instalar MLflow en la máquina local. Esto es bueno para la familiarización y la experimentación rápida, pero definitivamente no es una opción de producción.
Todo esto es posible porque las plataformas en la nube brindan una variedad de servicios listos para usar que ayudan a simplificar y acelerar la implementación.
, , Mail.ru Cloud Solutions, 3000 ₽. , MLflow .