Problema de reconocimiento de sucesión semántica(vinculación textual), o implicaciones (inferencia del lenguaje natural), en los textos en lenguaje natural consiste en determinar si una parte del texto (premisa, antecedente) puede estar implícita o contradecir (o no contradecir) otro fragmento del texto (consecuencia, consecuente ). Si bien este problema a menudo se considera una prueba importante de comprensión en los sistemas de aprendizaje automático (ML) y se ha estudiado en profundidad para textos simples, se ha dedicado mucho menos esfuerzo a aplicar dichos modelos a datos estructurados como sitios web, tablas, bases de datos, etc. , el reconocimiento de la sucesión semántica es especialmente importante cuando el contenido de la tabla debe resumirse con precisión y presentarse al usuario, y es importante para aplicaciones en las que se requiere una alta precisión: en sistemas de preguntas y respuestas yasistentes virtuales .
En el artículo “ Comprensión de tablas con preentrenamiento intermedio ” , publicado en EMNLP 2020 , los autores presentaron los primeros métodos de preentrenamiento adaptados para el análisis de tablas, permitiendo que los modelos aprendan mejor, más rápido y con menos datos. Los autores se basan en su modelo TAPAS anterior , que era una extensión del modelo bidireccional basado en el transformador BERT con incrustaciones especiales para encontrar respuestas en tablas. Los nuevos métodos de preentrenamiento de TAPAS proporcionan mejores métricas en múltiples conjuntos de datos, incluidas tablas. En TabFact, por ejemplo, la brecha entre los resultados del desempeño de esta tarea por parte del modelo y la persona se reduce en aproximadamente un 50%. Los autores también prueban sistemáticamente métodos para seleccionar entradas apropiadas para mejorar la eficiencia, lo que resulta en un aumento de cuatro veces en la velocidad y una reducción en el uso de la memoria, mientras retiene el 92% de los resultados. Todos los modelos para diferentes tareas y tamaños se publican en el repositorio de GitHub , donde puede probarlos en una computadora portátil Colab .
Seguimiento semántico
, . , , , . , , , , , , , . .
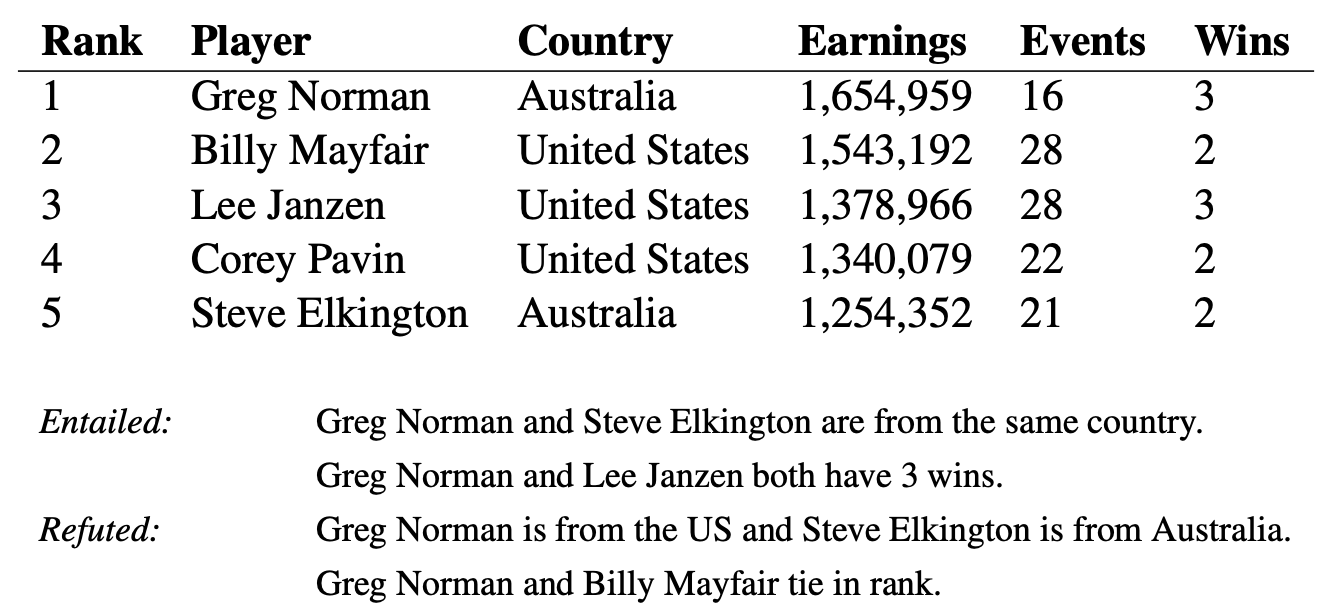
TabFact. .
, TAPAS, , , , .
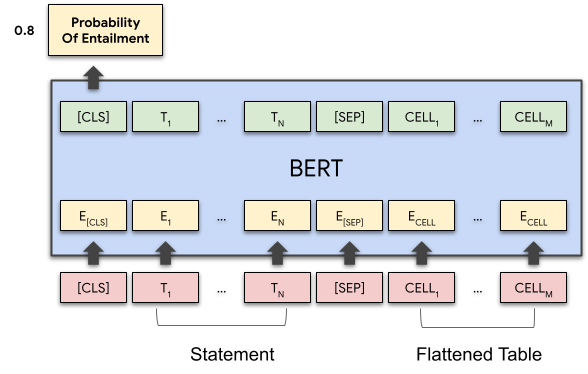
TAPAS BERT , . . .
— (.. «» «»), , , . , . , . , «Greg Norman and Billy Mayfair tie in rank» (« ») «tie» («»/«», «») , .
«» , . , . , TAPAS , . , : (counterfactual) (synthetic). ( — intermediate pre-training).
, (, ), . . , , . , . , , , , , .
, , , , (, « »), , (, « — »). , .

. , , , . , .
TabFact, TAPAS , , LogicalFactChecker (LFC) Structure Aware Transformer (SAT). TAPAS LFC SAT, (TAPAS + CS) , .
TAPAS + CS - SQA, . CS 4 , , .
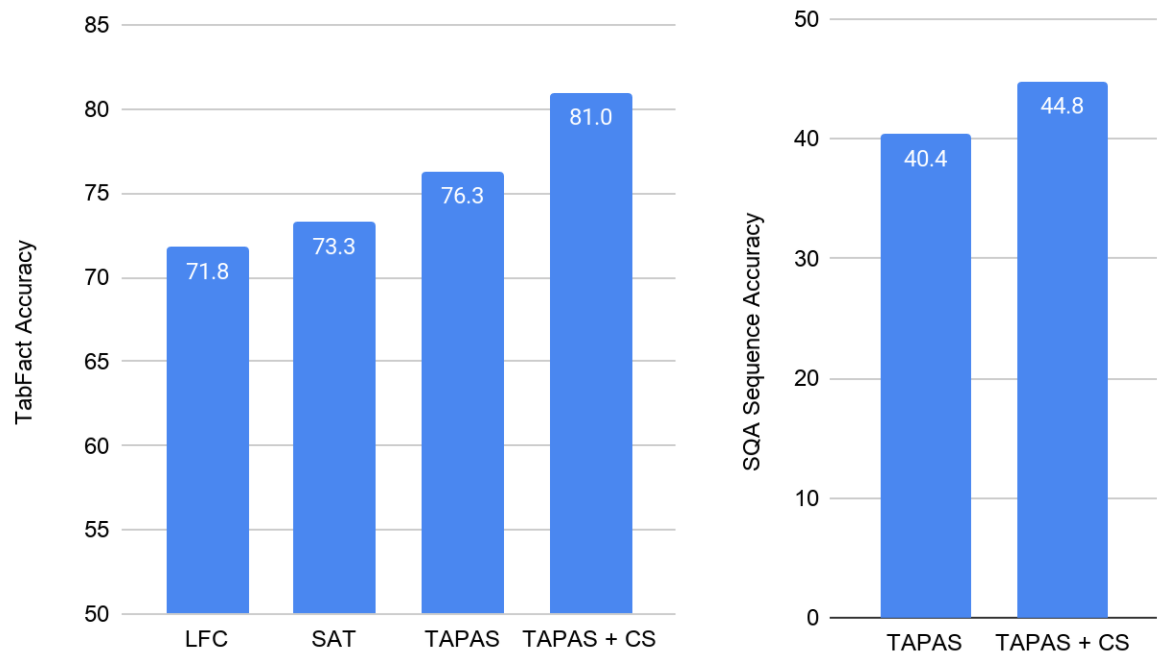
TabFact () SQA (). , .
, , , - TabFact. , ( ). , TAPAS + CS Table-Bert, 10% , .
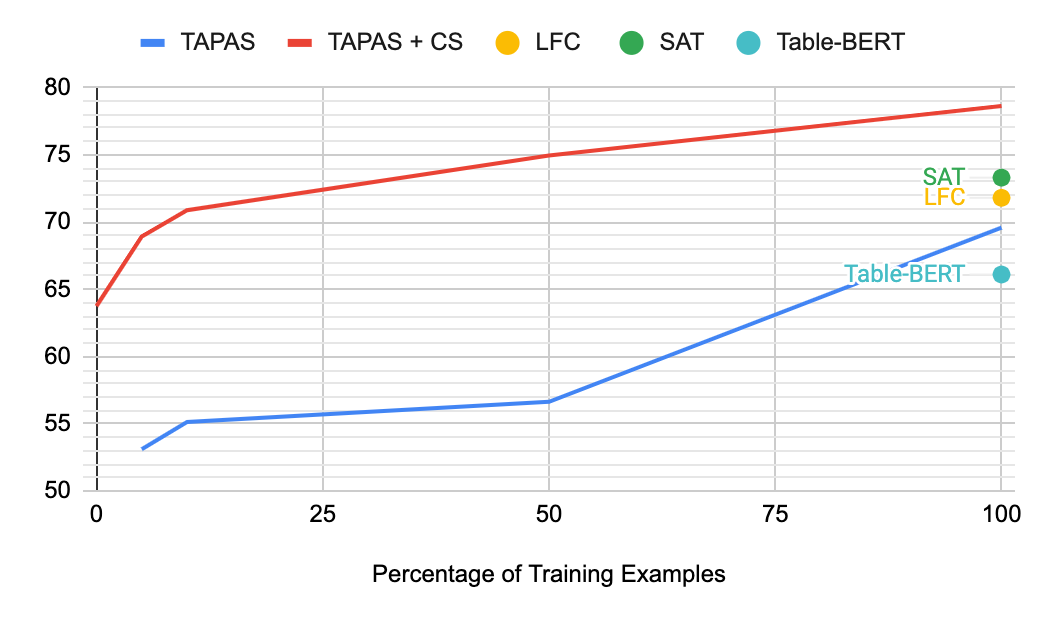
(Accuracy)
, , , . , .
, , , , . , , . , .
, , , 512 , ( , Reformer Performer, ). , TabFact. 256 , , . 128 - — 4 .
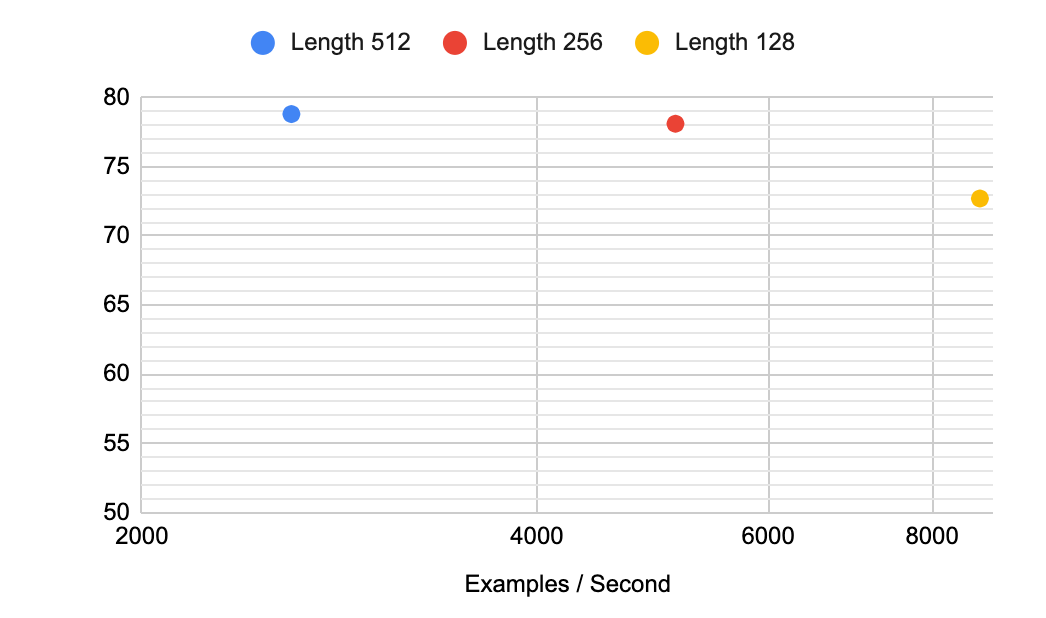
(Accuracy) TabFact .
, , .
Los autores han publicado los nuevos modelos y métodos de preaprendizaje en su repositorio de GitHub , donde puede probarlos usted mismo en colab . Para hacer este enfoque más accesible, los autores también compartieron modelos de varios tamaños, hasta " diminutos ", con la esperanza de que los resultados ayuden a estimular el desarrollo de tecnologías para comprender los datos tabulares entre una gama más amplia de investigadores.
Autores
- Autor original - Julian Eisenschlos
- Traducción - Ekaterina Smirnova
- Edición y maquetación - Sergey Shkarin