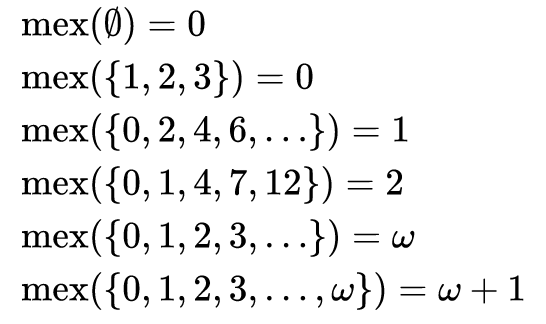
Analizaremos tres algoritmos y veremos su rendimiento.
Bienvenido bajo el corte
Prefacio
Antes de comenzar, me gustaría decirles: ¿por qué llevé a cabo este algoritmo?
Todo comenzó con un rompecabezas en OZON.

Como puede ver en el problema, en matemáticas, el resultado de la función MEX en un conjunto de números es el valor más pequeño de todo el conjunto que no pertenece a este conjunto. Es decir, este es el valor mínimo del conjunto de adiciones. El nombre "MEX" es una abreviatura del valor "Mínimo excluido".
Y después de hurgar en la red, resultó que no existe un algoritmo generalmente aceptado para encontrar MEX ...
Hay soluciones sencillas , hay opciones con matrices adicionales, gráficos, pero de alguna manera todo esto está disperso en diferentes rincones de Internet y no existe un solo artículo normal sobre este tema. Así nació la idea: escribir este artículo. En este artículo, analizaremos tres algoritmos para encontrar MEX y veremos qué obtenemos en términos de velocidad y memoria.
El código estará en C #, pero en general no habrá construcciones específicas.
El código básico para los cheques será así.
static void Main(string[] args)
{
//MEX = 2
int[] values = new[] { 0, 12, 4, 7, 1 };
//MEX = 5
//int[] values = new[] { 0, 1, 2, 3, 4 };
//MEX = 24
//int[] values = new[] { 11, 10, 9, 8, 15, 14, 13, 12, 3, 2, 0, 7, 6, 5, 27, 26, 25, 4, 31, 30, 28, 19, 18, 17, 16, 23, 22, 21, 20, 43, 1, 40, 47, 46, 45, 44, 35, 33, 32, 39, 38, 37, 36, 58, 57, 56, 63, 62, 60, 51, 49, 48, 55, 53, 52, 75, 73, 72, 79, 77, 67, 66, 65, 71, 70, 68, 90, 89, 88, 95, 94, 93, 92, 83, 82, 81, 80, 87, 86, 84, 107, 106, 104 };
//MEX = 1000
//int[] values = new int[1000];
//for (int i = 0; i < values.Length; i++) values[i] = i;
//
int total = 0;
int mex = GetMEX(values, ref total);
Console.WriteLine($"mex: {mex}, total: {total}");
Console.ReadKey();
}
Y un punto más en el artículo, a menudo menciono la palabra "matriz", aunque "conjunto" sería más correcto, entonces quiero disculparme de antemano con aquellos que serán cortados por esta suposición.
Nota 1 basada en comentarios : Muchos encontraron fallas en O (n), dicen que todos los algoritmos son O (n) y no les importa que "O" sea diferente en todas partes y en realidad no compara el número de iteraciones. Luego, para mayor tranquilidad, cambiamos O por T. Donde T es una operación más o menos comprensible: cheque o asignación. Entonces, según tengo entendido, será más fácil para todos
Nota 2 basada en comentarios : estamos considerando el caso cuando el juego original NO está ordenado. Ordenar estos conjuntos también lleva tiempo.
1) Decisión en la frente
¿Cómo encontramos el "número mínimo que falta"? La opción más fácil es hacer un contador e iterar sobre la matriz hasta que encontremos un número igual al contador.
static int GetMEX(int[] values, ref int total)
{
for (int mex = 0; mex < values.Length; mex++)
{
bool notFound = true;
for (int i = 0; i < values.Length; i++)
{
total++;
if (values[i] == mex)
{
notFound = false;
break;
}
}
if (notFound)
{
return mex;
}
}
return values.Length;
}
}
El caso más básico. La complejidad del algoritmo es T (n * celda (n / 2)) ... para el caso {0, 1, 2, 3, 4} necesitaremos iterar sobre todos los números ya que Realiza 15 operaciones. Y para una fila completamente completa de 100, incluidas 5050 operaciones ... Rendimiento regular.
2) Proyección
La segunda opción de implementación más compleja encaja en T (n) ... Bueno, o casi T (n), los matemáticos son astutos y no tienen en cuenta la preparación de datos ... Porque, al menos, necesitamos saber el número máximo en el set.
Desde el punto de vista de las matemáticas, se ve así.
Se toma una matriz de bits S de longitud m (donde m es la longitud de la matriz V) rellena con 0. Y en una pasada, el conjunto original (V) en la matriz (S) se establece en 1. Después de eso, en una pasada, encontramos el primer valor vacío. Todos los valores mayores que m pueden simplemente ignorarse. si la matriz contiene valores "insuficientes" hasta m, entonces obviamente será menor que la longitud de m.
static int GetMEX(int[] values, ref int total)
{
bool[] sieve = new bool[values.Length];
for (int i = 0; i < values.Length; i++)
{
total++;
var intdex = values[i];
if (intdex < values.Length)
{
sieve[intdex] = true;
}
}
for (int i = 0; i < sieve.Length; i++)
{
total++;
if (!sieve[i])
{
return i;
}
}
return values.Length;
}
Porque Los "matemáticos" son gente astuta. Luego dicen que solo hay una pasada a través de la matriz original para el algoritmo T (n) ... Se
sientan y se regocijan de que se haya inventado un algoritmo tan genial, pero la verdad es.
Primero, debe pasar por la matriz original y marcar este valor en la matriz S T1 (n). En
segundo lugar, debe pasar por la matriz S y encontrar la primera celda disponible T2 (n) allí
. todas las operaciones en general no son complicadas, todos los cálculos se pueden simplificar a T (n * 2)
Pero esto es claramente mejor que una solución sencilla ... Revisemos nuestros datos de prueba:
- Para el caso {0, 12, 4, 7, 1}: Frente : 11 iteraciones, tamizado : 8 iteraciones
- { 0, 1, 2, 3, 4 }: : 15 , : 10
- { 11,…}: : 441 , : 108
- { 0,…,999}: : 500500 , : 2000
El hecho es que si el "valor perdido" es un número pequeño, entonces, en este caso, una decisión frontal resulta ser más rápida, porque no requiere un triple atravesar la matriz. Pero en general, en grandes dimensiones pierde claramente con el tamizado, lo que no es realmente sorprendente.
Desde el punto de vista del "matemático", el algoritmo está listo y es genial, pero desde el punto de vista del "programador", es terrible debido a la cantidad de RAM desperdiciada y el último paso para encontrar el primer valor vacío obviamente quiere ser acelerado.
Hagamos esto y optimicemos el código.
static int GetMEX(int[] values, ref int total)
{
var max = values.Length;
var size = sizeof(ulong) * 8;
ulong[] sieve = new ulong[(max / size) + 1];
ulong one = 1;
for (int i = 0; i < values.Length; i++)
{
total++;
var intdex = values[i];
if (intdex < values.Length)
{
sieve[values[i] / size] |= (one << (values[i] % size));
}
}
var maxInblock = ulong.MaxValue;
for (int i = 0; i < sieve.Length; i++)
{
total++;
if (sieve[i] != maxInblock)
{
total--;
for (int j = 0; j < size; j++)
{
total++;
if ((sieve[i] & (one << j)) == 0)
{
return i * size + j;
}
}
}
}
return values.Length;
}
¿Qué hemos hecho aquí? En primer lugar, la cantidad de RAM necesaria se ha reducido 64 veces.
var size = sizeof(ulong) * 8;
ulong[] sieve = new ulong[(max / size) + 1];
Como resultado, el algoritmo tamiz nos da el siguiente resultado:
- Para el caso {0, 12, 4, 7, 1}: filtrado : 8 iteraciones, filtrado de optimización : 8 iteraciones
- Para el caso {0, 1, 2, 3, 4}: filtrado : 10 iteraciones, filtrado de optimización : 11 iteraciones
- Para el caso {11, ...}: tamizado : 108 iteraciones, tamizado con optimización : 108 iteraciones
- Para el caso {0, ..., 999}: filtrado : 2000 iteraciones, filtrado con optimización : 1056 iteraciones
Entonces, ¿cuál es la conclusión en la teoría de la velocidad?
Convertimos T (n * 3) en T (n * 2) + T (n / 64) en su conjunto, aumentamos ligeramente la velocidad e incluso redujimos la cantidad de RAM hasta 64 veces. Que bien)
3) Clasificación
Como puede adivinar, la forma más fácil de encontrar un elemento faltante en un conjunto es tener un conjunto ordenado.
El algoritmo de clasificación más rápido es "quicksort", que tiene una complejidad de T1 (n log (n)). Y en total, obtenemos la complejidad teórica para encontrar MEX en T1 (n log (n)) + T2 (n)
static int GetMEX(int[] values, ref int total)
{
total = values.Length * (int)Math.Log(values.Length);
values = values.OrderBy(x => x).ToArray();
for (int i = 0; i < values.Length - 1; i++)
{
total++;
if (values[i] + 1 != values[i + 1])
{
return values[i] + 1;
}
}
return values.Length;
}
Precioso. Nada extra.
Verifique el número de iteraciones
- Para el caso {0, 12, 4, 7, 1}: filtrado con optimización : 8, ordenación : ~ 7 iteraciones
- Para el caso {0, 1, 2, 3, 4}: cribado con optimización : 11 iteraciones, clasificación : ~ 9 iteraciones
- Para el caso {11, ...}: tamizado con optimización : 108 iteraciones, ordenando: ~356
- { 0,…,999}: : 1056 , : ~6999
Estos son valores medios y no son del todo justos. Pero en general: la clasificación no requiere memoria adicional y claramente le permite simplificar el último paso de la iteración.
Nota : values.OrderBy (x => x) .ToArray () - sí, sé que se ha asignado memoria aquí, pero si lo hace con prudencia, puede cambiar la matriz, no copiarla ...
Así que tuve una idea de optimizar la clasificación rápida para la búsqueda MEX. No encontré esta versión del algoritmo en Internet, ni desde el punto de vista de las matemáticas, y más aún desde el punto de vista de la programación. Luego escribiremos el código desde 0 en el camino, pensando en cómo se verá: D
Pero, primero, vamos recuerde cómo funciona la ordenación rápida. Daría un enlace, pero en realidad no hay una explicación normal de la ordenación rápida en los dedos, parece que los autores de los mismos manuales entienden el algoritmo mientras hablan de él ...
Así que esto es lo que es la ordenación rápida:
tenemos una matriz desordenada {0, 12, 4, 7, uno}
Necesitamos un "número aleatorio", pero es mejor tomar cualquiera de la matriz; esto se llama número de referencia (T).
Y dos punteros: L1: mira el primer elemento de la matriz, L2 mira el último elemento de la matriz.
0, 12, 4, 7, 1
L1 = 0, L2 = 1, T = 1 (T tomó los últimos estúpidos)
Primera etapa de iteración :
Hasta que trabajemos solo con el puntero L1,
muévelo a lo largo de la matriz hacia la derecha hasta encontrar un número mayor que nuestra referencia.
En nuestro caso, L1 es igual a 8.
Segunda etapa de la iteración :
Ahora cambiamos el puntero L2, lo
desplazamos a lo largo de la matriz hacia la izquierda hasta que encontremos un número menor o igual a nuestra referencia.
En este caso, L2 es igual a 1. Dado que Tomé el número de referencia igual al elemento extremo de la matriz y miré L2 allí también.
La tercera etapa de la iteración :
cambie los números en los punteros L1 y L2, no mueva los punteros.
Y pasamos a la primera etapa de la iteración.
Repetimos estos pasos hasta que los punteros L1 y L2 sean iguales, no sus valores, sino punteros. Esos. deben apuntar a un elemento.
Después de que los punteros converjan en algún elemento, ambas partes de la matriz aún no se ordenarán, pero seguro, en un lado de los "punteros combinados (L1 y L2)" habrá elementos que son menores que T, y en el otros, más que T. Es decir, este hecho nos permite dividir la matriz en dos grupos independientes, que se pueden ordenar en diferentes flujos en iteraciones posteriores.
Un artículo en la wiki, si no entiendo lo que está escrito
Escribamos Quicksort
static void Quicksort(int[] values, int l1, int l2, int t, ref int total)
{
var index = QuicksortSub(values, l1, l2, t, ref total);
if (l1 < index)
{
Quicksort(values, l1, index - 1, values[index - 1], ref total);
}
if (index < l2)
{
Quicksort(values, index, l2, values[l2], ref total);
}
}
static int QuicksortSub(int[] values, int l1, int l2, int t, ref int total)
{
for (; l1 < l2; l1++)
{
total++;
if (t < values[l1])
{
total--;
for (; l1 <= l2; l2--)
{
total++;
if (l1 == l2)
{
return l2;
}
if (values[l2] <= t)
{
values[l1] = values[l1] ^ values[l2];
values[l2] = values[l1] ^ values[l2];
values[l1] = values[l1] ^ values[l2];
break;
}
}
}
}
return l2;
}
Comprobemos el número real de iteraciones:
- Para el caso {0, 12, 4, 7, 1}: filtrado con optimización : 8, ordenación: 11
- Para el caso {0, 1, 2, 3, 4}: cribado con optimización : 11 iteraciones, clasificación : 14 iteraciones
- Para el caso {11, ...}: tamizado con optimización : 108 iteraciones, ordenación : 1520 iteraciones
- Para el caso {0, ..., 999}: tamizado con optimización : 1056 iteraciones, clasificación : 500499 iteraciones
Intentemos reflexionar sobre lo siguiente. La matriz {0, 4, 1, 2, 3} no tiene elementos faltantes y su longitud es 5. Es decir, resulta que la matriz en la que no faltan elementos es igual a la longitud de la matriz - 1. Es decir, m = {0, 4, 1, 2, 3}, Longitud (m) == Max (m) + 1. Y lo más importante en este momento es que esta condición es verdadera si los valores en la matriz son reorganizado. Y lo importante es que esta condición se puede extender a partes de la matriz. Es decir, así:
{0, 4, 1, 2, 3, 12, 10, 11, 14} sabiendo que en el lado izquierdo de la matriz todos los números son menores que un determinado número de referencia, por ejemplo 5, y en a la derecha, todo lo que sea más grande no tiene sentido buscar el número mínimo a la izquierda.
Esos. si sabemos con certeza que en una de las partes no hay elementos mayores que un cierto valor, entonces este número faltante debe buscarse en la segunda parte de la matriz. En general, así es como funciona el algoritmo de búsqueda binaria.
Como resultado, se me ocurrió la idea de simplificar la ordenación rápida para las búsquedas MEX combinándola con la búsqueda binaria. Permítame decirle de inmediato que no necesitaremos ordenar completamente la matriz completa, solo aquellas partes en las que buscaremos.
Como resultado, obtenemos el código
static int GetMEX(int[] values, ref int total)
{
return QuicksortMEX(values, 0, values.Length - 1, values[values.Length - 1], ref total);
}
static int QuicksortMEX(int[] values, int l1, int l2, int t, ref int total)
{
if (l1 == l2)
{
return l1;
}
int max = -1;
var index = QuicksortMEXSub(values, l1, l2, t, ref max, ref total);
if (index < max + 1)
{
return QuicksortMEX(values, l1, index - 1, values[index - 1], ref total);
}
if (index == values.Length - 1)
{
return index + 1;
}
return QuicksortMEX(values, index, l2, values[l2], ref total);
}
static int QuicksortMEXSub(int[] values, int l1, int l2, int t, ref int max, ref int total)
{
for (; l1 < l2; l1++)
{
total++;
if (values[l1] < t && max < values[l1])
{
max = values[l1];
}
if (t < values[l1])
{
total--;
for (; l1 <= l2; l2--)
{
total++;
if (values[l2] == t && max < values[l2])
{
max = values[l2];
}
if (l1 == l2)
{
return l2;
}
if (values[l2] <= t)
{
values[l1] = values[l1] ^ values[l2];
values[l2] = values[l1] ^ values[l2];
values[l1] = values[l1] ^ values[l2];
break;
}
}
}
}
return l2;
}
Verifique el número de iteraciones
- Para el caso {0, 12, 4, 7, 1}: cribado con optimización : 8, ordenación MEX : 8 iteraciones
- { 0, 1, 2, 3, 4 }: : 11 , MEX: 4
- { 11,…}: : 108 , MEX: 1353
- { 0,…,999}: : 1056 , MEX: 999
Tenemos diferentes opciones de búsqueda MEX. Cuál es mejor depende de ti.
Generalmente. Lo que más me gusta es la proyección , y estas son las razones:
Tiene un tiempo de ejecución muy predecible. Además, este algoritmo se puede utilizar fácilmente en modo multiproceso. Esos. divida la matriz en partes y ejecute cada parte en un hilo separado:
for (int i = minIndexThread; i < maxIndexThread; i++)
sieve[values[i] / size] |= (one << (values[i] % size));
Lo único que necesita es bloquear al escribir tamiz [valores [i] / tamaño] . Y una cosa más: el algoritmo es ideal para descargar datos de la base de datos. Puede cargar en paquetes de 1000 piezas, por ejemplo, en cada flujo y seguirá funcionando.
Pero si tenemos una grave escasez de memoria, entonces la clasificación MEX se ve claramente mejor.
PD
Comencé mi historia con un concurso para OZON en el que traté de participar, haciendo una "versión preliminar" del algoritmo de cribado, nunca recibí un premio por ello, OZON lo consideró insatisfactorio ... Por qué razones - nunca confesó. .. Y el código del ganador tampoco lo he visto. ¿Alguien puede tener alguna idea sobre cómo resolver mejor el problema de búsqueda MEX?