
En este artículo, hablaré sobre uno de los métodos para corregir el desequilibrio de las clases predichas. Es importante aclarar que muchos de los métodos que construyen modelos probabilísticos funcionan bien sin corregir el desequilibrio. Sin embargo, cuando pasamos a construir modelos de improbabilidad o cuando consideramos un problema de clasificación con un gran número de clases, vale la pena atender al problema del desequilibrio de clases.
, ́ , , , . , .
NearMiss — . ́ . , .
. pip cmd:
pip install pandas
pip install numpy
pip install sklearn
pip install imblearn
, - -.
import pandas as pd
import numpy as np
df = pd.read_csv('online_shoppers_intention.csv')
df.shape
(12330, 18)
«Revenue» 2 : True ( ) False ( ). , .
df['Revenue'].value_counts()
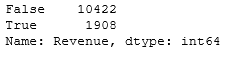
, , 85% 15%.
:
Y = df['Revenue']
X = df.drop('Revenue', axis = 1)
feature_names = X.columns
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3, random_state = 97)
:
print(' X_train: ', X_train.shape)
print(' Y_train: ', Y_train.shape)
print(' X_test: ', X_test.shape)
print(' Y_test: ', Y_test.shape)

.
from sklearn.linear_model import LogisticRegression
lregress1 = LogisticRegression()
lregress1.fit(X_train, Y_train.ravel())
prediction = lregress1.predict(X_test)
print(classification_report(Y_test, prediction))
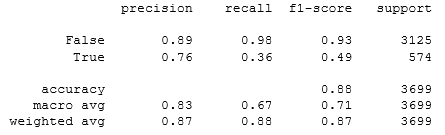
, 88%. «recall» , . , , .
NearMiss :
print(' - True: {}'.format(sum(y_train == True)))
print(' - False: {}'.format(sum(y_train == False)))
True: 1334
False: 7297
.
from imblearn.under_sampling import NearMiss
nm = NearMiss()
X_train_miss, Y_train_miss = nm.fit_resample(X_train, Y_train.ravel())
print(' - True: {}'.format(sum(Y_train_miss == True)))
print(' - False: {}'.format(sum(Y_train_miss == False)))
True: 1334
False: 1334
Se puede ver que el método ha nivelado las clases, disminuyendo la dimensión de la clase dominante. Usemos la regresión logística y visualicemos un informe con los principales indicadores de clasificación.
lregress2 = LogisticRegression()
lregress2.fit(X_train_miss, Y_train_miss.ravel())
prediction = lregress2.predict(X_test)
print(classification_report(Y_test, prediction))

El valor de las opiniones de las minorías se elevó al 84%. Pero debido al hecho de que la muestra de la clase más grande se redujo significativamente, la precisión del modelo disminuyó al 61%. Entonces, este método realmente ayudó a lidiar con el desequilibrio de clases.