 En ABBYY hemos estado lidiando con problemas de procesamiento del lenguaje natural (NLP) durante mucho tiempo
. Las tecnologías de procesamiento del lenguaje natural están en el corazón de muchas de las soluciones NLP de ABBYY para buscar y extraer datos. Con su ayuda, ayudamos al gigante industrial NPO Energomash
a realizar una búsqueda según los documentos acumulados en la empresa durante casi 100 años, y uno de los grandes bancos
utilizanuestra tecnología para monitorear el gigantesco flujo de noticias y administrar el riesgo. En esta publicación, explicaremos cómo nuestras tecnologías de PNL funcionan internamente para extraer información de texto sólido. No hablaremos de texto en tablas y formularios claramente estructurados, como notas de envío, sino de documentos no estructurados de varias páginas: contratos de arrendamiento, registros médicos y mucho más.
En ABBYY hemos estado lidiando con problemas de procesamiento del lenguaje natural (NLP) durante mucho tiempo
. Las tecnologías de procesamiento del lenguaje natural están en el corazón de muchas de las soluciones NLP de ABBYY para buscar y extraer datos. Con su ayuda, ayudamos al gigante industrial NPO Energomash
a realizar una búsqueda según los documentos acumulados en la empresa durante casi 100 años, y uno de los grandes bancos
utilizanuestra tecnología para monitorear el gigantesco flujo de noticias y administrar el riesgo. En esta publicación, explicaremos cómo nuestras tecnologías de PNL funcionan internamente para extraer información de texto sólido. No hablaremos de texto en tablas y formularios claramente estructurados, como notas de envío, sino de documentos no estructurados de varias páginas: contratos de arrendamiento, registros médicos y mucho más.
A continuación, le mostraremos cómo funciona esto en la práctica. Por ejemplo, cómo extraer X entidades de un acuerdo bancario de 200 páginas en X minutos. Asegúrese de que el contrato legal sea correcto u obtenga información sobre los efectos secundarios raros rápidamente de una colección de artículos médicos. Nuestra experiencia demuestra que las empresas necesitan obtener dichos datos de forma rápida y sin errores, ya que de ello depende el bienestar tanto de las empresas como de las personas.
Al final del post, mencionaremos varias dificultades que encontramos al realizar dichos proyectos y compartiremos nuestra experiencia de cómo logramos resolverlas. Bien, bienvenido a cat.
¿Entonces que estamos haciendo?
En general, las tecnologías de procesamiento y análisis del lenguaje natural permiten mucho: filtrar el correo no deseado en el correo electrónico, crear sistemas de traducción automática, reconocer el habla y desarrollar y entrenar bots de chat. Las tecnologías NLP de ABBYY ayudan a los bancos, organizaciones industriales y otras a extraer y estructurar rápidamente una gran cantidad de información de documentos comerciales. Las grandes empresas llevan mucho tiempo automatizando, o al menos esforzándose por reducir, el número de operaciones manuales y rutinarias. Estamos hablando de buscar en un documento en papel la fecha, el nombre completo, el monto, el TIN, el número de factura; reimpresión de datos en sistemas de información corporativos, comprobando si todo está correctamente cumplimentado
Recuerde que inicialmente pudimos extraer texto de documentos basados en características geométricas, en particular la estructura y disposición de líneas y campos. Así, sigue siendo conveniente procesar información de cuestionarios estructurados, formularios estrictos, cuestionarios, solicitudes, formularios censales, etc. Por cierto, hablamos en Habré sobre tal caso: con la ayuda de ABBYY FlexiCapture, el Ministerio de Salud de Bangladesh procesó los cuestionarios del censo médico completados por residentes de la república.
Está claro que la información importante se almacena no solo en formularios, por lo que capacitamos a nuestras soluciones de PNL para "extraer" datos de documentos que no tienen ninguna estructura o que son extremadamente complejos. Probablemente mucha gente recuerde ABBYY Compreno para el análisis y la comprensión del lenguaje natural. Hemos desarrollado y mejorado la tecnología y, posteriormente, formó la base de muchas de nuestras soluciones de PNL. Uno de los casos de uso de NLP es un proyecto con noticias de seguimiento en varios grandes bancos rusos. En resumen, nuestro motor puede realizar el trabajo de un asegurador bancario: una persona que capta eventos sobre contrapartes a partir de un flujo gigantesco de información y evalúa los riesgos. Lea más sobre esto aquí .
A continuación, hablaremos de otro aspecto: la extracción de información de documentos no estructurados como contratos, registros médicos, noticias de diversas fuentes.

Cómo funcionan nuestras tecnologías de PNL
Conceptualmente, el procesamiento de documentos desde el momento en que se carga en ABBYY FlexiCapture hasta que se extraen los campos obligatorios se ve así:
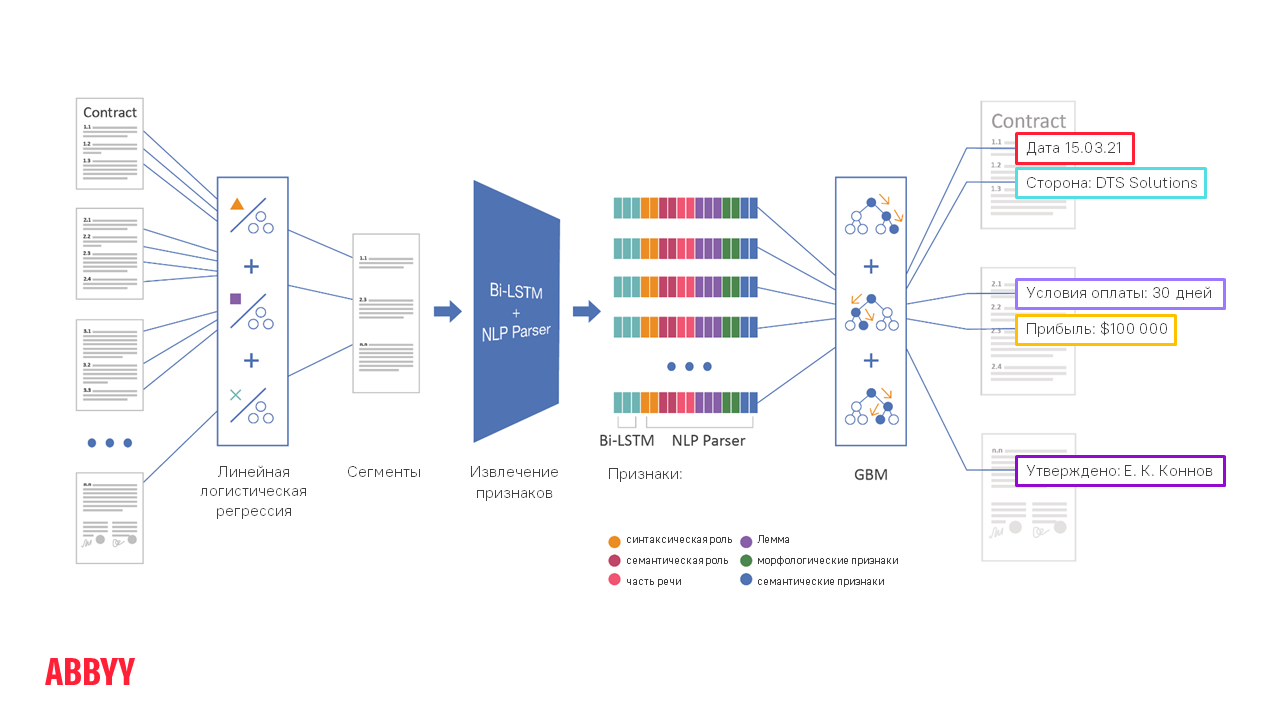
Supongamos que necesita extraer la fecha y el lugar de la firma, así como los nombres de las empresas participantes de un contrato de 50 páginas. . ¡50 páginas, Karl! ¡Y hay muchas citas! ¿Cómo encuentro la página que busca el cliente? La tecnología ayuda a hacer esto en varias etapas.
Etapa de segmentación
A continuación, se segmenta el documento, es decir, delimitamos el área para encontrar información y procesamos no las 50 páginas, sino solo, digamos, 5 segmentos por párrafo, donde puede estar la fecha que necesitamos. Por lo tanto, es mucho más fácil que los algoritmos funcionen, así como también distinguir la fecha requerida de alguna otra.
Todas las etapas a la derecha de la segmentación en el diagrama describen el funcionamiento de los algoritmos de PNL : estudio detallado, lectura y comprensión del texto. Estos procesos tardan entre 10 y 20 veces más que la clasificación y la segmentación, por lo que no es del todo correcto ejecutarlos en un documento completo de varias páginas. Es más fácil "incitarlos" a una pequeña cantidad de texto.
Cómo funcionan NLP Parser + Bi-LSTM
Con su ayuda, se extraen signos (características) de cada oración del texto. Esta es la tecnología ABBYY Compreno, que funciona como parte de FlexiCapture. El motor lee el texto en detalle y extrae muchas características de generalización. Entiende no solo lo que está específicamente formulado en esta oración, sino también el significado, lo que realmente significa.
La extracción de características es un paso largo. Hay señales de alto nivel. En términos generales, indican que en este fragmento, algo como un nombre hace algo como una acción con algún objeto de alguna clase semántica. Luego, en las características extraídas de alto nivel, se aplica un método ML-GBM bastante simple y clásico. Es un conjunto de árboles de decisión que proporciona una solución general y resalta los campos extraídos. Para que GBM aprenda rápidamente y extraiga información de calidad, es importante tener una cantidad suficiente de documentos para la capacitación. Si hay pocos, la calidad de la extracción de información puede disminuir. Esto se debe al hecho de que el núcleo de casos se vuelve más pequeño y, en consecuencia, la "máquina" es peor para generalizar, para distinguir los casos individuales de los frecuentes.

¿Dónde se usa?
A continuación se muestran algunos ejemplos de nuestra práctica: proyectos implementados, pilotos o casos conceptuales.
PNL para instituciones financieras

Los clientes a menudo nos piden que procesemos facturas (facturas) y órdenes de compra. Algunos datos (o campos), bloques con texto o con una dirección, se pueden extraer mediante métodos tradicionales, basándose en palabras clave. Pero si necesita mirar dentro de un bloque de texto, entonces se necesita PNL. También sucede que necesita "obtener" no todo el bloque con la dirección, sino solo una parte de esta dirección: calle, estado, ciudad, código postal, país. O necesita analizar las fechas y los porcentajes de descuento si la factura requiere el pago antes de una fecha específica. Nuestras tecnologías ayudan a tener en cuenta tales variables: cuánto costará un pedido si se paga por adelantado o al por mayor, y cuánto si se paga con retraso.
También ayudamos a los departamentos legales de grandes empresas a extraer datos importantes de contratos de servicio, informes de progreso, NDA (documentos de no divulgación). Tomemos como ejemplo uno de nuestros proyectos relacionados con contratos de arrendamiento comercial. Eran documentos de 30 páginas, datos de los campos de cada página que el cliente ingresaba previamente al sistema de información de forma manual. Por lo general, esto tomaba una hora para un documento. FlexiCapture completó la tarea en dos minutos y, según los cálculos del cliente, le ahorró 5000 horas-hombre en un año.
O acepte acuerdos de préstamo. Los préstamos no solo los toman las personas, sino también las grandes empresas. Para ello, proporcionan al banco un gran paquete de documentos. Digamos información sobre préstamos comerciales disponibles. Y esto no es una especie de hipoteca por 6 millones de rublos, sino una hipoteca por 100 millones de dólares (para edificios, oficinas). Y luego el banco necesita extraer 50-70 entidades o condiciones de un documento de 250 páginas de este tipo. Tomó mucho tiempo procesarlo manualmente, según los cálculos de nuestros clientes: 2-3 horas por documento. Con FlexiCapture, todo estuvo listo en 9 minutos. No instantáneamente, entendemos. El motivo está en el diseño de los documentos: suelen tener una alta densidad de texto y se deben extraer una gran cantidad de entidades diferentes. Ni una segunda cosa :)
Las solicitudes de préstamo también se procesan a menudo. Este es un documento preliminar con preguntas que el banco envía al cliente. Cuanto mayor sea el monto del préstamo, más preguntas habrá en dicho cuestionario. Por ejemplo, en la información sobre el lugar de trabajo, el banco puede pedirle que indique su identificador y domicilio legal. Los bancos a menudo requieren una aclaración de la información sobre el estado civil, la disponibilidad de préstamos, las deudas por servicios públicos, la pensión alimenticia y otras cosas que pueden interferir con el pago del préstamo. A veces las preguntas en las Solicitudes de Préstamo son bastante complejas, por lo que algunas empresas ayudan a sus clientes a traducir del lenguaje legal al público para comprender y describir de manera humana lo que quieren del cliente.
En el procesamiento de estos documentos completos, la principal dificultad radica en la gran cantidad de campos (en nuestro caso, eran 105). Es fácil para un empleado de banco confundirse con ellos, pero esto no puede derribar la tecnología. FlexiCapture dedica 5 minutos a todo, un empleado, hasta 2-3 horas. Sienta la diferencia, como dicen.
Salud
Parte de los proyectos de ABBYY están relacionados con la extracción de información de documentos médicos.

Por ejemplo, utilizando PNL, puede procesar el Resumen de artículos médicos científicos. Existe tal dirección en farmacología: farmacovigilancia. Está investigando los efectos secundarios que pueden causar los nuevos fármacos en pacientes que aún no han sido descritos. Las organizaciones médicas recopilan información sobre estos casos críticos de los pacientes y elaboran informes detallados sobre ellos: informes de seguridad de casos individuales (ICSR). Si una nueva píldora daña a una persona, el fabricante debe informar rápidamente de ello al organismo regulador, de lo contrario, podría enfrentarse a una gran multa. Para evitar tales consecuencias, los empleados altamente calificados de las empresas farmacéuticas leen el ICSR en grandes cantidades. Una tarea bastante tediosa.
Es mucho más fácil descifrar tecnologías con estos. Como parte de uno de los pilotos de Farmacovigilancia, nuestra tecnología extrajo datos de artículos médicos como el sexo y la edad del paciente, información sobre el evento que le sucedió y el nombre del fármaco. Todo, excepto el último, se extrajo mediante aprendizaje automático. Pero para los nombres de las drogas, usamos un método más simple: los diccionarios. La conclusión es que el cliente pidió extraer no todos los medicamentos posibles de los artículos, sino medicamentos de una lista con 80 nombres. En este caso, la coincidencia del diccionario funcionó bien. Los diccionarios también forman parte de FlexiCapture NLP. La morfología se utiliza para encontrar el nombre de un fármaco. No importa en qué forma o registro esté escrita la palabra, especialmente en inglés no hay tantas.
El procesamiento de historias de casos también está automatizado, porque hay mucha información para revisar. Estos son tablas, recibos y una descripción de la decisión de la compañía de seguros. Por ejemplo, uno de los reguladores de Estados Unidos acepta quejas de pacientes sobre seguros. Sucede que la compañía de seguros se niega a pagar el tratamiento. Las razones pueden ser diferentes, pero el paciente tiene derecho a averiguarlo y presentar una solicitud a la agencia gubernamental. Y el regulador debe analizar la información y emitir un veredicto, ¿estaba realmente justificada la negativa?
Si las tablas se procesan fácilmente con FlexiLayout, entonces los fragmentos de texto con la decisión del seguro de no procesar. Usamos PNL para extraer la solución en sí y su fundamento del texto.
Los historiales médicos deben analizarse cuidadosamente cuando se transfiere a un paciente de un hospital a otro. Dado que vivimos en una época de coronavirus, a veces hay muchos de esos pacientes y es difícil para el personal del hospital hacer frente a demasiados trámites burocráticos. El caso en el que participamos no tuvo nada que ver con la corona, pero potencialmente nuestra experiencia sigue siendo valiosa.
Bienes Raíces
- Uno de nuestros clientes potenciales alquila mucho terreno para construcción y oficinas. En consecuencia, la empresa celebra muchos contratos de arrendamiento.... Necesita procesar automáticamente dichos documentos: extraer de ellos las fechas y los plazos, para que luego pueda rastrear si fallan en los pagos, cuándo finaliza el contrato de arrendamiento, dónde se renueva automáticamente el contrato, cuánto cuesta todo.
- Las empresas constructoras también cuentan con especialistas como analistas de cartera... Analizan los contratos, averiguan cuánto cuesta una propiedad en particular y ayudan a evaluar qué tan buena es y cuántos ingresos puede aportar al propietario. Como puntuación bancaria. En los EE. UU., Por cierto, puede vender o comprar parcialmente un paquete de hipotecas. Este es un valor, también puede subir o bajar de precio. Por ejemplo, si los precios inmobiliarios suben, se puede refinanciar una hipoteca que cueste menos. Y si todo se vuelve más barato, entonces el cliente intenta deshacerse de este papel.
En dicho contrato, hay información que se recupera tanto con la ayuda de PNL como sin ella. Datos tabulares: usando FlexiLayout (esto es lo que podíamos hacer antes). Y todos los demás campos son párrafos extraídos por el segmentador, o campos dentro de párrafos extraídos por modelos de extracción.
La ventaja de las tecnologías de PNL es que es otro mecanismo mediante el cual se pueden procesar más tipos de campos y documentos.

- Uno de nuestros clientes es la asociación de propietarios, condicionalmente nuestro SNT . Si un nuevo participante entra en dicho SNT, se le entrega un paquete de 9 tipos de documentos: escrituras (esto puede ser un acuerdo de compraventa). Luego, los datos de estos documentos completos deben procesarse, verificarse e ingresarse en el sistema de información. 8 de ellos están estructurados y procesados por FlexiLayout. Pero el noveno con una trampa. Para completar este proyecto, nuestra empresa también necesitaba procesar actos no estructurados.
Que es lo que hicimos usando NLP. Los documentos en sí mismos, por un lado, no son demasiado voluminosos: 1-2 páginas. Por otro lado, son muy diversos y de mala calidad. A pesar de esto, nuestra solución pudo extraer la información requerida. Este proyecto es interesante porque su parte de PNL puede ser muy pequeña, pero al mismo tiempo crítica, porque el proyecto simplemente no se puede completar sin él.
- Necesidades de PNL y para automatizar el proceso de aprobación de contratos (Contract Approval Automation). Las empresas a menudo celebran un acuerdo marco, un acuerdo marco (marco) que establece los términos generales para una serie de operaciones futuras. Por ejemplo, qué debe cumplir el cliente, en qué plazo, qué sanciones por retrasos, cuándo pagar los servicios.
El proceso de aprobación automática de un contrato se ve así: extraemos una cierta cantidad de campos y condiciones (cláusula) del documento. Los campos son una o más palabras y la cláusula es uno o más párrafos que pueden contener descripciones largas. Una empresa necesita extraer campos para indexar documentos en ellos, guardarlos en un almacenamiento electrónico y luego buscarlos. En la cláusula, se produce la aprobación, verificando si las condiciones son correctas. Los términos de la tecnología extraída se comparan con los términos del contrato marco. Si todo coincide, entonces no hay riesgos para la empresa, puede aprobar (revisar) automáticamente y enviar el contrato a la base de datos. Esto hace la vida mucho más fácil para los abogados: en lugar de tratar con el mismo tipo de contratos, pueden pasar a tareas más importantes.El contrato deberá ser revisado solo si el sistema revela en el documento alguna inconsistencia con el principal.

Lo que une a todos los proyectos de PNL
En las facturas estructuradas, donde reconocemos el monto y la dirección, queda claro de inmediato dónde se encuentran los campos requeridos, y los documentos en sí ocupan una o varias páginas. En el caso de documentos no estructurados, no siempre es posible determinar rápidamente qué datos y de dónde extraerlos; esta es la característica principal de los proyectos de PNL. Además, los documentos en sí ocupan no una página, sino 100-200 páginas. Por lo tanto, en la etapa de desarrollo de requisitos, primero le pedimos al cliente que compile una lista de varias docenas de campos que deben recuperarse. Dichos proyectos requieren la participación de un experto en la materia, un experto en este campo, que responderá a las preguntas de qué y en qué caso se debe extraer del documento y a qué matices prestar atención.
A veces, un cliente solicita extraer varios cientos de campos de un documento a la vez. Este enfoque no es constructivo y lleva al hecho de que se necesitan más de un mes para discutir los requisitos del proyecto. Es por eso que, por regla general, no comenzamos con cientos de campos, sino con 10, aclaramos los requisitos, demostramos cómo funcionará todo. Como resultado, tanto nosotros como el cliente comprendemos las etapas posteriores del proyecto y los hitos.
Además, para cualquier proyecto de aprendizaje automático, ML, incluida la PNL, se necesita una muestra representativa: muestras de documentos del cliente en los que se capacitará al sistema. Mientras más, mejor.
Conclusión
Con estos ejemplos, hemos demostrado cómo la tecnología ayuda a ahorrar nuestro principal recurso: el tiempo. En inglés, el esquema se llama ganar-ganar: los robots asumen tareas repetitivas y los empleados liberan sus manos para participar en proyectos más inteligentes e interesantes. Las empresas en las que no son especialistas, sino máquinas que se dedican a la rutina, pueden generar interacciones con los clientes de manera más eficiente, evitar errores en el procesamiento de ciertos documentos y aumentar la rentabilidad más rápidamente.