Una base de datos en memoria no es un concepto nuevo. Pero está demasiado asociado con las palabras "caché" y "no persistente". Hoy explicaré por qué este no es necesariamente el caso. Las soluciones en memoria tienen un campo de aplicación mucho más amplio y un nivel de confiabilidad mucho más alto de lo que parece.
En este artículo, analizo los principios arquitectónicos de las soluciones en memoria. ¿Cómo puede aprovechar lo mejor del mundo en memoria, un rendimiento increíble, y no sacrificar las virtudes de los sistemas relacionales basados en disco? En primer lugar, confiabilidad: ¿cómo puede estar seguro de que sus datos están seguros?
Esta historia condensa 10 años de experiencia con soluciones en memoria en un solo texto. El umbral de entrada es lo más bajo posible. No es necesario tener tantos años de experiencia para beneficiarse de la lectura, un conocimiento básico de TI es suficiente.
- Introducción
- Historia del desarrollo
- Tarantool hoy
- Como funciona el kernel
- Lua
- Fibra y multitarea cooperativa
- Funcionalidad de la base de datos
- Comparación con otros sistemas
- Escenarios de uso
- Conclusión y conclusiones
- Enlaces
Introducción
Mi nombre es Vladimir Perepelitsa, pero soy más conocido como Mons Anderson. Soy arquitecto y jefe de producto de Tarantool. Lo he estado usando durante muchos años en producción, por ejemplo, al construir un almacenamiento de objetos compatible con S3 [1]. Por lo tanto, lo conozco bastante bien por dentro y por fuera.
Para comprender la tecnología, es útil sumergirse en la historia. Descubriremos cómo era Tarantool, qué pasó, qué es hoy, lo compararemos con otras soluciones, consideraremos su funcionalidad, cómo puede funcionar en la red, qué hay en el ecosistema circundante.
Este ejemplo nos permitirá comprender qué beneficios puede obtener de las soluciones en memoria. Aprenderá cómo evitar sacrificar la confiabilidad, la escala y la facilidad de uso.
PD: esta es una transcripción de una lección abierta, adaptada para el artículo. Si prefiere escuchar YouTube en 2x, un enlace al video lo espera al final del artículo [2].
Historia del desarrollo
Tarantool fue creado por el equipo de desarrollo interno de Mail.ru Group en 2008, inicialmente sin ningún alcance para el código abierto. Sin embargo, después de dos años de operación dentro de la empresa, nos dimos cuenta de que el producto estaba lo suficientemente maduro como para compartirlo con el público. Así es como comenzó la historia del código abierto de Tarantool.
commit 9b8dd7032d05e53ffcbde78d68ed3bd47f1d8081 Author: Yuriy Vostrikov <vostrikov@corp.mail.ru> Date: Thu Aug 12 11:39:14 2010 +0400
Pero, ¿por qué fue creado?
Tarantool se desarrolló originalmente para la red social My World. En ese momento, ya éramos una empresa bastante grande. Un clúster de MySQL que almacena perfiles, sesiones y usuarios cuesta mucho. Tanto es así que además de la productividad, pensamos en el dinero. De aquí nació la historia "Cómo ahorrar un millón de dólares en la base de datos" [3].
Es decir, Tarantool se creó para ahorrar dinero en grandes clústeres de MySQL. Pasó por una evolución gradual: era solo un caché, luego un caché persistente y luego una base de datos completa .
Habiéndose ganado una reputación interna en un proyecto, comenzó a extenderse a otros: correo, banners publicitarios, la nube. Como resultado del uso generalizado dentro de la empresa, a menudo se lanzan nuevos proyectos en Tarantool de forma predeterminada.
Si sigue la historia del desarrollo de Tarantool, puede ver la siguiente imagen. Tarantool era originalmente un caché en memoria. En sus inicios, casi no era diferente de memcached.
Para resolver los problemas de caché en frío, Tarantool se volvió persistente. Se le añadió más replicación. Cuando tenemos una caché persistente con replicación, esta ya es una base de datos de valores clave. Se agregaron índices a esta base de datos de valores clave, es decir, pudimos usar Tarantool casi como una base de datos relacional.
Y luego agregamos funciones de Lua. Inicialmente, estos eran procedimientos almacenados para trabajar con datos. Las funciones de Lua luego evolucionaron a un tiempo de ejecución cooperativo y un servidor de aplicaciones.
Gradualmente, todo esto se superó con varios chips, capacidades y otros motores de almacenamiento adicionales. Hoy ya es una base de datos multiparadigma. Más sobre esto.
Tarantool hoy
En la actualidad, Tarantool es una plataforma informática en memoria de esquemas de datos flexible.
Tarantool puede y debe usarse para crear aplicaciones de alta carga . Es decir, implementar soluciones complejas para almacenar y procesar datos, y no solo hacer cachés. Además, no es solo una base de datos, sino una plataforma en la que puede crear algo.
Tarantool viene en dos versiones. Disponible para la mayoría, la más comprensible y conocida es la versión de código abierto. Tarantool se desarrolla bajo una licencia BSD simplificada, alojada completamente en GitHub por la organización Tarantool.
Allí tenemos el propio Tarantool, su núcleo, conectores a sistemas externos, topologías como sharding o colas; módulos, bibliotecas, tanto del equipo de desarrollo como de la comunidad. Los módulos de la comunidad pueden ser alojados por nosotros.
Además de la versión de código abierto, Tarantool también tiene una sucursal empresarial. En primer lugar, se trata de soporte, productos empresariales, formación, desarrollo personalizado y consultoría. Hoy vamos a hablar de la principal funcionalidad que tienen todas las versiones del producto.
Tarantool es hoy un componente básico para aplicaciones centradas en bases de datos.
¿Cómo funciona el kernel?
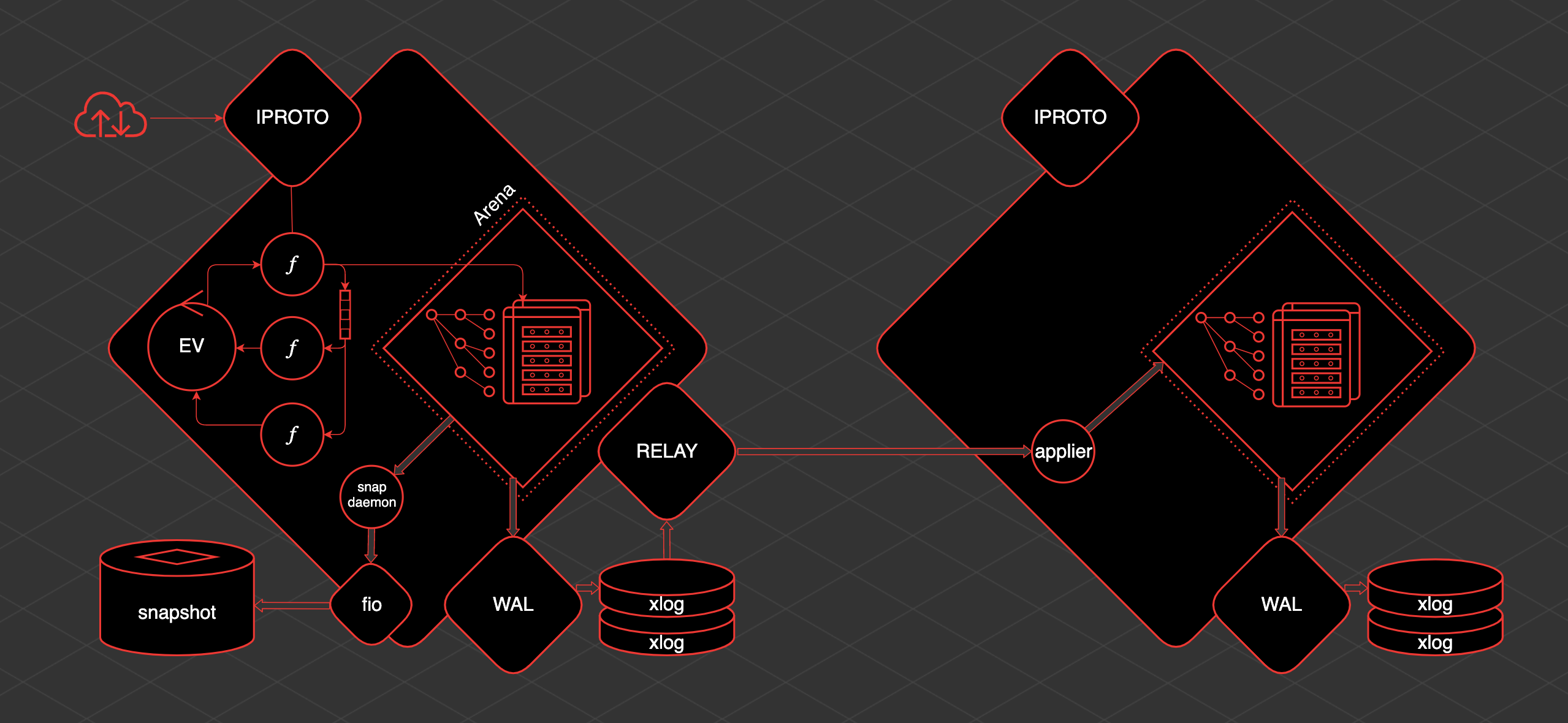
La idea principal en torno a la cual nació y se desarrolló Tarantool es que los datos están en la memoria. Siempre se accede a estos datos desde un hilo. Los cambios que hacemos se escriben linealmente en el registro de escritura anticipada.
Los índices se basan en los datos almacenados en la memoria. Es decir, tenemos acceso indexado y predecible a los datos. Periódicamente se guarda una instantánea de estos datos. Lo que se escribe en el disco se puede replicar.
Tarantool tiene un hilo transaccional principal. Lo llamamos hilo TX. Dentro de este hilo, está Arena. Esta es un área de memoria asignada por Tarantool para almacenar datos. Los datos se almacenan en Tarantool en espacios.
El espacio es un conjunto, una colección de unidades de almacenamiento: taples. Tapl es como una fila en una mesa. Los índices se basan en estos datos. Arena y los asignadores especializados que trabajan dentro de Arena son los encargados de almacenar y organizar todo esto.
- Tapl = cadena
- Espacio = mesa
También dentro del hilo de TX hay un bucle de eventos, un bucle de eventos. Las fibras funcionan dentro del ciclo de eventos. Se trata de primitivas cooperativas desde las que podemos comunicarnos con los espacios. Podemos leer datos desde allí, podemos crear datos. Además, las fibras pueden interactuar con el bucle de eventos y entre sí directamente o utilizando primitivas especiales: canales.

Para trabajar con el usuario desde el exterior, hay un hilo separado: iproto. iproto acepta solicitudes de la red, procesa el protocolo Tarantool, pasa la solicitud a TX y ejecuta la solicitud del usuario en una fibra separada.
Cuando ocurre cualquier cambio de datos, un hilo separado llamado WAL (del registro de escritura anticipada) escribe archivos llamados xlog.
Cuando Tarantool acumula una gran cantidad de xlog, puede resultar difícil que se inicie rápidamente. Por lo tanto, para acelerar el lanzamiento, se guarda periódicamente la instantánea. Para guardar instantáneas, existe una fibra llamada demonio de instantáneas. Lee el contenido coherente de todo el Arena y lo escribe en el disco en un archivo de instantánea.
No es posible escribir directamente en el disco desde Tarantool debido a la multitarea cooperativa. No se puede bloquear y el disco es una operación de bloqueo. Por lo tanto, el trabajo con el disco se lleva a cabo a través de un grupo de subprocesos separado de la biblioteca fio.

Tarantool tiene replicación y es bastante simple de organizar. Si hay una réplica más, para entregarle datos, se genera otro hilo: la retransmisión. Su tarea es leer xlog y enviarlos a réplicas. Se lanza un aplicador de fibra en la réplica, que recibe los cambios del host remoto y los aplica al Arena.
Y estos cambios son exactamente los mismos que si se hicieran localmente, a través de WAL, se escriben en el xlog. Sabiendo cómo funciona todo, puede comprender y predecir el comportamiento de esta o aquella sección de Tarantool y comprender qué hacer con ella.
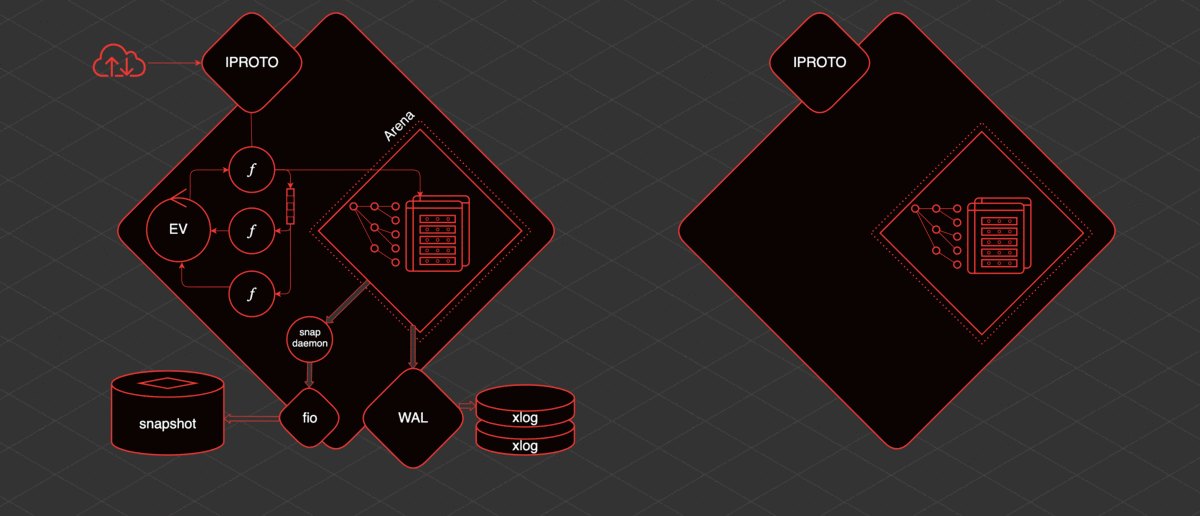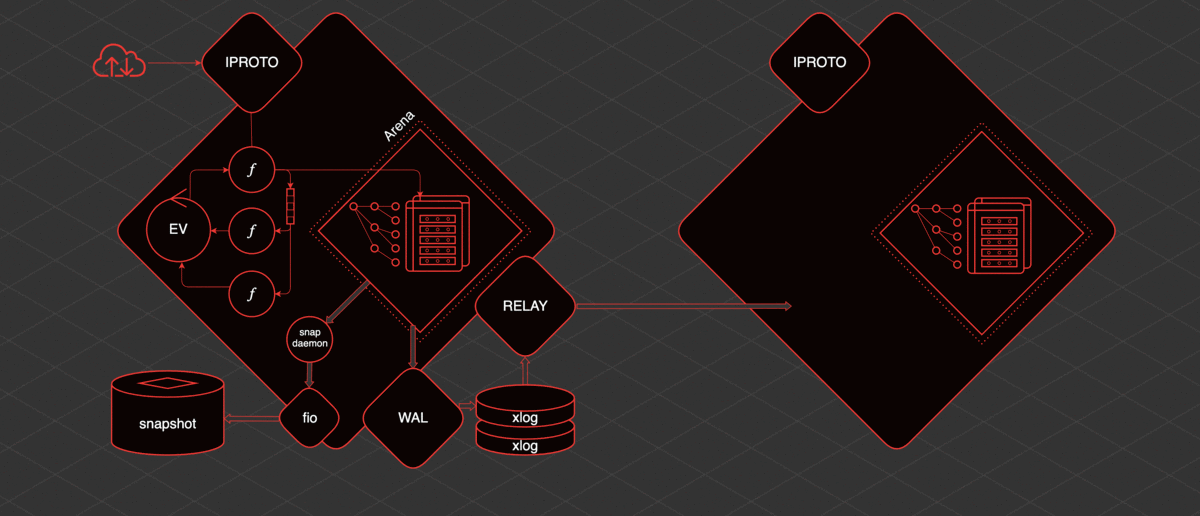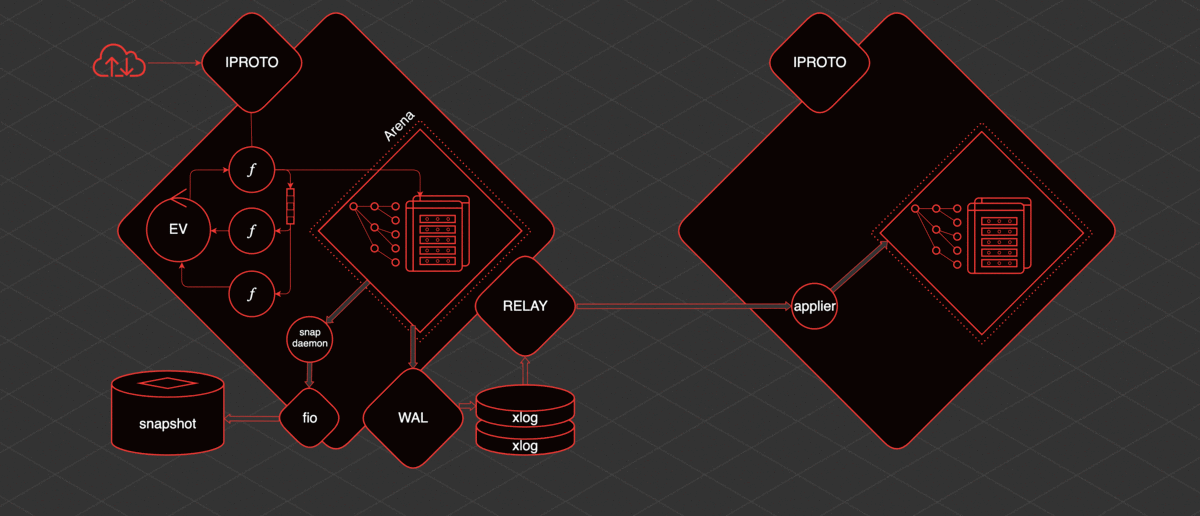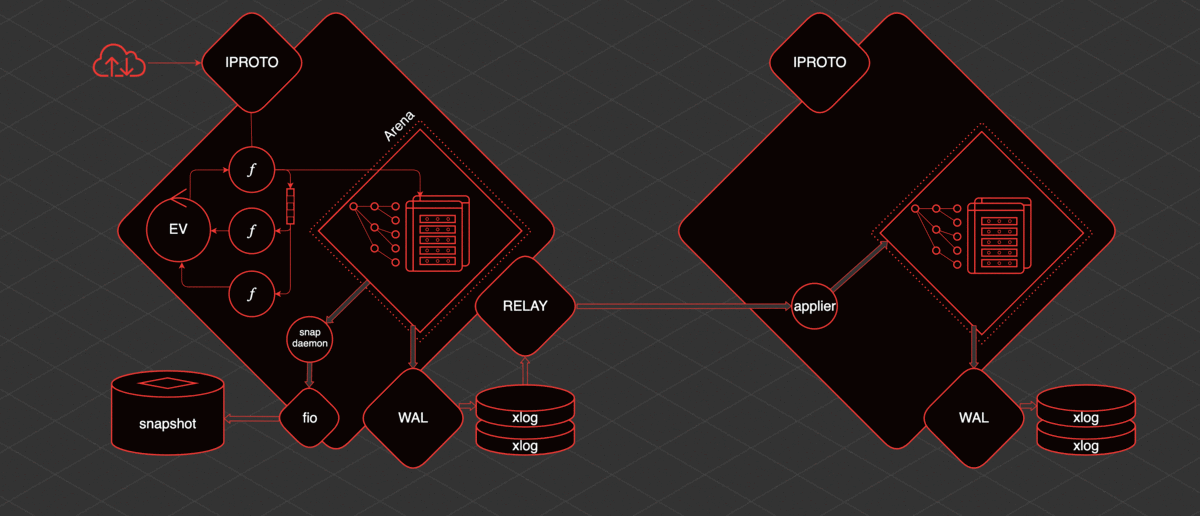
¿Qué pasa cuando reinicias? Imaginemos que Tarantool se ha estado ejecutando durante un tiempo, hay una instantánea, hay un xlog. Si lo reinicia:
- Tarantool encuentra la última instantánea y comienza a leerla.
- Lee y mira qué xlog hay después de esta instantánea. Los lee.
- Una vez completada la lectura de la instantánea y el xlog, tenemos una instantánea de los datos que estaban en el momento del reinicio.
- Entonces Tarantool completa los índices. En el momento de leer la instantánea, solo se crean índices primarios.
- Cuando todos los datos se han almacenado en la memoria, podemos crear índices secundarios.
- Tarantool lanza la aplicación.
Dispositivo kernel en seis líneas:
- Los datos están en la memoria
- Accediendo a datos desde un hilo
- Los cambios se escriben en el registro de escritura anticipada
- Los índices se basan en los datos
- La instantánea se guardará periódicamente
- WAL se replica.
Lua
Las aplicaciones de Tarantool se implementan en LuaJIT. Aquí puede detenerse y hablar sobre por qué LuaJIT.
Primero, Lua es un lenguaje de scripting accesible que fue creado originalmente no para programadores, sino para ingenieros. Es decir, para personas con formación técnica, pero no muy inmersas en los aspectos específicos de la programación.
Lua se ha mantenido lo más simple posible. Por lo tanto, resultó ser posible crear un compilador JIT que le permite llevar el rendimiento de un lenguaje de scripting casi al rendimiento de C. Puede encontrar ejemplos cuando un pequeño programa Lua compilado en LuaJIT prácticamente se pone al día con un C similar programa en ejecución [4].
Lua hace que sea bastante fácil escribir cosas eficientes. En general, había una idea en torno a Tarantool: trabajar codo con codo con los datos. Al lanzar el programa en el mismo espacio de nombres y el proceso en el que se ubican los datos, no podemos perder el tiempo paseando por la red.
Estamos accediendo a la memoria directamente, por lo que la lectura tiene una latencia casi nula y predecible. Todo esto podría haberse logrado simplemente con las funciones de Lua, pero dentro de Tarantool hay un bucle de eventos más fibras. Lua se integra con ellos.
Total:
- Lua: un lenguaje de programación simple para ingenieros
- Compilación JIT de alta eficiencia
- Trabajando junto con los datos
- No procedimientos, sino un tiempo de ejecución cooperativo
Fibra y multitarea cooperativa
La fibra es el hilo conductor de la ejecución. Es similar a un hilo, pero más liviano e implementa una primitiva multitarea cooperativa. Esto nos impone las siguientes propiedades.
- No se está ejecutando más de una tarea a la vez.
- El sistema carece de un planificador. Cualquier fibra debe entregarse voluntariamente.
La ausencia de un programador y la ejecución simultánea de tareas reduce el consumo de gastos generales parásitos y mejora el rendimiento. Todo esto junto hace posible construir un servidor de aplicaciones. Puede salir de Tarantool al mundo exterior.
Tarantool tiene bibliotecas para trabajar tanto con redes como con datos. Puede usarlo como un lenguaje de programación familiar, similar a Python, Perl, JavaScript, y resolver tareas que no están relacionadas en absoluto con la base de datos.
Dentro de Tarantool hay funciones, dentro del propio servidor de aplicaciones, para trabajar con la base de datos. A lo largo del desarrollo de Tarantool, la plataforma ha evolucionado sobre este servidor de aplicaciones. Nos referimos a lo siguiente en el término plataforma.
La plataforma es básicamentebase de datos en memoria y servidor de aplicaciones integrado. O viceversa, un servidor de aplicaciones más una base de datos. Pero Tarantool también viene con herramientas para replicar, para fragmentar; herramientas para agrupar y administrar este clúster y conectores a sistemas externos.
Total:
- La fibra es un hilo de ejecución ligero que implementa la multitarea cooperativa
- La siguiente tarea se realiza después de que la actual anuncia la transferencia de control.
- Servidor de aplicaciones
- Bucle de eventos con fibras
- Trabajo de enchufe sin bloqueo
- Colección de bibliotecas de datos y redes
- Funciones para trabajar con la base de datos
- Plataforma Tarantool
- Base de datos en memoria
- Servidor de aplicaciones integrado
- Herramientas de agrupación en clústeres
- Conectores a sistemas externos
Funcionalidad de la base de datos
Usamos cintas para almacenar datos. Son tuplas. Es una matriz con datos que no se escriben. Las tuplas o taples se combinan en espacios. El espacio es esencialmente una colección de cintas. El análogo del mundo de SQL es una tabla.
Tarantool tiene dos motores de almacenamiento. Puede definir diferentes espacios para el almacenamiento en memoria o en disco. Para trabajar con datos, se requiere un índice principal. Si creamos solo el índice principal, Tarantool se verá como un valor clave.
Pero podemos tener muchos índices. Los índices pueden ser compuestos. Pueden constar de varios campos. Podemos seleccionar por coincidencia parcial con el índice. Podemos trabajar con índices, es decir, una iteración secuencial sobre el iterador.
Los índices vienen en diferentes tipos. De forma predeterminada, Tarantool usa el árbol B + *. Y luego hay hash, mapa de bits, rtree, índices funcionales e índices en rutas JSON. Toda esta diversidad nos permite utilizar Tarantool con bastante éxito donde las bases de datos relacionales son adecuadas.
Tarantool también tiene un mecanismo de transacción ACID. Un dispositivo de acceso a datos de un solo subproceso nos brinda la capacidad de lograr el nivel de aislamiento serializable. Cuando nos referimos a la arena, podemos leer de ella o podemos escribir en ella, es decir, realizar modificaciones de datos. Todo lo que sucede se ejecuta secuencial y exclusivamente en un hilo.
Dos fibras no pueden correr en paralelo. Pero si hablamos de transacciones interactivas, entonces existe un motor MVCC separado. Le permite realizar transacciones serializables que ya son interactivas, pero además tendrá que manejar posibles conflictos de transacciones.
Además del motor de acceso Lua, Tarantool tiene SQL. A menudo hemos utilizado Tarantool como almacenamiento relacional. Concluimos que diseñaremos el almacenamiento de acuerdo con principios relacionales.
Donde se usaron tablas en SQL, tenemos espacios. Es decir, cada línea está representada por un toque. Definimos un esquema para nuestros espacios. Quedó claro que puede tomar cualquier motor SQL y simplemente mapear primitivas y ejecutar SQL sobre Tarantool.
En Tarantool, podemos llamar a SQL desde Lua. Podemos usar SQL directamente, o desde SQL podemos llamar a lo que está definido en Lua.
SQL es un mecanismo complementario, puedes usarlo, no necesitas usarlo, pero es una adición bastante buena que expande las posibilidades de usar Tarantool.
Total:
primitivas de almacenamiento de datos
- tapl (tupla, cadena)
- espacio (mesa) - colección de cintas
- motor:
- memtx: toda la cantidad de datos cabe en la memoria y una copia confiable en el disco
- vinilo: almacenado en el disco, la cantidad de datos puede exceder la cantidad de memoria
- índice primario
Índices
- tal vez mucho
- compuesto
- tipos de índice
- árbol (B⁺ *)
- picadillo
- mapa de bits
- rtree
- funcional
- camino json
Actas
- ÁCIDO
- Serializable (sin rendimiento)
- Interactivo (MVCC)
SQL y Lua
- TABLA: espacio
- FILA: tupla
- Esquema: formato de espacio
- Lua -> SQL: box.execute
Comparación con otros sistemas
Para comprender bien el lugar de Tarantool en el mundo de DBMS, lo compararemos con otros sistemas. Puedes comparar mucho con alguien, pero me interesan cuatro grupos principales:
- Plataformas en memoria
- DBMS relacional
- Soluciones de valor clave
- Sistemas orientados a documentos
Plataformas en memoria
GridGain, GigaSpaces, Redis Enterprise, Hazelcast, Tarantool.
¿En qué se parecen? Motor en memoria, base de datos en memoria y algo de tiempo de ejecución de la aplicación. Le permiten crear sistemas de clúster de forma flexible para diferentes cantidades de datos.
En particular, este es el uso en el rol de Data Grid. Estas plataformas están destinadas a resolver problemas comerciales. Cada cuadrícula, cada plataforma en memoria se basa en su propia arquitectura, mientras que pertenecen a la misma clase. Además, las diferentes plataformas tienen un conjunto de herramientas diferente, porque cada una de ellas está dirigida a un segmento diferente.
Tarantool es una plataforma sin segmentos de uso general. Esto brinda oportunidades más amplias y una variedad de escenarios comerciales que deben resolverse.
Bases de datos relacionales
Ahora comparemos el motor de base de datos en memoria de Tarantool con MySQL y PostgreSQL. Esto le permite posicionar el motor en sí, aislado del servidor de aplicaciones y más aún de la plataforma.
Tarantool es similar a las bases de datos relacionales porque almacena datos en forma tabular (en cintas y espacios). Los índices se construyen a partir de los datos, al igual que en las bases de datos relacionales. En Tarantool, puedes definir un esquema, incluso hay SQL, con el que puedes trabajar con datos.
Pero es el esquema SQL lo que distingue a Tarantool de las bases de datos relacionales clásicas. Porque aunque SQL está ahí, no tiene que usarlo. No es la principal herramienta para interactuar con la base de datos.
El esquema de Tarantool no es estricto. Solo puede definirlo para un subconjunto de sus datos.
En las bases de datos relacionales convencionales, una tabla en memoria no es un almacenamiento persistente utilizado para algún tipo de operaciones rápidas. En Tarantool, toda la cantidad de datos cabe en la memoria, se sirve desde la memoria y , al mismo tiempo, es confiable y persistente .
Esto es tan importante que volveré a escribir: Tarantool almacena todo el conjunto de datos en la memoria y, al mismo tiempo, los datos se guardan de forma segura en el disco .
Base de datos de valores-clave
La siguiente clase con la que comparar es el valor clave: memcached, Redis, Aerospike. ¿En qué se parece Tarantool a ellos? Puede funcionar en modo clave-valor, puede usar exactamente un índice. En este caso, Tarantool se comporta como un almacén de clave-valor clásico.
Por ejemplo, Tarantool se puede usar como un reemplazo directo de memcached. Existe un módulo que implementa el protocolo correspondiente, y en este caso imitamos completamente memcached.
Tarantool es similar en su arquitectura en memoria a Redis, solo que tiene un estilo diferente de descripción de datos. Dondequiera que Redis sea aplicable para escenarios arquitectónicos, puede tomar Tarantool. La batalla de estos yokozun se describe en el artículo en el enlace [5].
La diferencia entre Tarantool y las bases de datos de valor clave es precisamente la presencia de índices secundarios, transacciones, iteradores y otras cosas inherentes a las bases de datos relacionales.
Bases de datos orientadas a documentos
Como cuarta categoría, me gustaría citar las bases de datos basadas en documentos. El ejemplo más sorprendente aquí es MongoDB. Tarantool también puede almacenar documentos. Por tanto, podemos decir que Tarantool tiene su propio camino, incluida una base orientada a documentos.
El formato de almacenamiento interno de Tarantool en sí es msgpack. Este es un JSON binario. Es casi equivalente al formato utilizado por Mongo. Esto es BSON. Tiene la misma compacidad. Refleja los mismos tipos de datos. Al hacerlo, puede indexar el contenido de estos documentos. Lea más sobre msgpack en un artículo reciente [6].
También se incluye con Tarantool la biblioteca Avro Schema. Permite que los documentos de una estructura regular se analicen en líneas y estas líneas ya están almacenadas directamente en la base de datos.
Pero Tarantool no se concibió originalmente como una base de datos orientada a documentos. Esto es una ventaja para él y la capacidad de almacenar parte de los datos como un documento. Por lo tanto, tiene mecanismos de indexación ligeramente más débiles en comparación con el mismo Mongo.
Ronda de bonificación: bases de columna
A veces surgen tales preguntas. La respuesta aquí es simple: Tarantool no es una base de datos en columnas (quién lo hubiera pensado). Los scripts que son buenos para bases de columnas no funcionan con Tarantool. Se puede notar que se complementan extremadamente bien.
Creo que muchos de ustedes están familiarizados con Click House. Esta es una gran solución analítica. Esta es una base de columna. Además, a ClickHouse no le gustan las microtransacciones. Si le envía muchas transacciones pequeñas, no alcanzará su rendimiento máximo. Necesita enviarle datos en lotes.
Al mismo tiempo, las microtransacciones pueden y deben enviarse a Tarantool. Es capaz de acumularlos. Dado que tiene varios conectores, puede acumular estas transacciones y enviarlas a un almacenamiento tipo ClickHouse como un lote. Yin y yang.
Total:
| vs | ||
|---|---|---|
| In-memory |
|
|
|
|
|
| Key-value |
|
|
| - |
|
|
|
|
Comenzaremos con ejemplos de cuándo no se debe usar Tarantool. El escenario principal es el análisis, también conocido como OLAP, incluido el uso de SQL.
Las razones de esto son bastante simples. Tarantool es básicamente una aplicación de un solo hilo. No tiene bloqueos de acceso a datos. Pero si un hilo está ejecutando SQL largo, nadie más podrá ejecutarlo mientras se está ejecutando.
Por lo tanto, las bases de datos analíticas suelen utilizar el modo de acceso a datos de varios subprocesos. Entonces puedes hacer trampa en algo en hilos separados. En el caso de Tarantool, un hilo es más rápido que muchas otras soluciones. Pero es uno, y no hay forma de trabajar con datos de varios subprocesos.
Pero si desea crear algunos análisis precalculados, por ejemplo, sabe que necesitará datos acumulativos como este. Tiene un flujo de datos y puede saber de inmediato que necesita algún tipo de contadores. Esta analítica prefigurada se basa bien en Tarantool.
Cuándo usar
El escenario principal proviene de su patrimonio histórico, de para qué fue creado. Muchas transacciones pequeñas.
Pueden ser sesiones, perfiles de usuario y todo lo que haya surgido durante este tiempo. Por ejemplo, Tarantool se usa a menudo como un almacén de vectores junto a Machine Learning, porque es conveniente almacenarlo allí. Se puede utilizar como contadores altamente cargados que pasan todo el tráfico a través de ellos mismos, sistemas anti-fuerza bruta.
Subtotal:
Ejemplos de mal uso
- Analítica (OLAP)
- Incl. usando SQL
Ejemplos de buen uso
- Microtransacciones de alta frecuencia (OLTP)
- Perfiles de usuario
- Contadores y letreros
- Proxy de caché de datos
- Corredores de colas
Conclusión y conclusiones
Tarantool es persistente y tiene la capacidad de caminar a muchos otros sistemas. Por lo tanto, se utiliza como proxy de caché para sistemas heredados. Demasiado pesado, complejo, tanto en escritura proxy verdadero como en escritura detrás de proxy.
Además, la arquitectura de Tarantool, la presencia de fibras en él y la capacidad de escribir aplicaciones complejas lo convierte en una buena herramienta para escribir colas. Sé de 6 implementaciones de colas, algunas de ellas están en GitHub, algunas están en repositorios privados o en algún lugar de proyectos.
La razón principal de esto es la baja latencia garantizada para el acceso. Cuando estamos dentro de Tarantool y venimos por algunos datos, los damos de memoria. Tenemos acceso rápido y competitivo a los datos. Luego, puede crear mashups que se ejecuten junto a los datos.
Pruebe Tarantool en nuestro sitio web y venga con preguntas al chat de Telegram .
Enlaces
- Arquitectura S3: 3 años de evolución para Mail.ru Cloud Storage
- Video - Tarantool como base para aplicaciones de alta carga
- Tarantool: cómo ahorrar un millón de dólares en una base de datos en un proyecto de alta carga
- https://github.com/luafun/luafun
- Tarantool vs Redis: que pueden hacer las tecnologías en memoria
- Funciones avanzadas de MessagePack