
Después de tener la idea de agregar una segunda pantalla al Commodore 64, implementé rápidamente este proyecto. Todo el hardware encaja en un cartucho de tamaño estándar (incluido el conector DE-15). Salida de video compatible con VGA (31 kHz).
Dentro del cartucho hay 128KB SRAM para el framebuffer y un DAC simple de 1 bit.
TL; DR
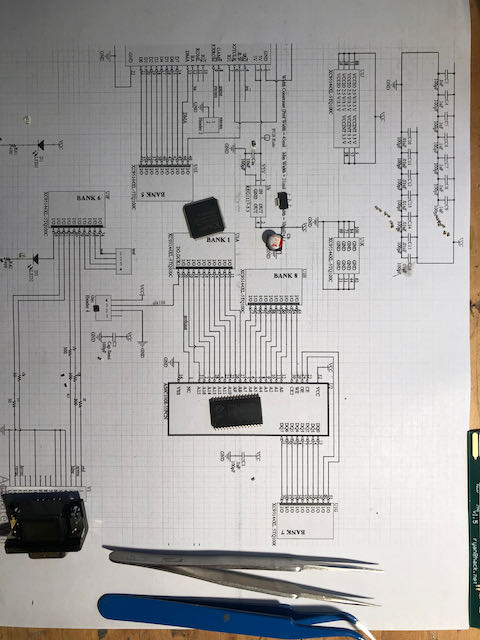
Así es como se ve la placa dentro del cartucho. Puede descargar la fuente aquí .

Interfaz de programación
El cartucho se puede colocar en cualquier lugar del espacio de direcciones de 64 KB, incluidas las E / S1 o E / S2. Hay código Verilog para presentar en una ventana en el framebuffer @EXPROM, que ocupará 8 KB de memoria básica, o un enfoque basado en registros que ahorra RAM.
En los ejemplos mostrados, I / O1 en $ DE00 se usa para los registros de control. Es posible que desee cambiar el ejemplo dado si hay un conflicto con algún otro complemento (segundo chip SID, etc.). En general, hay soporte para un token especial que le permite evitar conflictos, pero no tengo software adicional que cause estos conflictos.
Registros
IOBASE = token
IOBASE + 1 = dirección
lsb IOBASE + 2 = dirección msb
IOBASE + 3 = datos El framebuffer
es lineal y fácil de usar, como los modos de mapa de bits nativos de C64. En SRAM, comienza en $ 00,000.
Salida de video
Independientemente del modo seleccionado, el vídeo se emite con una frecuencia de píxeles de 25 MHz gracias al generador integrado de 100 MHz. Este parámetro está cerca del estándar de 25.175 MHz para una pantalla de 640x480 a 60 Hz FPS. En consecuencia, cualquier pantalla que conecté mostraba la imagen correctamente y sin problemas. Las áreas de supresión y sincronización vertical y horizontal se establecen en la polaridad y longitud correctas para activar este modo. Hay dos posibles interpretaciones de los datos de framebuffer: modo de alta resolución 640x480 1 bit por píxel y modo multicolor de baja resolución 320x480. Ambos modos son directos de paleta.
Hierro
El hardware es bastante básico: regulador de 3.3V, CPLD, oscilador y SRAM. SRAM pasa la mitad de su tiempo respondiendo al host y la mitad de su tiempo cargando datos de píxeles. El CPLD utilizado aquí, el Xilinx 95144XL, es estable a 5V, por lo que se encuentra en el bus de expansión C64, aunque está alimentado por un regulador de 3.3V junto con el resto del hardware.
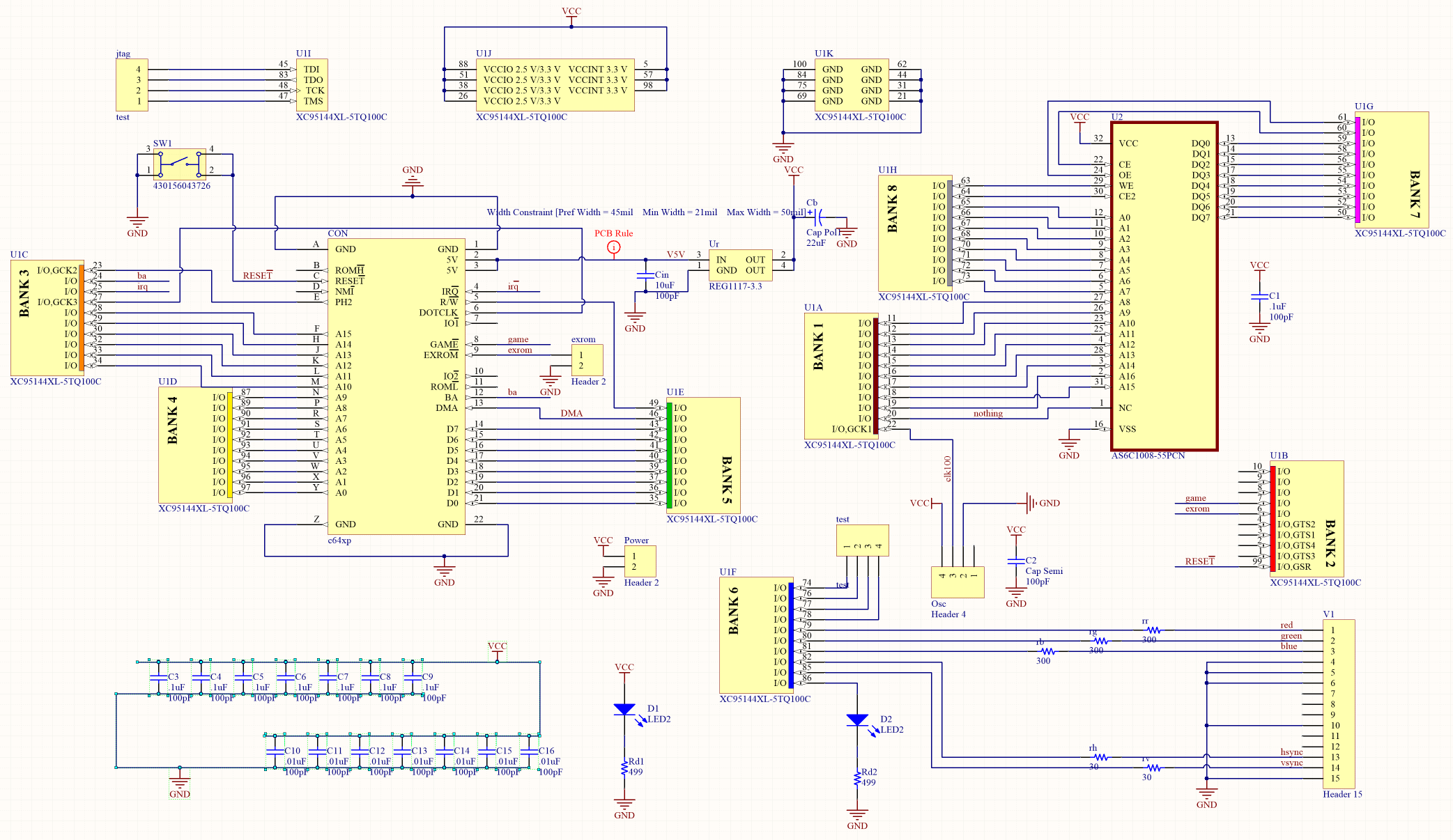
Se utilizan casi todos los recursos de CPLD. Esperaba colocar un objeto de hardware para el puntero, pero no había espacio para eso.
Para aquellos que imprimirán neveras portátiles, el modelo STL tiene todo lo que necesita y en el estilo C64.
El punto importante es que necesita un programador JTAG para cargar el flujo de bits en el CPLD.
Y una cosa más: el cartucho no funciona con la placa Ultimate 64. Además, instalar un cartucho en esta placa puede dañar el cartucho. Pero todo funciona con todas las versiones de placas C64, C128 y C64 Reloaded. No sé con certeza si el cartucho es compatible con todas las versiones de C64 o C128 lanzadas por Commodore, pero no veo ningún problema.
Especificaciones
- 4- . Gerber. , ( , female-).
- . STL.
- , 22 , 6,6
- , pn 430156043726, reset .
- .1"
- 0603: 2 499R, 3 300R, 2 30R
- 0603: 10 0,1 , 7 0,01
- 2 3,2x1,6 ( , )
- XC95144XL-5TQ100C CPLD ( )
- JEDEC 128kx8 SO Async SRAM a la AS6C1008-55PCN ( )
- VGA , DE15
Verilog
Usé Xilinx ISE 14.5 ya que no pude encontrar un conjunto de herramientas de código abierto para estos CPLD. Si alguien tiene tal información, por favor compártala.
Embalaje de píxeles
En el modo de alta definición, cada bit corresponde a un píxel. 1 = blanco, 0 = negro. Las direcciones se mueven desde (0,0) en la posición más visible de la parte superior izquierda a la parte inferior derecha (639 479), columna por columna, luego línea por línea. El bit 7 de cada byte es el primer píxel.
En el modo multicolor, los píxeles se emiten a la misma velocidad que en el modo monocromático, pero cada canal de color tiene una resolución diferente. El verde es de 1/2 píxel y el rojo y el azul son de 1/4 de píxel. El mapeo del patrón de bits al canal de color es byte a byte (fragmentario) y es:
G0 G1 G2 G3 R0 R1 B0 B1
Mientras que la representación en pantalla de cada byte del búfer de tramas se ve así:
R0 R0 R0 R0 R1 R1 R1 R1
G0 G0 G1 G1 G2 G2 G3 G3
B0 B0 B0 B0 B1 B1 B1 B1
Convertir imágenes para visualización con ImageMagick, modo monocromo:
convertir input.tiff -resize 640x480 -colors 2 -depth 1 output.mono
Modo de color:
convertir input.tiff + dither -posterize 2 -resize 640x480 output.tiff
convert output.tiff -separate channel% d.png
El código está escrito en Python; esta opción me pareció la más simple:
from PIL import Image
from array import *
import numpy as np
ir = Image.open("channel0.png")
ig = Image.open("channel1.png")
ib = Image.open("channel2.png")
ir = ir.resize((640,480))
ig = ig.resize((640,480))
ib = ib.resize((640,480))
r = ir.load()
g = ig.load()
b = ib.load()
arr=np.zeros((480,80,8))
out=np.zeros((480,640))
for y in range(0,480):
for x in range(0,80):
# 0 1 2 3 is green level
# 4 5 is red level
# 6 7 is blue level
# GREEN
arr[y][x][0]=(g[x*8+0,y]+g[x*8+1,y])/2
arr[y][x][1]=(g[x*8+2,y]+g[x*8+3,y])/2
arr[y][x][2]=(g[x*8+4,y]+g[x*8+5,y])/2
arr[y][x][3]=(g[x*8+6,y]+g[x*8+7,y])/2
# RED
arr[y][x][4]=(r[x*8+0,y]+r[x*8+1,y]+r[x*8+2,y]+r[x*8+3,y])/4
arr[y][x][5]=(r[x*8+4,y]+r[x*8+5,y]+r[x*8+6,y]+r[x*8+7,y])/4
#BLUE
arr[y][x][6]=(b[x*8+0,y]+b[x*8+1,y]+b[x*8+2,y]+b[x*8+3,y])/4
arr[y][x][7]=(b[x*8+4,y]+b[x*8+5,y]+b[x*8+6,y]+b[x*8+7,y])/4
for y in range(0,480):
for x in range(0,80):
for bit in range(0,8):
arr[y][x][bit] = int(round(round(arr[y][x][bit])/255))
newfile=open("output.bin","wb")
for y in range(0,480):
for x in range(0,80):
out[y][x] = int(arr[y][x][0] + arr[y][x][1]*2 + arr[y][x][2]*4 + arr[y][x][3]*8
+ arr[y][x][4]*16 + arr[y][x][5]*32 + arr[y][x][6]*64 + arr[y][x][7]*128)
newfile.write(out[y][x].astype(np.ubyte))
newfile.close()
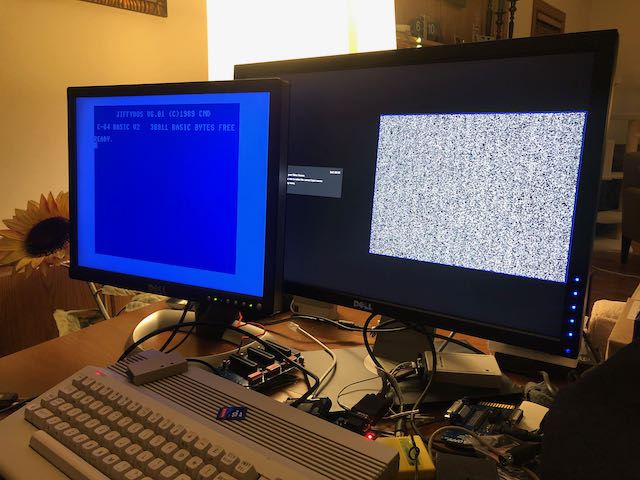
Video de demostración:
Recolectamos y soldamos:

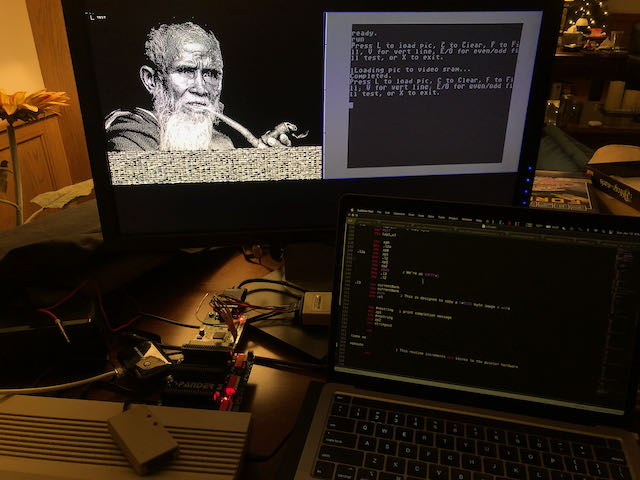
Desde este enlace puedes descargar todos los archivos necesarios para trabajar.
