
En la lingüística computacional moderna, la comprensión del significado de lo que se escribe o se dice se logra utilizando modelos de lenguaje natural (NLU). Con el crecimiento paulatino de la audiencia de asistentes virtuales de Salyut, surge la pregunta de optimizar nuestros servicios que trabajan con lenguaje natural. Para hacer esto, resulta aconsejable utilizar un modelo de NLU sólido para resolver varios problemas de procesamiento de texto a la vez. En este artículo, le mostraremos cómo puede usar el aprendizaje multitarea para mejorar las representaciones de vectores y entrenar un modelo NLU más general usando SBERT.
Los servicios de procesamiento de textos altamente cargados resuelven una serie de tareas diferentes de PNL:
- Reconociendo intenciones.
- Resaltando entidades nombradas.
- Análisis sentimental.
- Análisis de toxicidad.
- Busque consultas similares.
Cada una de estas tareas tiene sus propias particularidades y, en términos generales, requiere la construcción y entrenamiento de un modelo separado. Sin embargo, no es práctico mantener y ejecutar un modelo de NLU separado para cada una de estas tareas: el tiempo de procesamiento de la solicitud y la memoria consumida (video) aumentan considerablemente. En su lugar, usamos un modelo NLU sólido para extraer características genéricas del texto. Además de estas características, aplicamos modelos relativamente livianos (adaptadores), que resuelven problemas de PNL aplicados. Al mismo tiempo, NLU y adaptadores se pueden ejecutar en diferentes máquinas, lo que facilita la implementación y el escalado de soluciones.

Pero, ¿cómo hacer que las características identificadas por el modelo NLU base sean lo suficientemente universales para que se pueda construir un modelo NLP de alta calidad sobre ellas? Vamos a averiguarlo.
Por tradición, presentamos la implementación de nuestro enfoque en Python 3 y TensorFlow 1.15. Puede encontrar una guía completa paso a paso y ejemplos de código aquí: Colab .
También presentamos en un modelo ruso actualizado disponible públicamente SBERT-NLU clase BERT-grande [427 millones de opciones]. Versión Multitask : huggingface [tensorflow, pytorch] .
Aprendizaje multitarea. ¿Por qué es necesario esto?
Durante el funcionamiento de los modelos NLU, encontramos que las características asignadas por los modelos entrenados para una tarea (por ejemplo, NLI ) se pueden reutilizar con bastante éxito para otras tareas posteriores (por ejemplo, para clasificación o análisis sentimental). Para hacer esto, se entrena un modelo ligero (adaptador), afilado para resolver un nuevo problema, sobre los vectores seleccionados por el modelo base. Esto no cambia el modelo base.
Al mismo tiempo, la calidad de dichos modelos de adaptadores suele ser peor que si entrenamos nuestro modelo NLU para cada tarea. La razón es que los nuevos datos solo se utilizan para modelos de adaptador y no mejoran el modelo base. El aprendizaje multitarea nos ayuda a hacer frente a esto.
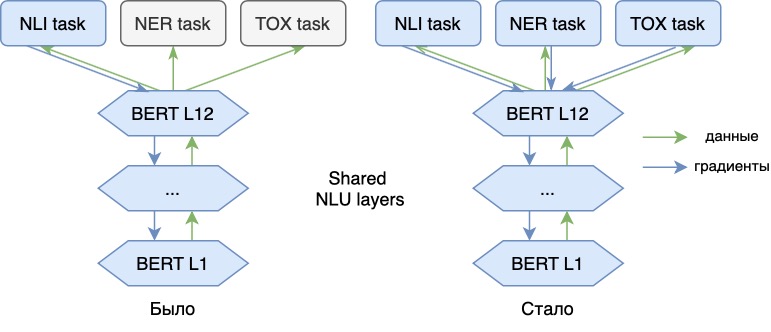
Ahora entrenamos el modelo de lenguaje no solo en el problema principal de NLI, sino también en otros adicionales (NER, análisis de toxicidad). Agregar nuevas tareas nos permite agregar nuevos "significados" a los vectores de nuestro modelo, los hace más universales. Así, el modelo podrá reflejar en sus vectores información, por ejemplo, sobre los matices emocionales del habla de una frase o sobre la parte del habla de cada palabra del texto. Con representaciones vectoriales de tal modelo, estos problemas se pueden resolver de manera más eficiente.
0. Experimento
Como ejemplo, considere la posibilidad de enseñar NLU en tres tareas:
- Representación de oraciones (NLI).
- Reconocimiento de entidad nombrada (NER).
- Análisis de los sentimientos.
Para enseñar la tarea principal de vectorización de oraciones, como la última vez , usamos un conjunto de datos para la inferencia del lenguaje natural , que contiene pares de oraciones con etiquetas que indican una consecuencia ("implicación"), una contradicción ("contradicción") o la ausencia. de una conexión semántica ("neutral") entre oraciones. Para estos datos, basados en el modelo BERT, aprenderemos una representación vectorial tal que la similitud entre los pares de oraciones correspondientes será mayor que la similitud entre conflictivas o neutrales entre sí.
Entrenaremos la cabeza NER usando el conjunto de datosdesde la plataforma kaggle. Este modelo asignará cada token de la propuesta que se está procesando a uno de varios tipos de entidad denominada IOB . Su tarea es una clasificación de clases múltiples.
Para el problema del análisis de sentimientos, tomemos los datos de la competencia Tweet Sentiment Extraction . La esencia de este concurso es predecir el color emocional de los comentarios en las publicaciones de Twitter. Hay tres clases en el conjunto de datos: color positivo, neutral y negativo de la réplica. Para este ejemplo, destacaremos solo dos clases: positiva y negativa. La tarea será una clasificación binaria.
Usamos la base BERT en inglés previamente entrenada como modelo básico de vectorización.
Plan de experimentación:
- Preparación de conjuntos de datos.
- Implementación del generador de lotes.
- Determinación de la función de pérdida.
- Construyendo el modelo.
- Elaboración del proceso de validación.
- Entrenamiento de modelos.
- Discusión de resultados y conclusiones.
1. Preparación de datos
Primero, carguemos los conjuntos de datos necesarios para entrenar el modelo básico de vectorización de oraciones - [ SNLI , MNLI ] y para su validación - [ STS SICK ]. Además, necesitamos un modelo BERT en inglés previamente entrenado. Afortunadamente, todo esto es de dominio público:
A continuación, vayamos a la plataforma kaggle y descarguemos datos desde allí para un análisis sentimental ; aquí necesitamos train.csv. Para estos datos, seleccionemos ejemplos negativos en una clase separada y combinemos el resto en un grupo común (positivo, neutral):
Queda por recoger los datos para NER y prepararlos en el formato [text, ner_labels]:
2. Generador de lotes
Ahora escribamos un procedimiento para generar un paquete de ejemplos para entrenar una red neuronal. Debido al hecho de que ahora no recibimos uno, sino ya tres
conjuntos de datos como entrada, también necesitamos más generadores: para una tarea NLI, usando el generador de tripletes, generaremos triples
[ancla, positivo, negativo]:
para problemas de clasificación, NER y Toxic usan el mismo generador de datos generando pares [muestra, etiqueta]. Aquí seleccionamos aleatoriamente varios ejemplos con sus etiquetas de clase de los conjuntos de datos proporcionados y formamos un paquete:
Finalmente, combinemos los tres generadores en un generador complejo común que concatenará los tres tipos de paquetes de datos en uno para entrenar el modelo:
3. Función de pérdida
Ahora, para cada tarea, definimos nuestra propia función de error y luego las combinamos para la función de pérdida final:
- También formularemos el problema de "convergencia" de oraciones parafraseadas como un problema de clasificación y usaremos la Softmax Loss ligeramente modificada, ya conocida por trabajos anteriores, como función de error :
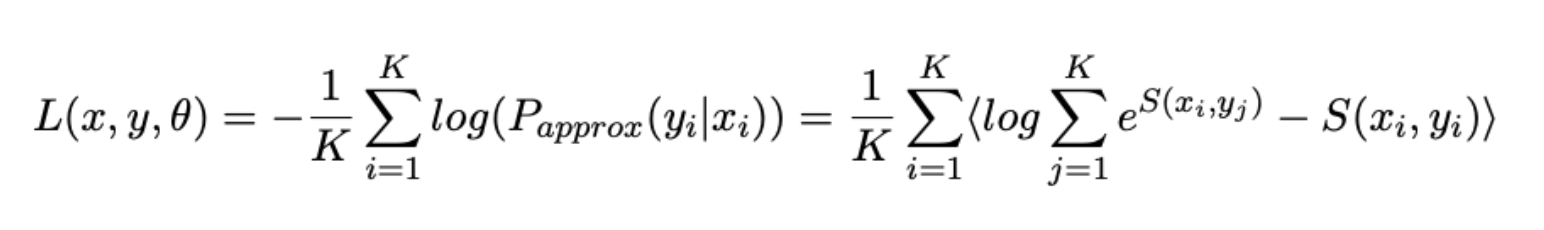
- Binary Cross Entropy Loss:

- NER- -, CrossEnrtopyLoss:

- Joint-loss, :
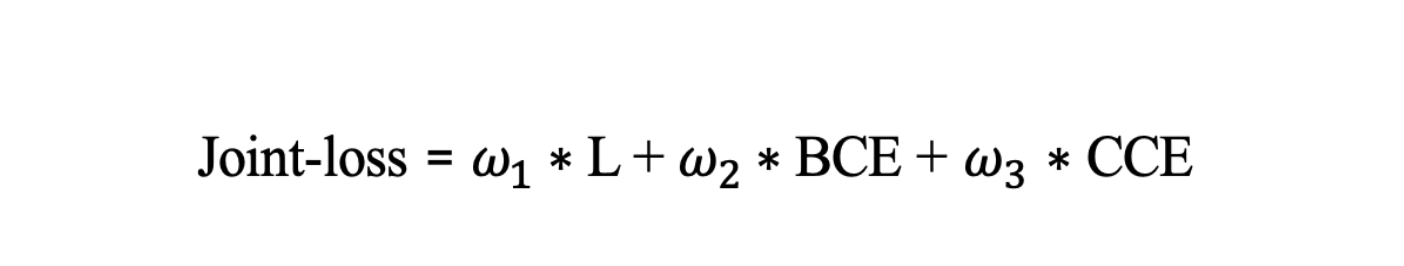
4.
Nuestro modelo consta de la parte principal NLU (aquí usamos la base BERT) y tres adaptadores "cabezas", específicos para cada tarea.
Para tareas NLI y Toxic, tomaremos incrustaciones de tokens promedio de la última capa BERT (usamos agrupaciones de medias enmascaradas). Para la tarea NER, usaremos incrustaciones de tokens de la salida de la octava capa del codificador. Cuando se enseñan representaciones a nivel de oración, las incorporaciones para problemas a nivel de token se obtienen mejor de las capas intermedias del modelo.
Tiene este aspecto:

Arquitectura de modelo multitarea
Código para ensamblar el modelo:
5. Validación de resultados
Para validar el modelo de vectorización de oraciones, utilizamos los conjuntos de datos STS 2012-2016 y SICK 2014 .
Como SNLI, este conjunto de datos contiene pares de oraciones. Vectoricémoslos con un modelo usando un modelo y estimemos la similitud entre las oraciones calculando la proximidad del coseno entre sus vectores. Como métrica, calcularemos la correlación de rango con las etiquetas del conjunto de datos.
Código de devolución de llamada que contiene esta lógica:
https://gist.githubusercontent.com/gaphex/f2d2e1a9c849ba9d69a3014da705968f/raw/8ac26c3b236979625a906591dd594b9fd8640483/pearsonr_callback.py .
La tarea de determinar la toxicidad de los comentarios se probará con la métrica AUC. La partición de datos se estratifica con respecto a la distribución de clases.
https://gist.github.com/Ab1992ao/873227b0834ebe43c95b4b5fe029eb95 .
La calidad del marcado NER se evaluará mediante dos métricas: precisión y medida F1.
https://gist.github.com/Ab1992ao/e3ea080d36d2bf2d0c1ddc17aa4b9e99 .
6. Proceso de aprendizaje
Estamos en la recta final. Ahora tenemos: datos, modelo y canalización de validación. Pasemos a los hiperparámetros y los recursos de aprendizaje.
Según los clásicos, tenemos Colab con acelerador de video NVIDIA K80 (12GB) / T80 (16GB) a nuestra disposición, dependiendo de su actividad en este entorno. Para que todo nuestro trabajo de arte multitarea quepa en la memoria, es importante elegir la longitud máxima correcta de la secuencia procesada (seq_len) y, por supuesto, el tamaño del lote.
En este experimento, nos limitaremos nuevamente a 24 tokens para la tarea de oración, que serán suficientes para codificar la mayoría de los datos utilizados en el entrenamiento. Para sentimiento y tarea nerviosa, use la misma longitud de secuencia.
Un aumento en el tamaño del lote tiene un efecto extremadamente positivo en la convergencia del modelo: elegiremos el máximo que quepa en la memoria de nuestra GPU.
Como optimizador, usaremos al bueno de Adam con una pequeña tasa de aprendizaje . Entrenaremos el modelo antes de la convergencia, 25 épocas deberían ser suficientes.
Parámetros de entrenamiento:
- tamaño de lote = 96/72 para la base BERT (16 GB de memoria o 12 GB, respectivamente);
- max_seq_len = 24;
- Optimizador Adam;
- Tasa de aprendizaje ~ 2e-6;
- Métricas - [SpearmanR, F1, AUC];
- Número de épocas ~ 25.
Comparemos las métricas de los adaptadores entrenados sobre la versión antigua y la nueva del modelo SBERT.

Como puede ver, debido a la capacitación adicional multitarea, logramos aumentar significativamente la calidad de las tareas adicionales NER y TOX. Es importante que esto no dañe la funcionalidad principal del modelo: las métricas en los conjuntos de datos de STS y SICK se mantuvieron al mismo nivel.
7. Oportunidades para seguir mejorando
Aumento
Como parte de nuestro trabajo, utilizamos manipulaciones adicionales que ayudan a obtener modelos más precisos y estables.
Durante la generación de lotes, aplicamos una serie de aumentos, entre los que se pueden distinguir los siguientes: a nivel de letra, a nivel de palabra, cambio de mayúsculas y minúsculas y eliminación de puntuación.
A nivel de letras, estos son:
1) eliminación de "prvet";
2) repita "saludos";
3) intercambio de dos símbolos adyacentes "Prievt";
4) reemplazo de una tecla de cierre en el teclado "da la bienvenida";
5) reemplazo por una letra cercana fonéticamente "hola".
A nivel de palabras, estos son:
1) intercambiar dos o más palabras;
2) inserción de las palabras de los parásitos - "bueno, esto es lo mismo, por así decirlo".
Para que el modelo sea más resistente a los cambios de mayúsculas y minúsculas, la puntuación puede eliminarse en algunos ejemplos. Para un token aleatorio, el registro se puede cambiar.
Los aumentos relacionados con el cambio de palabras y símbolos se aplican al 3% del lote, y con puntuación y mayúsculas, al 30%.
8. Resultados y conclusiones
En este artículo, nos familiarizamos con el concepto de aprendizaje multitarea y aplicamos este conocimiento para mejorar las representaciones vectoriales del modelo de lenguaje.
El uso de estos métodos, hemos mejorado el modelo UDE para el idioma ruso SBERT-multitarea y publicamos ella. Hemos entrenado aún más esta versión del modelo para resolver problemas de NER, análisis de sentimientos y análisis de toxicidad.
Medimos las métricas para ambas versiones del modelo SBERT en el punto de referencia de los modelos de idioma ruso RussianGLUE . Aunque las tareas de RuGLUE no participaron en el proceso de reentrenamiento multitarea, las métricas de la segunda versión del modelo aumentaron ligeramente. Enseñar el modelo a un problema amplió sus horizontes y mejoró la calidad en otros.

Planeamos desarrollar aún más los modelos de lenguaje natural SBERT. Entre las direcciones se pueden distinguir: aceleración y destilación , mejora de la arquitectura básica y la incorporación de nuevas tareas. Hablaremos de ellos en los siguientes artículos. Si está interesado en las tecnologías de PNL y desea implementarlas en nuevos productos para una amplia audiencia, acuda a nosotros para una entrevista .
¡Le deseamos lo mejor en su investigación!
Gracias por su ayuda en la preparación de los materiales para este artículo. Andriljo y Ibragim_bad...