
La naturaleza no tiene mal tiempo, todo tiempo es gracia. Las palabras de esta canción lírica pueden entenderse en sentido figurado, interpretando el clima como una relación entre personas. Se puede entender literalmente, lo cual también es cierto, porque no habría invierno nevado y frío, no valoramos tanto el verano, y viceversa. Pero los vehículos no tripulados carecen de sentimientos líricos y perspectiva poética, para ellos no todo el clima es gracia, especialmente el invierno. Uno de los principales problemas a los que se enfrentan los desarrolladores de "vehículos robóticos" es la disminución de la precisión de los sensores que le dicen al automóvil a dónde ir durante las malas condiciones climáticas. Los científicos de la Universidad Tecnológica de Michigan han creado una base de datos de las condiciones meteorológicas en las carreteras "a través de los ojos" de los vehículos no tripulados. Estos datos eran necesarios para comprender qué se debe cambiar o mejorar para que la visión de los vehículos robóticos durante una tormenta de nieve no sea peor.que en un claro día de verano. ¿Qué tan mal afecta el clima a los sensores de los vehículos no tripulados, qué método proponen los científicos para resolver el problema y qué tan efectivo es? Encontraremos respuestas a estas preguntas en el informe de los científicos. Ir.
Base de investigación
El funcionamiento de los coches autónomos se puede comparar con una ecuación en la que hay una gran cantidad de variables que deben tenerse en cuenta sin excepción para obtener el resultado correcto. Peatones, otros coches, la calidad de la superficie de la carretera (visibilidad de las líneas divisorias), la integridad de los sistemas del propio dron, etc. Muchas investigaciones de científicos, declaraciones provocativas de políticos, artículos punzantes de periodistas se basan en la conexión entre un vehículo no tripulado (en adelante, simplemente un automóvil o un automóvil) y un peatón. Esto es bastante lógico, porque una persona y su seguridad deben ser lo primero, especialmente dada la imprevisibilidad de su comportamiento. Las disputas morales y éticas sobre quién tendrá la culpa si un automóvil golpea a un peatón que saltó a la carretera continúan hasta el día de hoy.
Sin embargo, si eliminamos la variable "peatón" de nuestra ecuación figurativa, todavía habrá muchos factores potencialmente peligrosos. El clima es uno de ellos. Evidentemente, con mal tiempo (lluvia o nevada), la visibilidad puede disminuir tanto que a veces basta con detenerse, porque no es realista conducir. La visión de los coches, por supuesto, es difícil de comparar con la visión de una persona, pero sus sensores sufren de visibilidad reducida no menos que nosotros. Por otro lado, los automóviles tienen un arsenal más amplio de estos sensores: cámaras, radares de ondas milimétricas (MMW), sistema de posicionamiento global (GPS), estabilizador giroscópico (IMU), detección de luz y rango (LIDAR) e incluso sistemas ultrasónicos. A pesar de esta variedad de sentidos, los coches autónomos siguen estando ciegos durante el mal tiempo.
Para entender de qué se trata, los científicos proponen considerar aspectos cuya combinación de una forma u otra incide en una posible solución a este problema: segmentación semántica, detección de un camino transitable (adecuado) y combinación de sensores.
Con la segmentación semántica, en lugar de detectar un objeto en una imagen, cada píxel se clasifica individualmente y se asigna a la clase que mejor representa el píxel. En otras palabras, la segmentación semántica es una clasificación a nivel de píxel. La segmentación semántica clásica - red neuronal convolucional (CNN de la red neuronal convolucional A ) - consiste en redes de codificación y decodificación.
La red de codificación reduce la resolución de los datos de entrada y extrae funciones, y la red de decodificación utiliza estas funciones para recuperar y aumentar la muestra de los datos de entrada y finalmente asigna una clase a cada píxel.
Los dos componentes clave en la decodificación de redes son la capa denominada MaxUnpooling y la capa de convolución Transpose. La capa MaxUnpooling (un análogo de la capa MaxPooling - una operación de agrupación con una función máxima) es necesaria para reducir la dimensión de los datos procesados.
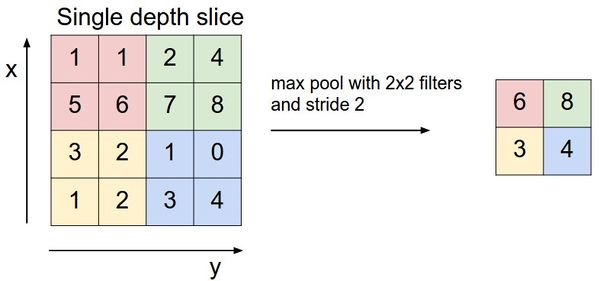
Un ejemplo de la operación MaxPooling.
Existen varios métodos para distribuir valores (es decir, extraer) que tienen el objetivo común de almacenar las ubicaciones de los valores máximos en la capa MaxPooling y usar esas ubicaciones para volver a colocar los valores máximos en ubicaciones coincidentes en el capa MaxUnpooling correspondiente. Este enfoque requiere que la red de códecs sea simétrica, en la que cada nivel de MaxPooling en el codificador tiene un nivel de MaxUnpooling correspondiente en el lado del descodificador.
Otro enfoque es colocar los valores en una ubicación predeterminada (por ejemplo, en la esquina superior izquierda) en el área a la que apunta el núcleo. Fue este método el que se utilizó en el modelado, que se discutirá un poco más adelante.
Una capa convolucional transpuesta es lo opuesto a una capa convolucional regular. Consiste en un núcleo en movimiento que escanea la entrada y convoluciona los valores para llenar la imagen de salida. El volumen de salida de ambas capas, MaxUnpooling y Transpose, se puede controlar ajustando el tamaño del kernel, el relleno y el tono.
El segundo aspecto, que juega un papel importante en la solución del problema del mal tiempo, es la detección de un camino transitable.
Un camino transitable es un espacio en el que un automóvil puede moverse con seguridad en un sentido físico, es decir, detección de calzada. Este aspecto es sumamente importante para diversas situaciones: estacionamiento, mala señalización vial, mala visibilidad, etc.
Según los científicos, la detección de un camino transitable se puede implementar como un paso preliminar para detectar un carril o cualquier objeto. Este proceso se deriva de la segmentación semántica, cuyo propósito es generar una clasificación píxel por píxel después del entrenamiento en un conjunto de datos mapeado por píxeles.
El tercer aspecto, pero no menos importante, es la fusión de sensores. Esto significa literalmente combinar datos de múltiples sensores para obtener una imagen más completa y reducir los probables errores e inexactitudes en los datos de los sensores individuales. Existe una agrupación de sensores homogénea y heterogénea. Un ejemplo de lo primero sería el uso de múltiples satélites para refinar una posición GPS. Un ejemplo del segundo es la combinación de datos de cámara, LiDAR y Radar para vehículos autónomos.
Cada uno de los sensores anteriores muestra individualmente resultados excelentes, pero solo en condiciones climáticas normales. En condiciones de trabajo más duras, sus deficiencias se hacen evidentes.
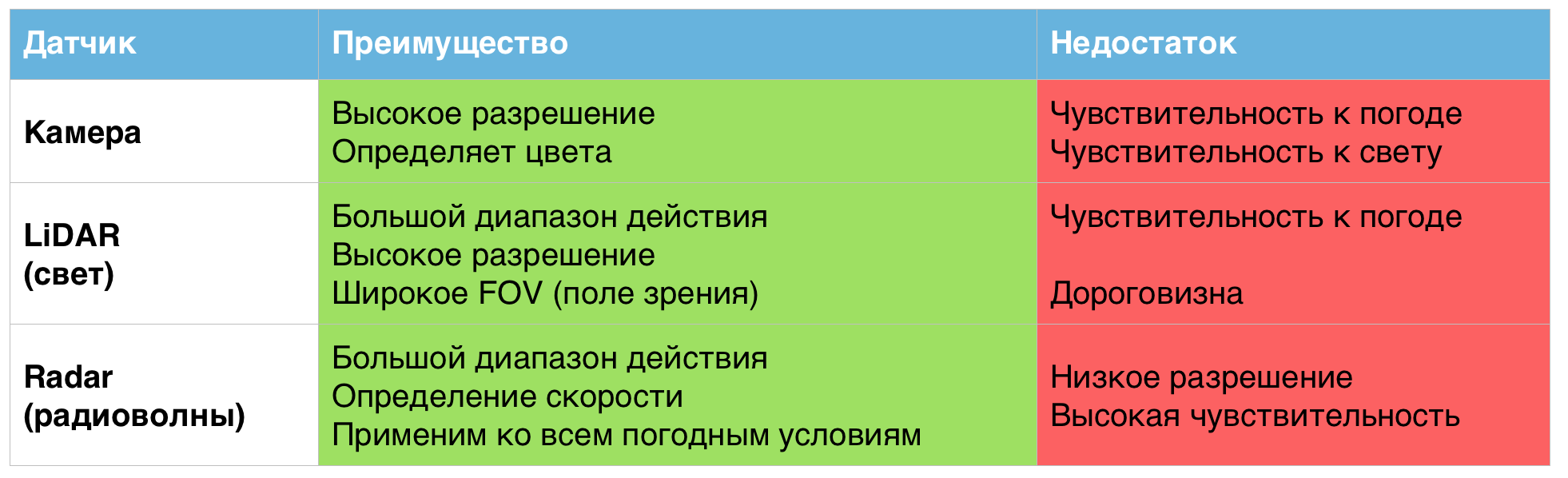
Una tabla de las ventajas y desventajas de los sensores utilizados en vehículos no tripulados.
Es por eso que, según los científicos, la combinación de estos sensores en un solo sistema puede ayudar a resolver los problemas asociados con las malas condiciones climáticas.
Recopilación de datos
En este estudio, como se mencionó anteriormente, se utilizaron redes neuronales convolucionales y fusión de sensores para resolver el problema de encontrar un camino para conducir en condiciones climáticas adversas. El modelo propuesto es una red neuronal convolucional profunda de subprocesos múltiples (un subproceso por sensor) que reducirá la resolución de los mapas de funciones (el resultado de aplicar un filtro a la capa anterior) de cada flujo, combinará los datos y luego volverá a muestrear el mapas para realizar la clasificación píxel por píxel.
Para llevar a cabo más trabajo, incluidos cálculos, modelado y pruebas, se necesitaban muchos datos. Cuanto más, mejor, dicen los propios científicos, y esto es bastante lógico cuando se trata del funcionamiento de varios sensores (cámaras, LiDAR y Radar). Entre los muchos conjuntos de datos ya existentes, se eligió DENSE, que cubre la mayoría de los matices necesarios para la investigación.
DENSOes también un proyecto destinado a resolver los problemas de encontrar un camino en condiciones climáticas severas. Los científicos que trabajan en DENSE viajaron alrededor de 10,000 km por el norte de Europa, registrando datos de múltiples cámaras, múltiples LiDAR, radares, GPS, IMU, sensores de fricción en carreteras y cámaras termográficas. El conjunto de datos consta de 12.000 muestras, que se pueden dividir en subgrupos más pequeños que describen condiciones específicas: día + nieve, noche + niebla, día + despejado, etc.
Sin embargo, para que el modelo funcione correctamente, fue necesario corregir los datos de DENSE. Las imágenes originales de la cámara en el conjunto de datos son de 1920 x 1024 píxeles y se han reducido a 480 x 256 para un entrenamiento y pruebas de modelos más rápidos.
Los datos LiDAR se almacenan en un formato de matriz NumPy que debe convertirse en imágenes, escalar (hasta 480 x 256) y normalizar.
Los datos del radar se almacenan en archivos JSON, un archivo para cada fotograma. Cada archivo contiene un diccionario de objetos detectados y varios valores para cada objeto, incluidas las coordenadas x, coordenadas y, distancia, velocidad, etc. Este sistema de coordenadas es paralelo al plano del vehículo. Para convertirlo en un plano vertical, solo se debe considerar la coordenada y.
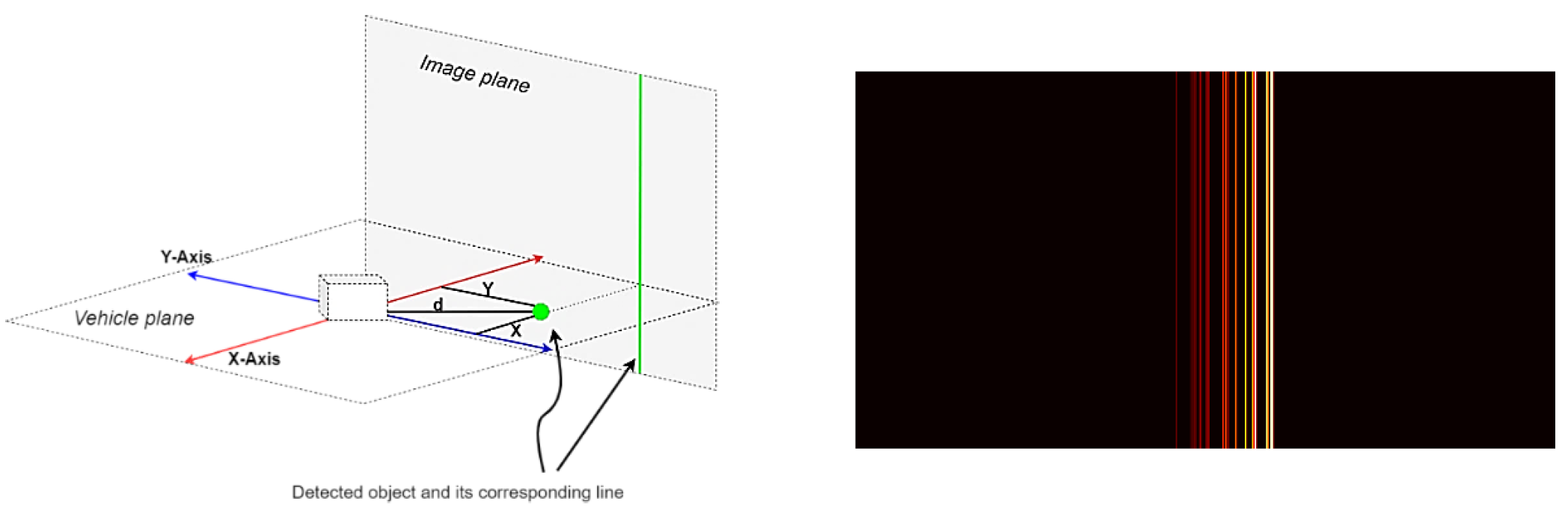
Imagen n. ° 1: proyección de la coordenada y sobre el plano de la imagen (izquierda) y el marco de radar procesado (derecha).
Las imágenes resultantes se escalaron (hasta 480 x 256) y se normalizaron.
Desarrollando un modelo de CNN
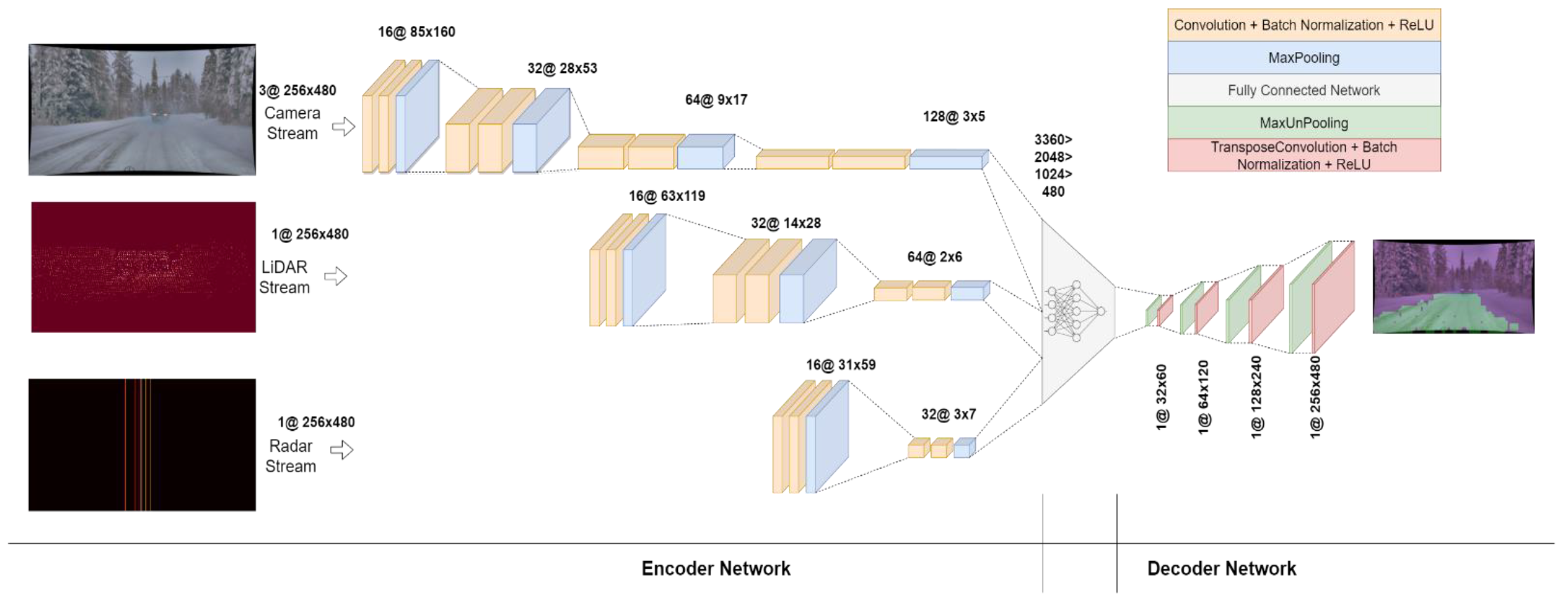
Imagen # 2: La arquitectura del modelo CNN.
La red fue diseñada para ser lo más compacta posible, ya que las redes de códecs profundos requieren una gran cantidad de recursos computacionales. Por esta razón, la red de decodificación no se diseñó con tantas capas como la red de codificación. La red de codificación consta de tres flujos: cámara, LiDAR y radar.
Dado que las imágenes de la cámara contienen más información, la transmisión de la cámara se hace más profunda que las otras dos. Consta de cuatro bloques, cada uno de los cuales consta de dos capas convolucionales: una capa de normalización por lotes y una capa ReLU, seguida de una capa MaxPooling.
Los datos LiDAR no son tan masivos como los datos de las cámaras, por lo que su flujo consta de tres bloques. Asimismo, el flujo de radar es más pequeño que el flujo de LiDAR, por lo tanto, consta de solo dos bloques.
La salida de todos los flujos se modifica y se combina en un vector unidimensional que está conectado a una red de tres capas ocultas con activación ReLU. Luego, los datos se convierten en una matriz bidimensional, que se pasa a una red de decodificación que consta de cuatro pasos consecutivos de MaxUnpooling y convolución transpuesta para muestrear los datos a un tamaño de entrada (480x256).
Resultados de las pruebas / entrenamiento del modelo de CNN
La capacitación y las pruebas se realizaron en Google Colab usando GPU. El subconjunto de datos etiquetados a mano consistió en 1000 muestras de datos de cámara, LiDAR y radar: 800 para entrenamiento y 200 para pruebas.
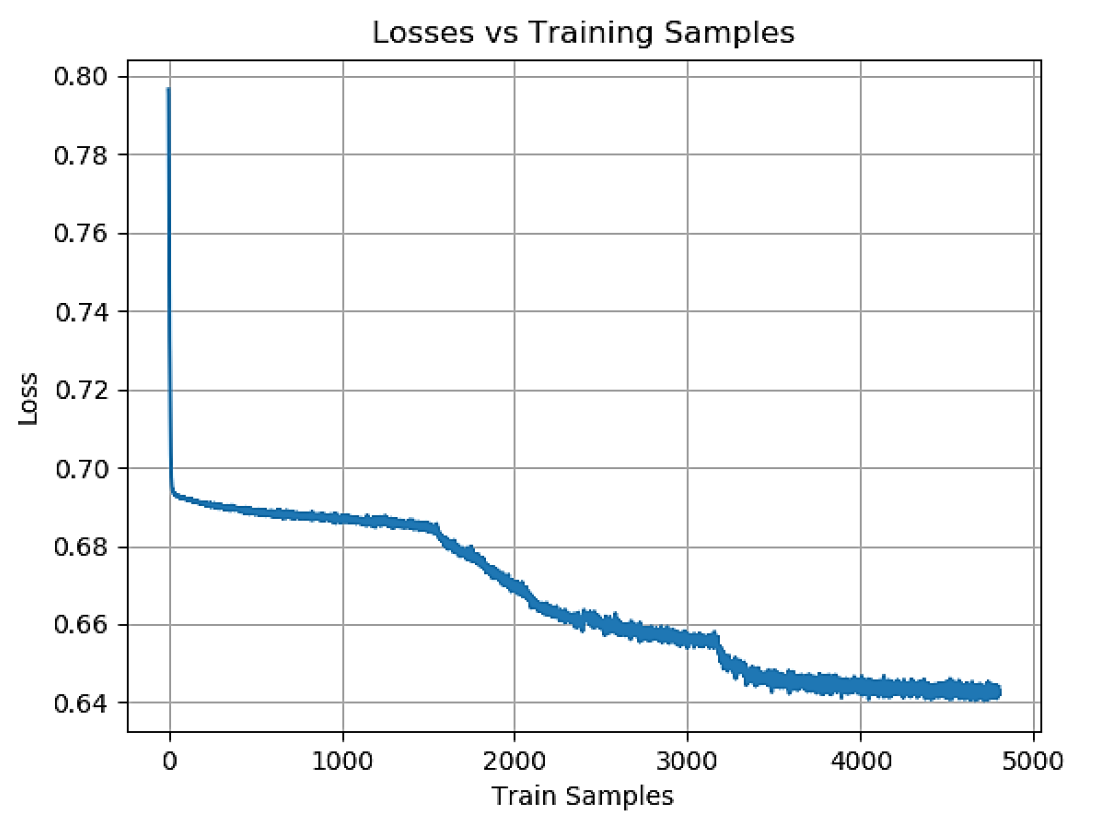
Imagen # 3: Pérdida de muestras de entrenamiento durante la fase de entrenamiento.
La salida del modelo se procesó posteriormente con expansión y erosión de la imagen con diferentes tamaños de kernel para reducir la cantidad de ruido en la salida de clasificación de píxeles.
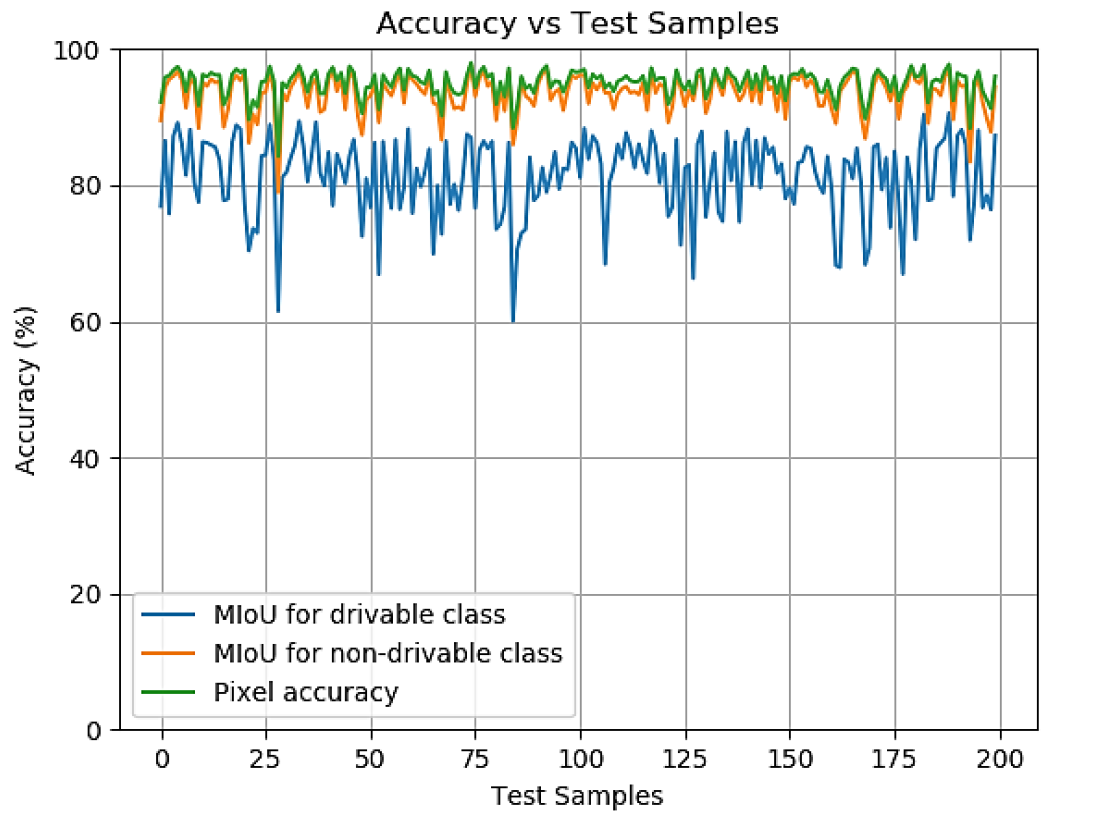
Imagen # 4: Precisión en las muestras de prueba durante la fase de prueba.
Los científicos señalan que el indicador más simple de la precisión del sistema es el píxel, es decir, la proporción de píxeles definidos correctamente y píxeles definidos incorrectamente al tamaño de la imagen. Se calculó la precisión de píxeles para cada muestra en el conjunto de prueba, y el promedio de estos valores representa la precisión general del modelo.
Sin embargo, esta cifra no es ideal. En algunos casos, una determinada clase está subrepresentada en la muestra, a partir de la cual la precisión de los píxeles será significativamente mayor (de lo que realmente es) debido al hecho de que no hay suficientes píxeles para probar el modelo para una determinada clase. Por lo tanto, se decidió utilizar adicionalmente MIoU, la relación promedio entre el área de intersección y el área de unión.
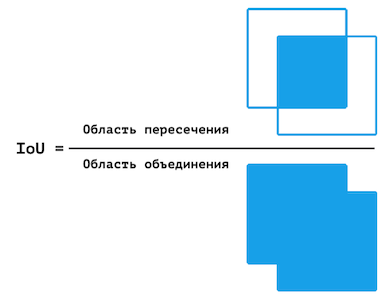
Representación visual de IoU.
De manera similar a la precisión de píxeles, la precisión de IoU se calcula para cada fotograma y la precisión final es el promedio de estos valores. Sin embargo, MIoU se calcula para cada clase por separado.

Tabla de valores de precisión.

Imagen # 5
La imagen de arriba muestra cuatro cuadros seleccionados de movimiento de nieve de la cámara, LiDAR, radar, datos del suelo y salida del modelo. Es evidente a partir de estas imágenes que el modelo puede delinear la circunferencia general del área en la que el vehículo puede moverse con seguridad. El modelo ignora las líneas y los bordes que de otro modo podrían interpretarse como los bordes de la calzada. El modelo también funciona bien en condiciones de poca visibilidad (por ejemplo, niebla).
El modelo también evita a los peatones, otros automóviles y animales, aunque este no fue el objetivo principal de este estudio en particular. Sin embargo, este aspecto en particular debe mejorarse. Sin embargo, dado que el sistema consta de menos capas, aprende mucho más rápido que sus predecesores.
Para un conocimiento más detallado de los matices del estudio, le recomiendo que consulte el informe de los científicos y datos adicionales .
Epílogo
La actitud hacia los vehículos autónomos es ambigua. Por un lado, el robo-coche niega riesgos como el factor humano: conductor ebrio, imprudencia, actitud irresponsable ante las normas de tráfico, poca experiencia de conducción, etc. En otras palabras, el robot no se comporta como un humano. Eso es bueno, ¿no? Si y no. Los vehículos autónomos superan a los conductores de carne y hueso de muchas maneras, pero no en todas. El mal tiempo es un buen ejemplo de esto. Por supuesto, no es fácil para una persona conducir durante una tormenta de nieve, pero para los vehículos no tripulados era casi irreal.
En este trabajo, los científicos llamaron la atención sobre este problema, proponiendo hacer las máquinas un poco más humanas. El caso es que una persona también tiene sensores que funcionan en equipo para asegurarse de que recibe la máxima información sobre el entorno. Si los sensores de un vehículo no tripulado también funcionan como un solo sistema, y no como elementos separados del mismo, será posible obtener más datos, es decir para mejorar la precisión de encontrar el camino transitable.
Por supuesto, el mal tiempo es un término colectivo. Para algunos, una nevada ligera es un mal tiempo, pero para otros es una tormenta de granizo. La investigación y las pruebas adicionales del sistema desarrollado deberían enseñarle a reconocer la carretera en todas las condiciones climáticas.
Gracias por su atención, mantengan la curiosidad y tengan una buena semana de trabajo, chicos. :)
Un poco de publicidad
Gracias por estar con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver contenido más interesante? Apóyenos haciendo un pedido o recomendando a amigos, VPS en la nube para desarrolladores desde $ 4.99 , un análogo único de los servidores de nivel de entrada que hemos inventado para usted: Toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o ¿cómo dividir el servidor correctamente? (opciones disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
¿Dell R730xd es 2 veces más barato en el centro de datos Maincubes Tier IV en Ámsterdam? ¡Solo tenemos 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡Desde $ 99! Lea sobre cómo construir la infraestructura de Bldg. clase con el uso de servidores Dell R730xd E5-2650 v4 a un costo de 9000 euros por un centavo?