
No hace falta decir que no podía esperar hasta el fin de semana para hacer mis comprobaciones. Echemos un vistazo a los resultados de la prueba. Y para hacerlo más interesante, en el camino consideraremos la tecnología de mostrar variables "sobre la marcha", sin detener el núcleo del procesador. Bueno, y la tecnología de depuración visual de archivos elf recopilados por compiladores por lotes.
Qué tipo de pruebas realizaremos
La esencia de las pruebas se discutió en los comentarios del artículo anterior. El programa de PC original envía datos. Lo que no importa. Datos, y eso es todo. El responsable del tratamiento acepta estos datos y los ignora de forma segura. Porque el problema era la velocidad de transmisión. En teoría, las nuevas bibliotecas pueden omitir algunos datos o mezclar un par de búferes. Por lo tanto, el flujo debe variar en el tiempo. En tales casos, se envía una secuencia pseudoaleatoria o datos incrementales.
No queriendo dedicar mucho tiempo a generar una secuencia pseudoaleatoria para el origen y el destino (el algoritmo debe ser el mismo), me limité a una palabra incremental de 32 bits. La principal desventaja de este enfoque es que hasta tres de cada cuatro bytes pueden coincidir en paquetes vecinos. Pero uno, y el primero, será diferente. Entonces, para la prueba de hoy, me parece aceptable.
El hecho es que el protocolo USB es paquete. Y el paquete en sí se captura a nivel de hardware. No debería haber una situación dentro del bloque en la que un byte esté dañado y luego se envíen nuevamente datos útiles. Al menos debido a los problemas que queremos atrapar en las bibliotecas ahora, esto no surgirá. Si los datos se corrompen, entonces globalmente. Si los datos antiguos se sobrescriben con otros nuevos, primero se sobrescribirá el primer byte y será diferente en los diferentes paquetes.
En principio, todos podrán reescribir mi código en una versión diferente de los datos de prueba ... Hoy, simplemente enviaré una palabra de 32 bits en aumento y, al recibirla, verificaré que el incremento se realice sin romper la secuencia.
¿Cómo rastrearemos el resultado?
¿Cómo vamos a saber que todo funciona? Un LED no será suficiente. Bueno, para agregar un UART, debe codificar el código de otra persona. Puedes cometer tus errores. Usemos una funcionalidad que conozco desde hace mucho tiempo, pero que siempre la he usado solo en el entorno de desarrollo de Keil. Hoy te mostraré cómo usarlo en Eclipse. Desde los comentarios hasta el último artículo, me di cuenta de que no todo el mundo conoce esta tecnología.
El puerto de depuración JTAG permite trabajar solo cuando el núcleo del procesador está parado. Esto no es aceptable para USB. Allí y durante el funcionamiento normal, las paradas están plagadas de tiempos de espera y, en nuestro caso, incluso si no alcanzamos el tiempo de espera, la velocidad puede estar subestimada. Afortunadamente, el puerto de depuración SWD le permite monitorear la memoria sobre la marcha. En 2016, verifiqué usando un osciloscopio, que le permite configurar la sincronización por duración de pulso, el acceso a la memoria por SWD prácticamente no ralentiza el núcleo del procesador. Pero, ¿cómo lo usamos?
Lo primero en lo que confiaremos hoy es en la capacidad de CubeIDE (que es un Eclipse dopado) para mostrar variables sobre la marcha. Crearemos un grupo de variables, donde el programa mostrará mucha información útil, y comenzaremos a rastrearlas en la pantalla. Mucha gente lo sabe, pero hasta ahora no todo el mundo. Házselo saber a todos ahora.
Y el segundo es lo que los chicos y yo encontramos recientemente. Nadie en nuestra oficina sabía esto. Resulta que si crea un proyecto con un compilador por lotes, incrustando información de depuración de Dwarf-2 en él, este archivo elf se puede abrir en Eclipse para depurarlo y puede obtener un enlace completo con sus fuentes. Al mismo tiempo, las fuentes en sí mismas no necesitan estar conectadas al proyecto.El depurador extraerá automáticamente rutas hacia ellos desde la información de depuración. Ahora siempre hago eso. Se construye un proyecto GCC o CLang, y simplemente conecto elf a Eclipse y lo trazo, sin perder tiempo adjuntando el proyecto a este Eclipse. A veces incluso me envían archivos elfos recopilados por cadenas de herramientas que no están en mi máquina. Incluso compilado en Linux (y yo trabajo con Windows). El método funciona incluso en estos casos, siempre que el proyecto se envíe en el conjunto completo: elf y sus fuentes. Hoy nos ayudará a no finalizar los proyectos del autor en cuanto a su estructura. Construiré todo sobre la base del archivo MAKE "nativo" y luego me conectaré con el depurador al archivo elf.
Entrenamos para conectar
Lo primero que debemos hacer en CubeIDE es un proyecto para STM32F103. "¡Espera un minuto!", Exclama el lector atento ... "¡¡¡El autor acaba de prometer que no tendrá que hacer nada con el proyecto original !!!" Eso está bien. Esta es la peculiaridad de CubeIDE. Necesitamos un proyecto para STM32F103. Alguna. Lo principal es que está bajo STM32F103. Lo creamos, lo recolectamos y lo olvidamos. Lo que hay en él no es importante. El hecho mismo de su existencia en el entorno del desarrollo es importante.
Ahora en CubeIDE vamos a la configuración del depurador. Por ejemplo, así:
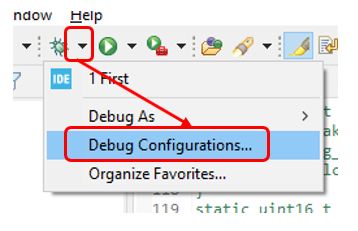
No tendríamos que pervertir con la creación del proyecto de la izquierda si seleccionáramos el elemento Depuración de hardware de GDB. Siempre lo elijo en Eclipses regulares. Intenté seleccionarlo aquí:
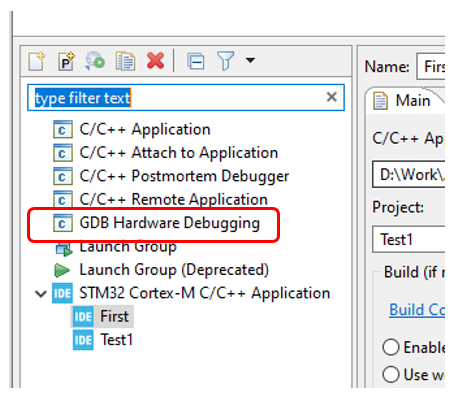
Pobre de mí. El proyecto de la izquierda no será necesario, pero se dice que la funcionalidad de mostrar variables en tiempo real no está disponible. Por tanto, ay y ah. Elija la aplicación STM32 Cortex-M C / C ++. Ya tengo dos configuraciones allí. Ahora, para asegurarme de que no te he engañado, crearé un tercero. Para hacer esto, hago doble clic aquí:
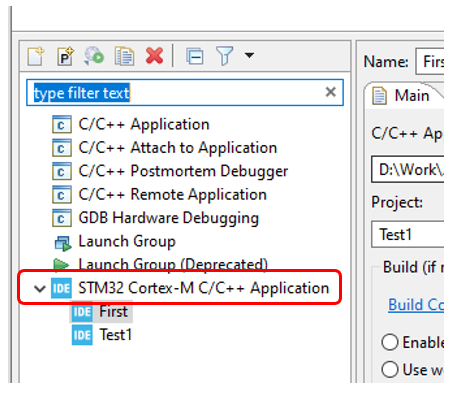
nombraré la configuración Artículo: Debe
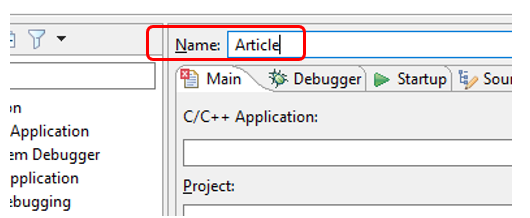
seleccionar la ruta al archivo elf:
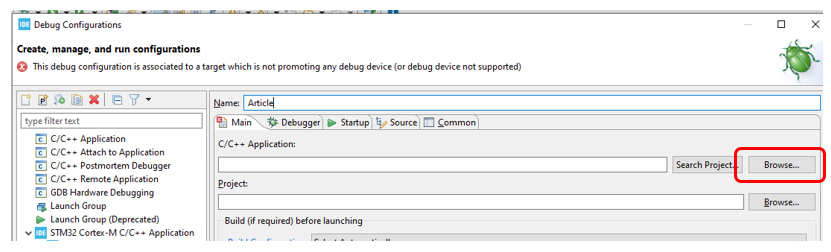
Elegí esta ruta (no debería haber letras rusas en ninguna parte de la ruta):

Y aquí el error parpadea . Aquí está, el rojo:
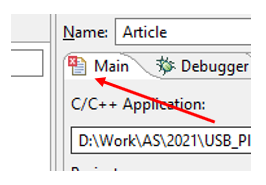
Para eliminarlo, tengo que seleccionar un proyecto vinculado a STM32F103. Aquí es donde debe ingresar a Examinar:
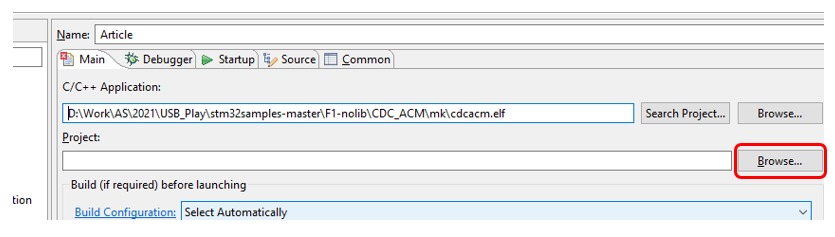
y seleccionar el proyecto izquierdo creado anteriormente.
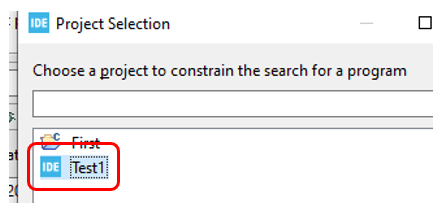
El rojo (signo de error) se ha ido:
¡Ups! En esta figura, puede ver que después de seleccionar un proyecto, el nombre del archivo elf saltó. El elfo de este proyecto fue registrado. Tuve que seleccionar el que necesitaba después de especificar el proyecto nuevamente. No es de extrañar que repasé todos los puntos.
Como no tenemos nada que recopilar aquí (recopilamos todo en lotes), debemos marcar la casilla para que el sistema no intente hacer un trabajo inútil:

En esta pestaña, todo. Vaya a la pestaña Depurador. Es cierto que aquí no es necesario cambiar nada. Al menos, si todo está configurado de la misma manera: en
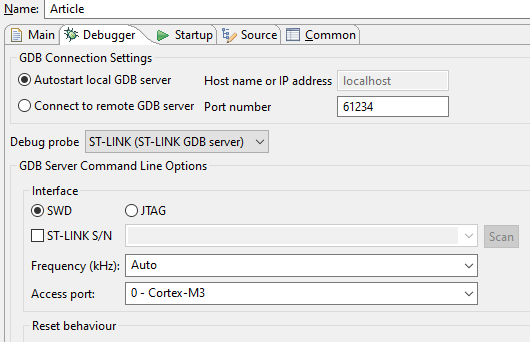
realidad, no necesita cambiar nada en ningún otro lugar. Bueno, ¿vamos a empezar a depurar?
Técnicamente, sí. Organizacionalmente, primero debemos preparar el código que ejecutaremos.
Comprobando la primera biblioteca
Entonces, descargue el proyecto stm32samples / F1-nolib / CDC_ACM en master eddyem / stm32samples GitHub para autoría EddyEm...
No olvide agregar la formación de información de depuración dwarf-2 al archivo MAKE:
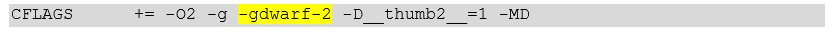
Lo mismo con el texto:
CFLAGS += -O2 -g -gdwarf-2 -D__thumb2__=1 -MD
Empezamos a editar el código.
Hay un bucle infinito en la función main (). Solo le dejaré cuernos, sí, piernas:
while (1){ IWDG->KR = IWDG_REFRESH; // refresh watchdog usb_proc(); get_USB(); }
Haré una función get_USB () funcional como esta:
uint32_t loop = 0; uint32_t errors = 0; uint32_t errState = 0; int32_t lastData = 0; int32_t show = 0; int32_t pkt = 0; #define USBBUF 63 char tmpbuf[USBBUF+1]; int32_t* pData = (int32_t*) tmpbuf; // usb getline char *get_USB() { int x = USB_receive((uint8_t*)tmpbuf) / sizeof(uint32_t); int i; show += 1; if(!x) return NULL; pkt += 1; // - // ! if (pData [0] == 0) { lastData = 0; errState = 0; loop += 1; } // if (errState) { return NULL; } // for (i=0;i<x;i++) { // ! if (pData[i]!=lastData++) { // ! errState = 1; // errors += 1; // return NULL; } } // return NULL; }
Se crean un montón de variables globales para monitorearlas en tiempo real. Los lugareños se pierden en cada inicio. Los globales son visibles para siempre.
La variable show indicará que el depurador realmente muestra todo. Se incrementa cada vez que se ingresa la función, haya o no datos. Y llamamos a la función en un bucle infinito todo el tiempo.
La variable pkt mostrará que los datos realmente provienen (al principio no provenían de mí). Aumentará solo si no salimos debido al hecho de que no había nada desde USB.
lastDatamostrará cuántos ya hemos contado en la prueba. Se asegurará de que realmente estemos trabajando con grandes bloques de datos. El valor de esta variable al final de la prueba muestra el tamaño del bloque en palabras dobles. Para comprender cuántos bytes han pasado, debe multiplicar el valor por 4. El
bucle aumentará cuando llegue un bloque de datos, comenzando en cero. En términos generales, este es el número de prueba. Bueno, o el número de ejecución. Cuando recopilo estadísticas para trazar, hay bastantes de estas ejecuciones. Diferentes tamaños de los bloques solicitados, multiplicados por repeticiones para promediar los resultados.
errState- una variable auxiliar que evita la aparición de una bola de nieve de errores. En el primer error, sube a uno y deja de analizar los datos antes de comenzar una nueva prueba.
errores : el contador de los errores que se produjeron una vez. Al principio, yo mismo cometí un error en la lógica, luego este contador aumentaba constantemente. Pero si todo va bien, no debería aumentar.
Casi lo olvido. También comenté la verificación de la bandera en la función USB_receive:

Lo mismo con el texto:
uint8_t USB_receive(uint8_t *buf){ if(/*!usbON ||*/ !rxNE) return 0; ...
Esta bandera se establece cuando el terminal establece la velocidad del puerto COM virtual. Mi programa de prueba, por otro lado, abre el dispositivo directamente a través del controlador WinUSB y no hace nada para personalizar la funcionalidad CDC. Lo más fácil de hacer fue ignorar esta bandera.
Bien. Cree el proyecto con un compilador por lotes y ejecútelo en el depurador CubeIDE. Como me dijeron, no a todos los lectores les gustan los dibujos animados. Para algunos, distraen de la lectura del texto. Pero esto es realmente agradable de ver.
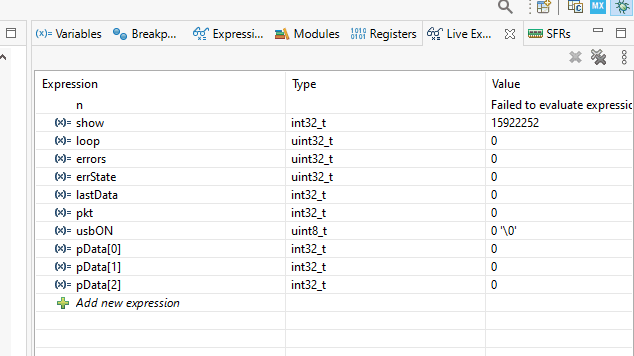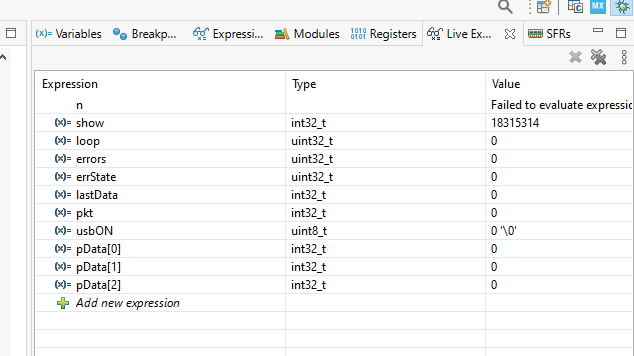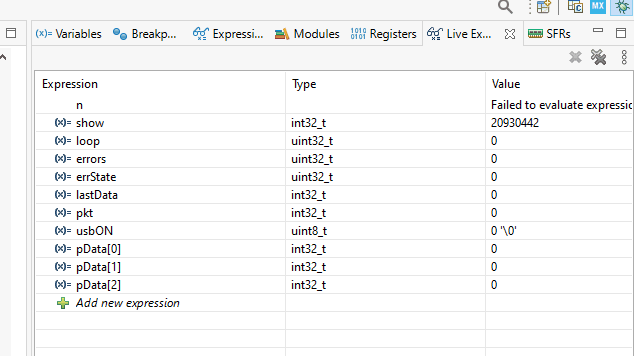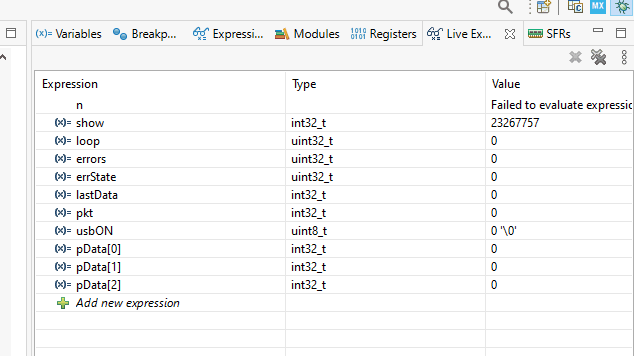
¡Está haciendo tictac! ¡Está haciendo tictac! ¡Está haciendo tictac!
Bien. Agregue llenar la matriz al programa de prueba:
QByteArray data; data.resize(totalSize); uint32_t* dwPtr = (uint32_t*) data.constData(); for (uint32_t i = 0;i<totalSize/4;i++) { dwPtr[i] = i; }
Y ejecutamos la prueba. Obtenemos este tipo de belleza en las variables (cero errores):

Y aquí hay un gráfico de la velocidad:

Los valores son ligeramente menores que en una operación completamente inactiva, pero aún así son agradables. En general, se ha agregado ST-LINK a mi sistema y la cantidad de bits que se ejecutan a través de USB depende de los datos que se bombean (a veces se puede insertar un bit de sincronización).
Un caballo esférico trabaja en el vacío, pero ¿qué pasa con el real?
Existe un problema potencial con todo este sistema. Ahora, la función de recibir datos se llama constantemente en un bucle infinito. No tenemos ningún trabajo útil especial en este momento. ¿Y si lo son? Entonces, la llamada de esta función puede ocurrir no inmediatamente después de la llegada del paquete, sino con un retraso.
¿Vamos a probar diferentes opciones? En la mente, sería necesario, pero no hay tiempo. Actualmente estoy ocupado en el trabajo con un controlador completamente diferente. Y luego me divertí el fin de semana. Por tanto, iremos al revés. Pegaremos la recepción de datos al hecho de su llegada.
Estas cosas se hacen con interrupciones. Pero en el último artículo se dijo que si estiramos el controlador de interrupciones USB, el hardware comenzará a enviar NAK y todo el encanto de la biblioteca en cuestión se esfumará. ¿Cómo obtenemos una interrupción, pero no nos demoramos en la interrupción?
Bueno, aquí se conoce el camino. En el manejador de interrupciones USB, debemos hacerlo para que inmediatamente después de salir de él, la interrupción también se dispare, pero alguna otra. Y allí rápidamente, con una latencia baja garantizada, llevaremos los datos del búfer de hardware a nuestro interno. ¿Qué interrupción para sentarse? Examinando el código de inicio. Es decir, manipuladores de interrupciones. Nuestra tarea es encontrar la que no se usa.
Aquí está el archivo que nos interesa
\ stm32samples-master \ F1-nolib \ inc \ startup \ vector.c
Permítanme tomar prestada descaradamente una interrupción del tercer UART. De hecho, tampoco usamos el primero. Pero tal vez lo sea más tarde. Y nunca he usado el tercero en mi vida. Por lo tanto, personalmente, me sentaré descaradamente sobre este manejador en particular. Así es como se describe:
[NVIC_USART3_IRQ] = usart3_isr, \
Conociendo el nombre, crea una función en el archivo main.c:
void usart3_isr() { NVIC_ClearPendingIRQ(USART3_IRQn); get_USB(); }
Esta será una especie de función de devolución de llamada. Y ya nos llamará el código que escribimos recientemente. Y comentemos la llamada a get_USB () en un bucle infinito.
Ahora necesitamos establecer esta interrupción en una prioridad más baja para que no interfiera con nadie. En la vida real, es posible que deba ser creativo al elegir una prioridad. Pero hoy solo tomaré el decimoquinto. Agregamos el siguiente código a la parte de inicialización de la función main ():
NVIC_SetPriority(USART3_IRQn, 15); NVIC_EnableIRQ(USART3_IRQn);
Bueno, ahora viene la parte divertida. En el controlador de interrupciones USB, agregue una provocación para activar la interrupción USART3, si hubo una llamada a nuestro punto final:

El mismo texto.
#include "stm32f10x.h" … void usb_lp_can_rx0_isr(){ LED_off(LED0); if(USB->ISTR & USB_ISTR_RESET){ … } if(USB->ISTR & USB_ISTR_CTR){ // EP number uint8_t n = USB->ISTR & USB_ISTR_EPID; if (n == 1) { NVIC_SetPendingIRQ(USART3_IRQn); } // copy status register uint16_t epstatus = USB->EPnR[n]; // copy received bytes amount …
Dado que la prioridad es baja, no sucederá nada hasta el final de la interrupción del USB. Pero tan pronto como termine, inmediatamente nos llamarán. Porque todavía no tenemos otras interrupciones. Incluso con la decimoquinta prioridad, seremos los VIP.
Lanzamos. Al principio da miedo que la variable show no esté aumentando. Pero es normal. Ahora, la función no se llama incondicionalmente, sino solo después de la interrupción real. Entonces tenemos que empezar a probar.
Puede ver el proceso de prueba para siempre.
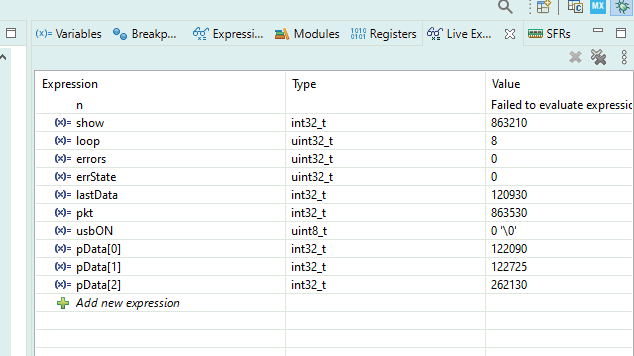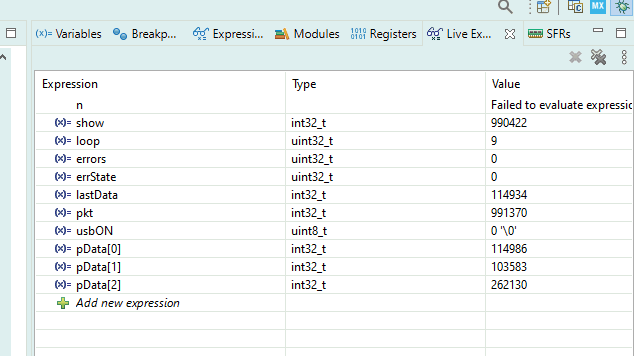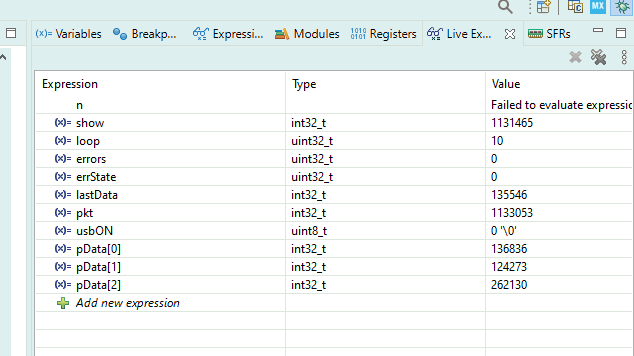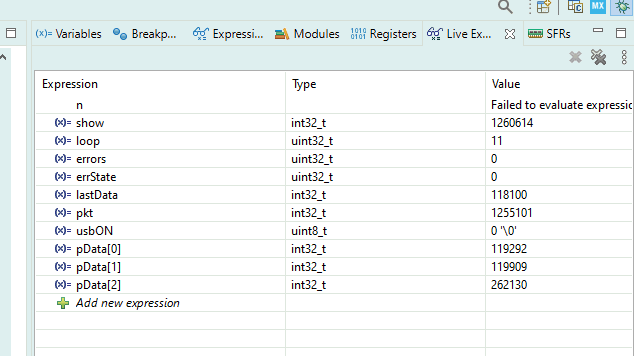
Y aquí está la métrica de velocidad:
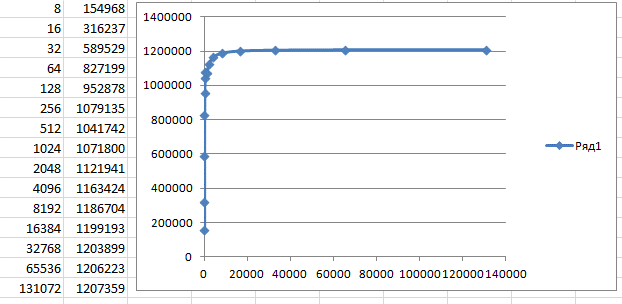
Comprobando la segunda biblioteca
Ahora verificamos la biblioteca usb / 5.CDC_F1 en el GitHub principal de COKPOWEHEU / usb por COKPOWEHEU... Puede encontrar una descripción de esta biblioteca aquí: USB en registros: STM32L1 / STM32F1 / . Aquí es donde se nos proporcionan funciones de devolución de llamada para manejar la actividad del punto final. Aquí lo arreglaremos. La variable show ya no es necesaria. Siempre estamos llamados a la llegada de los datos. De lo contrario, obtenemos prácticamente el mismo código.
uint32_t loop = 0; uint32_t errors = 0; uint32_t errState = 0; int32_t lastData = 0; int32_t pkt = 0; void data_out_callback(uint8_t epnum){ int i; uint8_t buf[ ENDP_DATA_SIZE ]; int32_t* pData = (int32_t*) buf; int len = usb_ep_read_double( ENDP_DATA_OUT, buf) / sizeof (uint32_t); if(len == 0)return; pkt += 1; // - // ! if (pData [0] == 0) { lastData = 0; errState = 0; loop += 1; } // if (errState) { return NULL; } // for (i=0;i<len;i++) { // ! if (pData[i]!=lastData++) { // ! errState = 1; // errors += 1; // return NULL; } } }
Al consultar conmigo, CubeIDE por alguna razón determinó incorrectamente la dirección de inicio. Quizás exista algún tipo de incompatibilidad con el mismo proyecto de "izquierda". Pospongamos esto para un estudio separado. Hasta que comencé a entender, pero desde el principio ingresé el valor correcto del registro de la PC. El código se ejecutó y comenzó a funcionar. Ejecutamos la prueba. El número de errores también es cero:

la velocidad también es decente:
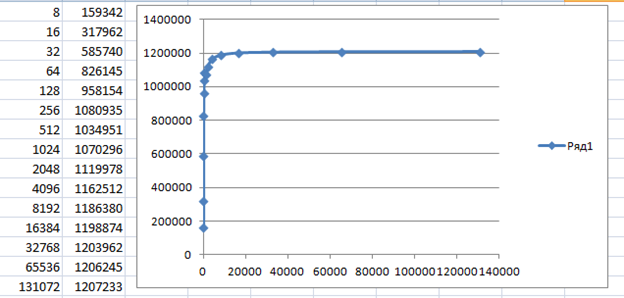
Conclusión
Ambas bibliotecas USB rusas hicieron frente a pruebas de carga aproximadas. Ninguno abandonó la carrera. Es cierto, sé de primera mano que las pruebas no prueban la ausencia de errores, sino que revelan su presencia. Pero las pruebas citadas específicamente no revelaron nada. Esto da la esperanza de que se pueda utilizar cualquiera de estas bibliotecas.
En el camino, hemos dominado el reemplazo de la salida de depuración al monitorear una serie de variables en tiempo real a través del puerto SWD. En general, también dominamos la depuración de cualquier aplicación creada por lotes en Eclipse, pero en el camino, debido a la combinación de los dos proyectos, tuve algunas dificultades que tuve que superar al corregir el registro de la PC directamente. Pero en un Eclipse normal, este tipo de mezcla no es necesaria. Y al final, incluso con la ayuda de una hoz, un martillo y algún tipo de madre, se logró el objetivo final. Se ha realizado la depuración. Al mismo tiempo, los códigos fuente en Syakh todavía se mostraban en Eclipse.
Epílogo
Cuando el artículo ya estaba escrito, pero aún estaba en proceso de subirlo a Habr, apareció un material tan maravilloso para la autoría. DSarovsky... Allí también se implementa el acceso a USB, pero esto se hace a través de una biblioteca creada en mi estilo favorito: el estilo de Konstantin Chizhov.
Simplemente me veo obligado a señalar la existencia de una biblioteca realizada en una versión tan hermosa. Por el momento, verificamos el rendimiento con su autor y descubrimos que hasta ahora su velocidad es típica, no máxima. Pero es posible que cuando leas estas líneas, ya se haya overclockeado. Por tanto, te dejo un enlace entre otros. ¡Simplemente tiene que despegar! ¡Las bibliotecas de este estilo no pueden evitar despegar!