
sobre el proyecto
Hay muchos problemas interesantes en el campo del procesamiento de lenguajes de programación, cuya solución automática puede ser útil para crear herramientas convenientes para los desarrolladores.
El código fuente de los programas difiere en muchos aspectos de los textos en lenguaje natural, pero también se puede considerar como una secuencia de tokens y se pueden utilizar métodos similares. Por ejemplo, en el campo del procesamiento del lenguaje natural, el modelo de lenguaje BERT se utiliza activamente. El proceso de su entrenamiento involucra dos etapas: entrenamiento previo en un gran conjunto de datos sin etiquetar y entrenamiento adicional para tareas específicas en conjuntos de datos etiquetados más pequeños. Este enfoque permite resolver muchas tareas con muy buena calidad.
Trabajos recientes ( 1 , 2, 3 ) mostró que si entrena el modelo BERT en un gran conjunto de datos de código de programa, entonces se adapta bien a varias tareas en esta área (entre ellas, por ejemplo, localización y eliminación de variables utilizadas incorrectamente y generación de comentarios a métodos) .
El proyecto tiene como objetivo investigar el uso de BERT para otras tareas de código fuente. En particular, nos centramos en la tarea de generar automáticamente mensajes de confirmación.
Sobre la tarea
¿Por qué elegimos esta tarea?
En primer lugar, los sistemas de control de versiones se utilizan en el desarrollo de muchos proyectos, por lo que una herramienta para resolver automáticamente este problema puede ser relevante para una amplia gama de desarrolladores.
En segundo lugar, planteamos la hipótesis de que el uso de BERT para esta tarea podría generar buenos resultados. Esto se debe a varias razones:
- en los trabajos existentes ( 4 , 5 , 6 ), los datos se recopilan de fuentes abiertas y requieren un filtrado serio, por lo que hay pocos ejemplos de capacitación. Aquí es donde la capacidad de BERT para entrenar en pequeños conjuntos de datos puede resultar útil;
- El resultado de vanguardia en el momento de trabajar en el proyecto estaba en el modelo de arquitectura Transformer, que se prepredicó de una manera bastante específica en un pequeño conjunto de datos ( 6 ). Para nosotros fue interesante compararlo con el modelo basado en BERT, que está preentrenado de una manera diferente, pero con muchos más datos.
Durante el semestre, tuve que hacer lo siguiente:
- estudiar el área temática;
- encontrar un conjunto de datos y seleccionar una representación de los datos de entrada;
- desarrollar un canal de capacitación y evaluación de la calidad;
- llevar a cabo experimentos.
Datos
Hay varios conjuntos de datos abiertos para esta tarea, elegí el más filtrado ( 5 ).
El conjunto de datos se recopiló de los 1000 principales repositorios abiertos de GitHub en el lenguaje Java. Después de filtrar, de los millones originales de ejemplos, quedan alrededor de 30 mil.
Los ejemplos en sí son pares de la salida del comando git diff y el mensaje corto correspondiente en inglés. Se parece a esto:
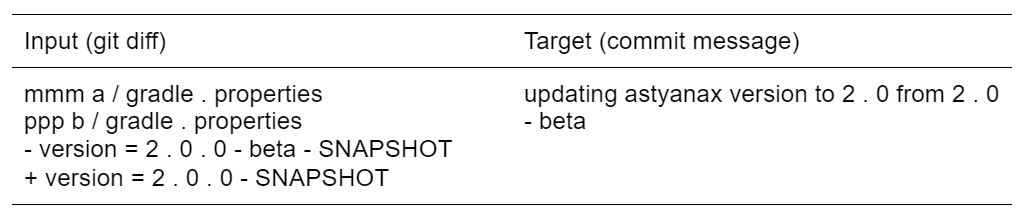
tanto los cambios como los mensajes en el conjunto de datos son cortos, no más de 100 y 30 tokens, respectivamente.
En la mayor parte del trabajo existente que investiga el problema de generar automáticamente mensajes para confirmaciones, se alimenta a los modelos una secuencia de tokens de git diff.
Hay otra idea: seleccionar explícitamente dos secuencias, antes y después de los cambios, y alinearlas utilizando el algoritmo clásico para calcular la distancia editorial. Por lo tanto, los tokens cambiados siempre están en las mismas posiciones.
Idealmente, nos gustaría probar varios enfoques y comprender cómo afectan la calidad de la resolución de este problema. En la etapa inicial, utilicé uno bastante simple: se alimentaron dos secuencias a la entrada del modelo, antes y después de los cambios, pero sin ninguna alineación.
BERT para tareas secuenciales
Tanto los datos de entrada como los de salida para la tarea de generar automáticamente mensajes para confirmaciones son secuencias, cuya longitud puede diferir.
Para solucionar este tipo de problemas, se suele utilizar una arquitectura codificador-decodificador, que consta de dos componentes:
- el modelo de codificador construye una representación vectorial basada en la secuencia de entrada,
- el decodificador de modelo genera una secuencia de salida basada en la representación del vector.
El modelo BERT se basa en un codificador de la arquitectura Transformer y por sí solo no es adecuado para tal tarea. Son posibles varias opciones para obtener un modelo de secuencia a secuencia completo, la más simple es usar algún tipo de decodificador con él. Este enfoque con un decodificador de la arquitectura Transformer se ha mostrado bien, por ejemplo, para la tarea de traducción automática neuronal ( 7 ).
Tubería
Para realizar los experimentos, se necesitaba un código para entrenar y evaluar la calidad de dicho modelo secuencia a secuencia.
Para trabajar con el modelo BERT, utilicé la biblioteca Transformers de HuggingFace y para la implementación en general, el marco PyTorch.
Dado que al principio tenía poca experiencia con PyTorch, confié en gran medida en ejemplos existentes para modelos secuencia a secuencia de otras arquitecturas, adaptándome gradualmente a las especificaciones de mi tarea. Desafortunadamente, este enfoque resultó en una gran cantidad de código de mala calidad.
En algún momento, se decidió comenzar a refactorizar, prácticamente reescribiendo la tubería. La biblioteca PyTorch Lightning ayudó a estructurar el código, lo que le permite recopilar toda la lógica principal del modelo en un módulo y automatizarlo de muchas maneras.
Experimentos
Durante los experimentos, queríamos comprender si el uso del modelo BERT previamente entrenado mejora el resultado de vanguardia en esta área.
Entre los modelos BERT entrenados en el código, solo se nos acercó CodeBERT ( 1 ), ya que solo tenía el lenguaje de programación Java en los ejemplos de entrenamiento. Primero, usando CodeBERT como codificador, probé decodificadores de diferentes arquitecturas:
- GRU.
, - . GRU Transformer, , .
- . - Transformer.
, — .
, GPT-2 (8) — Transformer, , — distilGPT-2 (9).
No hubo tiempo suficiente para más experimentos en el semestre de otoño; los continué en el invierno. Observamos varias otras formas de representar la entrada: intentamos alinear las secuencias antes y después de los cambios, y también presentamos un git diff.
Los principales resultados de los experimentos son los siguientes:


Resumiendo
En general, no se confirmó la suposición sobre los beneficios de usar CodeBERT para esta tarea; en todos los casos, el modelo Transformer entrenado desde cero mostró mayor calidad. El mejor método en esta área sigue siendo el modelo CoreGen6: este también es un Transformer, pero adicionalmente entrenado previamente usando la función objetivo propuesta por los autores.
Para resolver este problema, se pueden considerar muchas más ideas: por ejemplo, pruebe la representación de datos basada en árboles de sintaxis abstracta, que se usa a menudo cuando se trabaja con código de programa ( 10 , 11), pruebe otros modelos previamente entrenados o realice algún entrenamiento previo específico de campo si hay recursos disponibles. En el semestre de primavera, nos centramos en una aplicación más práctica de los resultados obtenidos y nos dedicamos a la autocompletación de mensajes a confirmaciones. Les contaré sobre esto en la segunda parte :)
En conclusión, quiero decir que fue realmente interesante participar en el proyecto, me sumergí en una nueva área temática para mí y aprendí mucho durante este tiempo. El trabajo en el proyecto estuvo muy bien organizado, por lo que muchas gracias a mis líderes.
¡Gracias por la atención!
Fuentes de
- Feng, Zhangyin y col. "Codebert: un modelo previamente entrenado para programación y lenguajes naturales". 2020
- Buratti, Luca, et al. «Exploring Software Naturalness through Neural Language Models.» 2020
- Kanade, Aditya, et al. «Learning and Evaluating Contextual Embedding of Source Code.» 2020
- Jiang, Siyuan, Ameer Armaly, and Collin McMillan. «Automatically generating commit messages from diffs using neural machine translation.» 2017
- Liu, Zhongxin, et al. «Neural-machine-translation-based commit message generation: how far are we?.» 2018
- Nie, Lun Yiu, et al. «CoreGen: Contextualized Code Representation Learning for Commit Message Generation.» 2021
- Rothe, Sascha, Shashi Narayan, and Aliaksei Severyn. «Leveraging pre-trained checkpoints for sequence generation tasks.» 2020
- Radford, Alec, et al. «Language models are unsupervised multitask learners.» 2019
- Sanh, Victor, et al. «DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.» 2019
- Yin, Pengcheng, et al. «Learning to represent edits.» 2018
- Kim, Seohyun, et al. «Code prediction by feeding trees to transformers.» 2021