
En una serie de artículos, quiero refutar los conceptos erróneos asociados con la administración de memoria y profundizar en su estructura en algunos lenguajes de programación modernos: Java, Kotlin, Scala, Groovy y Clojure. Esperamos que este artículo le ayude a descubrir qué está pasando bajo el capó de estos idiomas. Primero, veremos la administración de memoria en Java Virtual Machine (JVM) , que se usa en Java, Kotlin, Scala, Clojure, Groovy y otros lenguajes. En el primer artículo, también cubrí la diferencia entre una pila y un montón, que es útil para comprender este artículo.
Estructura de la memoria JVM
Primero, echemos un vistazo a la estructura de la memoria JVM. Esta estructura se ha utilizado desde JDK 11 . Esta es la memoria disponible para el proceso JVM, la asigna el sistema operativo:
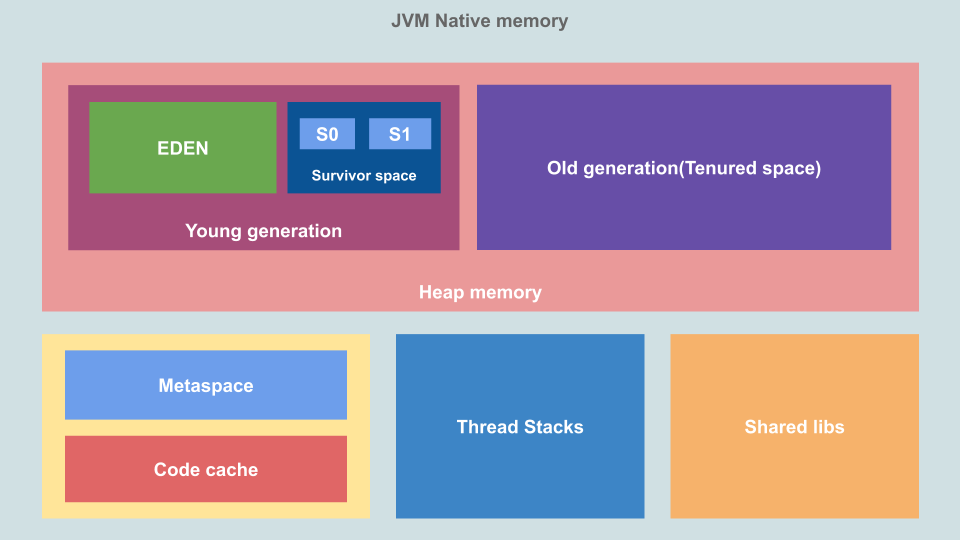
Esta es la memoria nativa asignada por el sistema operativo y su tamaño depende del sistema, procesador y JRE. ¿Qué áreas y para qué están destinadas?
Montón
Aquí es donde la JVM almacena objetos y datos dinámicos. Esta es el área de memoria más grande y es donde trabaja el recolector de basura. El tamaño del montón se puede controlar con los indicadores
Xms
(tamaño inicial) y
Xmx
(tamaño máximo). El montón no se transfiere a la máquina virtual como un todo, una parte se reserva como espacio virtual, por lo que el montón puede crecer en el futuro. El montón se divide en espacios de la generación "joven" y "vieja".
- La generación joven , o "nuevo espacio": el ámbito en el que viven los nuevos objetos. Está dividido en Eden Space y Survivor Space. El área de control de la generación joven, " el recolector de basura más joven » (Minor GC), que también se llama "el joven" (Young GC).
- Paraíso : aquí es donde se asigna la memoria cuando creamos nuevos objetos.
- Área de supervivientes : aquí es donde se almacenan los objetos sobrantes del recolector de basura menor. El área se divide en dos mitades, S0 y S1 .
- Antigua generación o "almacenamiento" (espacio de propiedad): incluye los objetos que han alcanzado el umbral máximo de almacenamiento durante la vida de un recolector de basura junior. Este espacio está gestionado por un Major GC.
Pilas de hilo
Esta es un área de pila en la que se asigna una pila por subproceso. Aquí es donde se almacenan los datos estáticos específicos del subproceso, incluidos los marcos de método y función, y los punteros a los objetos. El tamaño de la memoria de la pila se puede establecer mediante una bandera
Xss
.
Metaespacio
Esto es parte de la memoria nativa, por defecto no tiene límite superior. En versiones anteriores de la JVM, esta memoria se denomina espacio de generación permanente ( Espacio de generación permanente (PermGen)) . Los cargadores de clases almacenaban definiciones de clases en él. Si este espacio crece, el sistema operativo puede mover los datos almacenados aquí de la RAM a la memoria virtual, lo que puede ralentizar la aplicación. Esto se puede evitar configurando el tamaño del MetaSpace mediante banderas
XX:MetaspaceSize
y
-XX:MaxMetaspaceSize
, en este caso, la aplicación puede generar un error de memoria.
Caché de código
Aquí es donde el compilador Just In Time (JIT) almacena bloques de código compilados a los que necesita acceder con frecuencia. Por lo general, la JVM interpreta el código de bytes en código de máquina nativo, sin embargo, el código compilado por el compilador JIT no necesita ser interpretado, ya está en formato nativo y almacenado en caché en esta área de memoria.
Bibliotecas compartidas
Aquí es donde se almacena el código nativo de las bibliotecas compartidas. El sistema operativo carga esta área de memoria solo una vez para cada proceso.
Uso de memoria JVM: pila y montón
Ahora echemos un vistazo a cómo el programa ejecutable usa las partes más importantes de la memoria. Usemos el siguiente código. No está optimizado para ser correcto, así que ignore problemas como variables intermedias innecesarias, modificadores incorrectos y más. Su trabajo es visualizar el uso de la pila y el montón.
class Employee {
String name;
Integer salary;
Integer sales;
Integer bonus;
public Employee(String name, Integer salary, Integer sales) {
this.name = name;
this.salary = salary;
this.sales = sales;
}
}
public class Test {
static int BONUS_PERCENTAGE = 10;
static int getBonusPercentage(int salary) {
int percentage = salary * BONUS_PERCENTAGE / 100;
return percentage;
}
static int findEmployeeBonus(int salary, int noOfSales) {
int bonusPercentage = getBonusPercentage(salary);
int bonus = bonusPercentage * noOfSales;
return bonus;
}
public static void main(String[] args) {
Employee john = new Employee("John", 5000, 5);
john.bonus = findEmployeeBonus(john.salary, john.sales);
System.out.println(john.bonus);
}
}
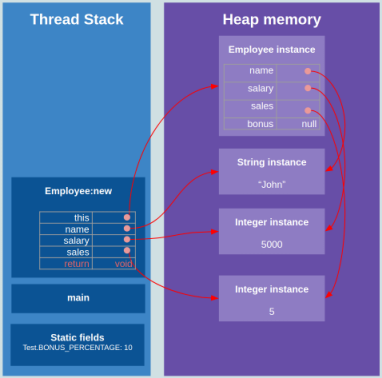
Aquí puede ver cómo se ejecuta el programa anterior y cómo se utilizan la pila y el montón:
https://files.speakerdeck.com/presentations/9780d352c95f4361bd8c6fa164554afc/JVM_memory_use.pdf
Como puede ver:
- Cada llamada de función se inserta en el hilo de la pila de ejecución como un bloque de marco.
- Todas las variables locales, incluidos los argumentos y los valores de retorno, se almacenan en la pila dentro de los bloques del marco de función.
- int .
- Employee, Integer String , . .
- , , .
- , .
- ().
- , .
La pila la administra automáticamente el sistema operativo, no la JVM. Por lo tanto, no hay necesidad de cuidarlo especialmente. Pero el montón ya no se administra de esta manera, y dado que esta es el área más grande de memoria que contiene datos dinámicos, puede crecer exponencialmente y el programa puede ocupar toda la memoria con el tiempo. Además, el montón se fragmenta gradualmente, lo que ralentiza el rendimiento de las aplicaciones. La JVM ayudará a resolver estos problemas. Gestiona automáticamente el montón mediante la recolección de basura.
Gestión de memoria JVM: recolección de basura
Echemos un vistazo a la gestión automática del montón, que juega un papel muy importante en el rendimiento de la aplicación. Cuando un programa intenta asignar más memoria en el montón de la que está disponible (dependiendo del valor
Xmx
), obtenemos errores de memoria .
La JVM administra la pila mediante la recolección de basura. Para dejar espacio para la creación de un nuevo objeto, la JVM limpia la memoria ocupada por objetos huérfanos, es decir, objetos a los que ya no se hace referencia directa o indirectamente desde la pila.
El recolector de basura JVM es responsable de:
- Obtener memoria del sistema operativo y devolverla al sistema operativo.
- Transferencia de memoria asignada a la aplicación a solicitud de ésta.
- Determine qué partes de la memoria asignada todavía están en uso por la aplicación.
- Reclamación de memoria no utilizada para uso de la aplicación.
Los recolectores de basura en la JVM trabajan de forma generacional (los objetos en el montón se agrupan por antigüedad y se limpian durante diferentes etapas). Hay muchos algoritmos de recolección de basura diferentes, pero Mark & Sweep es el más utilizado .
Recolector de basura Mark & Sweep
La JVM utiliza un subproceso de demonio separado que se ejecuta en segundo plano para la recolección de basura. Este proceso comienza cuando se cumplen ciertas condiciones. El colector Mark & Sweep generalmente funciona en dos etapas, a veces se agrega una tercera, dependiendo del algoritmo utilizado.

- Marcado : en primer lugar, el recopilador determina qué objetos están en uso y cuáles no. Aquellos usados o accedidos por punteros de pila se marcan recursivamente como vivos.
- Eliminación : el recolector recorre el montón y elimina todos los objetos que no están marcados como vivos. Estas ubicaciones de memoria están marcadas como libres.
- Compresión : después de eliminar los objetos no utilizados, todos los objetos supervivientes se mueven para que estén juntos. Esto reduce la fragmentación y acelera la asignación de memoria para nuevos objetos.
Este tipo de recopilador también se llama stop-the-world, porque mientras se eliminan, hay pausas en la aplicación.
La JVM ofrece varios algoritmos de recolección de basura diferentes para elegir y, dependiendo de su JDK, puede haber incluso más opciones (por ejemplo, el recolector de Shenandoah en OpenJDK). Los autores de diferentes implementaciones apuntan a diferentes objetivos:
- Rendimiento : tiempo dedicado a la recolección de basura, sin ejecutar la aplicación. Idealmente, el rendimiento debería ser alto, es decir, las pausas de recolección de basura son breves.
- Duración de las pausas : cuánto tiempo interfiere el recolector de basura con la ejecución de la aplicación. Idealmente, las pausas deberían ser muy cortas.
- Tamaño del montón : idealmente debería ser pequeño.
Coleccionistas en JDK 11
JDK 11 es la versión actual de LTE. A continuación se muestra una lista de los recolectores de basura disponibles en él, y la JVM elige uno de forma predeterminada según el hardware y el sistema operativo actuales. Siempre podemos forzar la selección de un selector mediante un botón de opción
-XX
.
- : , , .
-XX:+UseSerialGC
. - : , . , / .
-XX:+UseParallelGC
. - Garbage-First (G1): ( ). , . .
-XX:+UseG1GC
. - Z: , , JDK11. . , stop-the-world. , / ( ).
-XX:+UseZGC
.
Independientemente del colector que se seleccione, la JVM utiliza dos tipos de ensamblaje: el coleccionista menor y el coleccionista principal.
Ensamblador Junior
Mantiene la limpieza y la compacidad del espacio de la generación más joven. Se inicia cuando la JVM no puede obtener la memoria necesaria en el cielo para acomodar un nuevo objeto. Inicialmente, todas las áreas del montón están vacías. El paraíso se llena primero, seguido por el área de supervivientes y, al final, el almacenamiento.
Puedes ver el proceso de este recopilador aquí:
https://files.speakerdeck.com/presentations/f4783404769145f4b990154d0cc05629/JVM_minor_GC.pdf
- Digamos que ya hay objetos en el paraíso (los bloques 01 a 06 están marcados como usados).
- La aplicación crea un nuevo objeto (07).
- JVM , , JVM .
- ( ), — ().
- JVM S0 S1 «» (To Space), S0. «» , , , .
- , .
- , - , ( 07 13 ).
- (14).
- JVM , , JVM .
- , , « ».
- JVM «» S1, S0 «». «» «» (S1), , . , «», , (premature promotion). , .
- «» (S0), .
- Esto se repite con cada sesión de coleccionista junior, los supervivientes se mueven entre S0 y S1 y su edad aumenta. Cuando alcanza el "umbral máximo" especificado, que es 15 por defecto, el objeto se mueve al "almacenamiento".
Observamos cómo el coleccionista junior limpia la memoria en el espacio de la generación más joven. Este es un proceso de detener el mundo, pero es tan rápido que su duración generalmente puede pasarse por alto.
Ensamblador Senior
Supervisa la limpieza y la compacidad del espacio de la vieja generación (almacenamiento). Funciona bajo una de las siguientes condiciones:
- El desarrollador llama al programa
System
.gc()
oRuntime.getRunTime().gc()
. - La JVM decide que la tienda no tiene memoria porque está llena como resultado de sesiones pasadas del coleccionista junior.
- Si mientras se ejecuta el coleccionista junior JVM no puede obtener suficiente memoria en el paraíso o en el área de sobrevivientes.
- Si configuramos un parámetro en la JVM
MaxMetaspaceSize
y no hay suficiente memoria para cargar nuevas clases.
El proceso de trabajo del coleccionista senior es más sencillo que el del junior:
- Digamos que han pasado muchas sesiones de coleccionista junior y el almacenamiento está casi lleno. La JVM decide ejecutar el recopilador más antiguo.
- En el almacenamiento, atraviesa de forma recursiva el gráfico de objetos a partir de punteros de pila y marca los objetos usados como (memoria usada), el resto como basura (perdido). Si el coleccionista senior se lanzó durante el trabajo del coleccionista junior, entonces su trabajo cubre el espacio de la generación más joven (el paraíso y el área de los sobrevivientes) y la bóveda.
- El recolector elimina todos los objetos huérfanos y recupera la memoria.
- Si no quedan objetos en el montón durante el trabajo del recolector anterior, la JVM también recupera memoria del metaespacio, eliminando las clases cargadas de él, si se trata de una recolección de basura completa.
Conclusión
Hemos cubierto la estructura y la gestión de la memoria de la JVM. Este no es un artículo exhaustivo, no hemos hablado sobre muchos de los conceptos y formas más complejos de personalizar para casos de uso específicos. Puedes leer más detalles aquí .
Pero para la mayoría de los desarrolladores de JVM (Java, Kotlin, Scala, Clojure, JRuby, Jython) esta cantidad de información será suficiente. Con suerte, ahora puede escribir mejor código, crear aplicaciones más eficientes y evitar varios problemas con pérdidas de memoria.