
Mi nombre es Sasha, en SberDevices trabajo en el reconocimiento de voz y en cómo los datos pueden mejorarlo. En este artículo, hablaré sobre el nuevo conjunto de datos de voz de Golos, que consta de archivos de audio y las transcripciones correspondientes. La duración total de las grabaciones es de aproximadamente 1240 horas, la frecuencia de muestreo es de 16 kHz. Por el momento, este es el corpus más grande de grabaciones de audio en ruso, marcado a mano. Lanzamos el corpus bajo una licencia cercana a CC Attribution ShareAlike , lo que permite su uso tanto para investigación científica como para fines comerciales. Hablaré sobre en qué consiste el conjunto de datos, cómo se ensambló y qué resultados puede lograr.
Estructura del conjunto de datos de Golos
Al crear el conjunto de datos, nos guiamos por el deseo de resolver el problema del arranque en frío, cuando los datos de usuarios reales aún no estaban disponibles. Esto es lo que finalmente hizo posible ponerlo a disposición del público, ya que el discurso de los usuarios reales no está ahí.
Las grabaciones de audio del conjunto de datos se recopilan de dos fuentes. La primera fuente es una plataforma de crowdsourcing, por eso la llamamos Crowd Domain. La segunda fuente son las grabaciones creadas en el estudio utilizando el dispositivo de destino SberPortal. Tiene un sistema de micrófono especial, y este es uno de los dispositivos en los que debería funcionar nuestro reconocimiento de voz.
A esta fuente la llamamos dominio de Farfield, ya que la distancia del usuario al dispositivo suele ser bastante grande. Para grabar a través de SberPortal en el estudio, utilizamos tres distancias: 1, 3 y 5 metros del usuario al dispositivo. Cada dominio tiene una parte de entrenamiento y prueba, la estructura resultante se muestra en la tabla:
| Dominios | Parte de entrenamiento | Parte de prueba |
|---|---|---|
| Multitud | 979 796 archivos | 1095 horas | 9994 archivos | 11,2 horas |
| Campo lejano | 124 003 archivos | 132,4 horas | 1916 archivos | 1,4 horas |
| Total | 1 103 799 archivos | 1227,4 horas | 11910 archivos | 12,6 horas |
No hay información personal en el conjunto de datos, como edad, sexo o ID de usuario; todo es impersonal. Las partes de entrenamiento y prueba pueden contener el discurso del mismo usuario.
| Estadísticas \ Dominios | Multitud | Campo lejano |
|---|---|---|
| número | 979796 archivos | 124003 archivos |
| Promedio | 4.0 seg. | 3,8 segundos |
| Desviación Estándar | 1,9 seg. | 1,6 seg. |
| 1er percentil | 1,4 seg. | 2,0 seg. |
| Percentil 50 | 3,7 segundos | 3,5 seg. |
| Percentil 95 | 7,3 segundos | 6,8 segundos |
| Percentil 99 | 10,5 seg. | 9,6 seg. |
La tabla anterior proporciona información estadística sobre las entradas: media, desviación estándar y percentiles. Para mayor claridad, la figura muestra dos histogramas de la distribución de las longitudes de los registros:
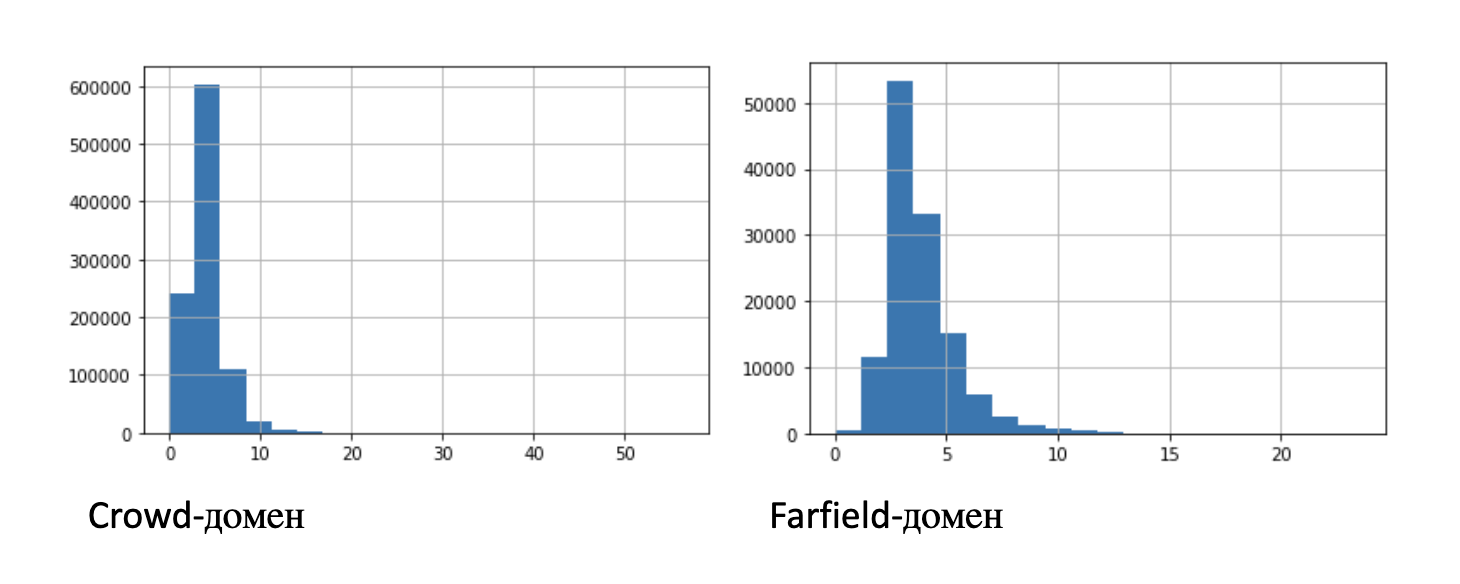
Para experimentos con un número limitado de registros, identificamos subconjuntos de menor duración: 100 horas, 10 horas, 1 hora, 10 minutos.
Recopilación de datos
En SberDevices, estamos desarrollando la familia Salute de asistentes virtuales, por lo que generamos un discurso similar a las solicitudes de los usuarios para un asistente. Hemos creado un sistema de plantillas para describir solicitudes en diferentes dominios: música, películas, pedidos de productos y otros. Son expresiones que describen la estructura de una solicitud y la descomponen en componentes. Usando plantillas, podemos generar consultas razonables, reentrenar el modelo acústico, crear un modelo de lenguaje basado en estas consultas y mucho más.
Plantillas de muestra:
| Plantilla | Ejemplo |
|---|---|
| [command_demands_vp] + [film_syn_vp] + [film_title_ip] | Juega el libro verde de la película |
| [command_demands_ip] + [film_syn_ip] + [film_title_ip] | Tienes un libro verde de película |
| [command_demands_ip] + [film_title_ip] | Tienes un libro verde |
| [film_title_ip] + [command_demands_vp] | poner libro verde |
| [film_syn_ip] + [film_title_ip] + [command_demands_vp] | filmar el libro verde puesto |
| [film_title_ip] | libro Verde |
| [command_demands_vp] + [film_title_ip] | enciende el libro verde |
| [film_syn_ip] + [film_title_ip] | libro verde de la película |
| [command_demands_vp] + [film_title_ip] | Enciende el libro verde |
| ... | ... |
Entre corchetes: la designación de la entidad correspondiente. Más adelante en la tabla para dos entidades "film_title_ip" y "film_title_vp" hay posibles opciones para llenarlo:
| film_title_ip | film_title_vp |
|---|---|
| obsesión | obsesión |
| el escape | el escape |
| la bella y la Bestia | la bella y la Bestia |
| isla | isla |
| Jane Eyre | Jane Eyre |
| cumbres borrascosas | cumbres borrascosas |
| ... | ... |
El proceso de creación de un conjunto de datos de audio etiquetado consta de varias etapas:
- Paso 1. Primero, creamos plantillas para un determinado dominio.
- 2. - . , :
- 3. «» :
- 4. – , , . – . 80% Golos. , “”, , . , , .
- 4*. - , , , , , , . , . , , , , , . , .

- 5*. , . , . , , , . , , , . , , , . , . :

:
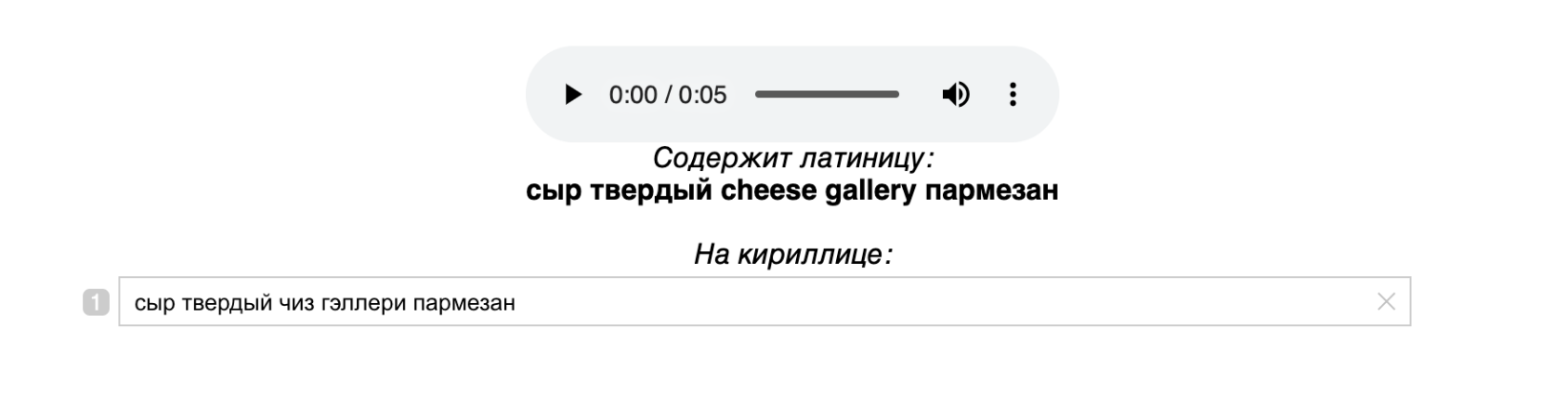
, . .
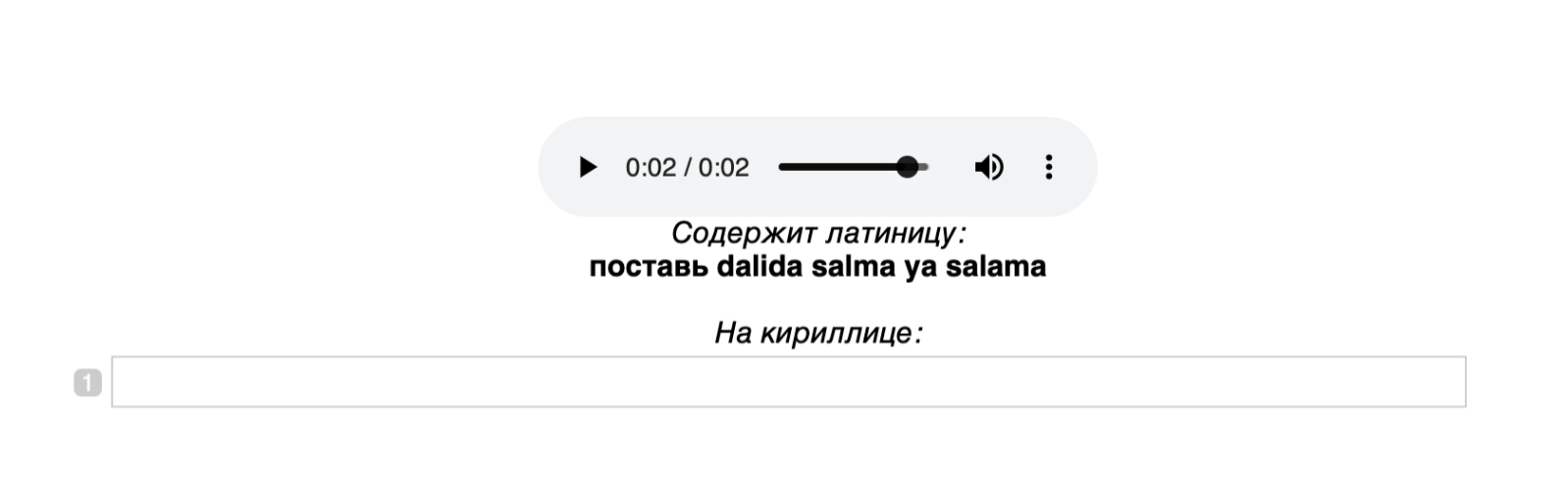
, , , .
- 5 . 3 , .
. -, , . -, . , .
, , “” – , “” - . , , , ( ) . bias , , . , . , .
El proceso descrito de creación de un conjunto de datos le permite hacer un marcado de la mayor calidad posible, lo que lo distingue de otros creados automáticamente o semiautomáticamente. Usamos estos datos para crear un sistema de reconocimiento de voz en nuestros dispositivos. Debido a la alta calidad de las marcas, la precisión del sistema resultante es comparable a la de un humano. Todos los datos, junto con los modelos acústicos y de lenguaje entrenados para el reconocimiento de voz, están disponibles en la página de GitHub del proyecto , así como en ML Space de Sbercloud , un servicio para entrenar modelos de aprendizaje automático, donde nuestro conjunto de datos se puede descargar sin problemas directamente en la interfaz. . Te contaremos más sobre el uso de ML Space y cómo lo usamos para enseñar modelos de reconocimiento de voz en el próximo artículo.
Actualmente, hay una gran cantidad de datos abiertos en inglés, pero no existía un conjunto de datos en ruso de alta calidad. Ahora también está disponible un corpus en ruso, que se puede utilizar para reconocimiento y síntesis de voz, y el modelo entrenado en ellos muestra una calidad muy alta. Creemos que el conjunto de datos de Golos permitirá a la comunidad científica rusa avanzar aún más rápido en la mejora de las tecnologías del habla en ruso.