Ahora los programadores se enfrentan a una tarea difícil: ¿cómo implementar una estructura tan engorrosa como una red neuronal, en, digamos, un brazalete? ¿Cómo optimizar el consumo de energía del modelo? ¿Cuál es el precio de dicha optimización, así como qué tan justificada está la introducción de modelos en dispositivos pequeños y por qué es imposible prescindir de ella?

¿Y para qué sirve?
Imaginemos un sensor industrial caro: 1000 mediciones por segundo, un sensor de temperatura, medición de vibraciones, transmisión de datos a más de 10 km, un procesador potente: ¡20 millones de operaciones por segundo! Su trabajo es enviar datos sobre temperatura, vibración, así como los valores de otros parámetros al servidor para evitar averías en los equipos. Pero aquí está la mala suerte: el 99% de los datos enviados por él son inútiles, por eso, una pérdida neta de electricidad. Y puede haber decenas y cientos de sensores de este tipo en producción.
, - ? ? , ? , " " " !" TinyML.

, , . "" : , , , , ..

- - . , , WiFi, Bluetooth .
- - . - , " ".
- - . , . , , ... . , ( - TinyML).
- - . - , , .
- - , int , float - .
Quantization
, . - , . , 32 . , 8 ? , .

- 1 . . , .

, , . , .
#
x_values = np.random.uniform(
low=0, high=2*math.pi, size=1000).astype(np.float32)
#
np.random.shuffle(x_values)
y_values = np.sin(x_values).astype(np.float32)
# , " "
y_values += 0.1 * np.random.randn(*y_values.shape)
plt.plot(x_values, y_values, 'b.')
plt.show()


!
#
model = tf.keras.Sequential()
model.add(keras.layers.Dense(16, activation='relu', input_shape=(1,)))
model.add(keras.layers.Dense(16, activation='relu'))
model.add(keras.layers.Dense(1))
model.compile(optimizer='adam', loss="mse", metrics=["mae"])
#
history = model.fit(x_train, y_train, epochs=500, batch_size=64,
validation_data=(x_validate, y_validate))
#
model.save(MODEL_TF)
, :

, . "" . TFLiteConverter, .
# TensorFlow Lite
converter = tf.lite.TFLiteConverter.from_saved_model(MODEL_TF)
model_no_quant_tflite = converter.convert()
#
open(MODEL_NO_QUANT_TFLITE, "wb").write(model_no_quant_tflite)
# TensorFlow Lite
def representative_dataset():
for i in range(500):
yield([x_train[i].reshape(1, 1)])
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# , int
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
# ,
converter.representative_dataset = representative_dataset
model_tflite = converter.convert()
open(MODEL_TFLITE, "wb").write(model_tflite)
: , TensorFlow Lite , TensorFlow Lite . , .
pd.DataFrame.from_records(
[["TensorFlow", f"{size_tf} bytes", ""],
["TensorFlow Lite", f"{size_no_quant_tflite} bytes ", f"(reduced by {size_tf - size_no_quant_tflite} bytes)"],
["TensorFlow Lite Quantized", f"{size_tflite} bytes", f"(reduced by {size_no_quant_tflite - size_tflite} bytes)"]],
columns = ["Model", "Size", ""], index="Model")
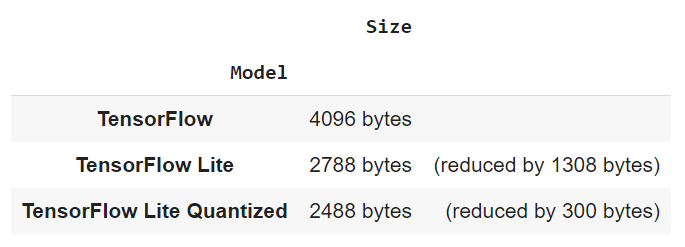
, , TensorFlow Lite 32% , 40% ! , , ?
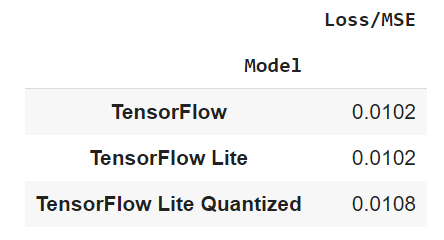
, . , , !
Python , , , ? , . ! Ubuntu, Windows - .
# xxd
!apt-get update && apt-get -qq install xxd
#
!xxd -i {MODEL_TFLITE} > {MODEL_TFLITE_MICRO}
#
REPLACE_TEXT = MODEL_TFLITE.replace('/', '_').replace('.', '_')
!sed -i 's/'{REPLACE_TEXT}'/g_model/g' {MODEL_TFLITE_MICRO}
# , C
!cat {MODEL_TFLITE_MICRO}

, 400.
// ,
float x = 0.0f;
float y_true = sin(x);
//
tflite::MicroErrorReporter micro_error_reporter;
//
const tflite::Model* model = ::tflite::GetModel(g_model);
. ? , : , . - , . , .
, :
x = 5.f;
y_true = sin(x);
input->data.int8[0] = x / input_scale + input_zero_point;
interpreter.Invoke();
y_pred = (output->data.int8[0] - output_zero_point) * output_scale;
TF_LITE_MICRO_EXPECT_NEAR(y_true, y_pred, epsilon);
Edge Impulse
Edge Impulse , TinyML.

, , . , , , - .
- TinyML . ( , ..) . 20% , , .
, NoML Community - https://t.me/noml_community.