
!
, Head of AI Celsus. .
, , ML- . «» — , , .
ML- DS-, , CV .
Entonces, suponga que decide fundar una empresa de IA para detectar el cáncer de mama (por cierto, el tipo de oncología más común entre las mujeres) y va a crear un sistema que detectará con precisión los signos de patología en los exámenes de mamografía, asegure doctor contra errores, y reducir el tiempo para hacer un diagnóstico ... Una misión brillante, ¿no?

Ha reunido un equipo de programadores talentosos, ingenieros de ML y analistas, compró equipos costosos, alquiló una oficina y pensó en una estrategia de marketing. ¡Todo parece estar listo para empezar a cambiar el mundo para mejor! Por desgracia, no todo es tan simple, porque se olvidó de lo más importante: los datos. Sin ellos, no puede entrenar una red neuronal u otro modelo de aprendizaje automático.
Aquí es donde radica uno de los principales obstáculos: la cantidad y calidad de los conjuntos de datos disponibles. Desafortunadamente, en el campo de la medicina diagnóstica, todavía hay muy pocos conjuntos de datos completos, verificados y de alta calidad, e incluso menos de ellos están disponibles públicamente para investigadores y empresas de inteligencia artificial.
Considere la situación usando el mismo ejemplo de detección de cáncer de mama. Los conjuntos de datos públicos de mayor o menor calidad se pueden contar con los dedos de una mano: DDSM (alrededor de 2600 casos), InBreast (115), MIAS (161). También hay OPTIMAM y BCDR con un procedimiento bastante complicado y confuso para obtener acceso.
E incluso si pudiera recopilar una cantidad suficiente de datos públicos, el siguiente obstáculo lo espera: casi todos estos conjuntos de datos pueden usarse solo con fines no comerciales. Además, el marcado en ellos puede ser completamente diferente, y no es un hecho que sea adecuado para su tarea. En general, sin recopilar sus propios conjuntos de datos y su marcado, será posible hacer solo un MVP, pero no un producto de alta calidad, listo para operar en condiciones de combate.
Entonces, envió solicitudes a instituciones médicas, reunió todas sus conexiones y contactos y recibió una colección variada de varias imágenes en sus manos. ¡No te regocijes antes de tiempo, estás al comienzo del camino! De hecho, a pesar de la presencia de un estándar unificado para almacenar imágenes médicas, DICOM(Imagen digital y comunicaciones en medicina), en la vida real no todo es tan color de rosa. Por ejemplo, la información sobre el lado (izquierda / derecha) y la proyección ( CC / MLO ) de una imagen de mama se puede almacenar en diferentes fuentes de datos en campos completamente diferentes. La única solución aquí es recopilar datos de tantas fuentes como sea posible e intentar tener en cuenta todas las opciones posibles en la lógica del servicio.
Lo que marca es lo que cosecha
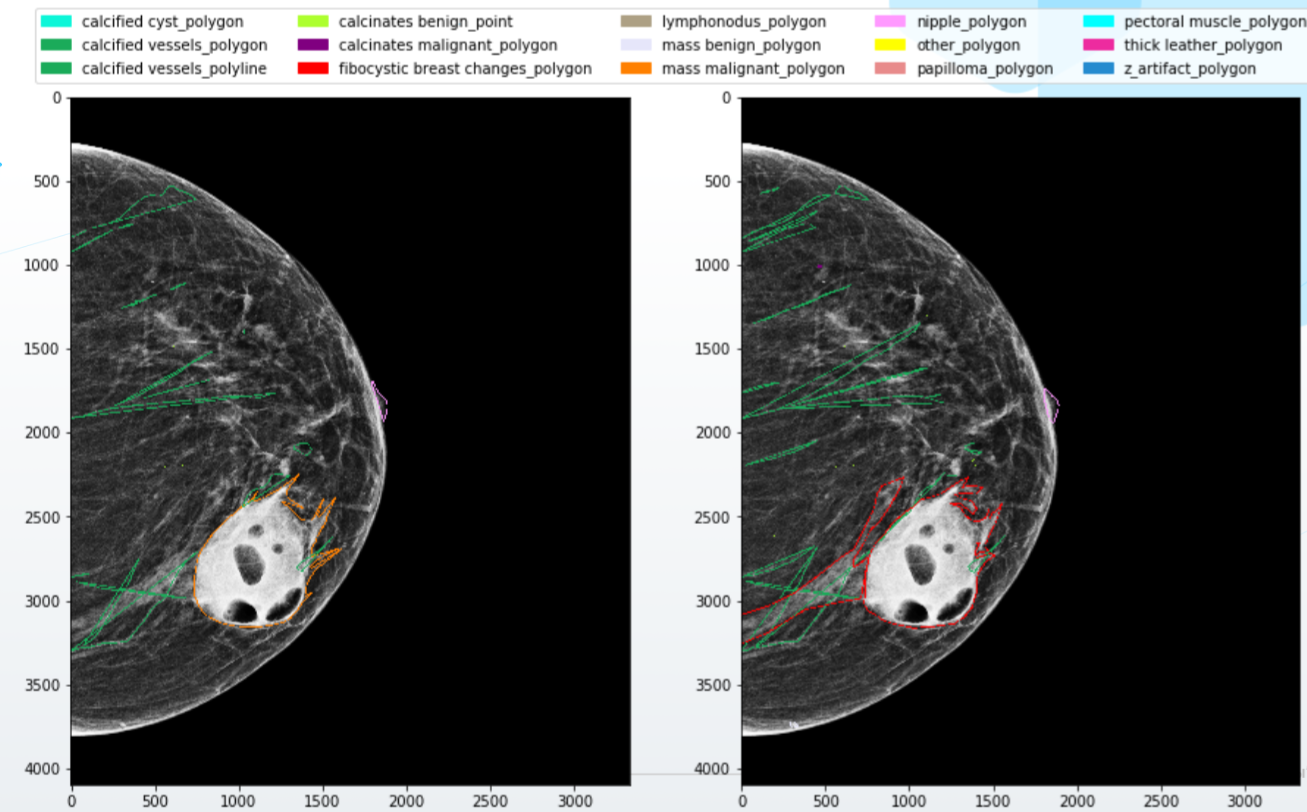
Finalmente llegamos a la parte divertida: el proceso de marcado de datos. ¿Qué lo hace tan especial e inolvidable en el campo de la medicina? En primer lugar, el proceso de marcado en sí es mucho más complicado y más largo que en la mayoría de las industrias. Los rayos X no se pueden cargar en Yandex.Toloka y puede obtener un conjunto de datos etiquetado por un centavo. Esto requiere un trabajo minucioso de especialistas médicos, y es aconsejable entregar cada imagen para que la marquen a varios médicos, y esto es costoso y requiere mucho tiempo.
Y lo que es peor: los expertos a menudo no están de acuerdo y dan marcas completamente diferentes de las mismas imágenes en la salida. Los médicos tienen diferentes calificaciones, educación, nivel de "sospecha". Alguien marca cuidadosamente todos los objetos en la imagen a lo largo del contorno, y alguien, con marcos anchos. Finalmente, uno de ellos está lleno de energía y entusiasmo, mientras que otro está marcando imágenes en una pequeña pantalla de computadora portátil después de un turno de veinte horas. Todas estas discrepancias, naturalmente, "vuelven locas" a las redes neuronales, y no obtendrá un modelo de alta calidad en tales condiciones.
La situación tampoco mejora por el hecho de que la mayoría de los errores y discrepancias ocurren precisamente en los casos más complejos, los más valiosos para entrenar neuronas. Por ejemplo, investigamuestran que la mayoría de los errores que cometen los médicos al hacer un diagnóstico en mamografías con una mayor densidad de tejido mamario, por lo que no es sorprendente que también sean los más difíciles para los sistemas de IA.
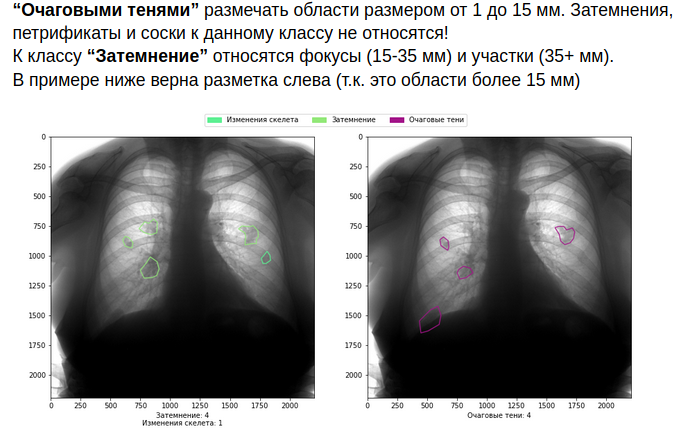
¿Qué hacer? Por supuesto, en primer lugar, debe crear un sistema de interacción de alta calidad con los médicos. Escriba reglas detalladas para el marcado, con ejemplos y visualizaciones, proporcione a los especialistas software y equipos de alta calidad, escriba la lógica para combinar conflictos menores en el marcado y solicite una opinión adicional en caso de conflictos más serios.
Como puede imaginar, todo esto aumenta el costo del margen de beneficio. Pero si no está listo para asumirlos, es mejor no entrar en el campo de la medicina.
Por supuesto, si aborda el proceso de manera inteligente, los costos pueden y deben reducirse, por ejemplo, a través del aprendizaje activo. En este caso, el propio sistema ML indica a los médicos qué imágenes deben marcarse adicionalmente para maximizar la calidad del reconocimiento de la patología. Hay diferentes formas de evaluar la confianza de un modelo en sus predicciones: pérdida de aprendizaje, aprendizaje activo discriminativo, abandono de MC, entropía de probabilidades predichas, rama de confianza y muchas otras. Cuál es mejor para usar, solo se mostrarán los experimentos en sus modelos y conjuntos de datos.
Finalmente, puede abandonar por completo el marcado de los médicos y confiar solo en los resultados finales confirmados, por ejemplo, la muerte o la recuperación del paciente. Quizás este sea el mejor enfoque (aunque hay muchos matices aquí), pero solo puede comenzar a funcionar en diez o quince años, en el mejor de los casos, cuando los PACS (sistemas de comunicación y archivo de imágenes) completos y los sistemas de información médica (MIS) ) y cuando se hayan acumulado suficientes datos. Pero incluso en este caso, nadie garantiza la pureza y calidad de estos datos.
Buen modelo - buen preprocesamiento

¡Hurra! El modelo ha sido entrenado, muestra excelentes resultados y está listo para ser probado. Se firmaron convenios de cooperación con varias organizaciones médicas, se instaló y configuró el sistema, se realizó una demostración a los médicos y se mostraron las capacidades del sistema.
Y ahora que terminó el primer día de operación del sistema, abres el tablero con métricas con el corazón hundido ... Y ves la siguiente imagen: un montón de solicitudes al sistema, con cero objetos detectados por el sistema y, de Por supuesto, una reacción negativa de los médicos. ¿Cómo es eso? Después de todo, ¡el sistema demostró ser excelente en pruebas internas!
Tras un análisis más detallado, resulta que en esta institución médica hay algún tipo de máquina de rayos X que no conoce con su propia configuración y, como resultado, las imágenes se ven completamente diferentes. La red neuronal no se entrenó con este tipo de imágenes, por lo que no es de extrañar que "falle" en ellas y no detecte nada. En el mundo del aprendizaje automático, estos casos se conocen comúnmente como datos fuera de distribución. Los modelos suelen tener un rendimiento significativamente peor con estos datos, y este es uno de los principales problemas del aprendizaje automático.
Ejemplo ilustrativo: nuestro equipo probó un modelo públicode investigadores de la Universidad de Nueva York, capacitados en un millón de imágenes. Los autores del artículo argumentan que el modelo demostró una alta calidad de detección de oncología en mamografías, y específicamente hablan de la tasa de precisión ROC-AUC en la región de 0,88-0,89. En nuestros datos, el mismo modelo demuestra resultados significativamente peores, de 0,65 a 0,70, según el conjunto de datos.
La solución más simple a este problema en la superficie es recopilar todos los tipos posibles de imágenes, de todos los dispositivos, con todas las configuraciones, marcarlas y entrenar al sistema en ellas. ¿Desventajas? De nuevo, largo y caro. En algunos casos, puede prescindir del marcado: el aprendizaje no supervisado vendrá en su ayuda. Las imágenes no etiquetadas se entregan a la neurona de cierta manera, y el modelo "se acostumbra" a sus características, lo que le permite detectar con éxito objetos en imágenes similares en el futuro. Esto se puede hacer, por ejemplo, utilizando pseudo-marcado de imágenes sin etiquetar o varias tareas auxiliares.
Sin embargo, esto tampoco es una panacea. Además, este método requiere que recolectes todo tipo de imágenes existentes en el mundo, lo que, en principio, parece una tarea imposible. Y la mejor solución aquí sería utilizar el preprocesamiento universal.
El preprocesamiento es un algoritmo para procesar datos de entrada antes de introducirlos en una red neuronal. Este procedimiento puede incluir cambios automáticos de contraste y brillo, varias normalizaciones estadísticas y eliminación de partes innecesarias de la imagen (artefactos).
Por ejemplo, después de muchos experimentos, nuestro equipo logró crear un preprocesamiento universal para imágenes de rayos X de la glándula mamaria, que trae casi todas las imágenes de entrada a una forma uniforme, lo que permite que la red neuronal las procese correctamente.

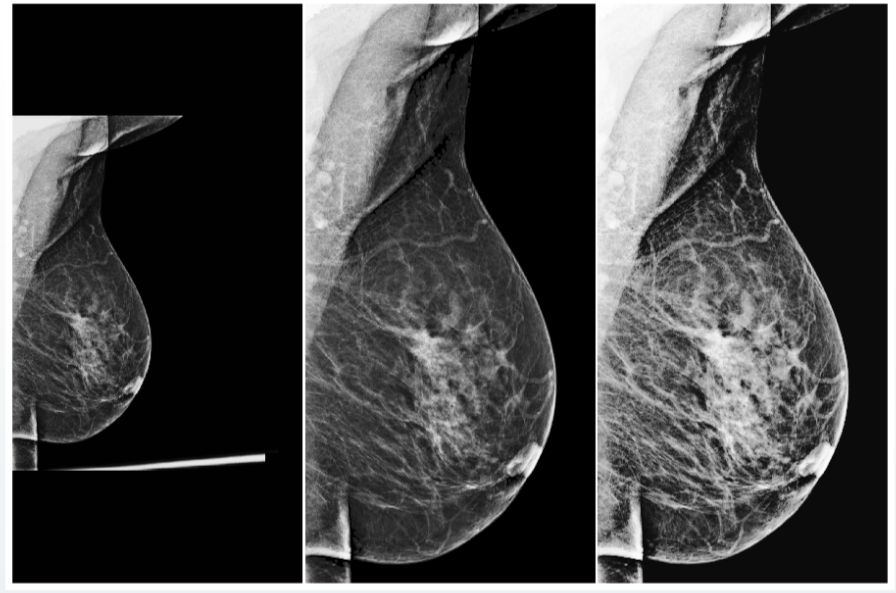
Pero incluso con el preprocesamiento universal, no debe olvidarse de las comprobaciones de calidad de los datos de entrada. Por ejemplo, en conjuntos de datos fluorográficos, a menudo encontramos imágenes de prueba, que incluían bolsas, botellas y otros objetos. Si el sistema asigna alguna probabilidad de presencia de patología en dicha imagen, esto claramente no aumenta la confianza de la comunidad médica en su modelo. Para evitar tales problemas, los sistemas de IA también deben señalar su confianza en las predicciones correctas y en la validez de los datos de entrada.

El hardware diferente no es el único problema con la capacidad de los sistemas de IA para generalizar, generalizar y trabajar con nuevos datos. Un parámetro muy importante son las características demográficas del conjunto de datos. Por ejemplo, si su muestra de formación está dominada por rusos mayores de 60 años, nadie puede garantizar que el modelo funcionará correctamente en jóvenes asiáticos. Es imperativo monitorear la similitud de los indicadores estadísticos de la muestra de capacitación y la población real para la cual se utilizará el sistema.
Si se encuentran discrepancias, es imperativo realizar pruebas y, muy probablemente, capacitación adicional o ajuste fino del modelo. Es imperativo realizar un seguimiento constante y una revisión periódica del sistema. En el mundo real pueden pasar un millón de cosas: se ha sustituido la máquina de rayos X, ha llegado un nuevo ayudante de laboratorio que investiga de otra forma, multitudes de inmigrantes de otro país de repente inundaron la ciudad. Todo esto puede llevar a la degradación de la calidad de su sistema de inteligencia artificial.
Sin embargo, como habrás adivinado, aprender no lo es todo. El sistema debe evaluarse como mínimo y es posible que las métricas estándar no sean aplicables en el campo médico. Esto también dificulta la evaluación de los servicios de IA de la competencia. Pero este es el tema de la segunda parte del material, como siempre, basado en nuestra experiencia personal.