Muchos proyectos ahora usan arquitectura de microservicio. Tampoco somos una excepción, y durante más de 2 años hemos intentado crear RBS para entidades legales en un banco utilizando microservicios.

Autores del artículo: ctimas y Alexey_Salaev
La importancia de la arquitectura de microservicios
Nuestro proyecto es un RBS para personas jurídicas. Muchos procesos diferentes bajo el capó y una agradable interfaz minimalista. Pero no siempre fue así. Durante mucho tiempo utilizamos una solución de un contratista, pero un buen día se decidió desarrollar nuestro producto.
Al comenzar el proyecto, hubo muchas discusiones: ¿qué enfoque elegir? ¿Cómo construir nuestro nuevo sistema RBS? Todo comenzó con discusiones "monolito vs microservicios": discutió los posibles lenguajes de programación utilizados, discutió sobre los marcos ("¿debería usar Spring Cloud?", "¿Qué protocolo debo elegir para la comunicación entre microservicios?"). Estas preguntas, por regla general, tienen un número limitado de respuestas y simplemente elegimos enfoques y tecnologías específicos en función de las necesidades y capacidades. Y la respuesta a la pregunta "¿Cómo escribir microservicios por sí mismos?" no fue del todo sencillo.
Muchos podrían decir: “¿Por qué desarrollar un concepto de arquitectura general para el microservicio en sí? Existe una arquitectura empresarial y una arquitectura de proyecto, y un vector general de desarrollo. Si asigna una tarea al equipo, la completará, y se escribirá el microservicio y realizará sus tareas. Después de todo, esta es la esencia de los microservicios: la independencia ". ¡Y tendrán toda la razón! Pero con el tiempo, los equipos se vuelven más grandes, por lo tanto, la cantidad de microservicios y empleados está creciendo y hay menos veteranos. Llegan nuevos desarrolladores que necesitan sumergirse en el proyecto, algunos desarrolladores cambian de equipo. Además, los equipos dejan de existir con el tiempo, pero sus microservicios continúan vivos y, en algunos casos, deben mejorarse.
Mientras desarrollamos el concepto general de la arquitectura de microservicios, nos dejamos una gran reserva para el futuro:
- ;
- ;
- : .
Todos los que trabajan con microservicios conocen bien sus pros y sus contras, uno de los cuales es la capacidad de reemplazar rápidamente una implementación antigua por una nueva. Pero, ¿qué tan pequeño debe ser un microservicio para que pueda reemplazarse fácilmente? ¿Dónde está el límite que determina el tamaño del microservicio? ¿Cómo no hacer un mini monolito o un servicio nanservicio? Y siempre puede ir directamente al lado de las funciones que realizan una pequeña parte de la lógica y construir procesos de negocios construyendo el orden de llamada a tales funciones ...
Decidimos seleccionar microservicios por dominios comerciales (por ejemplo, el microservicio para pagos en rublos) y construyen los propios microservicios de acuerdo con las tareas de este dominio.
Consideremos un ejemplo de un proceso comercial estándar para cualquier banco: "crear una orden de pago".

Puede ver que una solicitud de cliente aparentemente simple es un conjunto bastante grande de operaciones. Este escenario es aproximado, se omiten algunas etapas por simplicidad, algunas de las etapas ocurren a nivel de componentes de infraestructura y no llegan a la lógica principal del negocio en el producto servicio, la otra parte de las operaciones funciona de forma asincrónica. La conclusión es que tenemos un proceso que en un momento dado puede usar muchos servicios vecinos, usar la funcionalidad de diferentes bibliotecas, implementar algún tipo de lógica dentro de sí mismo y guardar datos en varios almacenamientos.
Mirando más de cerca, puede ver que el proceso de negocio es bastante lineal y en el curso de su trabajo necesitará obtener algunos datos en algún lugar o de alguna manera procesar los datos que tiene, y esto puede requerir trabajar con fuentes de datos externas ( microservicios, bases de datos) o lógica (bibliotecas).

Algunos microservicios no se ajustan a este concepto, pero la cantidad de tales microservicios en el porcentaje general es pequeña y asciende a aproximadamente el 5%.
Arquitectura limpia
Después de analizar diferentes enfoques para organizar el código, decidimos probar un enfoque de "arquitectura limpia" organizando el código en nuestros microservicios como capas.
En cuanto a la "arquitectura limpia" en sí, se ha escrito más de un libro, hay muchos artículos tanto en Internet como en Habré ( artículo 1 , artículo 2 ), más de una vez se han discutido sus pros y contras.
Bob Martin dibujó un diagrama popular que se puede encontrar sobre este tema en su libro Arquitectura limpia:

aquí, el gráfico circular de la izquierda en el centro muestra la dirección de las dependencias entre capas, y modestamente en la esquina derecha se puede ver la dirección del flujo de ejecución.
Este enfoque, como, de hecho, en cualquier tecnología de programación, tiene sus pros y sus contras. Pero para nosotros hay muchos más aspectos positivos que negativos al utilizar este enfoque.
Implementación de "arquitectura limpia" en el proyecto
Hemos vuelto a dibujar este diagrama en función de nuestro escenario.
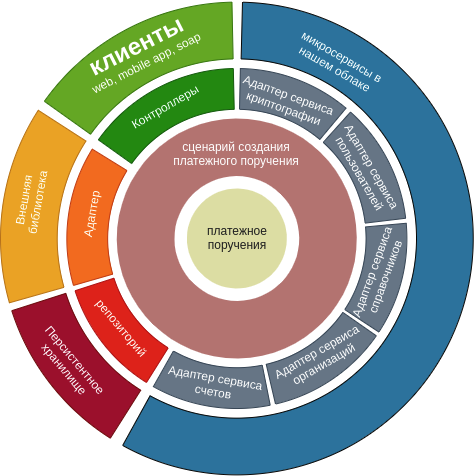
Naturalmente, este diagrama refleja un escenario. A menudo sucede que un microservicio realiza más operaciones en una entidad de dominio, pero, para ser justos, se pueden reutilizar muchos adaptadores.
Se pueden usar diferentes enfoques para separar el microservicio en capas, pero elegimos la división en módulos al nivel del constructor del proyecto. La implementación a nivel de módulo proporciona una percepción visual más fácil del proyecto y también proporciona otra capa de protección para los proyectos contra el uso indebido del estilo arquitectónico.
Por experiencia, notamos que cuando se sumerge en un proyecto, un nuevo desarrollador solo necesita familiarizarse con la parte teórica y puede navegar fácil y rápidamente en casi cualquier microservicio.
Usamos Gradle para construir nuestros microservicios en Java, por lo que las capas principales se forman como un conjunto de sus módulos:

Ahora nuestro proyecto consta de módulos que implementan contratos o los utilizan. Para que estos módulos comiencen a funcionar y a resolver problemas, necesitamos implementar la inyección de dependencias y crear un punto de entrada que lanzará toda nuestra aplicación. Y aquí hay una pregunta interesante en el libro del tío Bob "Arquitectura pura", hay capítulos enteros que nos hablan de los detalles, modelos y frameworks, pero no construimos su arquitectura alrededor del framework o alrededor de la base de datos, los usamos como uno de los componentes ...
Cuando necesitamos guardar la entidad, nos referimos a la base de datos, por ejemplo, para que nuestro script reciba las implementaciones del contrato que necesita en el momento de la ejecución, usamos el framework que da nuestro arquitectura DI.
Hay tareas en las que necesitamos implementar un microservicio sin una base de datos, o podemos abandonar DI, porque la tarea es demasiado simple y es más rápido resolverlo de frente. Y si vamos a realizar todo el trabajo con la base de datos en el módulo "repositorio", entonces, ¿dónde usamos el framework para preparar todo el DI para nosotros? No hay tantas opciones: o agregamos una dependencia a cada módulo de nuestra aplicación, o intentaremos seleccionar la DI completa como un módulo separado.
Elegimos un nuevo enfoque de módulo por separado y lo llamamos "infraestructura" o "aplicación".
Es cierto que cuando se introduce un módulo de este tipo, el principio se viola ligeramente, según el cual dirigimos todas las dependencias al centro de la capa de dominio, ya que debe tener acceso a todas las clases de la aplicación.
No funcionará agregar una capa de infraestructura a nuestra cebolla en forma de capa, simplemente no hay lugar para ella allí, pero aquí puedes mirar todo desde un ángulo diferente, y resulta que tenemos un círculo ”. Infraestructura ”y nuestra cebolla de hojaldre está en ella ... Para mayor claridad, intentemos separar un poco las capas para que sea mejor visible:

agregue un nuevo módulo y observe el árbol de dependencias en la capa de infraestructura para ver las dependencias finales entre los módulos:

Ahora todo lo que queda es agregar el DI marco en sí. Usamos Spring en nuestro proyecto, pero esto no es obligatorio, puede tomar cualquier marco que implemente DI (por ejemplo, micronauta).
Cómo construir un microservicio y dónde estará la parte del código, ya lo hemos decidido y vale la pena volver a analizar el escenario empresarial, porque hay otro punto interesante.
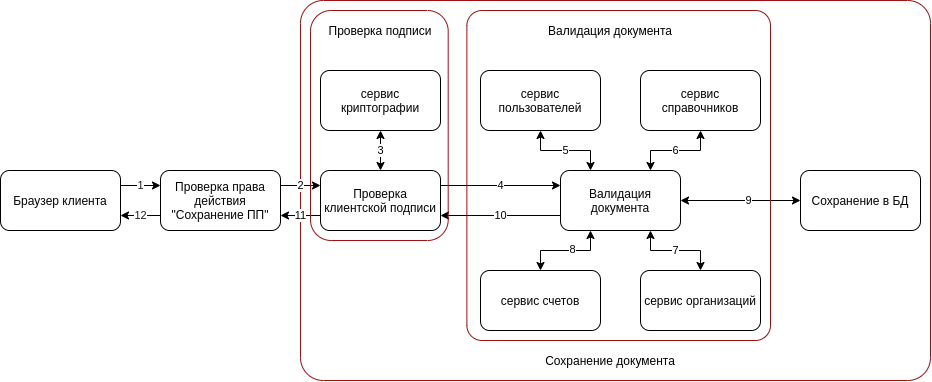
El diagrama muestra que es posible que la verificación del derecho de acción no se realice en el script principal. Esta es una tarea separada que no depende de lo que suceda a continuación. La verificación de firmas podría trasladarse a un microservicio separado, pero aquí hay muchas contradicciones al definir el límite del microservicio, y decidimos simplemente agregar otra capa a nuestra arquitectura.
En capas separadas, es necesario resaltar las etapas que se pueden repetir en nuestra aplicación, por ejemplo, verificación de firma. Este procedimiento puede ocurrir al crear, cambiar o firmar un documento. Muchos scripts principales inician las operaciones más pequeñas primero y luego solo el script principal. Por lo tanto, es más fácil para nosotros aislar operaciones más pequeñas en pequeños scripts, divididos en capas para que puedan reutilizarse más convenientemente.
Este enfoque hace que la lógica empresarial sea más fácil de entender y, con el tiempo, se formará un conjunto de bloques de construcción de pequeñas empresas que se pueden reutilizar.
No hay mucho que decir sobre el código de adaptadores, controladores y repositorios. son bastante simples. Los adaptadores para otro microservicio usan un cliente generado a partir de un swagger, un Spring RestTemplate o un cliente Grpc. En repositorios: una de las variaciones del uso de Hibernate u otros ORM. Los controladores obedecerán la biblioteca que utilizará.
Conclusión
En este artículo, queríamos mostrar por qué estamos construyendo una arquitectura de microservicio, qué enfoques usamos y cómo nos desarrollamos. Nuestro proyecto es joven y está apenas al comienzo de su andadura, pero ya ahora podemos destacar los principales puntos de su desarrollo desde el punto de vista de la arquitectura del propio microservicio.
Estamos construyendo microservicios de módulos múltiples, donde las ventajas incluyen:
- , - , , - , ;
- , , - ;
- , Api, , , , ;
- , , , , .
No sin, por supuesto, una mosca en el ungüento. Por ejemplo, lo más obvio es que a menudo cada módulo trabaja con sus propios modelos pequeños. Por ejemplo, en el controlador tendrás una descripción del resto de modelos, y en el repositorio habrá entidades de base de datos. En este sentido, es necesario mapear mucho los objetos entre sí, pero herramientas como “maptruct” le permiten hacerlo de manera rápida y confiable.
Además, las desventajas incluyen el hecho de que necesita monitorear constantemente a otros desarrolladores, porque existe la tentación de hacer menos trabajo de lo que cuesta. Por ejemplo, mover el marco un poco más allá de un módulo, pero esto conduce a la erosión de la responsabilidad de este marco en toda la arquitectura, lo que en el futuro puede afectar negativamente la velocidad de las mejoras.
Este enfoque para implementar microservicios es adecuado para proyectos con una vida útil prolongada y proyectos con comportamiento complejo. Dado que la implementación de toda la infraestructura lleva tiempo, en el futuro vale la pena con estabilidad y mejoras rápidas.