Introducción
Mi trabajo principal es la publicidad móvil y, de vez en cuando, tengo que trabajar con datos sobre aplicaciones móviles. Decidí poner algunos de los datos a disposición del público para aquellos que quieran practicar la construcción de modelos o tener una idea de los datos que se pueden recopilar de fuentes abiertas. Creo que los conjuntos de datos abiertos siempre son útiles para la comunidad. La recopilación de datos suele ser un trabajo difícil y aburrido, y no todo el mundo tiene la oportunidad de hacerlo. En este artículo, presentaré un conjunto de datos y lo usaré para construir un modelo.
Datos
El conjunto de datos se publica en el sitio web de Kaggle .
DOI: 10.34740/KAGGLE/DSV/2107675.
Para 293,392 aplicaciones (las más populares), se recopilan los tokens de descripción y los datos de la aplicación, incluida la descripción original. No hay nombres de aplicaciones en el conjunto de datos; se identifican mediante identificadores únicos. Antes de la tokenización, la mayoría de las descripciones se tradujeron al inglés.
Hay 4 archivos en el conjunto de datos:
bundles_desc.csv: contiene solo descripciones;
bundles_desc_tokens.csv: contiene tokens y géneros;
bundles_prop.csv, bundles_summary.csv : contienen varias características de la aplicación y fechas de lanzamiento / actualización.
EDA
En primer lugar, echemos un vistazo a cómo se distribuyen los datos en los sistemas operativos.

Las aplicaciones de Android dominan los datos. Lo más probable es que esto se deba al hecho de que se están creando más aplicaciones de Android.
, , , .
histnorm ='probability' # type of normalization

, .

2021 .

- .
df['bundle_update_period'] = \
(pd.to_datetime(
df['bundle_updated_at'], utc=True).dt.tz_convert(None).dt.to_period('M').astype('int') -
df['bundle_released_at'].dt.to_period('M').astype('int'))

, . , .
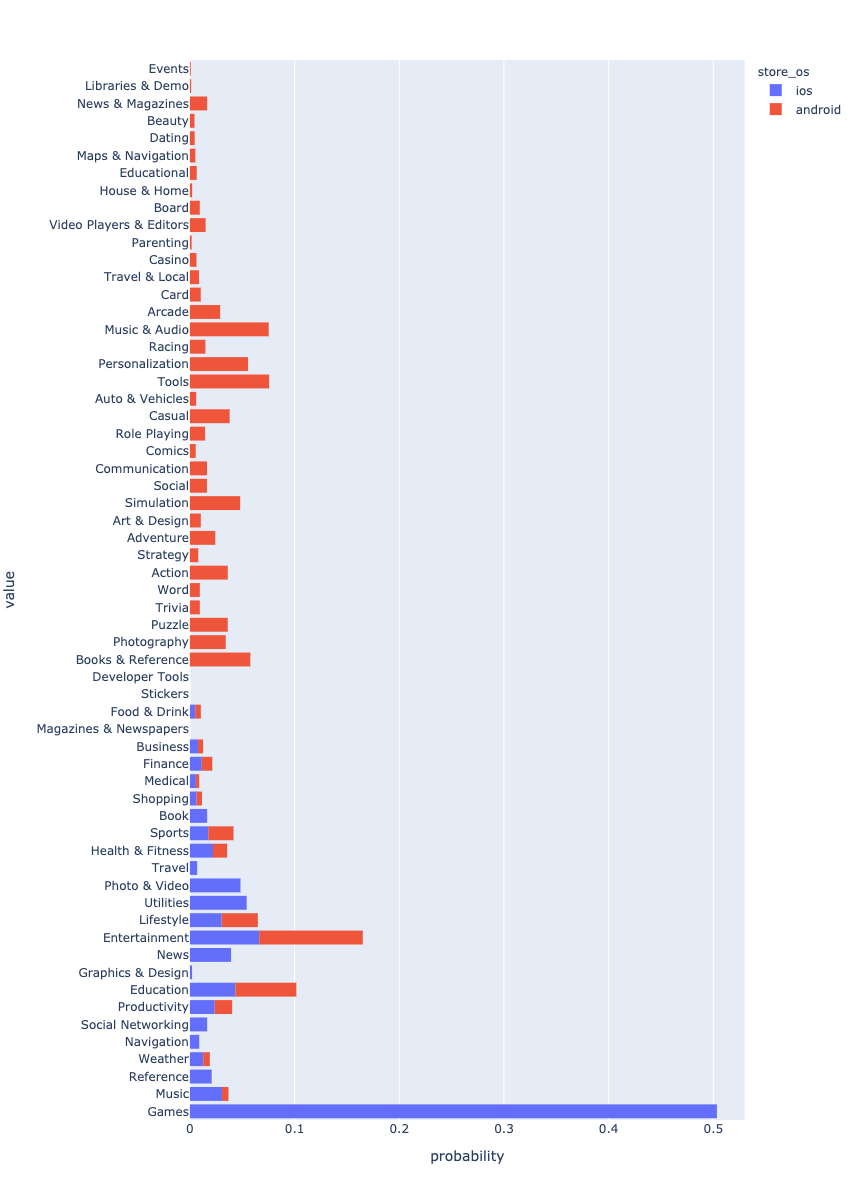
, . . . ? - Android , iOS Games. , , . . , .
, .
def get_lengths(df, columns=['tokens', 'description']):
lengths_df = pd.DataFrame()
for i, c in enumerate(columns):
lengths_df[f"{c}_len"] = df[c].apply(len)
if i > 0:
lengths_df[f"{c}_div"] = \
lengths_df.iloc[:, i-1] / lengths_df.iloc[:, i]
lengths_df[f"{c}_diff"] = \
lengths_df.iloc[:, i-1] - lengths_df.iloc[:, i]
return lengths_df
df = pd.concat([df, get_lengths(df)], axis=1, sort=False, copy=False)
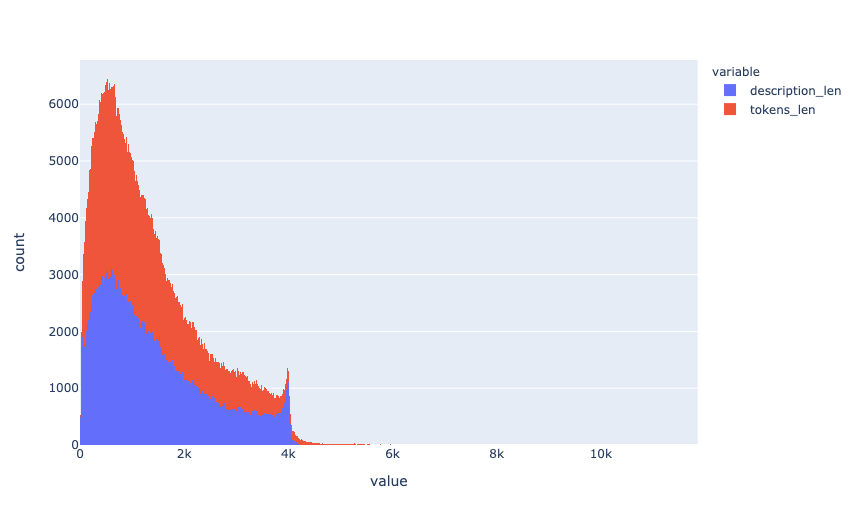
, . , - .

Android-.
android_df = df[df['store_os']=='android']
ios_df = df[df['store_os']=='ios']
:
columns = [
'genre', 'tokens', 'bundle_update_period', 'tokens_len',
'description_len', 'description_div', 'description_diff',
'description', 'rating', 'reviews', 'score',
'released_at_month'
]
- train validation. , .
train_df, test_df = train_test_split(
android_df[columns], train_size=0.7, random_state=0, stratify=android_df['genre'])
y_train, X_train = train_df['genre'], train_df.drop(['genre'], axis=1)
y_test, X_test = test_df['genre'], test_df.drop(['genre'], axis=1)
CatBoost. CatBoost - . , CatBoost . 0.19.1
: BERT vs CatBoost , CatBoost BERT.
!pip install -U catboost
CatBoost Pool. , , . , .
train_pool = Pool(
data=X_train,
label=y_train,
text_features=['tokens', 'description']
)
test_pool = Pool(
data=X_test,
label=y_test,
text_features=['tokens', 'description']
)
. ; .
def fit_model(train_pool, test_pool, **kwargs):
model = CatBoostClassifier(
random_seed=0,
task_type='GPU',
iterations=10000,
learning_rate=0.1,
eval_metric='Accuracy',
od_type='Iter',
od_wait=500,
**kwargs
)
return model.fit(
train_pool,
eval_set=test_pool,
verbose=1000,
plot=True,
use_best_model=True
)
. CatBoost, .
CatBoostClassifier :
tokenizers — ;
dictionaries — ;
feature_calcers — ;
text_processing — JSON- , , , .
, , , , .
tpo = {
'tokenizers': [
{
'tokenizer_id': 'Sense',
'separator_type': 'BySense',
}
],
'dictionaries': [
{
'dictionary_id': 'Word',
'token_level_type': 'Word',
'occurrence_lower_bound': '10'
},
{
'dictionary_id': 'Bigram',
'token_level_type': 'Word',
'gram_order': '2',
'occurrence_lower_bound': '10'
},
{
'dictionary_id': 'Trigram',
'token_level_type': 'Word',
'gram_order': '3',
'occurrence_lower_bound': '10'
},
],
'feature_processing': {
'0': [
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Word'],
'feature_calcers': ['BoW']
},
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Bigram', 'Trigram'],
'feature_calcers': ['BoW']
},
],
'1': [
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Word'],
'feature_calcers': ['BoW', 'BM25']
},
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Bigram', 'Trigram'],
'feature_calcers': ['BoW']
},
]
}
}
:
model_catboost = fit_model( train_pool, test_pool, text_processing = tpo )


bestTest = 0.6454657601
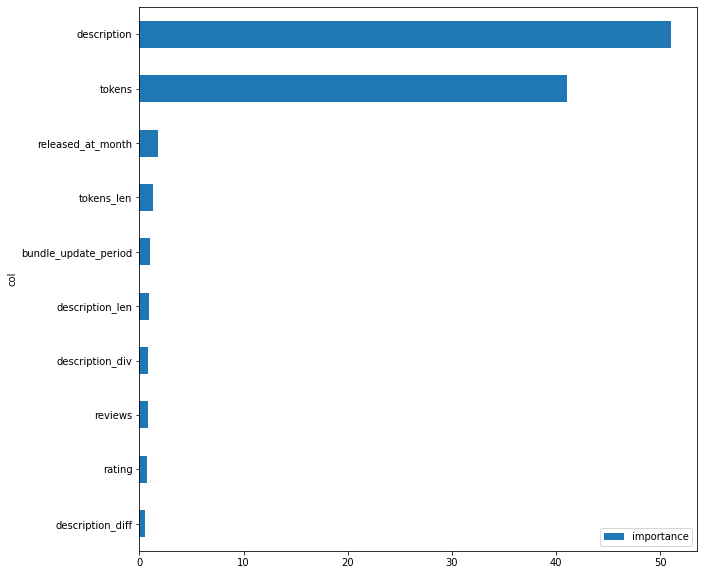
. , summary, , iOS, . , . .
, . , , . , . , .
, , OOF (Out-of-Fold). ; .
def get_oof(n_folds, x_train, y, x_test, text_features, seeds):
ntrain = x_train.shape[0]
ntest = x_test.shape[0]
oof_train = np.zeros((len(seeds), ntrain, 48))
oof_test = np.zeros((ntest, 48))
oof_test_skf = np.empty((len(seeds), n_folds, ntest, 48))
test_pool = Pool(data=x_test, text_features=text_features)
models = {}
for iseed, seed in enumerate(seeds):
kf = StratifiedKFold(
n_splits=n_folds,
shuffle=True,
random_state=seed)
for i, (tr_i, t_i) in enumerate(kf.split(x_train, y)):
print(f'\nSeed {seed}, Fold {i}')
x_tr = x_train.iloc[tr_i, :]
y_tr = y[tr_i]
x_te = x_train.iloc[t_i, :]
y_te = y[t_i]
train_pool = Pool(
data=x_tr, label=y_tr, text_features=text_features)
valid_pool = Pool(
data=x_te, label=y_te, text_features=text_features)
model = fit_model(
train_pool, valid_pool,
random_seed=seed,
text_processing = tpo
)
x_te_pool = Pool(
data=x_te, text_features=text_features)
oof_train[iseed, t_i, :] = \
model.predict_proba(x_te_pool)
oof_test_skf[iseed, i, :, :] = \
model.predict_proba(test_pool)
models[(seed, i)] = model
oof_test[:, :] = oof_test_skf.mean(axis=1).mean(axis=0)
oof_train = oof_train.mean(axis=0)
return oof_train, oof_test, models
, :
oof_train — OOF- Android
oof_test — OOF- iOS
models — all OOF-
from sklearn.metrics import accuracy_score
accuracy_score(
android_df['genre'].values,
np.take(models[(0,0)].classes_, oof_train.argmax(axis=1)))
.
OOF accuracy: 0.6560790777135628
android_genre_vec, oof_train Android oof_test iOS.
idx = df[df['store_os']=='ios'].index
df.loc[df['store_os']=='ios', 'android_genre_vec'] = \
pd.Series(list(oof_test), index=idx)
idx = df[df['store_os']=='android'].index
df.loc[df['store_os']=='android', 'android_genre_vec'] = \
pd.Series(list(oof_train), index=idx)
android_genre, .
df.loc[df['store_os']=='ios', 'android_genre'] = \
np.take(models[(0,0)].classes_, oof_test.argmax(axis=1))
df.loc[df['store_os']=='android', 'android_genre'] = \
np.take(models[(0,0)].classes_, oof_train.argmax(axis=1))
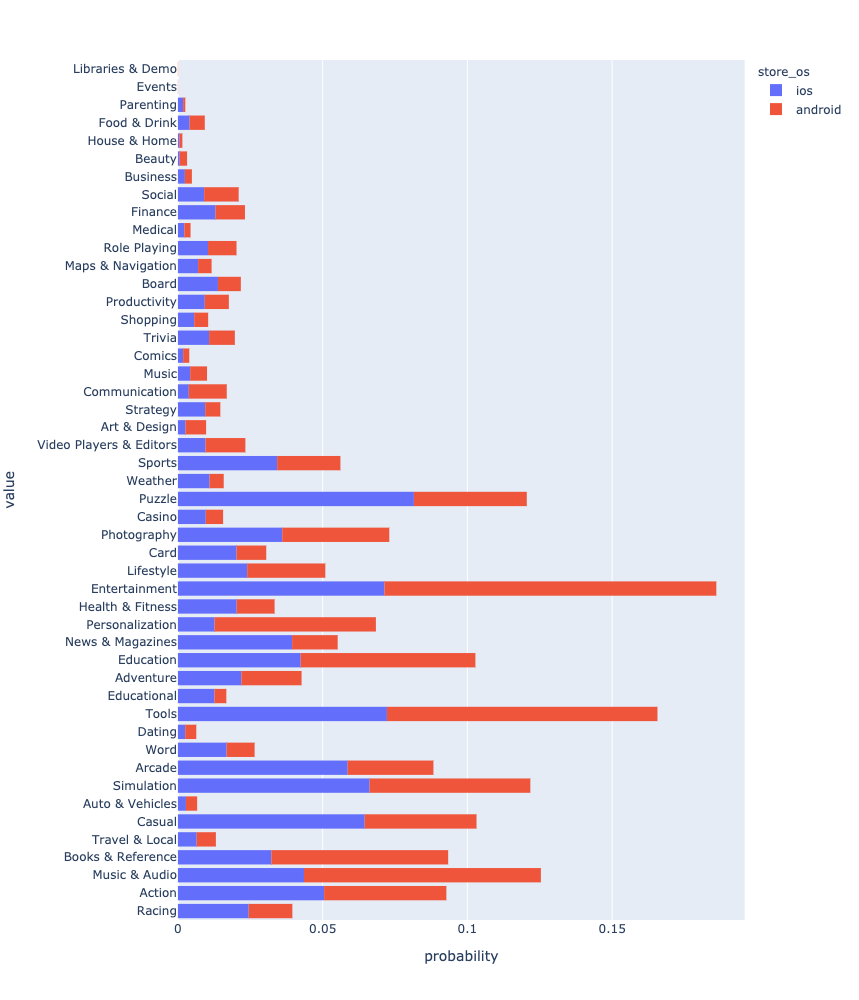
Después de todas las manipulaciones, finalmente puede ver y comparar la distribución de aplicaciones por género.
Resultados
En el artículo:
nuevo conjunto de datos gratuito introducido;
hizo una pequeña EDA;
se han creado varias funciones nuevas;
Se ha creado un modelo para predecir los géneros de aplicaciones a partir de descripciones.
Espero que este conjunto de datos sea útil para la comunidad y se utilice tanto en modelos como para estudios posteriores. En la medida de lo posible, intentaré actualizarlo.
El código del artículo se puede ver aquí .