
SberCraft, CyberCode, Luxcity: es posible que haya oído hablar de estos juegos o incluso haya participado en ellos. Todo esto es obra de Geecko. Los proyectos más grandes de Geecko reúnen a 20 mil jugadores cada uno, mientras que hasta hace poco la empresa no contaba con un equipo dedicado para respaldar la infraestructura.
La estación de servicio de la compañía, Nikita Obukhov, y la directora de marketing Irina Fedorova hablaron sobre el incidente, que se convirtió en uno de los argumentos para pensar seriamente en los cambios de infraestructura, mudarse a K8 y contratar un equipo de DevOps.
Que hay adentro:
- pérdida de control sobre Facebook,
- una avalancha repentina de tráfico el viernes por la noche,
- Beca de Microsoft Azure, Cloud Moving and Transformation Challenges.
¡Ir!
Geecko — DevRel . IT- , : , , -.
Geecko
¿En qué motor están hechos los juegos, en qué son técnicamente?
Nikita: Nuestros juegos se basan exclusivamente en el navegador. Utilizamos nuestros propios desarrollos y bibliotecas probadas para trabajar con Canvas, mapas, isometría. Usamos JS / TS, un marco Vue.js para una interfaz de usuario web típica.
Todavía no estamos escribiendo para plataformas móviles; en el mejor de los casos, admitimos permisos móviles. Pero esto no suele ser necesario: en la mayoría de nuestros juegos, es necesario escribir código, y escribir código desde un teléfono móvil es muy conveniente.
¿Qué tan exigentes son los juegos en CPU y memoria?
Nikita: En nuestros juegos, necesitamos escribir código y necesitamos ejecutar este código.
Admitimos 12 idiomas: tanto compilados como interpretados en diferentes entornos. Ejecutamos el código en los recursos de nuestro servidor: la carga en el procesador y la memoria es intensiva.
También ejecutamos servicios LSP que proporcionan código de autocompletado para nuestro IDE en línea. También requieren CPU y especialmente memoria: cuando hay muchos jugadores, la carga aumenta significativamente.
¿Dónde se alojan los juegos?
Nikita: Siempre fueron nubes. Ahora el principal proveedor es Azure (Geecko recibió una subvención de Microsoft para el uso gratuito de la nube). Lanzamos todos los proyectos nuevos allí y, lo que es importante para nosotros, los lanzamos en Kubernetes. Toda la nueva infraestructura se basa en Kubernetes y Docker.
¿Qué proveedor tenía antes y por qué decidió cambiarse?
Nikita: Hemos estado y seguimos estando representados en DigitalOcean y Yandex.Cloud. Son buenos proveedores, pero Microsoft resultó ser el programa de subvenciones más adecuado para nosotros.
¿Cuánto gastaste en servidores antes y ahora?
Nikita: Hace seis meses, gastamos unos 30 mil rublos al mes, ahora esta cifra se acerca a los 100 mil. El crecimiento está relacionado con la cantidad de proyectos: no paramos a los antiguos, siguen funcionando y reciben inscripciones orgánicas. Regularmente lanzamos nuevas actividades: en un mes podemos lanzar tres proyectos, por ejemplo, una batalla, un juego y una reunión.
¿Microsoft Grant cubre todos los costos?
Nikita: Nuestros costos de infraestructura no se han vuelto cero: no podemos transportar todo a la vez, esto no es económicamente viable. Por lo tanto, dos proveedores de nube más continúan trabajando con nosotros, su participación simplemente está disminuyendo.
Copias de seguridad en otras áreas geográficas, recuperación ante desastres de recursos en otra nube: todo esto es importante.
En general, se reducen los costos generales. El servicio de ejecución de código tiene el mayor consumo de recursos y, gracias a la subvención, sus costos en el próximo año serán cero. Si se cumplen varias condiciones, la subvención se extenderá por un segundo año.

Captura de pantalla del juego Cybercode
La avalancha de tráfico de Facebook del viernes
¿Ha tenido una situación en la que una afluencia de usuarios redujo la producción?
Nikita: Sí, una vez hubo un incidente cercano a este. Teníamos una tarea de una empresa internacional: encontrar muchos desarrolladores de habla inglesa.
Por diseño, los jugadores deben completar colectivamente la misión mientras se encuentran en el mismo mapa. El mapa tiene dimensiones finitas, por lo que es imposible ubicar a todos en él. Dividimos a los usuarios en grupos de 100 personas, cada una de las cuales no vive más de cinco días; este es el ciclo del juego para completar la misión. Durante este tiempo, los participantes ganan o pierden.
Esperábamos que hasta 10 tarjetas de este tipo estuvieran activas al mismo tiempo, es decir, hasta 1000 jugadores. Pero, de hecho, había más de 2000 jugadores o 20 cartas en la cima.
¿Por qué sucedió? ¿Por qué tantos usuarios vinieron repentinamente al juego?
Irina: La historia sucedió a principios de marzo, cuando Facebook comenzó a bloquear masiva y espontáneamente las cuentas de publicidad por inconsistencia con la política para los anunciantes. Luego, muchas empresas perdieron sus oficinas de publicidad, incluyéndonos a nosotros: nuestra oficina principal y ambas oficinas de respaldo cayeron. Y todo esto en el mismo momento en que teníamos que promocionar el juego.
Facebook es uno de los principales canales de promoción, porque es bastante fácil seleccionar una audiencia y segmentarla en función de los datos disponibles. Y durante 12 días enteros perdimos el acceso a este canal. Cuando lo devolvimos con sudor, sangre y lágrimas, tuvimos que ponernos al día con el KPI - 4500 registros líquidos para determinadas geolocalizaciones, principalmente en Europa.
No quedaba más remedio que impulsar el presupuesto: aceleramos nuestras campañas publicitarias.
¿Qué significa "presionar con el presupuesto"?
Irina: Si inicialmente gastamos 300-500 dólares por día, aquí pasamos de 1000.
Tienes que entender que generalmente las campañas publicitarias se entrenan durante varios días y luego comienzan a funcionar de la manera más rentable posible. Pero nuestro presupuesto publicitario era más grande de lo habitual, por lo que la campaña aprendió más rápido y el segundo día comenzó a generar indicadores realmente interesantes. En algún momento, perdimos el control de ella.
Contamos con una cierta tasa de conversión, pero resultó ser más simplemente debido al hecho de que Facebook hizo overclock. Si la tasa de conversión promedio en tales juegos es de alrededor del 8%, entonces en el momento pico alcanzó el 15%.
¡Fresco!
Irina: Sí, fue entonces cuando comprendimos lo que significa un gran presupuesto publicitario. Es cierto que esto solo funciona en el caso de Occidente: en Rusia simplemente no hay audiencia para gastar tanto dinero.
Y, por supuesto, todo sucedió el viernes. ¡Clásico! El viernes por la noche, recibí un mensaje de Nikita de que tenemos tanto tráfico que debemos hacer algo al respecto.
¿Cómo se enteró Nikita de esto? ¿De dónde vino esta señal?
Nikita: Tenemos notificaciones automáticas de carga del servidor. Así es como se veía:

Llega una alerta de que la máquina virtual (8 núcleos, 32 GB de memoria) está cargada en un 90% en la CPU en el valor umbral del 50%.
Esto no es crítico, ya que el servicio sigue funcionando. Para los jugadores, esto significa que presionan el botón "Ejecutar código" y esperan el doble de tiempo para la ejecución. Pero también significa que si siguen llegando nuevos jugadores, la situación empeorará, hasta el tiempo de inactividad.
Como resultado, se evitó el peor resultado: ¿el servicio no se interrumpió por completo?
Nikita: Afortunadamente, todo terminó bien.
Por supuesto, si la situación hubiera surgido en medio de la jornada laboral, no nos habríamos preocupado en absoluto, allí puede reaccionar rápidamente. Pero no el viernes por la noche. El viernes por la noche, vas a un bar y recibes este mensaje en tu teléfono. Pero para arreglarlo todo, no basta con estar al teléfono.
¿Cómo manejaste la situación?
Irina: Acabamos de reducir el costo de las campañas publicitarias en casi un 70%.
¿Volvió a encarrilarse más tarde?
Irina: No, no lo llevaron al mismo estado, porque la situación era impredecible: Facebook aumentaba y aumentaba la conversión cada día. Si hubiéramos estado girando a la misma velocidad durante otra semana, tal vez la conversión hubiera sido aún mayor. Pero no se requirieron victorias heroicas, por lo que restauramos un nivel cómodo. Resultó que había unos 10 mapas cargados y el servicio funcionó en silencio.
Nikita: Cabe señalar que hay otros lados del problema: tratamos de responder rápidamente a los mensajes de los jugadores. Cuantos más jugadores, más solicitudes de apoyo generan. Queríamos mantener un alto nivel de servicio y no estábamos preparados para aumentar la cantidad de soporte tan rápidamente. Decidimos que sería más prudente hacer todo de manera más fluida y predecible que alcanzar el pico durante el fin de semana.
Esta vez decidió sofocar la campaña publicitaria y así salvó la situación. ¿Cómo suele resolver un problema de escala desde un punto de vista técnico?
Nikita: Estamos escalando lanzando instancias adicionales del servicio.
En este caso, no es Kubernetes y no hay escala automática. Es necesario iniciar una clonación de máquina virtual en modo semi-manual; debe esperar hasta media hora mientras se recrea la máquina virtual a partir de la imagen. Después de eso, debe verificar que la máquina virtual esté funcionando como se esperaba y que todos los servicios en ella hayan aumentado: servidores LSP, ejecutores de código. Después de eso, equilibramos el tráfico a las nuevas máquinas y continuamos monitoreando la carga de trabajo y los códigos de estado.
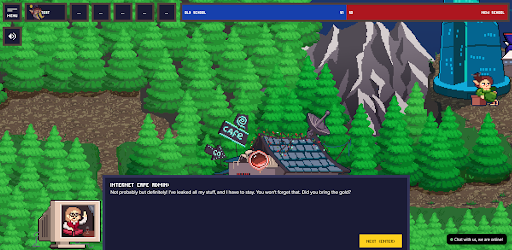
Captura de pantalla del juego SberCraft
Conclusiones y planes
¿Cómo reorganizó su trabajo después de este incidente?
Nikita: Descubrimos cuál es la mejor manera de planificar el marketing: cuánta inversión hace qué cantidad de registros dan.
A nivel técnico, estamos firmemente convencidos de que necesitamos una nueva forma de escalar el servicio de ejecución de código, idealmente: escala automática.
Hacemos que el servicio de ejecución de código no tenga estado (independiente del sistema de almacenamiento), realizamos pequeños cambios en la arquitectura y cambiamos la infraestructura; presentamos el mismo Kubernetes en el que se ejecutan otros servicios.
Pero en el caso de un servicio de ejecución de código, el esquema es más complicado: no es tan fácil traducirlo como los demás. Seguimos comprobando que todo funciona como debería.
En este momento, el código se está ejecutando en DigitalOcean y se ejecutará en la nube de Azure. En Kubernetes.
¿Está utilizando Kubernetes como servicio (Azure Kubernetes Service)?
Nikita: Sí. Estamos utilizando Kubernetes como servicio y también estamos considerando la opción Cloud Functions.
¿Cómo es AWS Lambda?
Nikita: Sí, todos los proveedores importantes los tienen. Le permiten pagar exactamente lo mismo que ejecuta el código. Pero existen limitaciones técnicas en las capacidades de los entornos de ejecución.
¿Quién está a cargo de la infraestructura ahora?
Nikita: Mis calificaciones y calificaciones de los desarrolladores de back-end no siempre son suficientes, porque DevOps, SRE son un área muy amplia. Y dejar a los desarrolladores de back-end a cargo de incidentes no es muy correcto. Por lo tanto, a principios de año, obtuvimos un equipo de DevOps de subcontratación: los chicos con los que trabajamos anteriormente en otros negocios.
¿Por qué empezó a colaborar con el equipo de infraestructura y DevOps?
Nikita: El incidente con el juego fue el catalizador de cambios que reconocemos desde hace mucho tiempo, pero que no tuvimos la oportunidad de implementar.
La compañía ha crecido, comenzaron a ocurrir casos similares, lo que confirmó: sí, chicos, necesitan ingenieros de DevOps, necesitan hacer una infraestructura que sea más fácil de escalar.
La tarea se resolvió por completo hace dos meses, cuando recibimos una subvención de Azure. A estas alturas, muchos servicios se han trasladado a la nueva nube.
¿Por qué decidió subcontratar en lugar de contratar personas?
Nikita: Por nuestra propia experiencia, sabemos que DevOps es un área difícil de contratar. Y aquí resultó que hay muchachos probados, y la forma de trabajar con un contratista es muy conveniente para nosotros.
Bueno, y lo más importante: adquirimos no un ingeniero, sino todo un equipo que monitorea la disponibilidad de los servicios las 24 horas y está listo para responder a un incidente antes de que los usuarios lo descubran.
¿El equipo de DevOps está configurando todo desde cero o usando lo que era, incluido el monitoreo?
Nikita: Tomamos el camino del desplazamiento. Comenzamos nuevos proyectos en una nueva infraestructura, migramos los servicios centrales allí y dejamos los proyectos bajo soporte en la antigua. Todo es nuevo para nuevos proyectos, incluido el seguimiento.
La peculiaridad de la transformación es que hay que repensar la arquitectura del servicio. Entendimos cómo se puede cambiar para obtener nuevas cualidades.
Por lo tanto, también se está trabajando en el lado del backend: refactorizaremos el código, actualizaremos la arquitectura, pero en una cantidad bastante moderada.
Entonces, ¿está configurando nuevos procesos de CI / CD en este momento?
En primer lugar, nos estamos reestructurando organizativamente. Tenemos un nuevo rol, correspondiente al equipo dedicado, y las formas de comunicación, establecimiento de tareas han cambiado.
Teníamos procesos de CI / CD, recién comenzaron a pasar a la nueva infraestructura. Por supuesto, están mejorando, pero no cambian fundamentalmente.
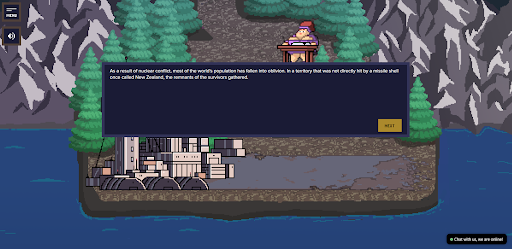
Captura de pantalla del juego SberCraft
¿Qué conclusión global has llegado a ti mismo?
En diferentes etapas de la vida de un proyecto, las cosas son diferentes. Hace seis meses, no hubiéramos estado preparados para el equipo de DevOps. Pero ahora podemos comunicarnos con ellos de manera mucho más sustancial. Entendemos claramente nuestros dolores y llegamos a los chicos con una lista de preguntas y sugerencias sobre cómo hacer algo. Resultó ser una buena colaboración: juntos llegamos a decisiones de alta calidad y bien fundamentadas.
Hay mucho trabajo por delante. El servicio de ejecución de código en el proceso de migración, y como el más complejo de nuestros servicios, requerirá mucha implicación. Durante algún tiempo tendremos ambas versiones del servicio en producción y equilibramos el tráfico entre ellas. Cuando entendamos que todo está bien, cambiaremos completamente a Azure.
, . , .
, , , .
21 «» , .
:
— ,
— ,
— ,
— ,
— .
Databricks, Mail.ru Cloud Solutions TangoMe.