
Recientemente se agregó una gran característica a la línea principal del compilador de Clang . Con los atributos
[[clang::musttail]]
o ,
__attribute__((musttail))
ahora puede obtener llamadas finales garantizadas en C, C ++ y Objective-C.
int g(int);
int f(int x) {
__attribute__((musttail)) return g(x);
}
( Compilador en línea )
Por lo general, estas llamadas están asociadas con la programación funcional, pero solo me interesan desde el punto de vista del rendimiento. En algunos casos, con su ayuda, puede obtener un mejor código del compilador, al menos con las tecnologías de compilación disponibles, sin recurrir a un ensamblador.
El uso de este enfoque para analizar el protocolo de serialización dio resultados sorprendentes: pudimos analizar a velocidades superiores a 2 Gb / s. , más del doble de rápido que la mejor solución anterior. Esta aceleración será útil en muchas situaciones, por lo que sería incorrecto limitarse a la declaración "tail calls == double speedup". Sin embargo, estos desafíos son un elemento clave que ha hecho posible ese aumento de velocidad.
Te diré cuáles son las ventajas de las llamadas finales, cómo analizamos el protocolo usándolas y cómo podemos extender esta técnica a los intérpretes. Creo que gracias a él, los intérpretes de los principales lenguajes escritos en C (Python, Ruby, PHP, Lua, etc.) pueden obtener ganancias de rendimiento significativas. El principal inconveniente está relacionado con la portabilidad: hoy
musttail
es una extensión de compilador no estándar. Aunque espero que se ponga al día, pasará algún tiempo antes de que la extensión se extienda lo suficiente para que el compilador de C de su sistema la admita. Al construir, puede sacrificar la eficiencia a cambio de la portabilidad si resulta que
musttail
no está disponible.
Conceptos básicos de Tail Call
Una llamada de cola es una llamada a cualquier función en la posición de cola, la última acción antes de que la función devuelva un resultado. Al optimizar las llamadas de cola, el compilador compila la instrucción para la llamada de cola
jmp
, no
call
. Esto no realiza acciones generales que normalmente permitirían
g()
a la persona que llama regresar a la persona que llama
f()
, como crear un nuevo marco de pila o pasar una dirección de retorno. En cambio, se
f()
refiere directamente a
g()
él como si fuera parte de sí mismo y
g()
devuelve el resultado directamente a la persona que llama
f()
. Esta optimización es segura porque el marco de la pila
f()
ya no es necesario después del inicio de la llamada de cola, porque se hizo imposible acceder a cualquier variable local
f()
.
Incluso si parece trivial, esta optimización tiene dos características importantes que abren nuevas posibilidades para escribir algoritmos. Primero, al ejecutar n llamadas de cola consecutivas, la pila de memoria se reduce de O (n) a O (1). Esto es importante porque la pila es limitada y el desbordamiento puede bloquear el programa. Entonces, sin esta optimización, algunos algoritmos son peligrosos. En segundo lugar,
jmp
elimina la sobrecarga de
call
y como resultado, la llamada a la función se vuelve tan eficiente como cualquier otra rama. Ambas características permiten que las llamadas de cola se utilicen como una alternativa eficiente a las estructuras de control iterativo convencionales como
for
y
while
.
Esta idea no es nueva en absoluto y se remonta a 1977, cuando Guy Steele escribió un artículo completo en el que argumentó que las llamadas a procedimientos son más limpias que las arquitecturas
GOTO
, mientras que la optimización de las llamadas finales no pierde velocidad. Fue una de las "Obras Lambda" escritas entre 1975 y 1980, que formuló muchas de las ideas detrás de Lisp y Scheme.
La optimización de llamadas de cola no es nada nuevo, incluso para Clang. Podía optimizarlos antes, como GCC y muchos otros compiladores. De hecho, el atributo
musttail
en este ejemplo no cambia la salida del compilador en absoluto: Clang ya ha optimizado las llamadas de cola para
-O2
.
Lo nuevo aquí es una garantía . Si bien los compiladores suelen tener éxito en la optimización de las llamadas finales, esto es lo "mejor posible" y no se puede confiar en ello. En particular, la optimización seguramente no funcionará en compilaciones no optimizadas: el compilador en línea . En este ejemplo, la llamada de cola se compila
call
, por lo que estamos de vuelta en una pila de tamaño O (n). Es por eso que necesitamos
musttail
: Hasta que tengamos una garantía del compilador de que nuestras llamadas de cola siempre estarán optimizadas en todos los modos de ensamblaje, no será seguro escribir algoritmos con tales llamadas para iteración. Y ceñirse al código que solo funciona con optimizaciones habilitadas es una restricción bastante difícil.
El problema con los bucles de intérprete
Los compiladores son una tecnología increíble, pero no son perfectos. Mike Pall, el autor de LuaJIT, decidió escribir el intérprete de LuaJIT 2.x en lenguaje ensamblador, no en C, y lo llamó el factor principal que hizo que el intérprete fuera tan rápido . Paul explicó más tarde con más detalle por qué los compiladores de C tienen dificultades para encontrar los bucles principales del intérprete . Dos puntos principales:
- , .
- , .
Estas observaciones reflejan bien nuestra experiencia en la optimización del análisis del protocolo de serialización. Y las llamadas de cola nos ayudarán a resolver ambos problemas.
Puede que le resulte extraño comparar los bucles del intérprete con los analizadores del protocolo de serialización. Sin embargo, su similitud inesperada está determinada por la naturaleza del formato de cable del protocolo: es un conjunto de pares clave-valor en el que la clave contiene el número de campo y su tipo. La clave funciona como un código de operación en el intérprete: nos dice qué operación se debe realizar para analizar este campo. Los números de campo en el protocolo pueden ir en cualquier orden, por lo que debe estar listo para saltar a cualquier parte del código en cualquier momento.
Sería lógico escribir un analizador de este tipo utilizando un bucle
while
con una expresión anidada
switch
... Este ha sido el mejor enfoque para analizar un protocolo de serialización durante la vida útil del protocolo. Por ejemplo, aquí está el código de análisis de la versión actual de C ++ . Si representamos el flujo de control gráficamente, obtenemos el siguiente esquema:
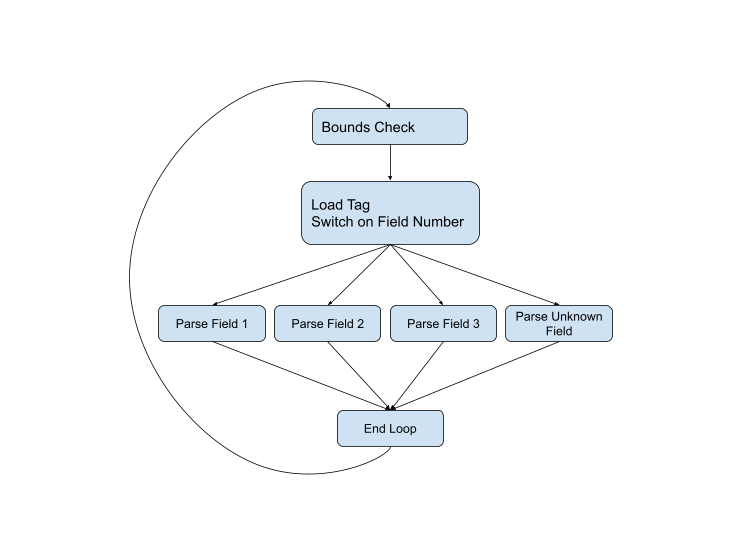
Pero el diagrama no está completo, porque pueden surgir problemas en casi todas las etapas. Es posible que el tipo de campo sea incorrecto, que los datos estén dañados o que simplemente saltemos al final del búfer actual. El diagrama completo se ve así:
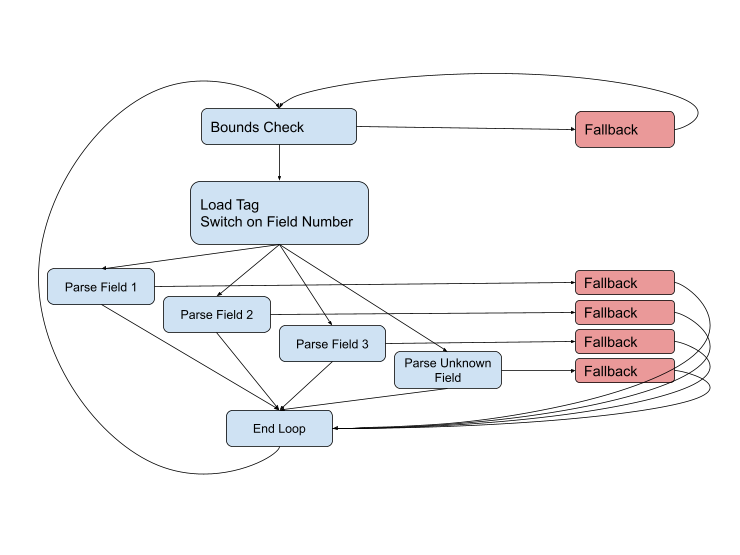
Necesitamos permanecer en las rutas rápidas (azul) el mayor tiempo posible, pero cuando nos enfrentemos a una situación difícil, tendremos que manejarla usando el código de reserva. Estas rutas suelen ser más largas y complejas que las rápidas, involucran más datos y, a menudo, usan llamadas incómodas a otras funciones para manejar casos aún más complejos.
En teoría, si combina este esquema con el perfil, el compilador obtendrá toda la información que necesita para generar el código más óptimo. Pero en la práctica, con este tamaño de función y el número de conexiones, a menudo tenemos que luchar con el compilador. Arroja una variable importante que queremos almacenar en el registro. Aplica la manipulación del marco de pila que queremos envolver alrededor de la llamada a la función de reserva. Concatena rutas de código idénticas que queremos mantener separadas para la predicción de ramas. Todo parece como intentar tocar el piano con guantes.
Mejora de bucles de intérprete con llamadas de cola
El razonamiento descrito anteriormente es en gran parte una reformulación de las observaciones de Pablo sobre los ciclos principales del intérprete . Pero en lugar de lanzarnos al ensamblador, descubrimos que la arquitectura personalizada puede brindarnos el control que necesitamos para obtener un código casi óptimo de C. Trabajé en esto con mi colega Gerben Stavenga, a quien se le ocurrió la mayor parte de la arquitectura. Nuestro enfoque es similar al intérprete wasm3 WebAssembly , que llama a este patrón "metamachine" .
Ponemos el código para nuestro analizador de 2 gigabits en upb, una pequeña biblioteca protobuf en C. Está en pleno funcionamiento y pasa todas las pruebas de conformidad con el protocolo de serialización, pero aún no se ha implementado en ningún lugar y la arquitectura no se ha implementado en la versión C ++ del protocolo. Pero cuando la extensión llegó a Clang
musttail
(y upb se actualizó para usarla ), una de las principales barreras para la implementación completa de nuestro analizador rápido desapareció.
Nos hemos alejado de una gran función de análisis y aplicamos su propia función pequeña para cada operación. Cada función de cola llama a la siguiente operación de la secuencia. Por ejemplo, aquí hay una función para analizar un solo campo de un tamaño fijo (el código está simplificado en comparación con upb, he eliminado muchos pequeños detalles de la arquitectura).
El código
#include <stdint.h>
#include <stddef.h>
#include <string.h>
typedef void *upb_msg;
struct upb_decstate;
typedef struct upb_decstate upb_decstate;
// The standard set of arguments passed to each parsing function.
// Thanks to x86-64 calling conventions, these will be passed in registers.
#define UPB_PARSE_PARAMS \
upb_decstate *d, const char *ptr, upb_msg *msg, intptr_t table, \
uint64_t hasbits, uint64_t data
#define UPB_PARSE_ARGS d, ptr, msg, table, hasbits, data
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
const char *fallback(UPB_PARSE_PARAMS);
const char *dispatch(UPB_PARSE_PARAMS);
// Code to parse a 4-byte fixed field that uses a 1-byte tag (field 1-15).
const char *upb_pf32_1bt(UPB_PARSE_PARAMS) {
// Decode "data", which contains information about this field.
uint8_t hasbit_index = data >> 24;
size_t ofs = data >> 48;
if (UNLIKELY(data & 0xff)) {
// Wire type mismatch (the dispatch function xor's the expected wire type
// with the actual wire type, so data & 0xff == 0 indicates a match).
MUSTTAIL return fallback(UPB_PARSE_ARGS);
}
ptr += 1; // Advance past tag.
// Store data to message.
hasbits |= 1ull << hasbit_index;
memcpy((char*)msg + ofs, ptr, 4);
ptr += 4; // Advance past data.
// Call dispatch function, which will read the next tag and branch to the
// correct field parser function.
MUSTTAIL return dispatch(UPB_PARSE_ARGS);
}
Para una función tan pequeña y simple, Clang genera código que es casi imposible de superar:
upb_pf32_1bt: # @upb_pf32_1bt
mov rax, r9
shr rax, 24
bts r8, rax
test r9b, r9b
jne .LBB0_1
mov r10, r9
shr r10, 48
mov eax, dword ptr [rsi + 1]
mov dword ptr [rdx + r10], eax
add rsi, 5
jmp dispatch # TAILCALL
.LBB0_1:
jmp fallback # TAILCALL
Tenga en cuenta que no hay prólogo ni epílogo, ni preferencia de registro, ni uso de pila en absoluto. Las únicas salidas son
jmp
de dos llamadas de cola, pero no se necesita código para pasar parámetros, porque los argumentos ya están en los registros correctos. Quizás la única mejora posible que vemos aquí es un salto condicional para una llamada de cola en
jne fallback
lugar de
jne
una llamada posterior
jmp
.
Si viera un desmontaje de este código sin información simbólica, no se daría cuenta de que esta era la función completa. También podría ser la unidad base de una función mayor. Y eso es exactamente lo que hacemos: tomamos el bucle del intérprete, que es una función grande y compleja, y lo programamos bloque por bloque, pasando el flujo de control entre ellos a través de llamadas de cola. Tenemos un control completo sobre la distribución de registros en el límite de cada bloque (al menos seis registros), y dado que la función es lo suficientemente simple y no reemplaza los registros, hemos logrado nuestro objetivo de almacenar el estado más importante a lo largo de todos los registros rápidos. rutas.
Podemos optimizar de forma independiente cada secuencia de instrucciones. Y el compilador también manejará todas las secuencias de forma independiente, ya que están ubicadas en funciones separadas (si es necesario, puede evitar alinearse con
noinline
). Así es como resolvemos el problema descrito anteriormente, en el que el código de las rutas de respaldo degrada la calidad del código de las rutas rápidas. Al colocar las rutas lentas en funciones completamente separadas, se puede garantizar la estabilidad de velocidad de las rutas rápidas. El hermoso ensamblador permanece sin cambios, no se ve afectado por ningún cambio en otras partes del analizador.
Si aplicamos este patrón al ejemplo de Paul de LuaJIT , entonces podemos aproximadamente correlacionar su ensamblador escrito a mano con pequeñas degradaciones en la calidad del código :
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
return fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
El ensamblador resultante:
ADDVN: # @ADDVN
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
movzx eax, dl
movsd xmm0, qword ptr [r8 + 8*rax] # xmm0 = mem[0],zero
mov eax, edi
addsd xmm0, qword ptr [r9 + 8*rax]
movsd qword ptr [r9 + 8*rax], xmm0
mov edx, dword ptr [rcx]
add rcx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [rsi + 8*rax]
jmp rax # TAILCALL
.LBB0_1:
jmp fallback
La única mejora que veo aquí además de lo anterior es
jne fallback
que, por alguna razón, el compilador no quiere generar
jmp qword ptr [rsi + 8*rax]
, sino que carga
rax
y luego ejecuta
jmp rax
. Estos son problemas menores de codificación que espero que Clang solucione pronto sin demasiada dificultad.
Limitaciones
Uno de los principales inconvenientes de este enfoque es que todas estas hermosas secuencias de lenguaje ensamblador están catastróficamente pesimizadas en ausencia de llamadas finales. Cualquier llamada no personalizada creará un marco de pila y enviará una gran cantidad de datos a la pila.
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
// When we leave off "return", things get real bad.
fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
De repente obtenemos esto
ADDVN: # @ADDVN
push rbp
push r15
push r14
push r13
push r12
push rbx
push rax
mov r15, r9
mov r14, r8
mov rbx, rcx
mov r12, rsi
mov ebp, edi
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
.LBB0_2:
movzx eax, dl
movsd xmm0, qword ptr [r14 + 8*rax] # xmm0 = mem[0],zero
mov eax, ebp
addsd xmm0, qword ptr [r15 + 8*rax]
movsd qword ptr [r15 + 8*rax], xmm0
mov edx, dword ptr [rbx]
add rbx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [r12 + 8*rax]
mov rsi, r12
mov rcx, rbx
mov r8, r14
mov r9, r15
add rsp, 8
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
jmp rax # TAILCALL
.LBB0_1:
mov edi, ebp
mov rsi, r12
mov r13d, edx
mov rcx, rbx
mov r8, r14
mov r9, r15
call fallback
mov edx, r13d
jmp .LBB0_2
Para evitar esto, intentamos llamar a otras funciones solo a través de inlining o tail calls. Esto puede resultar tedioso si la operación tiene muchos lugares en los que puede ocurrir una situación inusual que no sea un error. Por ejemplo, cuando analizamos el protocolo de serialización, las variables enteras suelen tener un byte de longitud, pero las más largas no son un error. Incluir el manejo de tales situaciones puede degradar la calidad de la ruta rápida si el código de reserva es demasiado complejo. Pero la llamada de cola de la función de reserva no facilita el regreso a la operación cuando se maneja una anomalía, por lo que la función de reserva debe poder completar la operación. Esto conduce a la duplicación y complicación del código.
Idealmente, este problema se puede resolver agregando __attribute __ ((preserve_most))en una función de reserva seguida de una llamada normal, no una llamada de cola. El atributo
preserve_most
hace que el destinatario de la llamada sea responsable de conservar casi todos los registros. Esto le permite delegar la tarea de apropiación de registros a funciones de respaldo, si es necesario. Experimentamos con este atributo, pero encontramos problemas misteriosos que no pudimos resolver. Quizás cometimos un error en alguna parte, volveremos a esto en el futuro.
La principal limitación es que
musttail
no es portátil. Realmente espero que el atributo se arraigue, se implemente en GCC, Visual C ++ y otros compiladores, y algún día incluso se estandarizará. Pero esto no sucederá pronto, pero ¿qué debemos hacer ahora?
Cuando la expansión
musttail
no está disponible, debe ejecutar al menos uno correcto
return
sin una llamada de cola para cada iteración teórica del bucle . Aún no hemos implementado tal respaldo en la biblioteca upb, pero creo que se convertirá en una macro que, dependiendo de la disponibilidad,
musttail
hará llamadas finales o simplemente regresará.