 ¡Hola, habitantes! ¿Cómo sacar todo de tus datos? ¿Cómo tomar decisiones basadas en datos? ¿Cómo organizar la ciencia de datos dentro de la empresa? ¿A quién contratar un analista? ¿Cómo llevar los proyectos de aprendizaje automático e inteligencia artificial al máximo nivel? Roman Zykov conoce la respuesta a estas y muchas otras preguntas, porque ha estado analizando datos durante casi veinte años. La trayectoria de Roman incluye la creación de su propia empresa desde cero con oficinas en Europa y Sudamérica, que se ha convertido en líder en el uso de inteligencia artificial (IA) en el mercado ruso. Además, el autor del libro creó análisis en Ozon.ru desde cero. Este libro está dirigido al lector pensante que quiera probar suerte en el análisis de datos y crear servicios basados en él. Te será útil si eres gerente,que quiere establecer metas y administrar análisis. Si eres un inversor, te resultará más fácil comprender el potencial de una startup. Aquellos que "vieron" su puesta en marcha encontrarán aquí recomendaciones sobre cómo elegir la tecnología adecuada y reclutar un equipo. Y el libro ayudará a los especialistas en ciernes a ampliar sus horizontes y comenzar a aplicar prácticas en las que no habían pensado antes, y esto los diferenciará de los profesionales en un campo tan difícil y volátil.
¡Hola, habitantes! ¿Cómo sacar todo de tus datos? ¿Cómo tomar decisiones basadas en datos? ¿Cómo organizar la ciencia de datos dentro de la empresa? ¿A quién contratar un analista? ¿Cómo llevar los proyectos de aprendizaje automático e inteligencia artificial al máximo nivel? Roman Zykov conoce la respuesta a estas y muchas otras preguntas, porque ha estado analizando datos durante casi veinte años. La trayectoria de Roman incluye la creación de su propia empresa desde cero con oficinas en Europa y Sudamérica, que se ha convertido en líder en el uso de inteligencia artificial (IA) en el mercado ruso. Además, el autor del libro creó análisis en Ozon.ru desde cero. Este libro está dirigido al lector pensante que quiera probar suerte en el análisis de datos y crear servicios basados en él. Te será útil si eres gerente,que quiere establecer metas y administrar análisis. Si eres un inversor, te resultará más fácil comprender el potencial de una startup. Aquellos que "vieron" su puesta en marcha encontrarán aquí recomendaciones sobre cómo elegir la tecnología adecuada y reclutar un equipo. Y el libro ayudará a los especialistas en ciernes a ampliar sus horizontes y comenzar a aplicar prácticas en las que no habían pensado antes, y esto los diferenciará de los profesionales en un campo tan difícil y volátil.
¿Necesito poder programar?
Si es necesario. En el siglo XXI, es deseable que todas las personas comprendan cómo utilizar la programación en su trabajo. Anteriormente, la programación estaba disponible solo para un círculo reducido de ingenieros. Con el tiempo, la programación aplicada se ha vuelto más accesible, democrática y conveniente.
Aprendí a programar por mi cuenta cuando era niño. Mi padre compró una computadora "Partner 01.01" a fines de la década de 1980, cuando yo tenía unos once años, y comencé a sumergirme en la programación. Primero, dominé el lenguaje BÁSICO, luego llegué al ensamblador. Estudié de todo, desde libros, luego no había nadie a quien preguntar. El trabajo de base que se hizo en la infancia fue muy útil para mí en la vida. En ese momento, mi instrumento principal era un cursor blanco parpadeante sobre una pantalla negra, los programas debían grabarse en una grabadora, todo esto no se puede comparar con las posibilidades que tenemos ahora. Los conceptos básicos de la programación no son tan difíciles de aprender. Cuando mi hija tenía cinco años y medio, la puse en un curso de programación Scratch simple. Con mis pequeños consejos, tomó este curso e incluso obtuvo su certificación MIT de nivel de entrada.
La programación de aplicaciones es lo que le permite automatizar parte de las funciones de un empleado. Los primeros candidatos a la automatización son las acciones repetitivas.
Hay dos formas de análisis. La primera es utilizar herramientas listas para usar (Excel, Tableau, SAS, SPSS, etc.), donde todas las acciones se realizan con el mouse, y la máxima programación es escribir una fórmula. El segundo es escribir en Python, R o SQL. Estos son dos enfoques fundamentalmente diferentes, pero una buena persona debe dominar ambos. Cuando trabaje con cualquier tarea, debe encontrar un equilibrio entre velocidad y calidad. Esto es especialmente cierto para la búsqueda de información. He conocido tanto a fervientes seguidores de la programación como a testarudos que solo podían usar un mouse y, como mucho, un programa. Un buen especialista seleccionará su propia herramienta para cada tarea. En algún caso, escribirá un programa, en otro hará todo en Excel. Y en el tercero, combinará ambos enfoques: cargará datos en SQL, procesará el conjunto de datos en Python y lo analizará en una tabla dinámica de Excel o Google Docs.La velocidad de trabajo de un especialista tan avanzado puede ser un orden de magnitud más alta que la de uno de una sola línea. El conocimiento da libertad.
Cuando aún era estudiante, dominaba varios lenguajes de programación e incluso logré trabajar durante un año y medio como desarrollador de software. Los tiempos eran difíciles entonces: ingresé al Instituto de Física y Tecnología de Moscú en junio de 1998, y en agosto hubo un incumplimiento. Era imposible vivir de una beca, no quería quitarles dinero a mis padres. En mi segundo año, tuve suerte, me contrataron como desarrollador en una de las empresas de MIPT, allí profundicé mis conocimientos de ensamblador y C. Después de un tiempo, conseguí un trabajo en el soporte técnico de StatSoft Rusia; aquí mejoré mi análisis estadístico. En Ozon.ru completó la capacitación y recibió un certificado SAS, y también escribió mucho en SQL. La experiencia de programación me ayudó mucho: no tenía miedo de algo nuevo, simplemente lo tomé y lo hice. Si no tuviera esa experiencia en programación, no habría muchas cosas interesantes en mi vida, incluida la empresa Retail Rocket,que fundamos con mis socios.
Conjunto de datos
Un conjunto de datos es un conjunto de datos, la mayoría de las veces en forma de tabla, que se ha descargado del almacenamiento (por ejemplo, a través de SQL) u obtenido de otra manera. Una tabla está formada por columnas y filas, comúnmente denominadas registros. En el aprendizaje automático, las columnas en sí mismas son variables independientes o predictores, o más comúnmente características y variables dependientes, resultado. Encontrará esta división en la literatura. La tarea del aprendizaje automático es entrenar un modelo que, utilizando las variables independientes (características), podrá predecir correctamente el valor de la variable dependiente (como regla, solo hay una en el conjunto de datos).
Los dos tipos principales de variables son categóricas y cuantitativas. Una variable categórica contiene el texto o la codificación numérica de "categorías". A su vez, puede ser:
- Binario: solo puede tomar dos valores (ejemplos: sí / no, 0/1).
- Nominal: puede tomar más de dos valores (ejemplo: sí / no / no sé).
- Ordinal: cuando el orden importa (por ejemplo, el rango del atleta, el número de línea en los resultados de la búsqueda).
Una variable cuantitativa puede ser:
- Discreto (discreto): la cuenta calcula el valor, por ejemplo, la cantidad de personas en la habitación.
- Continuo: cualquier valor del intervalo, por ejemplo, peso de la caja, precio del producto.
Veamos un ejemplo. Existe una tabla con precios de departamentos (variable dependiente), una fila (registro) para un departamento, cada departamento tiene un conjunto de atributos (independientes) con las siguientes columnas:
- El precio del apartamento es continuo y dependiente.
- El área del apartamento es continua.
- El número de habitaciones es discreto (1, 2, 3, ...).
- El baño es combinado (sí / no) - binario.
- Número de piso: ordinal o nominal (según la tarea).
- La distancia al centro es continua.
Estadísticas descriptivas
El primer paso después de descargar los datos del almacén es realizar un análisis de datos exploratorio, que incluye estadísticas descriptivas y visualización de datos, posiblemente borrando los datos mediante la eliminación de valores atípicos.
Las estadísticas descriptivas generalmente incluyen diferentes estadísticas para cada una de las variables en el conjunto de datos de entrada:
- El número de valores que no faltan.
- El número de valores únicos.
- Mínimo máximo.
- Significar.
- Mediana.
- Desviación Estándar.
- Percentiles: 25%, 50% (mediana), 75%, 95%.
No se pueden calcular todos los tipos de variables; por ejemplo, el promedio solo se puede calcular para variables cuantitativas. Los paquetes estadísticos y las bibliotecas de análisis estadístico ya tienen funciones listas para usar que cuentan estadísticas descriptivas. Por ejemplo, la biblioteca Python de pandas tiene una función de descripción que mostrará inmediatamente varias estadísticas para una o todas las variables en el conjunto de datos:
s = pd.Series([4-1, 2, 3])
s.describe()
count 3.0
mean 2.0
std 1.0
min 1.0
25% 1.5
50% 2.0
75% 2.5
max 3.0
Si bien este libro no pretende ser un libro de texto sobre estadística, le daré algunas sugerencias útiles. A menudo, en teoría, se supone que estamos trabajando con datos distribuidos normalmente, cuyo histograma parece una campana (Figura 4.1).
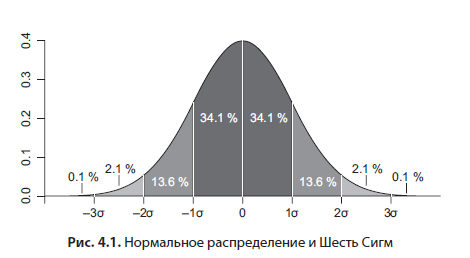
Recomiendo encarecidamente comprobar esta suposición al menos a ojo. La mediana es el valor que divide a la mitad la muestra. Por ejemplo, si los percentiles 25 y 75 están a distancias diferentes de la mediana, esto ya indica una distribución desplazada. Otro factor es la fuerte diferencia entre la media y la mediana; en una distribución normal, prácticamente coinciden. A menudo se enfrentará a una distribución exponencial al analizar el comportamiento del cliente; por ejemplo, en Ozon.ru, el tiempo entre los pedidos sucesivos de los clientes tendrá una distribución exponencial. La media y la mediana difieren significativamente. Por lo tanto, el número correcto es la mediana, el valor que divide a la mitad la muestra. En el ejemplo con Ozon.ru, este es el tiempo durante el cual el 50% de los usuarios realizan el siguiente pedido después del primero. La mediana también es más robusta a valores atípicos en los datos.Si desea trabajar con promedios, por ejemplo, debido a las limitaciones del paquete estadístico, y técnicamente el promedio se calcula más rápido que la mediana, entonces, en el caso de una distribución exponencial, puede procesarlo con el logaritmo natural. Para volver a la escala de datos original, debe procesar el promedio resultante con el exponente habitual.
El percentil es un valor que una variable aleatoria dada no excede con una probabilidad fija. Por ejemplo, la frase "el percentil 25 del precio de los bienes es igual a 150 rublos" significa que el 25% de los bienes tienen un precio menor o igual a 150 rublos, el 75% restante de los bienes es más caro que 150 rublos.
Para una distribución normal, si se conocen la media y la desviación estándar, hay patrones útiles derivados teóricamente: el 95% de todos los valores caen en el intervalo a una distancia de dos desviaciones estándar de la media en ambas direcciones, es decir, el el ancho del intervalo es cuatro sigma. Es posible que haya escuchado un término como Six Sigma (Figura 4.1): esta figura caracteriza la producción sin desperdicio. Entonces, esta ley empírica se deriva de la distribución normal: en el intervalo de seis desviaciones estándar alrededor de la media (tres en cada dirección), el 99,99966% de los valores se ajustan - calidad ideal. Los percentiles son muy útiles para encontrar y eliminar valores atípicos de los datos. Por ejemplo, al analizar datos experimentales, puede asumir que todos los datos fuera del percentil 99 son valores atípicos y eliminarlos.
Gráficos
Un buen gráfico vale más que mil palabras. Los principales tipos de gráficos que utilizo:
- histogramas;
- gráfico de dispersión;
- gráfico de series de tiempo con una línea de tendencia;
- diagrama de caja, diagrama de caja y bigotes.
El histograma (Figura 4.2) es la herramienta de análisis más útil. Le permite visualizar la distribución de frecuencia de la ocurrencia de un valor (para una variable categórica) o dividir una variable continua en rangos (bins). El segundo se usa con más frecuencia, y si además proporciona estadísticas descriptivas a dicho gráfico, tendrá una imagen completa que describe la variable que le interesa. El histograma es una herramienta sencilla e intuitiva.
Un diagrama de dispersión (Figura 4.3) le permite ver cómo dos variables dependen una de la otra. Se construye simplemente: en el eje horizontal - la escala de la variable independiente, en el eje vertical - la escala de la dependiente. Los valores (registros) están marcados como puntos. También se puede agregar una línea de tendencia. En los paquetes de estadísticas avanzadas, puede marcar de forma interactiva los valores atípicos.
Las gráficas de series de tiempo (Figura 4.4) son muy parecidas a una gráfica de dispersión, en la que la variable independiente (en el eje horizontal) es el tiempo. Por lo general, se pueden distinguir dos componentes de una serie de tiempo: cíclico y de tendencia. Se puede construir una tendencia sabiendo la duración del ciclo, por ejemplo, uno de siete días es un ciclo de ventas estándar en las tiendas de comestibles, puede ver una imagen repetida en el gráfico cada 7 días. A continuación, se superpone en el gráfico una media móvil con una longitud de ventana igual al ciclo, y se obtiene una línea de tendencia. Casi todos los paquetes estadísticos, Excel, Google Sheets pueden hacer esto. Si necesita obtener el componente cíclico, esto se hace restando la línea de tendencia de la serie de tiempo. Sobre la base de cálculos tan simples, se construyen los algoritmos más simples para pronosticar series de tiempo.
El diagrama de caja (Fig. 4.5) es muy interesante; hasta cierto punto, duplica los histogramas, ya que también muestra una estimación de la distribución.
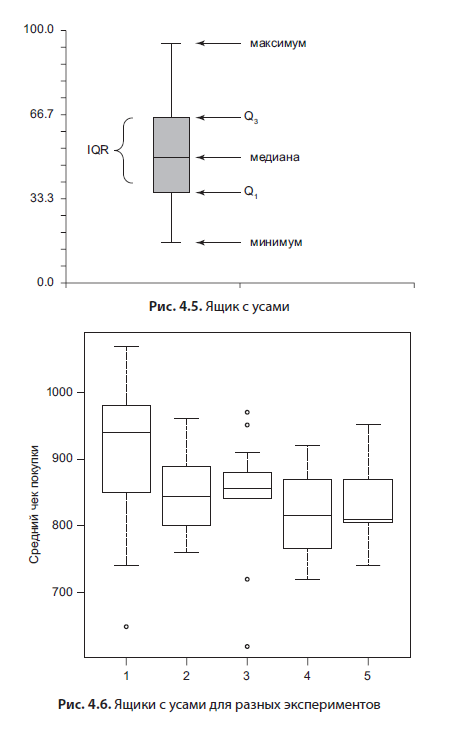
Consta de varios elementos: un bigote, que denota el mínimo y el máximo, una caja, cuyo borde superior es el percentil 75, el borde inferior es el percentil 25. En el cuadro, la línea es la mediana, el valor "en el medio", que divide la muestra por la mitad. Este tipo de gráfico es útil para comparar resultados experimentales o variables entre sí. A continuación se muestra un ejemplo de un gráfico de este tipo (Fig. 4.6). Creo que esta es la mejor manera de visualizar los resultados de la prueba de hipótesis.
Enfoque general de la visualización de datos
La visualización de datos es necesaria para dos cosas: explorar los datos y explicar los hallazgos al cliente. A menudo, se utilizan varios métodos para presentar los resultados: un simple comentario con un par de números, Excel u otro formato de hoja de cálculo, una presentación con diapositivas. Los tres métodos combinan conclusión y prueba, es decir, una explicación de cómo se llegó a esta conclusión. Es conveniente expresar la prueba en gráficos. En el 90% de los casos, los gráficos de los tipos descritos anteriormente son suficientes para esto.
Los gráficos exploratorios y los gráficos de presentación son diferentes entre sí. El propósito de la investigación es encontrar un patrón o causa, por regla general, hay muchos de ellos, y sucede que se construyen al azar. El propósito de los gráficos de presentación es guiar al tomador de decisiones (tomador de decisiones) a las conclusiones del problema. Todo es importante aquí, tanto el título de la diapositiva como su secuencia simple que conduce a la conclusión deseada. Un criterio importante para el esquema de prueba de inferencia es qué tan rápido el cliente lo comprenderá y estará de acuerdo con usted. No tiene por qué ser una presentación. Personalmente, prefiero texto simple: un par de oraciones con conclusiones, un par de gráficos y algunos números que prueben estas conclusiones, nada más.
Gene Zelazny, director de comunicaciones visuales de McKinsey & Company, afirma en su libro Speak the Language of Diagrams:
“El tipo de gráfico no está determinado por los datos (dólares o intereses) ni por ciertos parámetros (beneficio, rentabilidad o salario). y tu idea es lo que quieres poner en el diagrama ".
Te recomiendo que prestes atención a los gráficos en las presentaciones y artículos, ¿prueban las conclusiones del autor? ¿Te gusta todo sobre ellos? ¿Podrían ser más convincentes?
Y esto es lo que escribe Jean Zelazny sobre las diapositivas en las presentaciones:
"El uso generalizado de la tecnología informática ha llevado al hecho de que ahora, en minutos, puede hacer lo que antes requería horas de trabajo minucioso, y las diapositivas se hornean como pasteles ... insípidos y sin sabor".
Hice muchos informes: con y sin diapositivas, cortos, de 5 a 10 minutos y largos, de una hora. Les puedo asegurar que me es mucho más difícil hacer un texto convincente para una presentación corta sin diapositivas que una presentación en PowerPoint. Mire a los políticos que están hablando: su tarea es convencer, ¿cuántos de ellos muestran diapositivas en sus discursos? La palabra es más convincente, las diapositivas son solo material visual. Y hacer que tu palabra sea clara y convincente requiere más trabajo que lanzar diapositivas. Me encontré pensando en cómo se ve la presentación al componer las diapositivas. Y al escribir un informe oral, qué tan convincentes son mis argumentos, cómo trabajar con la entonación, qué tan claro es mi pensamiento. Por favor considera¿realmente necesitas una presentación? ¿Quiere convertir una reunión en aburridas diapositivas en lugar de tomar decisiones?
“Las reuniones deben centrarse en informes breves y escritos en papel, en lugar de resúmenes o fragmentos de listas proyectadas en la pared”, dice Edward Tufty, un destacado portavoz de la escuela de visualización de datos, en PowerPoint Cognitive Style.
Análisis de datos emparejados
Aprendí sobre la programación por pares de los desarrolladores [30] Retail Rocket. Es una técnica de programación en la que el código fuente es creado por pares de personas que programan la misma tarea y se sientan en la misma estación de trabajo. Un programador se sienta al teclado, el otro trabaja con la cabeza, se concentra en el panorama general y mira continuamente el código producido por el primer programador. Pueden cambiar de lugar de vez en cuando.
¡Y logramos adaptarlo a las necesidades de la analítica! La analítica, como la programación, es un proceso creativo. Imagina que necesitas construir un muro. Tienes un trabajador. Si agrega uno más, la velocidad se duplicará aproximadamente. En el proceso creativo, esto no funcionará. La velocidad de creación del proyecto no se duplicará. Sí, puede descomponer un proyecto, pero ahora estoy discutiendo una tarea que no se puede descomponer, y debe ser realizada por una sola persona. El enfoque emparejado le permite acelerar este proceso muchas veces. Una persona está en el teclado, la segunda está sentada a su lado. Dos cabezas están trabajando en el mismo problema. Cuando resuelvo problemas difíciles, hablo conmigo mismo. Cuando dos cabezas se hablan, buscan una mejor razón. Usamos el esquema de trabajo por parejas para las siguientes tareas.
- Cuando es necesario transferir el conocimiento de un proyecto de un empleado a otro, por ejemplo, se contrató a un recién llegado. El "jefe" será un empleado que transfiere conocimiento, "manos" en el teclado - a quien se transfiere.
- Cuando el problema es complejo e incomprensible. Entonces, dos empleados experimentados en pareja lo resolverán de manera mucho más eficiente que uno. Será más difícil hacer que la tarea de análisis sea unilateral.
Por lo general, durante la planificación, transferimos una tarea a la categoría de emparejados, si está claro que se ajusta a los criterios de los mismos.
Las ventajas del enfoque de pareja son que el tiempo se usa de manera mucho más eficiente, ambas personas están muy concentradas, se disciplinan mutuamente. Las tareas complejas se resuelven de forma más creativa y en un orden de magnitud más rápido. Menos: es imposible trabajar en este modo durante más de unas pocas horas, te cansas mucho.
Deuda técnica
Otra cosa importante que aprendí de los ingenieros de Retail Rocket es lidiar con la deuda técnica. La deuda técnica consiste en trabajar con proyectos antiguos, optimizar la velocidad de trabajo, cambiar a nuevas versiones de bibliotecas, eliminar el código antiguo de las pruebas de hipótesis, simplificar la ingeniería de proyectos. Todas estas tareas ocupan un buen tercio del tiempo de desarrollo de la analítica. Citaré al director técnico de Retail Rocket Andrey Chizh:
“Todavía no he conocido a ninguna empresa en mi práctica (y esto es más de 10 empresas en las que trabajé, y aproximadamente el mismo número que conozco bien desde dentro) , a excepción del nuestro, que si hubiera habido tareas para eliminar la funcionalidad, aunque, probablemente, tal exista ".
Yo tampoco me he encontrado. Vi los "pantanos" de los proyectos de software, donde las cosas viejas interfieren con la creación de algo nuevo. El quid de la deuda tecnológica es que todo lo que ha hecho antes debe ser reparado. Es como el mantenimiento de un automóvil: debe realizarse con regularidad, de lo contrario, el automóvil se descompondrá en el momento más inesperado. El código que no se ha cambiado o actualizado durante mucho tiempo es un código incorrecto. Por lo general, ya funciona según el principio de "funciona, no tocar". Hace cuatro años, hablé con un desarrollador de Bing. Dijo que en la arquitectura de este buscador hay una biblioteca compilada, cuyo código se pierde. Y nadie sabe cómo restaurarlo. Cuanto más tarde, peores serán las consecuencias.
Cómo los analistas de Retail Rocket atienden la deuda tecnológica:
- , . .
- - — , . , Spark , 1.0.0.
- - — .
- - — , , .
Lidiar con la deuda técnica es el camino hacia la calidad. Estaba convencido de esto trabajando en el proyecto Retail Rocket. Desde el punto de vista de la ingeniería, el proyecto se realiza como en las "mejores casas de California".
Se pueden encontrar más detalles sobre el libro en el sitio web de la editorial
» Tabla de contenido
» Extracto
para los habitantes un 25% de descuento en el cupón - Ciencia de datos
Tras el pago de la versión impresa del libro, se envía un libro electrónico a la Email.