
YELP es una red en el extranjero que ayuda a las personas a encontrar negocios y servicios locales basándose en comentarios, preferencias y recomendaciones. En los artículos actuales se realizará un cierto análisis del mismo utilizando la plataforma Neo4j, relacionada con el DBMS gráfico, así como el lenguaje python.
Que veremos:
- cómo trabajar con Neo4j y grandes conjuntos de datos usando YELP como ejemplo;
- cómo puede ser útil el conjunto de datos YELP;
- parcialmente: cuáles son las características de las nuevas versiones de Neo4j y por qué el libro "Graph Algorithms" 2019 de O'REILLY ya está desactualizado.
¿Qué es el conjunto de datos YELP y yelp?
La red YELP cubre actualmente 30 países, la Federación de Rusia aún no está incluida en su número. La red no admite el idioma ruso. La red en sí contiene una cantidad bastante voluminosa de información sobre varios tipos de empresas, así como reseñas sobre ellas. Además, yelp se puede llamar de forma segura una red social, ya que contiene datos sobre los usuarios que dejaron reseñas. Allí no hay datos personales, solo nombres. Sin embargo, los usuarios forman comunidades, grupos o pueden unirse en estos grupos y comunidades de acuerdo con varios criterios. Por ejemplo, por el número de estrellas (estrellas) que se han asignado al punto (restaurante, gasolinera, etc.) que has visitado.
YELP se describe a sí mismo de la siguiente manera:
- 8.635.403 opiniones
- 160.585 Empresas
- 200.000 imágenes
- 8 megalópolis
1,162,119 recomendaciones de 2,189,457 usuarios.
Más de 1.2 millones de parafernalia comercial: horarios de apertura, estacionamiento, disponibilidad y más.
Desde 2013, Yelp ha organizado regularmente el concurso de conjuntos de datos de Yelp, animando a todos a
explorar y explorar el conjunto de datos abiertos de Yelp.
El conjunto de datos en sí está disponible en el enlace El
conjunto de datos es bastante voluminoso y, después de desempaquetarlo, consta de 5 archivos json:
todo estaría bien, pero solo YELP carga datos sin procesar y sin procesar y, para comenzar a trabajar con ellos, se requiere un procesamiento previo.
Instalación y configuración rápida de Neo4j
Para el análisis se utilizará Neo4j, usaremos las capacidades del DBMS gráfico y su lenguaje cifrado simple para trabajar con el conjunto de datos.
Acerca de Neo4j como una base de datos de gráficos escrita repetidamente en Habre ( aquí y aquí para un artículo para principiantes), así que volver a enviarlo no tiene sentido.
Para comenzar a trabajar con la plataforma, debe descargar la versión de escritorio (aproximadamente 500Mb) o trabajar en el sandbox en línea. En el momento de escribir este artículo, Neo4j Enterprise 4.2.6 para desarrolladores está disponible, así como otras versiones anteriores para su instalación.
Además, se utilizará la opción: trabajar en la versión de escritorio en el entorno de Windows (Neo4j Desktop 1.4.5, versiones de base de datos 4.2.5, 4.2.1).
A pesar de que la versión más reciente es la 4.2.6, es mejor no instalarla todavía, ya que todos los complementos utilizados en neo4j aún no se han actualizado. La versión anterior, 4.2.5, será suficiente.
Después de instalar el paquete descargado, deberá:
- crear una nueva base de datos local, especificando el usuario neo4j y la contraseña 123 (por qué exactamente se explicarán a continuación),
imagen

- instale los complementos que necesita: APOC, Graph Data Science Library.
imagen

- compruebe si la base de datos se inicia y si el navegador se abre cuando hace clic en el botón de inicio
imagen


*: habilite el modo fuera de línea para que la base de datos no intente sugerir nuevas versiones.
imagen

Cargando datos en Neo4j
Si todo salió bien con la instalación de Neo4j, puede seguir adelante y hay tres formas.
La primera forma es recorrer un largo camino desde la importación de datos a la base de datos desde cero, incluida su limpieza y transformación inicial.
La segunda forma es cargar la base de datos terminada desde el volcado y comenzar a trabajar con ella.
La tercera forma es cargar la base de datos terminada directamente en la carpeta con la base de datos recién creada.
Como resultado, en todos los casos, debe obtener una base de datos con los siguientes parámetros:

y el esquema final:
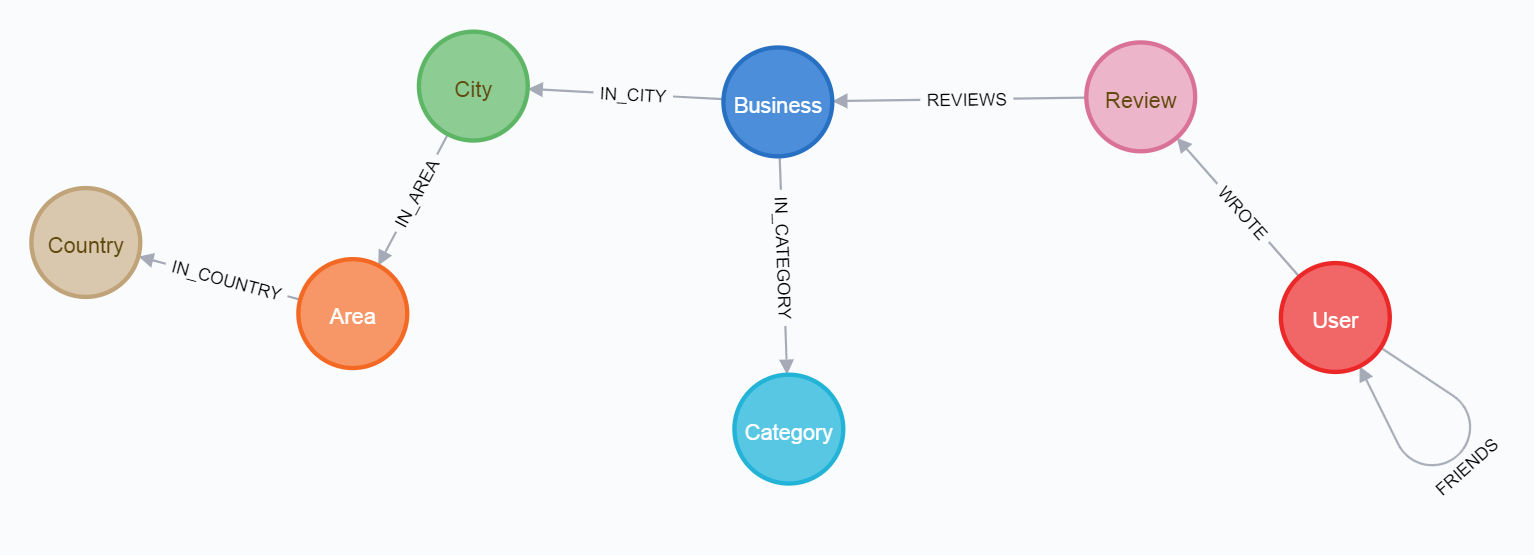
Para pasar por la primera ruta, es mejor leer primero el artículo sobre el medio .
* Muchas gracias a TRAN Ngoc Thach por esto.
Y use un cuaderno jupyter listo para usar (adaptado por mí para Windows): enlace .
El proceso de importación no es fácil y lleva bastante tiempo:

no hay problemas con la memoria, incluso si solo tiene 8 GB de RAM, ya que se utiliza la importación por lotes.
Sin embargo, deberá crear un archivo de intercambio de 10 GB, ya que al verificar los datos importados, jupyter se bloquea, se menciona este punto en el cuaderno jupyter anterior.
La segunda forma es más sencilla.
Cree una base de datos, vaya a la carpeta con su neo4j-admin (cada base de datos tiene la suya) y ejecute:
neo4j-admin load --from=G:\neo4j\dumps\neo4j.dump --database=neo4j --force
donde G: \ neo4j \ dumps \ neo4j.dump es la ruta al volcado de la base de datos.
La tercera vía es la más rápida y fue descubierta por accidente. Implica copiar una base de datos neo4j lista para usar directamente en una base de datos neo4j existente. De las desventajas (descubiertas hasta ahora): no puede hacer una copia de seguridad de la base de datos usando Neo4j (neo4j-admin dump --database = neo4j --to = D: \ neo4j \ neo4j.dump). Sin embargo, esto puede deberse a diferencias en las versiones: en la versión 4.2.1, la base de datos se copió de la versión 4.2.5. Además, aparecen artefactos en el esquema general de la base de datos que, sin embargo, no afectan su funcionamiento.
Cómo se implementa este método:
- abra la pestaña Administrar de la base de datos donde se realizará la importación
imagen


- vaya a la carpeta con la base de datos y copie la carpeta de datos allí, sobrescribiendo posibles coincidencias
imagen

En este caso, la base de datos en sí, donde se realizó la copia, no debe iniciarse.
- Reinicie Neo4j.
Y aquí es donde la contraseña de inicio de sesión que se utilizó anteriormente (neo4j, 123) será útil para evitar conflictos.
Después de iniciar la base de datos copiada, estará disponible una base de datos con un conjunto de datos de yelp:

Viendo YELP
Puede estudiar YELP tanto desde el navegador Neo4j como enviando consultas a la base de datos desde el mismo cuaderno jupyter.
Debido a que la base de datos es gráfica, el navegador irá acompañado de una agradable imagen visual en la que se mostrarán estos gráficos.
Comenzando a familiarizarse con YELP, es necesario hacer una reserva de que la base de datos contendrá solo 3 países US, KG y CA:

Puede ver el esquema de la base de datos escribiendo una solicitud en el idioma cifrado en el navegador neo4j:
CALL db.schema.visualization()
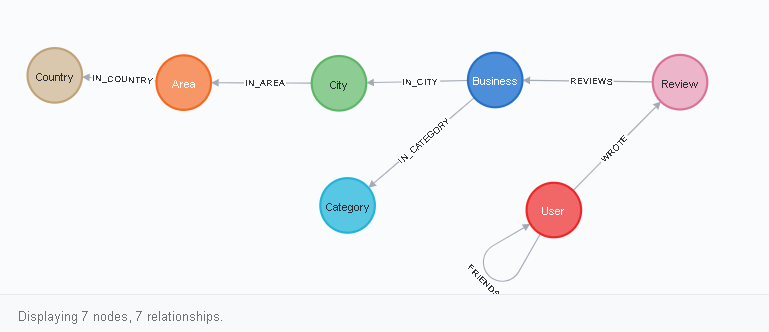
¿Cómo leer este diagrama? Todo se ve así. El nodo Usuario tiene un enlace a sí mismo del tipo AMIGOS, así como un enlace ESCRITO al nodo Revisar. Rewiew, a su vez, tiene una conexión de REVIEWS con Business, y así sucesivamente. Puede ver esto visualmente después de hacer clic en uno de los vértices (etiquetas de nodo), por ejemplo, en Usuario: la

base de datos seleccionará 25 usuarios y los mostrará:

Si hace clic en el icono correspondiente directamente en el usuario, entonces todos Se mostrarán conexiones directas de él, y así como conexiones para Usuario de dos tipos - AMIGOS y REVISIÓN, entonces aparecerán todas:
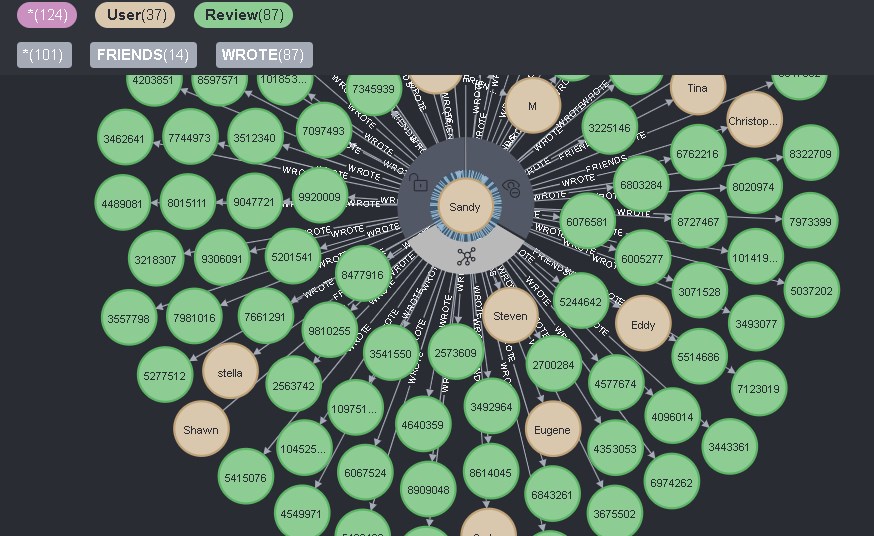
Esto es conveniente e inconveniente al mismo tiempo. Por un lado, puede ver toda la información sobre el usuario con un clic, pero al mismo tiempo, no puede eliminar información innecesaria con este clic.
Pero no hay nada de qué preocuparse, puede encontrar a este usuario y solo a todos sus amigos por id:
MATCH p=(:User {user_id:"u-CFWELen3aWMSiLAa_9VANw"}) -[r:FRIENDS]->() RETURN p LIMIT 25

De la misma manera, puede ver qué reseñas escribió una persona determinada: ¡

YELP almacena reseñas ya desde 2010! Utilidad dudosa, pero no obstante.
Para leer estas reseñas, debe cambiar a la vista de texto haciendo clic en A -

Veamos el lugar donde Sandy escribió hace unos 10 años y busquemos en yelp.com -

Un lugar así realmente existe - www.yelp.com/ biz / cafe-sushi- cambridge ,
y aquí está la propia Sandy con su propia reseña: www.yelp.com/biz/cafe-sushi-cambridge?q=I%20was%20really%20excited
imagen

Consultas de Python en Neo4j db desde jupyter notebook
Utilizará parcialmente información del libro gratuito mencionado "Graph Algorithms" 2019 de O'REILLY. En parte porque la sintaxis del libro está desactualizada en muchos lugares.
La base con la que trabajaremos debe ser lanzada, mientras que no es necesario lanzar el navegador neo4j en sí.
Importación de bibliotecas:
from neo4j import GraphDatabase
import pandas as pd
from tabulate import tabulate
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
Conexión DB:
driver = GraphDatabase.driver("bolt://localhost", auth=("neo4j", "123"))
Cuentemos el número de vértices para cada etiqueta en la base de datos:
result = {"label": [], "count": []}
with driver.session() as session:
labels = [row["label"] for row in session.run("CALL db.labels()")]
for label in labels:
query = f"MATCH (:`{label}`) RETURN count(*) as count"
count = session.run(query).single()["count"]
result["label"].append(label)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Salida:
+ ---------- + --------- +
| etiqueta | contar |
| ---------- + --------- |
| País | 3 |
| Area | 15 |
| Ciudad | 355 |
| Categoría | 1330 |
| Negocios | 160585 |
| Usuario | 2189457 |
| Revisión | 8635403 |
+ ---------- + --------- +
Parece ser cierto, en nuestra base de datos hay 3 países, como vimos anteriormente a través del navegador neo4j.
Y este código contará el número de enlaces (bordes):
result = {"relType": [], "count": []}
with driver.session() as session:
rel_types = [row["relationshipType"] for row in session.run
("CALL db.relationshipTypes()")]
for rel_type in rel_types:
query = f"MATCH ()-[:`{rel_type}`]->() RETURN count(*) as count"
count = session.run(query).single()["count"]
result["relType"].append(rel_type)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Salida:
+ ------------- + --------- +
| relType | contar |
| ------------- + --------- |
| IN_COUNTRY | 15 |
| IN_AREA | 355 |
| IN_CITY | 160585 |
| IN_CATEGORY | 708884 |
| REVISIONES | 8635403 |
| ESCRITO | 8635403 |
| AMIGOS | 8985774 |
+ ------------- + --------- +
Creo que el principio es claro. Finalmente, escribamos una solicitud y la rendericemos.
Los 10 mejores hoteles de Vancouver con más reseñas
# Find the 10 hotels with the most reviews
query = """
MATCH (review:Review)-[:REVIEWS]->(business:Business),
(business)-[:IN_CATEGORY]->(category:Category {category_id: $category}),
(business)-[:IN_CITY]->(:City {name: $city})
RETURN business.name AS business, collect(review.stars) AS allReviews
ORDER BY size(allReviews) DESC
LIMIT 10
"""
#MATCH (review:Review)-[:REVIEWS]->(business:Business),
#(business)-[:IN_CATEGORY]->(category:Category {category_id: "Hotels"}),
#(business)-[:IN_CITY]->(:City {name: "Vancouver"})
#RETURN business.name AS business, collect(review.stars) AS allReviews
#ORDER BY size(allReviews) DESC
#LIMIT 10
fig = plt.figure()
fig.set_size_inches(10.5, 14.5)
fig.subplots_adjust(hspace=0.4, wspace=0.4)
with driver.session() as session:
params = { "city": "Vancouver", "category": "Hotels"}
result = session.run(query, params)
for index, row in enumerate(result):
business = row["business"]
stars = pd.Series(row["allReviews"])
#print(dir(stars))
total = stars.count()
#s = pd.concat([pd.Series(x['A']) for x in data]).astype(float)
s = pd.concat([pd.Series(row['allReviews'])]).astype(float)
average_stars = s.mean().round(2)
# Calculate the star distribution
stars_histogram = stars.value_counts().sort_index()
stars_histogram /= float(stars_histogram.sum())
# Plot a bar chart showing the distribution of star ratings
ax = fig.add_subplot(5, 2, index+1)
stars_histogram.plot(kind="bar", legend=None, color="darkblue",
title=f"{business}\nAve:{average_stars}, Total: {total}")
#print(business)
#print(stars)
plt.tight_layout()
plt.show()
El resultado debería verse así: el

eje X representa la calificación de estrellas del hotel y el eje Y representa el porcentaje total de cada calificación.
Cómo puede ser útil el conjunto de datos YELP
Entre las ventajas se encuentran las siguientes :
- un campo de información bastante rico en términos de contenido. En particular, puede recopilar reseñas con 1.0 o 5.0 estrellas y enviar spam a cualquier negocio. Hmm. Un poco en la dirección equivocada, pero el vector está claro;
- el conjunto de datos es grande, lo que crea agradables dificultades adicionales en términos de probar el rendimiento de varias plataformas de extracción de datos;
- los datos presentados tienen una cierta retrospectiva y, en principio, es posible comprender cómo ha cambiado la empresa, con base en las revisiones al respecto;
- los datos se pueden utilizar como puntos de referencia para las empresas, dado que las direcciones están disponibles;
- los usuarios en el conjunto de datos a menudo forman estructuras interconectadas interesantes que pueden tomarse como están, sin convertir a los usuarios en una sociedad artificial. red y no recopilar esta red de otras redes sociales existentes. redes.
Contras :
- sólo tres de los 30 países están representados y existe la sospecha de que esto no es del todo,
- las opiniones se almacenan durante 10 años, lo que puede distorsionar y, a menudo, estropear las características de una empresa existente,
- hay pocos datos sobre los usuarios, son impersonales, por lo tanto, los sistemas de recomendación basados en el conjunto de datos serán claramente patéticos
- Los enlaces de AMIGOS usan gráficos dirigidos, es decir, Anya es amiga -> Petya. Resulta que Petya no es amiga de Anya. Esto se puede resolver mediante programación, pero sigue siendo un inconveniente.
- el conjunto de datos se presenta "sin procesar" y requiere un esfuerzo considerable para preprocesarlo.
Neo4j
Neo4j se actualiza dinámicamente y la nueva versión de la interfaz utilizada en Neo4j Desktop 1.4.5 no es muy conveniente, en mi opinión. En particular, hay una falta de claridad en términos de información sobre el número de nodos y enlaces en la base de datos, que estaba en versiones anteriores. Además, se ha cambiado la interfaz para navegar por las pestañas cuando se trabaja con la base de datos y también es necesario acostumbrarse.
La principal molestia de las actualizaciones es la integración de algoritmos de gráficos en el complemento Graph Data Science Library. Anteriormente se llamaban algoritmos de gráficos neo4j .
Después de la integración, muchos algoritmos cambiaron su sintaxis significativamente. Por esta razón, estudiar el libro de algoritmos gráficos de 2019 de O'REILLY puede ser difícil.
Volcado de base de datos de Yelp para neo4j - descargar...