Esta publicación final trata sobre el análisis de varianza. Vea la publicación anterior aquí .
Análisis de variación
Análisis de varianza (varianza), que en la literatura especial también se conoce como ANOVA del inglés. ANalysis Of VAriance es un conjunto de métodos estadísticos utilizados para medir la significación estadística de las diferencias entre grupos. Fue desarrollado por el estadístico extremadamente talentoso Ronald Fisher, quien también popularizó la prueba de significación estadística en sus trabajos de investigación de pruebas biológicas.
Nota... En las publicaciones anteriores y en esta serie, el término "varianza" se usó en nuestro término aceptado "varianza" y el término "varianza" se indicó entre paréntesis en algunos lugares. No es casualidad. En el extranjero existen términos pareados "varianza" y "covarianza", y en teoría deberían traducirse con una raíz, por ejemplo, como "varianza" y "covarianza", pero de hecho, tenemos una conexión pareada rota, y son traducido como "varianza" y "covarianza" completamente diferentes. Pero eso no es todo. La "dispersión" (variación estadística) en el extranjero es un concepto genérico separado de dispersión, es decir, el grado en que la distribución se estira o contrae, y las medidas de la varianza estadística son la varianza, la desviación estándar y el rango intercuartil. Dispersión, como concepto genérico de dispersión, y varianza, como una de sus medidas,medir la distancia desde la media son dos conceptos diferentes. Además, en el texto para la variación, se utilizará en todo el texto el término generalmente aceptado "variación". Sin embargo, esta discrepancia en la terminología debe tenerse en cuenta.
z- t- . , , , .
, . , .
, página por página y combinada")
, , . - . , , .
— . , , . , , .
F-
F- — .
— 1, — . k , n — , :


F- pandas plot
:
def ex_2_Fisher():
''' F- '''
mu = 0
d1_values, d2_values = [4, 9, 49], [95, 90, 50]
linestyles = ['-', '--', ':', '-.']
x = sp.linspace(0, 5, 101)[1:]
ax = None
for (d1, d2, ls) in zip(d1_values, d2_values, linestyles):
dist = stats.f(d1, d2, mu)
df = pd.DataFrame( {0:x, 1:dist.pdf(x)} )
ax = df.plot(0, 1, ls=ls,
label=r'$d_1=%i,\ d_2=%i$' % (d1,d2), ax=ax)
plt.xlabel('$x$\nF-')
plt.ylabel(' \n$p(x|d_1, d_2)$')
plt.show()

F- , 100 , 5, 10 50 .
F-
, , F-. F- , . F- :
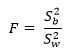
S2b — , S2w — .
F . , , . , , , .
F- , F. F .
F- . , . , k , x̅k, :

SSW — , xjk — j- .
SSW , Python, ssdev
, :
def ssdev( xs ):
'''
'''
mu = xs.mean()
square_deviation = lambda x : (x - mu) ** 2
return sum( map(square_deviation, xs) )
F- :

SST — , SSW — , . «» , :

, SST — - . Python SST SSW , .
ssw = sum( groups.apply( lambda g: ssdev(g) ) ) #
#
sst = ssdev( df['dwell-time'] ) #
ssb = sst – ssw #
F- . ssb
ssw
, F-.
Python F- :
msb = ssb / df1 #
msw = ssw / df2 #
f_stat = msb / msw
F- , F-.
F-
, , () , , .
scipy stats.f.sf
, . F- 20 , . , , F-. F-, F- F-, . f_test
, :
def f_test(groups):
m, n = len(groups), sum(groups.count())
df1, df2 = m - 1, n - m
ssw = sum( groups.apply(lambda g: ssdev(g)) )
sst = ssdev( df['dwell-time'] )
ssb = sst - ssw
msb = ssb / df1
msw = ssw / df2
f_stat = msb / msw
return stats.f.sf(f_stat, df1, df2)
def ex_2_24():
''' - F-'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
return f_test(groups)
0.014031745203658217
F- p-, scipy stats.f.sf
, . P- , .. - . . 5%- .
p-, 0.014, .. . - , .

- , :
def ex_2_25():
'''
- '''
df = load_data('multiple-sites.tsv')
df.boxplot(by='site', showmeans=True)
plt.xlabel(' -')
plt.ylabel(' , .')
plt.title('')
plt.suptitle('')
plt.show()
boxplot
, -. - 0, .

, - 10 , . , , , , 6, 144 .:
def ex_2_26():
'''T- 0 10 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_10 = groups.get_group(10)
_, p_val = stats.ttest_ind(site_0, site_10, equal_var=False)
return p_val
0.0068811940138903786
F-, , - 6 :
def ex_2_27():
'''t- 0 6 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_6 = groups.get_group(6)
_, p_val = stats.ttest_ind(site_0, site_6, equal_var=False)
return p_val
0.005534181712508717
, , , - 6 -. AcmeContent -. - - !
, , . , — , . . , , .
d
d — , , , , . , :
Sab — ( ) . :
def pooled_standard_deviation(a, b):
'''
( )'''
return sp.sqrt( standard_deviation(a) ** 2 +
standard_deviation(b) ** 2)
, 6 - d :
def ex_2_28():
''' d
- 6'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(6)
return (b.mean() - a.mean()) / pooled_standard_deviation(a, b)
0.38913648705499848
p-, d . , , . 0.5, , , 0.38 — . - , -, .
, . , , z-, t- F-.
, , , . — , — . , , F- 1- 2- .
.
En la siguiente serie de publicaciones, si los lectores lo desean, aplicaremos lo que hemos aprendido sobre la varianza y la prueba F a muestras individuales. Presentaremos un método de análisis de regresión y lo usaremos para encontrar correlaciones entre variables en una muestra de atletas olímpicos.