La publicación # 3 para principiantes está dedicada a generar distribuciones, sus propiedades y gráficos para su análisis comparativo.
Baker y Poincaré
Existe una leyenda, casi con certeza apócrifa, que permite considerar con más detalle la cuestión de cómo el teorema del límite central permite razonar sobre el principio de formación de distribuciones estadísticas. Se trata del renombrado erudito francés del siglo XIX, Henri Poincaré, quien, cuenta la leyenda, pasaba un año todos los días pesando una hogaza de pan recién hecho.
En ese momento, el horneado estaba regulado por el Estado, y Poincaré constató que si bien los resultados del pesaje de las hogazas de pan obedecían a una distribución normal, el pico no estaba en el 1 kg anunciado públicamente, sino en 950 g. Informó a las autoridades sobre la panadero al que compraba pan con regularidad, y lo multaban. Esta es la leyenda ;-).
Al año siguiente, Poincaré siguió pesando hogazas de pan del mismo panadero. Descubrió que la media era ahora de 1 kg, pero que la distribución ya no era simétrica alrededor de la media. Ahora se ha desplazado hacia la derecha. Esto era coherente con el hecho de que el panadero ahora le estaba dando a Poincaré solo la más pesada de sus hogazas de pan. Poincaré volvió a denunciar al panadero a las autoridades y el panadero fue multado por segunda vez.
Si realmente lo fue o no, no es importante aquí; este ejemplo solo sirve para ilustrar un punto clave: la distribución estadística de una secuencia de números puede decirnos algo importante sobre el proceso que la creó.
Generando distribuciones
, , stats.norm.rvs. (rvs . normal variates, .. ). 1000, 1 . , 30.
def honest_baker(mu, sigma):
''' '''
return pd.Series( stats.norm.rvs(loc, scale, size=10000) )
def ex_1_18():
''' '''
honest_baker(1000, 30).hist(bins=25)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, :

, . ( « ») :
def dishonest_baker(mu, sigma):
''' '''
xs = stats.norm.rvs(loc, scale, size=10000)
return pd.Series( map(max, bootstrap(xs, 13)) )
def ex_1_19():
''' '''
dishonest_baker(950, 30).hist(bins=25)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, :
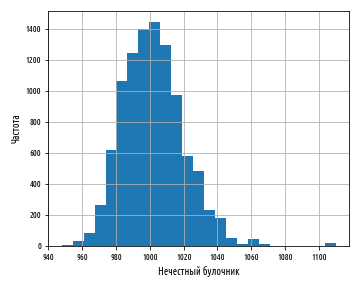
, , , . - 1 , . , .
. , , , . , , , .

pandas skew
:
def ex_1_20():
''' '''
s = dishonest_baker(950, 30)
return { '' : s.mean(),
'' : s.median(),
'': s.skew() }
{'': 0.4202176889083849,
'': 998.7670301469957,
'': 1000.059263920949}
, 0.4. , .
. , quantile
0 1 . 0.5- .
, . , -, Q-Q, . Q-Q plot. . , , . , .
. qqplot
, :
def qqplot( xs ):
''' ( -, Q-Q plot)'''
d = {0:sorted(stats.norm.rvs(loc=0, scale=1, size=len(xs))),
1:sorted(xs)}
pd.DataFrame(d).plot.scatter(0, 1, s=5, grid=True)
df.plot.scatter(0, 1, s=5, grid=True)
plt.xlabel(' ')
plt.ylabel(' ')
plt.title (' ', fontweight='semibold')
def ex_1_21():
'''
'''
qqplot( honest_baker(1000, 30) )
plt.show()
qqplot( dishonest_baker(950, 30) )
plt.show()
:

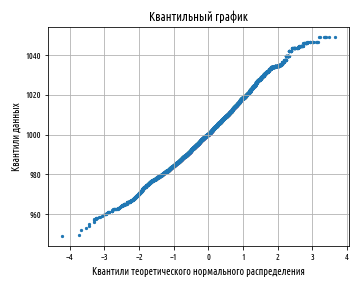
. :
, , , ; . , :

: , , , , ,
. ( ) .
() . , . , , .
, « », — , . :
def ex_1_22():
'''
'''
d = {' ' :honest_baker(1000, 30),
' ':dishonest_baker(950, 30)}
pd.DataFrame(d).boxplot(sym='o', whis=1.95, showmeans=True)
plt.ylabel(' (.)')
plt.show()
:

. — . — . , , . , .
. . , .
(), , . Cumulative Distribution Function (CDF), , , , x. , 0 1, 0 — , 1 — . , , . , 6?
5/6. , , , 1/6. — 50%.
, — , . , , , .
— . 0.5- 1000, 1000 0.5.
, pandas quantile
, empirical_cdf
0 1. , .. ( ) , , , , .
— , .
. pandas plot
, — — , . plot
, x y . pandas DataFrame
.
, plot
. pandas , . plot
, (ax
) plot
, (ax=ax
). . , . , (tp[1]
tp[3]
) , :
def empirical_cdf(x):
''' x'''
sx = sorted(x)
return pd.DataFrame( {0: sx, 1:sp.arange(len(sx))/len(sx)} )
def ex_1_23():
'''
'''
df = empirical_cdf(honest_baker(1000, 30))
df2 = empirical_cdf(dishonest_baker(950, 30))
ax = df.plot(0, 1, label=' ')
df2.plot(0, 1, label=' ', grid=True, ax=ax)
plt.xlabel(' ')
plt.ylabel('')
plt.legend(loc='best')
plt.show()
:
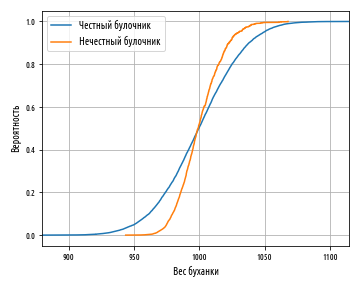
, -, , . , 0.5, 1000 . , .
, 4, «Python, » .