¡Buenas tardes queridos lectores! El material es de naturaleza teórica y está dirigido exclusivamente a analistas novatos que encontraron por primera vez la analítica de BI.
¿Qué se entiende tradicionalmente por este concepto? En términos simples, este es un sistema complejo (como, por ejemplo, presupuestación) para recopilar, procesar y analizar datos, presentando los resultados finales en forma de gráficos, tablas, tablas.
Esto requiere el trabajo bien coordinado de varios especialistas a la vez. El ingeniero de datos es responsable de los procesos de almacenamiento y ETL / ELT, el analista de datos ayuda a completar la base de datos, el analista de BI desarrolla paneles de control, el analista de negocios simplifica la comunicación con los clientes del informe. Pero esta opción solo es posible si la empresa está dispuesta a pagar por el trabajo del equipo. En la mayoría de los casos, las pequeñas empresas dependen de una persona para minimizar los costos, que a menudo no tiene una perspectiva amplia en el campo de BI, sino que solo tiene un conocimiento de la plataforma de informes.
En este caso, sucede lo siguiente: la recopilación, el procesamiento y el análisis de datos se produce por las fuerzas de una sola herramienta: la propia plataforma de BI. En este caso, los datos no se borran preliminarmente de ninguna manera, no pasan por los compuestos. La recolección de información proviene de fuentes primarias sin la participación de un almacenamiento intermedio. Los resultados de este enfoque se pueden ver fácilmente en foros temáticos. Si intenta resumir todas las preguntas relacionadas con las herramientas de BI, lo siguiente probablemente se incluirá entre las 3 principales: cómo cargar datos mal estructurados en el sistema, cómo calcular las métricas requeridas a partir de ellos, qué hacer si el informe se está ejecutando. muy lentamente. Sorprendentemente, en estos foros difícilmente encontrará discusiones sobre herramientas ETL, experiencias de almacenamiento de datos, mejores prácticas de programación y consultas SQL. Además, repetidamente me he encontrado con el hechoque los analistas de BI experimentados no hablaron de manera muy halagadora sobre el uso de R / Python / Scala, citando el hecho de que todos los problemas pueden resolverse solo por medio de la plataforma de BI. Al mismo tiempo, todos entienden que la ingeniería de fechas competente le permite solucionar muchos problemas al crear informes de BI.
-. , . -, , , -, .
«Data – BI» . . (-) (csv, txt, xlsx . .).
. . , . , , . BI .
. (, 1). , . ( , , . .). BI-, . .
«Data – DB – BI» , , . , , .
. , . . SQL ( ), BI-. .
. , . . . SQL.
«Data – ETL – DB – BI» . ETL- , R/Python/Scala . . . .
. , . . BI-.
. ETL- SQL. . , .
. «» SQLite. , (). E-Commerce Data Kaggle.
#
import pandas as pd
#
pd.set_option('display.max_columns', 10)
pd.set_option('display.expand_frame_repr', False)
path_dataset = 'dataset/ecommerce_data.csv'
#
def func_main(path_dataset: str):
#
df = pd.read_csv(path_dataset, sep=',')
#
list_col = list(map(str.lower, df.columns))
df.columns = list_col
# -
df['invoicedate'] = df['invoicedate'].apply(lambda x: x.split(' ')[0])
df['invoicedate'] = pd.to_datetime(df['invoicedate'], format='%m/%d/%Y')
#
df['amount'] = df['quantity'] * df['unitprice']
#
df_result = df.drop(['invoiceno', 'quantity', 'unitprice', 'customerid'], axis=1)
#
df_result = df_result[['invoicedate', 'country', 'stockcode', 'description', 'amount']]
return df_result
#
def func_sale():
tbl = func_main(path_dataset)
df_sale = tbl.groupby(['invoicedate', 'country', 'stockcode'])['amount'].sum().reset_index()
return df_sale
#
def func_country():
tbl = func_main(path_dataset)
df_country = pd.DataFrame(sorted(pd.unique(tbl['country'])), columns=['country'])
return df_country
#
def func_product():
tbl = func_main(path_dataset)
df_product = tbl[['stockcode','description']].\
drop_duplicates(subset=['stockcode'], keep='first').reset_index(drop=True)
return df_product
Extract Transform. , . . , , .
#
import pandas as pd
import sqlite3 as sq
from etl1 import func_country,func_product,func_sale
con = sq.connect('sale.db')
cur = con.cursor()
##
# cur.executescript('''DROP TABLE IF EXISTS country;
# CREATE TABLE IF NOT EXISTS country (
# country_id INTEGER PRIMARY KEY AUTOINCREMENT,
# country TEXT NOT NULL UNIQUE);''')
# func_country().to_sql('country',con,index=False,if_exists='append')
##
# cur.executescript('''DROP TABLE IF EXISTS product;
# CREATE TABLE IF NOT EXISTS product (
# product_id INTEGER PRIMARY KEY AUTOINCREMENT,
# stockcode TEXT NOT NULL UNIQUE,
# description TEXT);''')
# func_product().to_sql('product',con,index=False,if_exists='append')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale;
# CREATE TABLE IF NOT EXISTS sale (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country_id INTEGER NOT NULL,
# product_id INTEGER NOT NULL,
# amount REAL NOT NULL,
# FOREIGN KEY(country_id) REFERENCES country(country_id),
# FOREIGN KEY(product_id) REFERENCES product(product_id));''')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale_data_lake;
# CREATE TABLE IF NOT EXISTS sale_data_lake (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country TEXT NOT NULL,
# stockcode TEXT NOT NULL,
# amount REAL NOT NULL);''')
# func_sale().to_sql('sale_data_lake',con,index=False,if_exists='append')
## (sale_data_lake) (sale)
# cur.executescript('''INSERT INTO sale (invoicedate, country_id, product_id, amount)
# SELECT sdl.invoicedate, c.country_id, pr.product_id, sdl.amount
# FROM sale_data_lake as sdl LEFT JOIN country as c ON sdl.country = c.country
# LEFT JOIN product as pr ON sdl.stockcode = pr.stockcode
# ''')
##
# cur.executescript('''DELETE FROM sale_data_lake''')
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
round(s.amount,1) as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
print(select(sql))
cur.close()
con.close()
(Load) . . . , . .
SQL, . , BI-.
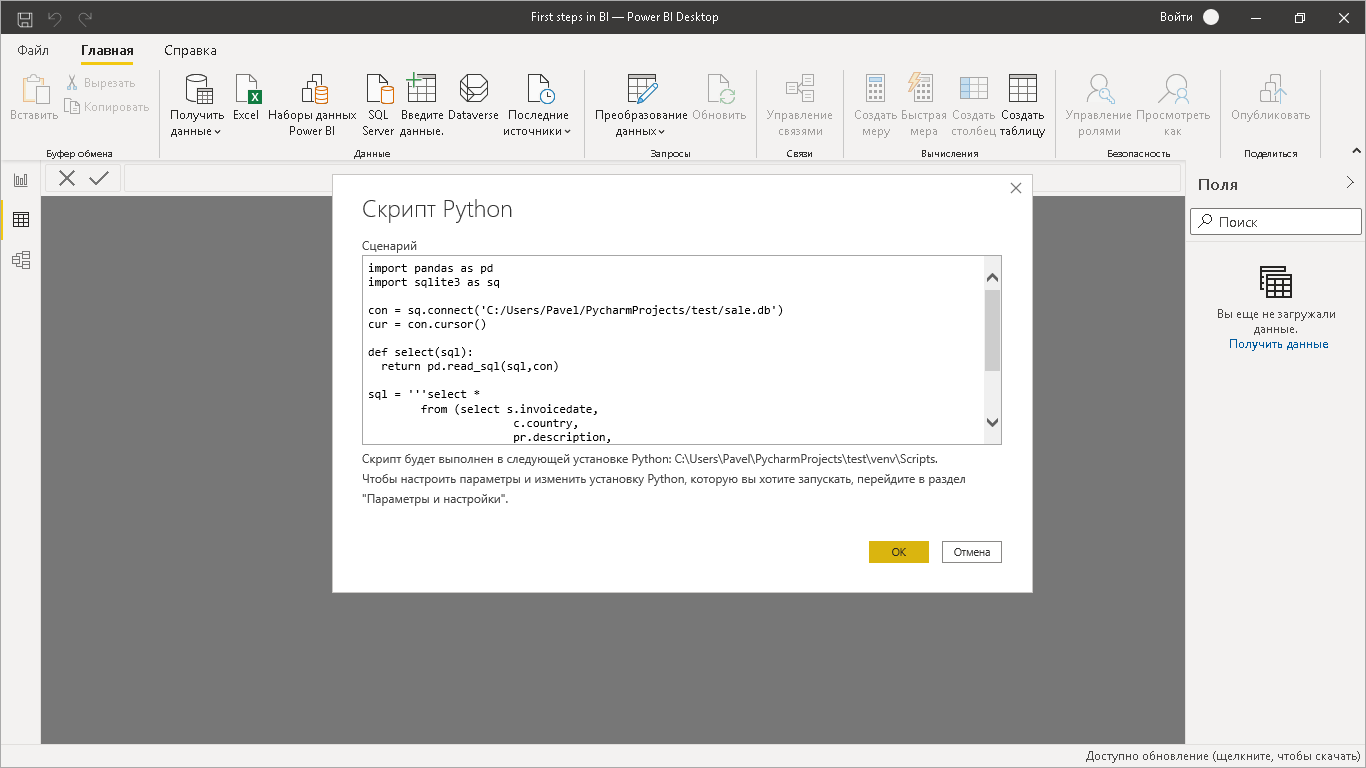
BI- SQLite Python.
import pandas as pd
import sqlite3 as sq
con = sq.connect('C:/Users/Pavel/PycharmProjects/test/sale.db')
cur = con.cursor()
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
replace(round(s.amount,1),'.',',') as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
tbl = select(sql)
print(tbl)
.
«Data – Workflow management platform + ETL – DB – BI» . .
. . .
. . BI. .
«Data – Workflow management platform + ELT – Data Lake – Workflow management platform + ETL – DB – BI» , : (Data Lake), (DB), .
. . , Data Lake.
. . Data Lake – , .
.
BI- .
BI , .
, SQL, - , , , .
Eso es todo. ¡Toda salud, buena suerte y éxito profesional!