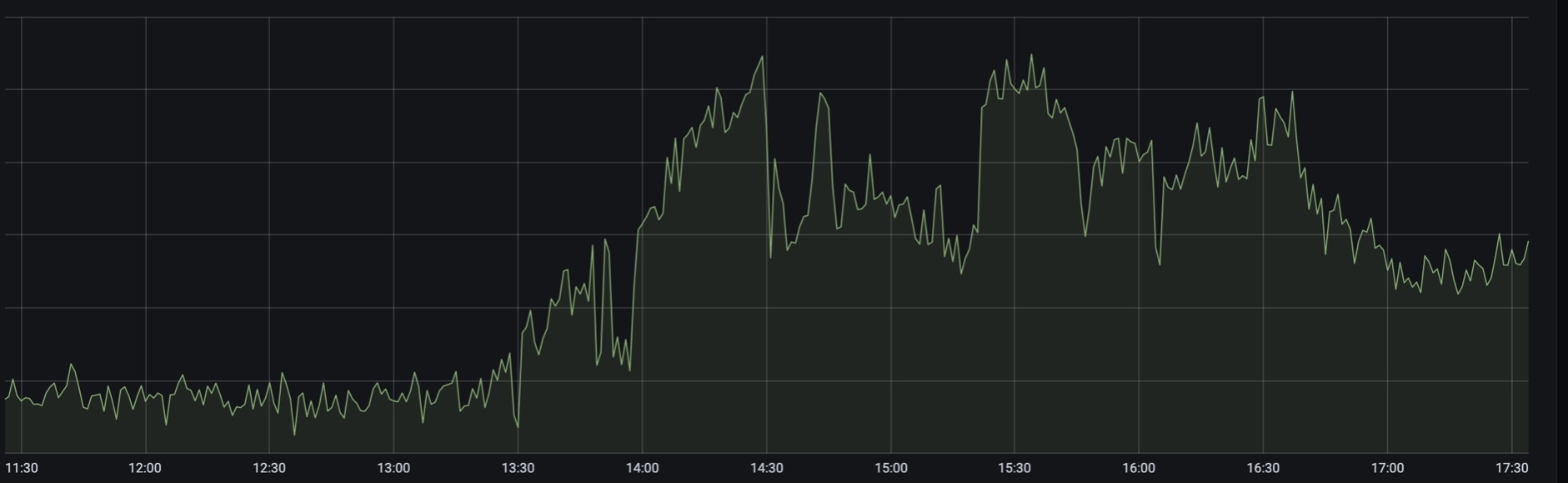
alrededor de la 1:30 pm, la carga en la búsqueda de aviación y boletos de tren aumentó drásticamente. En algún lugar en este momento, Russian Railways informó interrupciones en el sitio web y la aplicación, y comenzamos a verter urgentemente instancias adicionales de backends en todos los centros de datos.
Pero, de hecho, los problemas comenzaron antes. Aproximadamente a las 8 am, el monitoreo envió una alerta sobre el hecho de que en una de las réplicas de la base de datos tenemos algo sospechosamente muchos procesos de larga duración. Pero lo echamos de menos, lo consideramos poco importante.
Introductorio
Nuestra infraestructura ha crecido significativamente durante casi veinte años de desarrollo. Las aplicaciones viven en tres plataformas: el antiguo código php en un monolito , la primera versión de microservicios está en una plataforma con orquestación propia, la segunda, estratégicamente correcta, es OKD, donde viven los servicios go, php y nodejs. Alrededor de todo esto, docenas de bases mysql con un enlace para HA, la "guirnalda" principal que sirve al monolito, y muchos pares master-hotstandby para microservicios. Además de ellos, memkesh, kafkas, mongas, rábanos, elásticos, también están lejos de ser una sola copia. Nginx y envoy como frontproxy . Todo vive en tres ubicaciones de red y partimos del supuesto de que la pérdida de alguna de ellas no afecta a los usuarios.
-: mysql
Tenemos tres productos cargados. El horario de los trenes, donde hay mucho tráfico de entrada. El horario ferroviario para trenes de larga distancia y la compra y reserva de billetes de tren: hay mucho tráfico y la búsqueda es más difícil. Aviación con búsquedas muy difíciles, caché multietapa, muchas opciones por traspasos y bifurcaciones "más o menos 3 días". Hace mucho tiempo, los tres productos vivían solo en un monolito, y luego comenzamos a mover lentamente partes individuales en microservicios. Los primeros en ser desmantelados fueron los trenes eléctricos, y, a pesar de que suele caer sobre ellos el pico de mayo, la nueva arquitectura es muy cómoda y fácil de escalar al crecimiento de la carga. En el caso de la aviación, la mayor parte del monolito fue robado, y justo en el momento del día P, las pruebas A / B del sabio de la geografía se llevaban a cabo durante una semana. Comparamos dos versiones de la implementación: una nueva,en elasticsearch y el antiguo mysql. En el momento de su lanzamiento, el 15 de abril, ya habían detectado un montón de problemas, pero luego se concibieron rápidamente, corrigieron el código y decidieron que no volvería a dispararse.
Disparo. Cabe señalar que la versión anterior es su propia implementación de búsqueda de texto completo y clasificación en mysql. No es la mejor solución, pero ha sido probada por el tiempo y en su mayoría funciona. Los problemas comienzan cuando alguna de las tablas está muy fragmentada, luego todas las consultas con su participación comienzan a ralentizarse y a cargar mucho el sistema. Y, obviamente, a las 8 de la mañana cruzamos este umbral de fragmentación, que fue informado por la alerta. La reacción estándar a una situación tan rara, pero aún esperada, es sacar una réplica aburrida de la carga (con nuestra capa de proxy de proxysql, esto es fácil de hacer), luego ejecutar optimizar + analizar y luego devolverlo. Teniendo en cuenta la reserva de energía durante tiempos normales bajo carga normal, esto no da lugar a ningún problema. Pero aquí, en un momento de tranquilidad, no procesamos esta alerta.
13:20
Por esta época suena la noticia sobre las vacaciones de mayo y días no laborables.
Tráfico pico alrededor de las 13:30
Como descubrimos más tarde, apenas unos minutos después del anuncio del fin de semana adicional (que no es un fin de semana, sino un “fin de semana”), el tráfico comenzó a crecer. La carga se fue abruptamente. En el pico estaba entre 2,5 y 3 veces de la norma, y esto continuó durante varias horas.
Casi de inmediato fuimos bombardeados con "alertas de emergencia" - alertas del nivel de criticidad "despertar y arreglar". En primer lugar, fue una alerta sobre el crecimiento de 50 * errores que enviamos a los clientes desde nuestro frontproxy. En un nivel inferior, se activó una alerta por errores de conexión de la base de datos y en los registros vimos algo como esto: "DB: Se alcanzó el tiempo de espera máximo de conexión al alcanzar el grupo de hosts 102 después de 3162ms". Además alerta sobre la falta de capacidad en los tres grupos de servidores de aplicaciones de la antigua plataforma monolítica. Alerta de tormenta en su forma más pura.
La idea de las razones surgió casi instantáneamente, incluso antes de ingresar al horario con las solicitudes entrantes: la noticia sobre las "vacaciones" ya había aparecido en la correspondencia interna en los chats.
Habiendo recuperado un poco el sentido en una situación de Achtung casi completa, comenzaron a reaccionar. Escale los servidores de aplicaciones, trate los errores en la interfaz entre la aplicación y la base. Rápidamente recordamos la alerta que había estado “ardiendo” en la mañana y encontramos a nuestros viejos conocidos de la geografía entristecidos en la lista de procesos del comentario enfermo. Nos pusimos en contacto con el equipo de avia y nos confirmaron que el crecimiento del tráfico en los últimos días de abril, que ni siquiera se ha acercado durante los últimos 15 años, es real. Y esto no es un ataque, no es una especie de problema de equilibrio, sino usuarios naturales en vivo. Y bajo sus animadas solicitudes, nuestra réplica ya sobrecargada se volvió completamente enferma.
Alexey, nuestro DBA, sacó la réplica de la carga, definió los procesos de larga duración y siguió el procedimiento estándar de optimización de tablas. Todo esto es rápido, un par de minutos, pero durante este tiempo, con tal tráfico, las réplicas restantes empeoraron aún más. Entendimos esto, pero lo elegimos como el menor de los males.
Casi en paralelo, alrededor de las 13:40, comenzaron a verterse nuevos servidores de aplicaciones, dándose cuenta de que esta carga no es algo que no desaparezca rápidamente por sí solo, sino que puede crecer, y el proceso en sí para la parte monolítica no es muy rapido.
La manipulación de la base ayudó durante un tiempo. Aproximadamente desde la 1:50 pm hasta las 2:30 pm, todo estuvo en calma.
Segundo pico - alrededor de las 14:30
En ese momento, el seguimiento nos informó que el sitio web de Russian Railways estaba caído. Bueno, eso es, de hecho, dijo que los backends del tren empeoraron, y nos enteramos de Russian Railways más tarde, cuando salió la noticia . En tiempo real, nos pareció así.

La carga parece estar relacionada con interrupciones en el sitio web de Russian Railways
. Desafortunadamente, la mayoría de los trenes todavía viven en un monolito y solo se pueden escalar a nivel de aplicación agregando nuevos backends. Y esto, como escribí anteriormente, es un procedimiento lento y difícil de acelerar. Por lo tanto, solo quedaba esperar a que funcionaran las automáticas ya iniciadas. En microservicios todo es mucho más sencillo, claro, pero el movimiento en sí ... aunque esa es otra historia.
La espera no fue aburrida. En aproximadamente 5 minutos, el cuello de botella del sistema de alguna manera aún no del todo clara "empujó" desde la capa de la aplicación a la capa de la base de datos, ya sea a la base misma o al proxy. Y a las 14:40, habíamos dejado de escribir por completo en el clúster principal de mysql. Lo que sucedió exactamente allí, aún no lo hemos descubierto, pero cambiar el maestro a la reserva de emergencia ayudó. Y después de 10 minutos devolvimos el registro. Casi al mismo tiempo, decidieron transferir a la fuerza toda la carga del sillín al elástico, sacrificando los resultados de la campaña AB. Tampoco se dieron cuenta de cuánto ayudó, pero ciertamente no empeoró.
15:00
La grabación cobró vida, parece que todo debería estar bien, y la carga en las réplicas y en proxysql frente a ellas es normal. Pero por alguna razón, los errores durante las solicitudes de lectura de la aplicación a la base de datos no terminan. En aproximadamente 15 a 20 minutos de apegarnos a gráficos en diferentes capas y buscar al menos algunos patrones, nos dimos cuenta de que los errores provienen de un solo proxysql. Lo reinicié y los errores desaparecieron. La causa raíz se desenterró mucho más tarde, con un análisis detallado de la falla. Resultó que durante la última emergencia, una semana antes, durante el inicio de la campaña de AB sobre sagest, proxysql no cerró correctamente las conexiones con una de las réplicas de la guirnalda, que luego fue manipulada. Y en esta instancia de proxysql, estúpidamente nos encontramos con una falta de puertos para el tráfico saliente. Esta métrica, por supuesto, va a funcionar, pero nunca se nos ocurrió colgar una alerta sobre ella. Ahora ya está ahí.
15:20
Todos los productos fueron restaurados, excepto los trenes.
15:50
Se ampliaron los últimos backends del tren. Por lo general, no toma dos horas, sino una hora, pero aquí ellos mismos se equivocaron un poco en una situación estresante.
Como suele suceder, se reparó en un lugar y se rompió en otro. Los backends comenzaron a aceptar más conexiones, los front-proxies comenzaron a eliminar menos las solicitudes de los clientes debido al desbordamiento de los upstreams, como resultado, aumentó el tráfico interno entre servicios. Y había un servicio de autorización. Este es un microservicio, pero no en OKD, sino en una plataforma antigua. El escalado es más simple que en monolito, pero peor que en OKD. Lo levantamos durante unos 15 minutos, torciendo los parámetros varias veces y agregando capacidades, pero al final también funcionó.
16:10
Hurra, todo está funcionando, puedes ir a almorzar.
Bellas imágenes
Son hermosos porque no son completamente informativos, pero el Consejo de Seguridad no ha probado los ejes.
Gráfico de los 500:

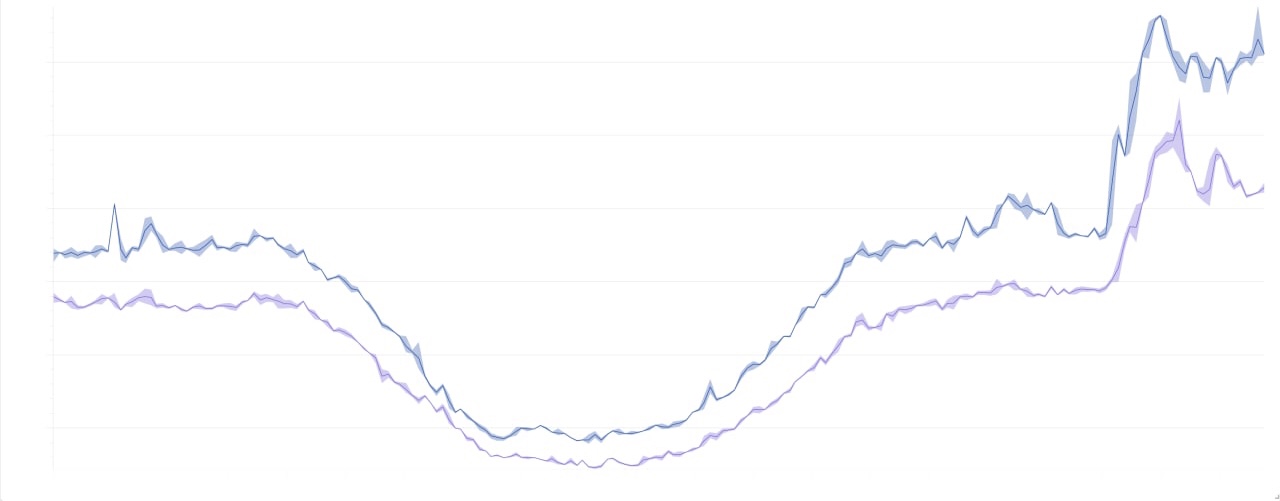
El panorama general de la carga durante 2 días:
Conclusiones del capitán
- Gracias por no esta noche.
- Debes hacer algo con las alertas. Ya hay muchos, pero, por un lado, a veces todavía no es suficiente, y por otro lado, algunos están agotados, incluso por la cantidad. Y el costo del soporte aumenta con cada nueva alerta. En general, todavía hay una comprensión del problema, pero no hay una solución estratégica. Se esconde en algún lugar del cruce de procesos y herramientas que estamos buscando. Pero ya hemos abordado un par de alertas tácticamente.
- . , - proxysql , . , .
- , OKD . .
- . , , , .