Hoy te diré por qué la entrega subcontratada no siempre es buena, por qué necesitas transparencia en los procesos y cómo escribimos una plataforma en un año y medio que ayuda a nuestros mensajeros a entregar los pedidos. También compartiré tres historias del mundo del desarrollo.

En la foto aparece el equipo de la plataforma de mensajería hace diez meses. En esos días, la colocaron en una habitación. Ahora somos 5 veces más.
¿Por qué hicimos todo esto?
Al desarrollar la plataforma de mensajería, queríamos actualizar tres cosas principales.
La primera es la calidad . Cuando trabajamos con servicios de entrega externos, no se puede controlar la calidad. La empresa contratista promete que habrá tal o cual capacidad de entrega, pero es posible que no se entregue un cierto número de pedidos. Y queríamos reducir el porcentaje de retrasos al mínimo, para que casi cualquier pedido se entregara a tiempo.
El segundo es la transparencia... Cuando algo sale mal (hay transferencias, plazos), entonces no sabemos por qué sucedieron. No podemos ir y decir: "Chicos, hagámoslo así". Nosotros mismos no vemos y no podemos mostrarle al cliente ninguna cosa adicional. Por ejemplo, que el pedido no llegará a las ocho, sino en 15 minutos. Esto se debe a que no existe tal nivel de transparencia en el proceso.
El tercero es dinero... Cuando trabajamos con un contratista, existe un contrato que detalla los montos. Y podemos cambiar estos números en el marco del contrato. Y cuando somos responsables de todo el proceso de la A a la Z, entonces puede ver qué partes del sistema están diseñadas económicamente no rentables. Y puede, por ejemplo, cambiar el proveedor de SMS o el formato de flujo de documentos. O puede notar que los mensajeros tienen un kilometraje demasiado alto. Y si construye rutas más de cerca, al final podrá entregar más pedidos. Gracias a esto, también puede ahorrar dinero: la entrega será más eficiente.
Estos fueron los tres objetivos que nos pusimos a la cabeza de todo.
Cómo se ve la plataforma
Veamos qué tenemos.
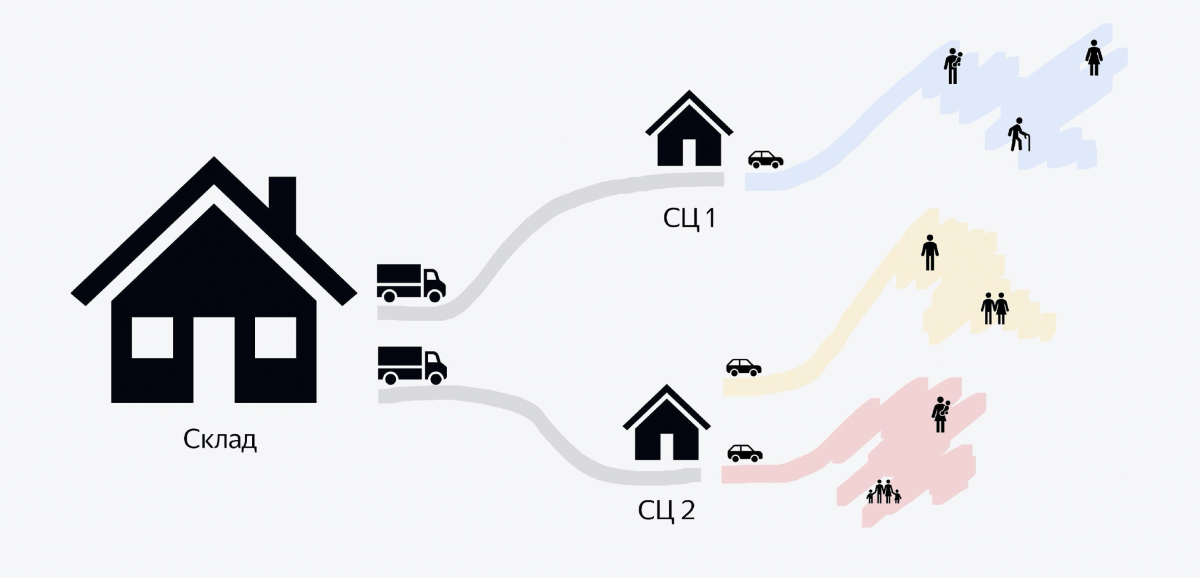
La imagen muestra un diagrama del proceso. Disponemos de grandes almacenes con capacidad para cientos de miles de pedidos. Los camiones llenos hasta el borde con pedidos salen de cada almacén por la noche. Puede haber entre 5 y 6 mil pedidos. Estos camiones viajan a edificios más pequeños llamados centros de clasificación. En ellos, en pocas horas, una gran pila de pedidos se convierte en pequeñas pilas para los mensajeros. Y cuando los mensajeros llegan en automóviles por la mañana, cada mensajero sabe que necesita recoger un montón con este código QR, cargarlo en su automóvil e ir a entregar.
Y el backend del que quiero hablar en este artículo es sobre la última parte del proceso cuando los pedidos se llevan a los clientes. Todo lo que está antes de esto, por el momento, lo dejaremos de lado.
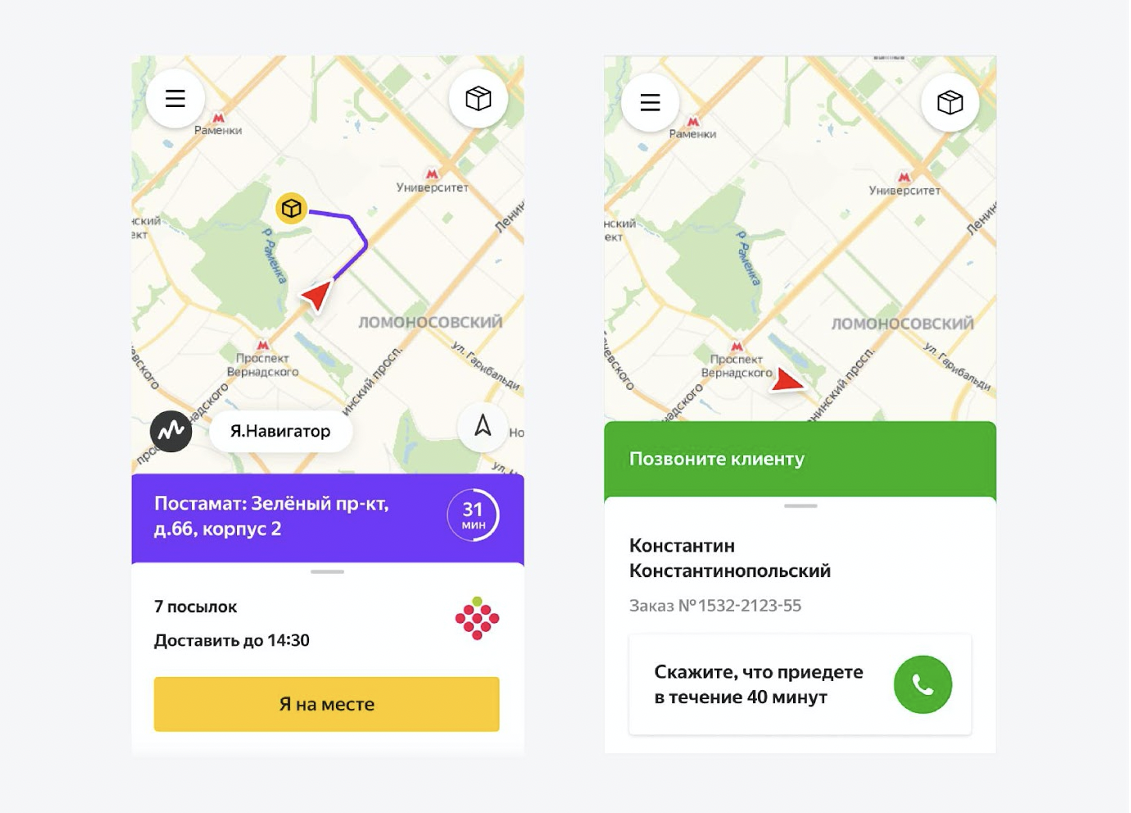
Cómo lo ve el mensajero Los mensajeros
tienen una aplicación de Android escrita en React Native. Y en esta aplicación, ven todo su día. Entienden claramente la secuencia: a qué dirección ir primero, a cuál después. Cuándo llamar a un cliente, cuándo llevar devoluciones al centro de clasificación, cómo empezar el día, cómo finalizarlo. Ven todo en la aplicación y prácticamente no hacen preguntas innecesarias. Les ayudamos mucho. Básicamente, solo están haciendo asignaciones.
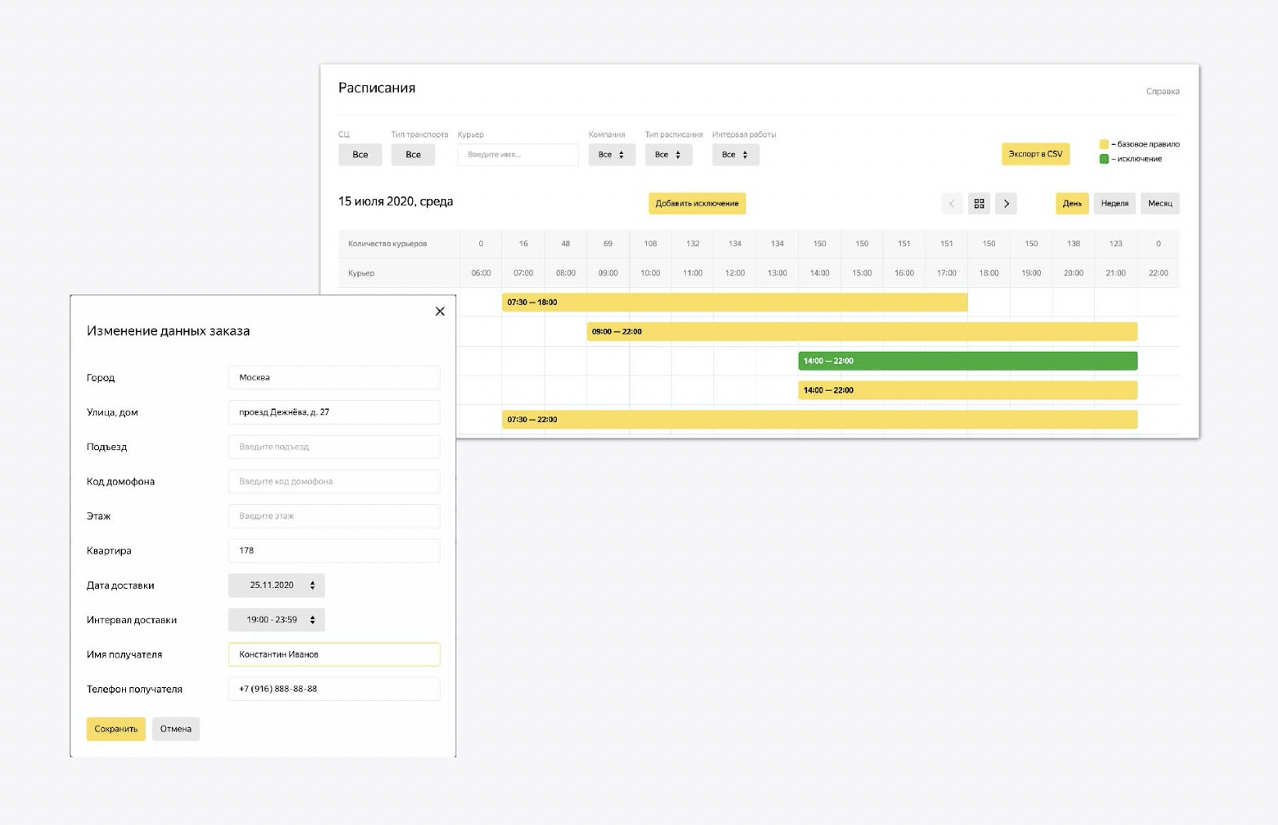
Además, hay controles en la plataforma. Este es un panel de administración multifuncional que reutilizamos de otro servicio de Yandex. En esta área de administración, puede configurar el estado del sistema. Subimos datos sobre nuevos mensajeros allí, cambiamos los intervalos de trabajo. Podemos ajustar el proceso de creación de tareas para mañana. Casi todo lo que necesita está regulado.
Por cierto, sobre el backend. En el mercado amamos mucho Java, sobre todo la versión 11. Y todos los servicios de backend, que se discutirán, están escritos en Java.
Arquitectura
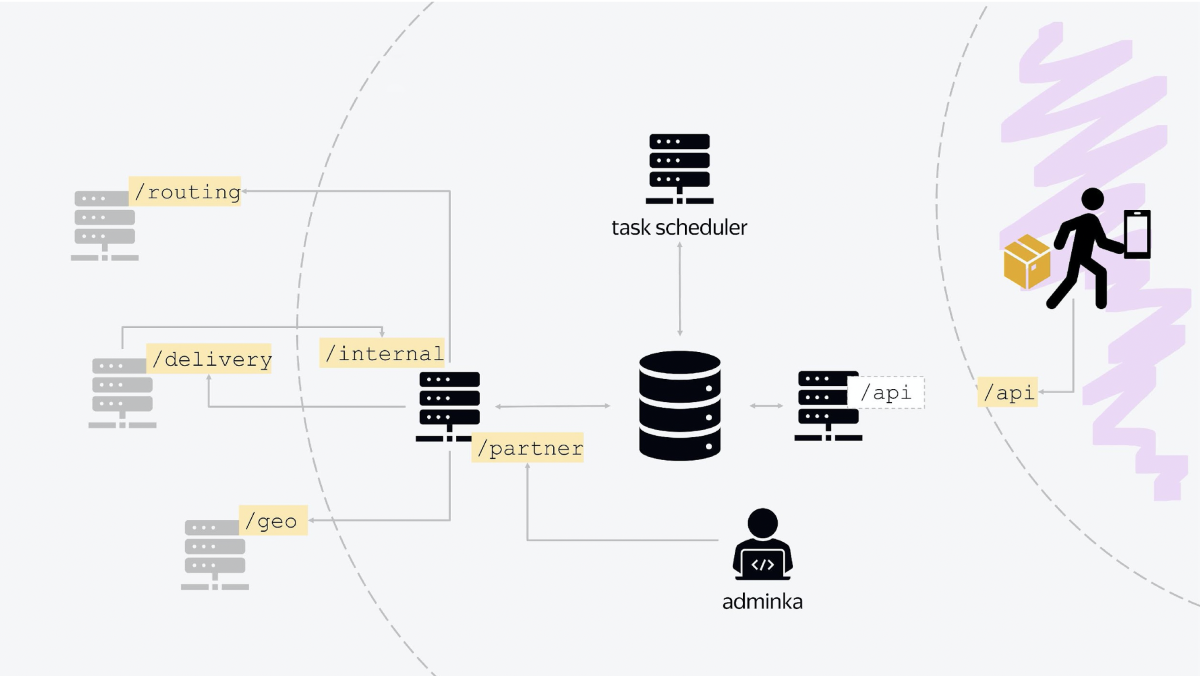
Hay tres nodos principales en la arquitectura de nuestra plataforma. El primero es responsable de la comunicación con el mundo exterior. La aplicación de mensajería "golpea" al equilibrador, que se activa y se comunica con él mediante la API HTTP estándar de JSON. De hecho, este nodo es responsable de toda la lógica del día actual, cuando los mensajeros transfieren algo, cancelan algo, emiten pedidos, reciben nuevas tareas.
El segundo nodo es un servicio que se comunica con los servicios internos de Yandex. Todos los servicios son servicios RESTful clásicos con comunicación estándar. Cuando realices un pedido en el Market, al cabo de un tiempo te llegará un documento en formato JSON, donde estará todo escrito: cuándo entregamos, a quién entregamos, en qué intervalo. Y guardaremos este estado en la base de datos. Es sencillo.
Además, el segundo nodo también se comunica con otros servicios internos, no Market, sino Yandex. Por ejemplo, para aclarar geocoordenadas, vamos al geoservicio. Para enviar una notificación push, nos dirigimos al servicio que envía push y SMS. Usamos otro servicio para la autorización. Otro servicio para calcular el enrutamiento del mañana. Así, se realiza toda la comunicación con los servicios internos.
Este nodo también es un punto de entrada, tiene una API a la que llama nuestro panel de administración. Tiene su propio punto final, que se llama, digamos, / socio. Y nuestro panel de administración, todo el estado del sistema, se configura a través de la comunicación con este servicio.
El tercer nodo es la base de tareas en segundo plano. Aquí se utiliza Quartz 2, hay tareas que se lanzan en la corona con diferentes condiciones para diferentes puntos, para diferentes centros de clasificación. Hay tareas de actualizar el día, tareas de cerrar el día, comenzar un nuevo día.
Y en el centro de todo está la base de datos, que, de hecho, almacena todo el estado. Todos los servicios están incluidos en una base de datos.
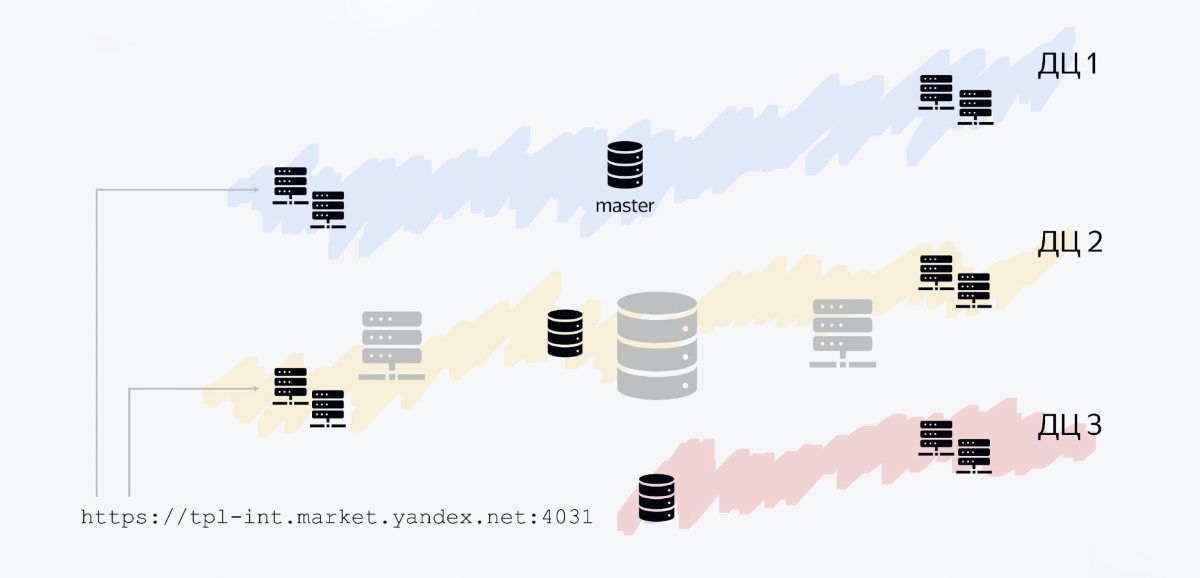
Tolerancia a fallos
Yandex tiene varios centros de datos y nuestro servicio se distribuye regionalmente en tres centros de datos. Qué aspecto tiene.
La base de datos consta de tres hosts, cada uno en su propio centro de datos. Un anfitrión es el maestro, los otros dos son réplicas. Le escribimos al maestro, leemos de las líneas. Todos los demás servicios de Java también son procesos de Java que se ejecutan en varios centros de datos.
Uno de los nodos es nuestra API. Se ejecuta en los tres centros de datos, porque el flujo de mensajes es mayor que el de los servicios internos. Además, este diseño le permite escalar horizontalmente con bastante facilidad.
Por ejemplo, si su tráfico entrante aumenta nueve veces, puede optimizar, pero también puede "inundar" este negocio con hierro abriendo más nodos que procesarán el tráfico entrante.
El equilibrador simplemente tendrá que dividir el tráfico en una mayor cantidad de puntos que satisfagan las solicitudes. Y ahora, por ejemplo, no tenemos un nodo, sino dos nodos en cada centro de datos.
Nuestra arquitectura nos permite hacer frente incluso a casos como el cierre de uno de los centros de datos. Por ejemplo, decidimos realizar un ejercicio y apagamos el centro de datos en Vladimir, y nuestro servicio permanece a flote, nada cambia. Los hosts de la base de datos que se encuentran allí desaparecen y el servicio permanece en funcionamiento.
El equilibrador entiende después de un tiempo: sí, no me queda ni un solo host en vivo en este centro de datos, y ya no redirige el tráfico allí.
Todos los servicios en Yandex están organizados de manera similar, todos sabemos cómo sobrevivir a la falla de uno de los centros de datos. Ya hemos descrito cómo se implementa esto, qué es la degradación elegante y cómo los servicios de Yandex manejan el cierre de uno de los centros de datos .
Así que eso era arquitectura. Y ahora comienzan las historias.
La primera historia: sobre Yandex.Rover
Recientemente tuvimos otra conferencia, en la que se prestó mucha atención a Rover. Continuaré con el tema.
Una vez, los chicos del equipo de Yandex.Rover se acercaron a nosotros y se ofrecieron a probar la hipótesis de que la gente querría recibir pedidos de una manera tan extraordinaria.
Yandex.Rover es un pequeño robot del tamaño de un perro promedio. Puede poner comida allí, un par de cajas de pedidos; él recorrerá la ciudad y traerá pedidos sin ayuda humana. Hay un lidar, el robot comprende su posición en el espacio. Sabe cómo entregar pequeños pedidos.
Y pensamos: ¿por qué no? Aclaramos los detalles del experimento: en ese momento era necesario probar la hipótesis de que a la gente le gustaría. Y decidimos entregar 50 pedidos en una semana y media en un modo muy ligero.
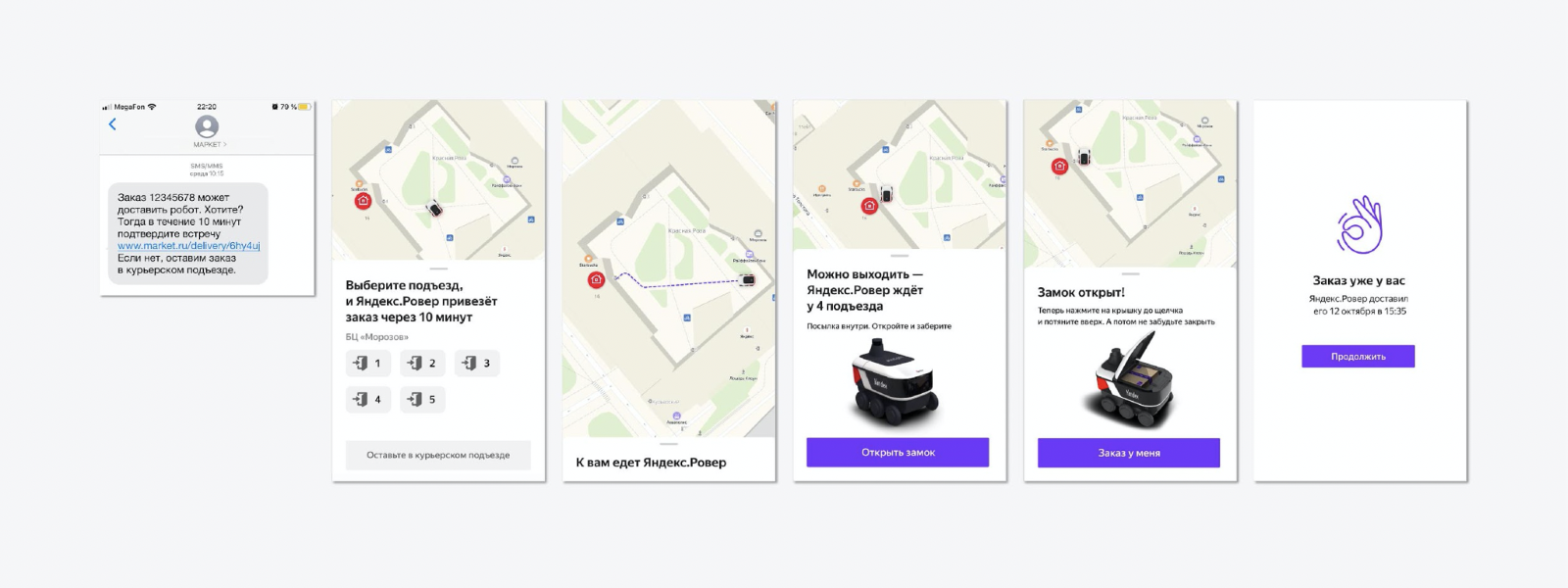
Se nos ocurrió el flujo más simple, cuando una persona recibe un SMS con una propuesta para un método de entrega no estándar, no el mensajero lo traerá, sino el Rover. Todo el experimento tuvo lugar en el patio de Yandex. El hombre estaba eligiendo la entrada por la que llegaría el Rover. Cuando llegó el robot, se abrió la tapa, el cliente tomó el pedido, cerró la tapa y Rover salió para un nuevo pedido. Es sencillo.
Luego fuimos al equipo de Rover para negociar una API.
Hay métodos simples en la API de Rover: abrir la tapa, cerrar la tapa, ir a cierto punto, obtener un estado. Clásico. También JSON. Muy simple.
Lo que también es muy importante: tanto las historias pequeñas como las grandes se hacen mejor a través de las banderas de características. De hecho, tiene un interruptor mediante el cual puede habilitar esta historia en producción. Cuando ya no lo necesite, el experimento se completó con éxito o no, o notó algunos errores, simplemente elimínelo. Y no necesita hacer otra implementación de la nueva versión del código para producción. Esto hace la vida mucho más fácil.
Parecería que todo es simple y todo debería funcionar. Incluso no hay nada que desarrollar allí durante dos semanas, puedes hacerlo en unos días. Pero mira dónde está enterrado el perro.
Todos los procesos son en su mayoría sincrónicos. El hombre presiona un botón, la tapa se abre. El hombre presiona el botón, la tapa se cierra. Pero uno de estos procesos es asincrónico. En el momento en que el Rover se dirige hacia usted, debe tener algún tipo de proceso en segundo plano que rastree que el robot ha regresado al punto.
Y en este momento enviaremos un SMS a la persona, por ejemplo, que el Rover está esperando en el lugar. Esto no se puede hacer de forma sincrónica y es necesario resolver este problema de alguna manera.
Hay muchos enfoques diferentes. Lo hemos hecho lo más simple posible.
Decidimos que podemos ejecutar el hilo o tarea Java en segundo plano más común en Executer. Este hilo de fondo se lanza inmediatamente para rastrear el proceso. Y tan pronto como finalice el proceso, enviamos una notificación.
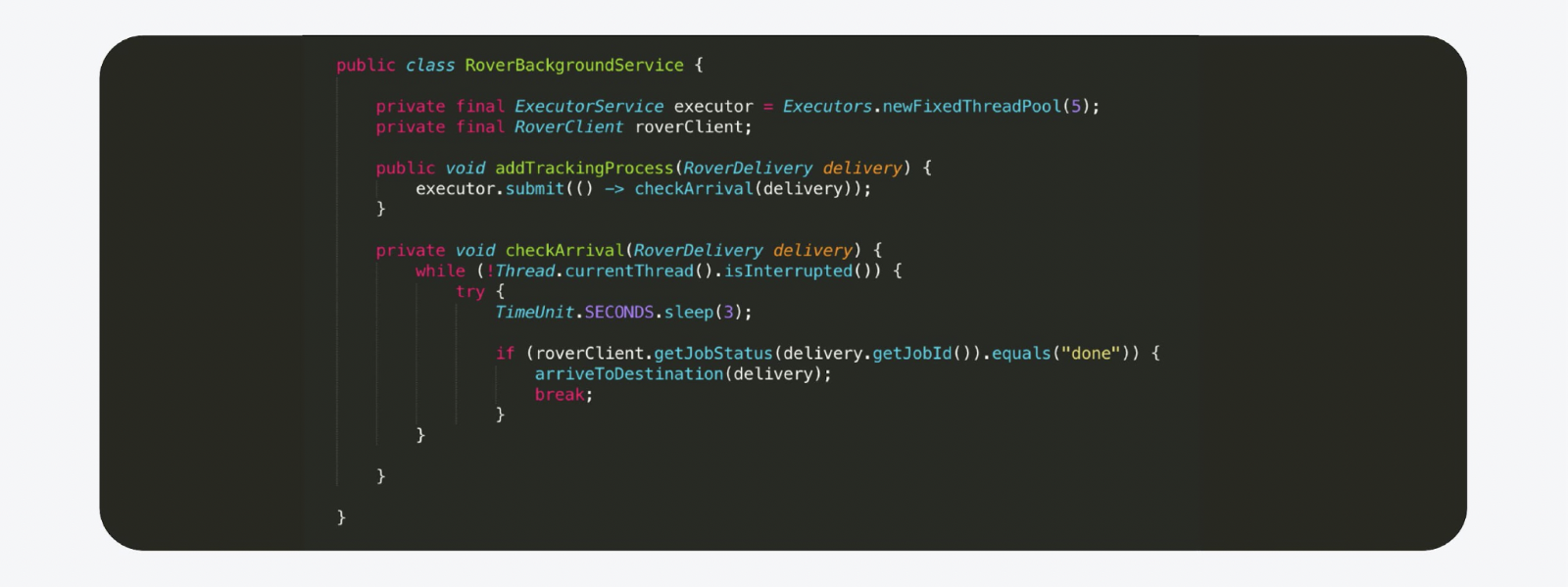
Por ejemplo, tiene este aspecto. Esto es prácticamente una copia del código de producción, con la excepción de los comentarios eliminados. Pero hay una trampa. No se pueden hacer sistemas serios de esta manera. Digamos que estamos lanzando una nueva versión al backend. El host se reinicia, el estado se pierde, y eso es todo, el Rover va al infinito, nadie más lo ve.
¿Pero por qué? Si sabemos que nuestro objetivo es entregar 50 pedidos en una semana y media, elegimos el momento en el que monitoreamos el backend. Si algo sale mal, puede cambiar algo manualmente. Para tal tarea, esta solución es más que suficiente. Y esta es la moraleja de la primera historia.
Hay situaciones para las que es necesario realizar la versión mínima de la funcionalidad. No hay necesidad de cercar un jardín y sobre ingeniería. Es mejor hacerlo lo más alienado posible. Para no cambiar demasiado la lógica de los objetos internos. Y el exceso de complejidad, la deuda técnica innecesaria no se acumuló.
La segunda historia: sobre bases de datos
Pero primero, algunas palabras sobre cómo se organizan las entidades principales. Existe un servicio Yandex.Routing que crea rutas para los mensajeros al final del día.
Cada ruta consta de puntos en el mapa. Y en cada punto los mensajeros tienen una tarea. Esta puede ser una tarea para emitir un pedido o llamar a un cliente, o por la mañana cargar en el centro de clasificación, recoger todos los pedidos.
Además, los clientes reciben un enlace de seguimiento por la mañana. Pueden abrir el mapa y ver cómo viaja el mensajero hasta ellos. El cliente también puede elegir la entrega por Rover, que mencioné anteriormente.
Ahora veamos cómo se pueden mostrar estas entidades en la base de datos. Esto se hace, por ejemplo, así.
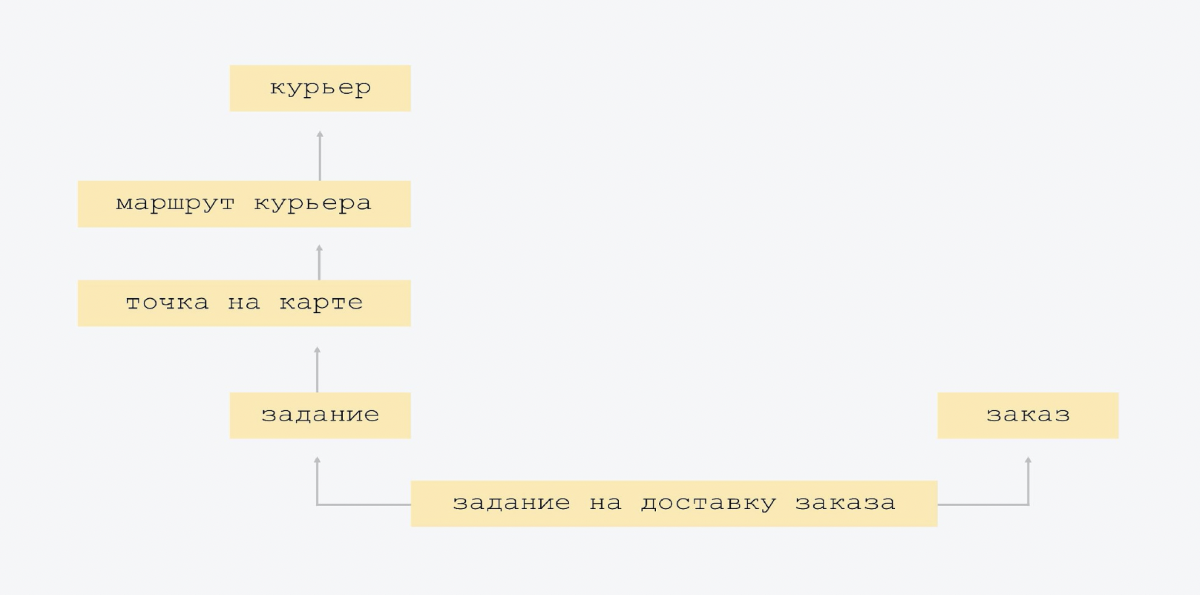
Este es un modelo de datos muy ordenado. No inventamos una sola entidad nueva y no colapsamos fuertemente las existentes.
El diagrama muestra que la flecha de abajo hacia arriba muestra la ruta del mensajero, conoce al mensajero cuya ruta es. El letrero de ruta de mensajería contiene el enlace de identificación de mensajería. Y la placa superior no lo sabe. Tenemos la conectividad más simple, no hay una gran intersección de entidades. Cuando todos conocen a todos, es más difícil de controlar y, muy probablemente, habrá redundancia. Por lo tanto, tenemos el esquema más simple posible.
La única "exageración" que hicimos al principio de la creación de la plataforma es esta. Tuvimos un tipo de asignación de entrega. Pero nos dimos cuenta de que en el futuro habrá otras tareas. Y ponemos un poco de flexibilidad arquitectónica: tenemos tareas, y uno de los tipos de tareas es la entrega de pedidos.
Luego agregamos seguimiento y Rover. Solo dos tabletas. En rastreo, el mensajero envía sus coordenadas, las registramos en una placa aparte. Y hay seguimiento de pedidos con su propio modelo de estado, hay cosas adicionales, como "SMS dejado / no desaparecido". No debe agregar esto directamente a la tarea. Es mejor ponerlo en un plato aparte, porque este seguimiento no es necesario para todo tipo de tareas.
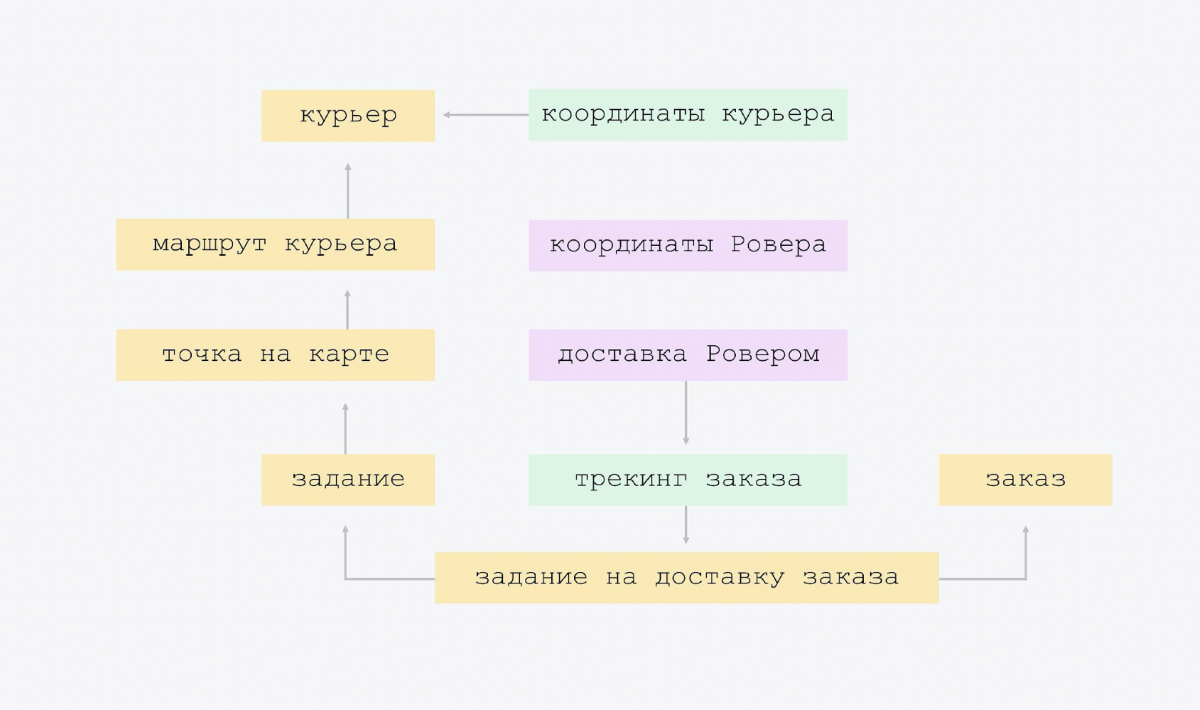
En Rover: sus coordenadas y entrega. Nuestra entrega por Rover es como rastrear para Rover. Puede agregarlo al pedido de seguimiento, pero ¿por qué? Después de todo, cuando nos deshagamos de este experimento, cuando se apague, estas opciones permanecerán para siempre en la esencia del seguimiento. Habrá campos nulos.
Puede surgir la pregunta: ¿por qué hacer una placa con coordenadas? One Rover entrega cinco pedidos al día. No necesita almacenar coordenadas en la base de datos, puede ir a la API de Rover y obtenerlas en tiempo de ejecución.
La conclusión es que esto se hizo inicialmente. Este letrero no estaba allí, inmediatamente fuimos al servicio y lo tomamos todo. Pero durante las pruebas, vimos que muchas personas abren un mapa con un Rover rodante y la carga en este servicio aumenta muchas veces. Digamos que lo abrieron siete personas. Y allí, en la página, cada dos segundos, Java Script solicita coordenadas. Y los colegas nos escribieron en el chat: “¿De dónde viene tal carga? Tienes una persona ahí para patinar ".
Y después de eso agregamos una señal. Allí comenzamos a sumar las coordenadas, la hora en que fueron recibidas. Y ahora, si la gente viene a nosotros con demasiada frecuencia para pedir coordenadas y no han pasado dos segundos desde el último recibo, los sacamos del plato. Resulta un caché de este tipo a nivel de base de datos.
Esta historia se podría hacer con 20 mesas. Se pueden utilizar dos tablas: mensajería y pedido. Pero en el primer caso, sería un exceso de ingeniería y, en el segundo, sería demasiado difícil de mantener. Lógica compleja, difícil de probar.
Y además. La estructura de las bases de datos, que hicimos hace año y medio, el núcleo de estas entidades se ha mantenido invariable hasta el día de hoy. Y tuvimos mucha suerte de poder elegir esas entidades en las que la base no tuvo que ser rehecha. No hubo necesidad de rediseñar significativamente las bases de datos, realizar migraciones complejas, luego lanzar esta versión, probarla durante mucho tiempo y luego cambiar la estructura raíz.
El punto de la historia es que hay aspectos a los que es mejor prestar especial atención. El primero es preste especial atención a la estructura de la API y la base de datos . Trate de notar qué tipo de entidades tiene en la vida real. Intente digitalizar esta estructura de la misma manera. Trate de no acortarlo demasiado, de no expandirlo demasiado.
En segundo lugar, hay errores que son costosos de corregir . Los errores a nivel de API son más difíciles de corregir que los errores a nivel de base de datos porque normalmente hay muchos clientes que utilizan la API. Y cuando cambias mucho la API, tienes que:
- llegar a todos los clientes, garantizar la compatibilidad con versiones anteriores;
- implementar la nueva API, cambiar todos los clientes a la nueva API;
- recorta el código antiguo sobre clientes, recorta el código antiguo en el backend.
Esto es muy caro.
Los errores en el código generalmente son una tontería en comparación con esto. Simplemente reescribió el código, ejecutó las pruebas. Las pruebas son verdes: ha ingresado al maestro. Preste especial atención a la API de la base de datos.
Y no importa cuánto intente realizar un seguimiento de la base de datos, con el tiempo se convertirá en algo inmanejable. En la captura de pantalla, puede ver una décima parte de nuestra base de datos, que ahora existe.
Hay un consejo. Cuando desarrolla algo muy rápidamente, hay imprecisiones en la base de datos, a veces falta una clave externa o aparece un campo duplicado. Por lo tanto, a veces, una vez cada dos o tres meses, solo mire solo la base. La misma Intellij IDEA puede generar circuitos fríos. Y ahí puedes verlo todo.
Su base de datos debe ser adecuada. Es muy fácil hacer una lista de seis tickets en una hora: agregue una clave externa aquí, allí un índice. No importa cuánto lo intente, inevitablemente se acumularán algunos escombros.
La tercera historia trata sobre la calidad.
Hay cosas que es mejor hacer bien desde el principio. Es importante actuar de acuerdo con el principio "hazlo normalmente, estará bien".
Por ejemplo, tenemos un proceso que es fundamental para la plataforma. Todo el día estamos recogiendo pedidos para mañana, pero por la noche se dispara una nota de que después de las 22:00 no estamos recogiendo pedidos, pero antes de la 01:00 nos estamos preparando para mañana. Luego comienza la distribución de pedidos a los centros de clasificación. Vamos a Yandex.Routing, construye rutas.
Y si este trabajo preparatorio fracasa, todo el mañana está en entredicho. Mañana los mensajeros no tendrán adónde ir. No han creado un estado. Este es el proceso más crítico de nuestra plataforma. Y procesos tan importantes no se pueden hacer sobre una base sobrante, con recursos mínimos.
Recuerdo que tuvimos un momento en que este proceso falló, y durante varias semanas casi la mitad del equipo en el chat resolvió estos problemas, todos estaban salvando el día, reelaborando algo, reiniciando.
Entendimos que si el proceso no se completa desde las diez de la tarde hasta la una de la mañana, los centros de clasificación ni siquiera sabrán cómo clasificar los pedidos, en qué montones. Allí todo estará inactivo. Los mensajeros saldrán más tarde y tendremos fallos de calidad.
Es mejor realizar estos procesos lo mejor posible de inmediato, pensando en cada paso en el que algo puede salir mal. Y ponga la máxima cantidad de paja por todas partes.
Te contaré una de las opciones sobre cómo puedes configurar dicho proceso.
Este proceso es multicomponente. El cálculo de rutas y su publicación se puede dividir en partes y, por ejemplo, se pueden crear colas. Luego tenemos varias colas que son responsables de las secciones de trabajo completadas. Y hay consumidores en estas colas que se sientan y esperan mensajes.
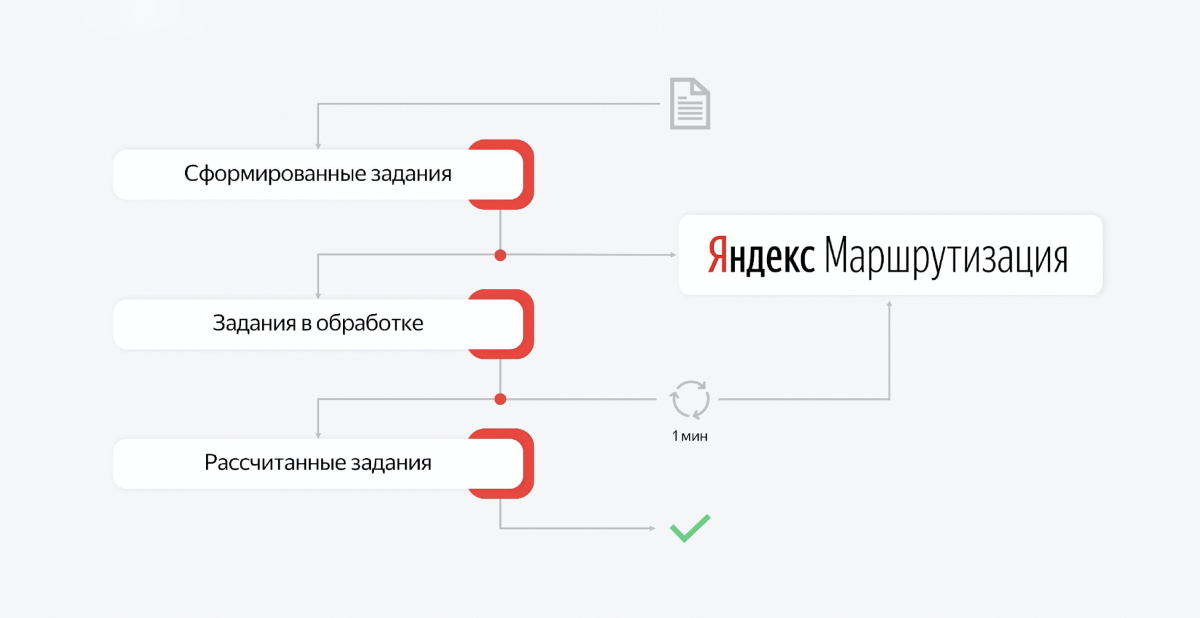
Por ejemplo, el día terminó, queremos calcular las rutas para mañana. En primer lugar, enviamos una solicitud: cree una tarea y comience el cálculo. El consumidor recoge el primer mensaje y se dirige al servicio de enrutamiento. Esta es una API asincrónica. El consumidor recibe una respuesta de que la tarea se ha llevado a cabo.
Pone esta identificación en la base y pone un nuevo trabajo en la cola con tareas en proceso. Y eso es todo. El mensaje desaparece de la primera cola, el segundo consumidor "se despierta". Toma la segunda tarea para procesar, y su tarea es ir regularmente al enrutamiento y verificar si esta tarea aún no se ha completado para el cálculo.
La tarea del nivel "crear rutas para 200 mensajeros que entregarán varios miles de pedidos en Moscú" toma de media hora a una hora. De hecho, esta es una tarea muy difícil. Y los chicos de este servicio son geniales, resuelven el problema algorítmico más complejo que lleva mucho tiempo.
Como resultado, el consumidor de la segunda cola simplemente comprobará, comprobará, comprobará. Después de un tiempo, se completará la tarea. Cuando se completa la tarea, recibimos una respuesta en forma de la estructura requerida de las rutas y turnos de mañana para los mensajeros.
Ponemos lo calculado en la tercera prioridad. El mensaje desaparece de la segunda cola. Y el tercer consumidor "despierta", toma este contexto del servicio Yandex.Routing y, sobre esta base, crea el estado del mañana. Crea pedidos para mensajeros, crea pedidos, crea turnos. Esto también es mucho trabajo. Dedica algún tiempo a esto. Y cuando se crea todo, esta transacción finaliza y el trabajo se elimina de la cola.
Si algo sale mal en algún lugar de este proceso, el servidor se reiniciará. Tras la restauración posterior, simplemente veremos el punto en el que terminamos. Digamos que la primera fase y la segunda han pasado. Y pasemos al tercero.
Con esta arquitectura, en los últimos meses todo ha ido bastante bien, no hay problemas. Pero antes hubo un try-catch sólido. No está claro dónde falló el proceso, qué estados se cambiaron en la base de datos, etc.
Hay cosas en las que no debes escatimar. Hay cosas con las que te ahorrarás un montón de neuronas si haces todo bien de inmediato.
¿Qué hemos hecho sin conexión?
He descrito la mayor parte de lo que está sucediendo en nuestra plataforma. Pero algo quedó entre bastidores.
Aprendimos sobre el software que ayuda a los mensajeros a entregar los pedidos en un día. Pero alguien debería hacer estos montones para mensajeros. En un centro de clasificación, las personas tienen que clasificar una gran máquina de pedidos en pequeñas pilas. ¿Cómo está hecho?
Esta es la segunda parte de la plataforma. Escribimos todo el software nosotros mismos. Ahora tenemos terminales con los que los comerciantes leen el código de las cajas y los colocan en las celdas correspondientes. Hay una lógica bastante complicada. Este backend no es mucho más simple que el del que ya hablé.
Esta segunda pieza del rompecabezas era necesaria para permitir, junto con la primera, extender el proceso a otras ciudades. De lo contrario, tendríamos que buscar un contratista en cada nueva ciudad que pudiera organizar el intercambio de algunos Excels por correo, o integrarse con nuestra API. Y eso sería mucho tiempo.
Cuando tengamos la primera y la segunda pieza del rompecabezas, simplemente podemos alquilar un edificio, contratar mensajeros en automóviles. Dígales cómo empujar, qué empujar, cómo elegir, qué caja poner dónde, y eso es todo. Gracias a esto, ya lo hemos lanzado en siete ciudades, tenemos más de diez centros de clasificación.
Y la apertura de nuestra plataforma en una nueva ciudad lleva muy poco tiempo. Además, hemos aprendido no solo a entregar pedidos a personas específicas. Sabemos cómo entregar los pedidos a los puntos de recogida con la ayuda de mensajeros. También escribimos software para ellos. Y en estos puntos también damos órdenes a la gente.
Resultados
Al principio, dije por qué comenzamos a crear nuestra propia plataforma de mensajería. Ahora les contaré lo que hemos logrado. Es increíble, pero usando nuestra plataforma pudimos acercarnos casi al 100% al intervalo. Por ejemplo, durante la última semana, la calidad de la entrega en Moscú fue del 95% al 98%. Esto significa que en el 95-98% de los casos no llegamos tarde. Encajamos en el intervalo elegido por el cliente. Y ni siquiera podíamos soñar con tal precisión cuando confiábamos únicamente en servicios de entrega externos. Por lo tanto, ahora estamos expandiendo gradualmente nuestra plataforma a todas las regiones. Y mejoraremos la capacidad de entrega.
Conseguimos una transparencia poco realista. También necesitamos esta transparencia. Todo está registrado con nosotros: todas las acciones, todo el proceso de emisión de un pedido. Tenemos la oportunidad de retroceder en la historia durante cinco meses y comparar alguna métrica con la actual.
Pero también les dimos esta transparencia a los clientes. Ven a un mensajero que se les acerca. Pueden interactuar con él. No es necesario que llamen al servicio de soporte y digan: "¿Dónde está mi mensajero?"
Además, resultó optimizar los costos, porque tenemos acceso a todos los elementos de la cadena. Como resultado, ahora cuesta un cuarto menos entregar un pedido que antes cuando trabajábamos con servicios externos. Sí, el costo de envío del pedido se ha reducido en un 25%.
Y si resume todas las ideas que se discutieron, se pueden distinguir las siguientes.
Debe comprender claramente en qué etapa de desarrollo se encuentra su servicio actual, su proyecto actual. Y si se trata de un negocio consolidado, utilizado por millones de personas, utilizado, quizás en varios países, no se puede hacer todo al mismo nivel que con Rover.
Pero si tienes un experimento ... El experimento es diferente en que en cualquier momento, si no mostramos los resultados prometidos, podemos cerrar. No despegó. Y eso esta bien.
Y estuvimos en este régimen durante unos diez meses. Teníamos intervalos de informes, cada dos meses teníamos que mostrar el resultado. Y lo logramos.
En este modo, me parece que no tienes derecho a hacer algo invirtiendo a largo plazo y no obteniendo nada a corto plazo. Es imposible sentar una base tan sólida para el futuro en este formato de trabajo, porque es posible que el futuro simplemente no llegue.
Y cualquier desarrollador competente, líder técnico debe elegir constantemente entre hacerlo con muletas o construir una nave espacial de inmediato.
En resumen, trate de mantenerlo lo más simple posible, dejando espacio para la expansión.
Hay un primer nivel en el que necesitas hacerlo de forma bastante sencilla. Y está el primer nivel con un asterisco, cuando lo mantienes sencillo, pero dejas al menos un poco de margen de maniobra para que se pueda ampliar. Con esta mentalidad, me parece que los resultados serán mucho mejores.
Y lo ultimo. Hablé de Rover de que es bueno hacer tales procesos usando indicadores de características. Te aconsejo que escuches la charla de Maria Kuznetsova de la reunión de Java. Ella contó cómo se organizan las banderas de funciones en nuestro sistema y monitoreo.