
¡Hola, Habr!
En este artículo, veremos algunos enfoques sencillos de predicción de series de tiempo.
El material presentado en el artículo, en mi opinión, complementa bien la primera semana del curso "Problemas aplicados de análisis de datos" de MIPT y Yandex. En el curso indicado, se puede obtener conocimientos teóricos suficientes para resolver los problemas de predicción de la serie de dinámicas, y como consolidación práctica del material, se propone utilizar el modelo ARIMA de la biblioteca scipy para generar una previsión salarial en ruso. Federación para el año que viene. En el artículo, también generaremos una previsión salarial, pero al mismo tiempo usaremos no la biblioteca scipy , sino la biblioteca. sklearn . El truco es que scipy ya tiene un modelo ARIMA , pero sklearn no tiene un modelo ya hecho, así que tenemos que trabajar duro con bolígrafos. Por lo tanto, para resolver el problema, en cierto sentido, necesitaremos averiguar cómo funciona el modelo desde adentro. Además, como material adicional, en el artículo, el problema de predicción se resuelve utilizando una red neuronal de una sola capa de la biblioteca pytorch .
Todo el código está escrito en python 3 en el cuaderno jupyter . Además, el cuaderno está diseñado de tal manera que en lugar de datos sobre salarios, puede sustituir muchas otras series de dinámicas, por ejemplo, datos sobre precios del azúcar, cambiar el período de pronóstico, validación y capacitación, agregar otros factores externos y formar un pronóstico apropiado. En otras palabras, en el trabajo se utiliza un simple simulador autoescrito, con la ayuda del cual es posible predecir varias series de dinámicas. El código se puede ver aquí.
Esquema del artículo
- Breve descripción del simulador.
- Una solución directa es pronosticar series de tiempo utilizando sólo datos "brutos" de valores pasados de series de tiempo.
- Suma de variables exógenas.
- Corrección de heterocedasticidad mediante el logaritmo de los datos iniciales.
- Llevando la fila a una estacionaria.
- Pronóstico con una red neuronal de una sola capa.
- Comparación de enfoques.
- Enlaces útiles
Breve descripción del simulador
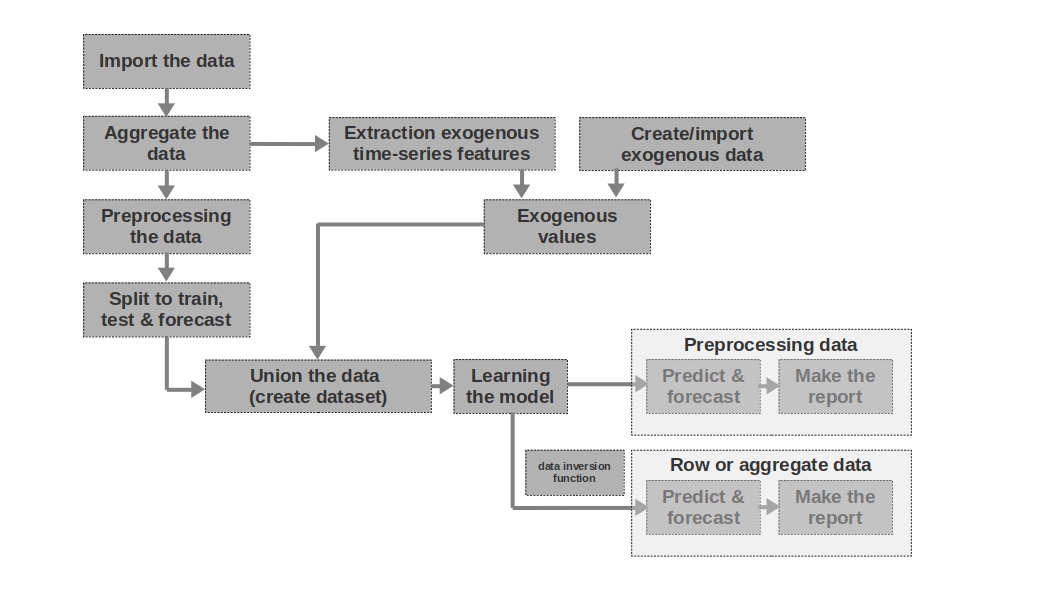
Importar los datos
Aquí todo es sencillo: importamos los datos. A veces sucede que los datos brutos son suficientes para formar un pronóstico más o menos inteligible. Son los primeros y segundos pronósticos del artículo los que se modelan sobre la base de datos brutos, es decir, los datos brutos sobre salarios en períodos pasados se utilizan para pronosticar los salarios.
Agregue los datos
El artículo no utiliza la agregación de datos porque no es necesario. Sin embargo, los datos a menudo se pueden presentar en intervalos de tiempo desiguales. En este caso, solo necesita agregarlos. Por ejemplo, los datos de la negociación de valores, divisas y otros instrumentos financieros deben agregarse. Por lo general, se toma el valor promedio en el intervalo, pero también son posibles el máximo, el mínimo, la desviación estándar y otras estadísticas.
Preprocesamiento de los datos
En nuestro caso, estamos hablando principalmente del preprocesamiento de datos, por lo que la serie temporal adquiere la propiedad de homocedasticidad (a través del logaritmo de los datos) y se vuelve estacionaria (a través de la diferenciación de la serie).
Dividir para entrenar, probar y pronosticar
En este bloque de código, la serie temporal se divide en períodos de entrenamiento, prueba y pronóstico agregando una nueva columna con los valores correspondientes "entrenar", "probar", "pronóstico". Es decir, no creamos tres tablas separadas para cada período, sino que simplemente agregamos una columna, en función de la cual dividiremos aún más los datos.
Extracción de características de series de tiempo exógenas
Puede resultar útil aislar características externas (exógenas) adicionales de una serie de tiempo. Por ejemplo, indique si es un día libre o no, indique el número de días en un mes (o el número de días laborables en un mes), etc. Por regla general, estos signos se "extraen" de la serie temporal sí mismo sin ninguna intervención manual.
Crear / importar datos exógenos
No toda la información se puede "extraer" de la serie temporal. A veces, es posible que se requieran datos externos adicionales. Por ejemplo, algunos eventos episódicos que tienen un fuerte impacto en los valores de la serie temporal. Tales hechos pueden ser fechas de inicio de hostilidades, imposición de sanciones, desastres naturales, etc. El trabajo no considera tales factores, pero debe tenerse en cuenta la posibilidad de su uso.
Valores exógenos
En este bloque de código, combinamos todos los datos exógenos en una tabla.
Unir los datos (crear un conjunto de datos)
En este bloque de código, combinamos los valores de la serie temporal y las características exógenas en una tabla. En otras palabras, estamos preparando un conjunto de datos, a partir del cual entrenaremos el modelo, probaremos la calidad y formaremos un pronóstico.
Aprendiendo el modelo
Todo está claro aquí, solo estamos entrenando el modelo.
Preprocesamiento de datos: predecir y pronosticar
Si utilizamos datos preprocesados para entrenar el modelo (logarítmicos, procesados por la función box-coke, series estacionarias, etc.), entonces la calidad del modelo se evalúa primero en los datos preprocesados y solo luego en los datos "sin procesar". Si no preprocesamos los datos, esta etapa se omite.
Datos de fila: predecir y pronosticar
Esta etapa es la última. Si el modelo se entrenó con datos preprocesados, por ejemplo, los prologábamos, luego, para obtener el pronóstico de salarios en rublos, y no el logaritmo de rublos, deberíamos traducir el pronóstico de nuevo a rublos.
También me gustaría señalar que el artículo utiliza una serie de tiempo unidimensional para predecir los salarios. Sin embargo, nada le impide utilizar una serie multidimensional, por ejemplo, agregar datos sobre el tipo de cambio del rublo al dólar o alguna otra serie.
Decisión en la frente
Supondremos que los datos sobre salarios en el pasado pueden aproximarse a los salarios en el futuro. En otras palabras, el tamaño de los salarios, por ejemplo, en enero depende de lo que fueron los salarios en diciembre, noviembre, octubre, ...
Tomemos los valores de los salarios en los últimos 12 meses para predecir los salarios en el decimotercer mes. En otras palabras, para cada valor objetivo, tendremos 12 características.
Los letreros se enviarán a la entrada de Ridge Regression de la biblioteca sklearn. Tomamos los parámetros predeterminados del modelo, excepto el parámetro alfa, se estableció en 0, es decir, de hecho, estamos usando regresión regular.
Esta es una solución sencilla, es la más simple :) Hay situaciones en las que necesita dar al menos algún resultado con mucha urgencia, pero simplemente no hay tiempo para ningún preprocesamiento o no hay suficiente experiencia para procesar o agregar datos rápidamente. En tales situaciones, puede utilizar datos sin procesar como base para crear un pronóstico. De cara al futuro, observo que la calidad del modelo resultó ser comparable a la calidad de los modelos que utilizan preprocesamiento de datos.
Veamos qué tenemos.
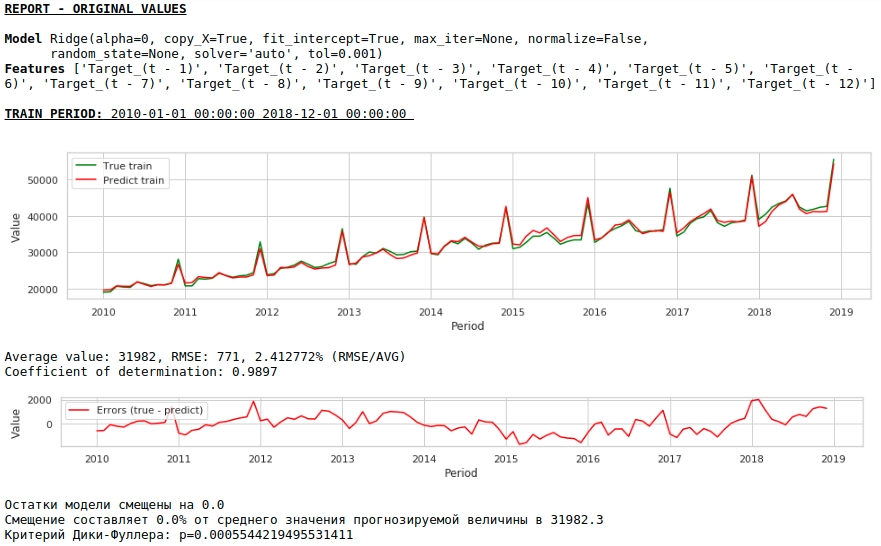
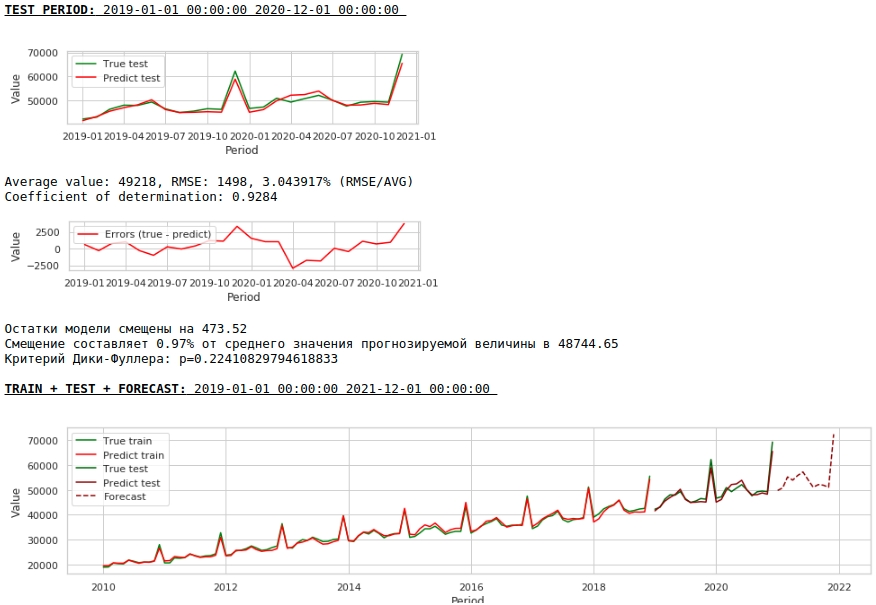
A primera vista, el resultado parece, aunque imperfecto, pero cercano a la realidad.
De acuerdo con los valores de los coeficientes de regresión, el valor del salario tiene la mayor influencia en la previsión de salarios hace exactamente un año.
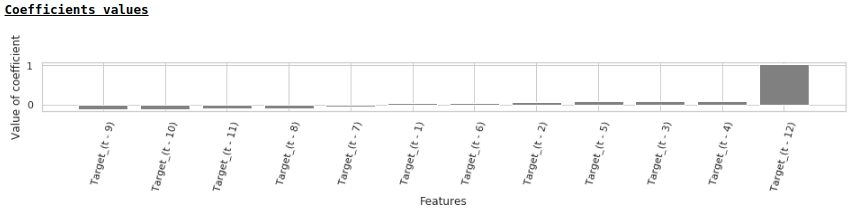
Intentemos agregar variables exógenas al modelo.
Agregar variables exógenas
Usaremos 2 signos externos: el número de días en un mes y el número del mes (de 1 a 12). Binarizamos el atributo "Número de mes", como resultado obtenemos 12 columnas para cada mes con valores de 0 o 1.
Formemos un nuevo conjunto de datos y observemos la calidad del modelo.
Viendo gráficos
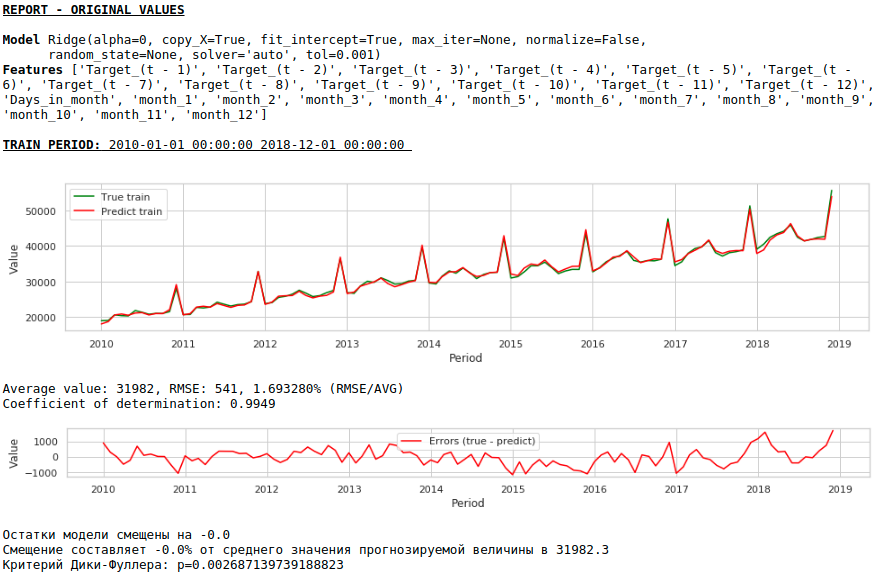
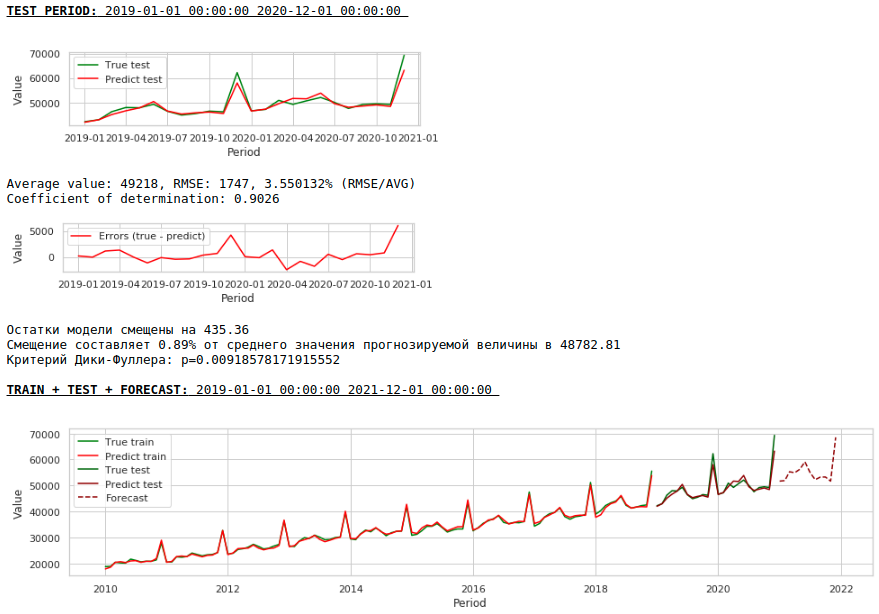
La calidad es menor. Visualmente, se nota que el pronóstico no parece del todo plausible en términos de crecimiento salarial en diciembre.
Hagamos ahora el primer preprocesamiento de datos.
Corrección de heterocedasticidad.
Si miramos el gráfico de salarios para el período de 2010 a 2020, podemos ver que la distribución de los salarios dentro del año entre meses aumenta cada año.
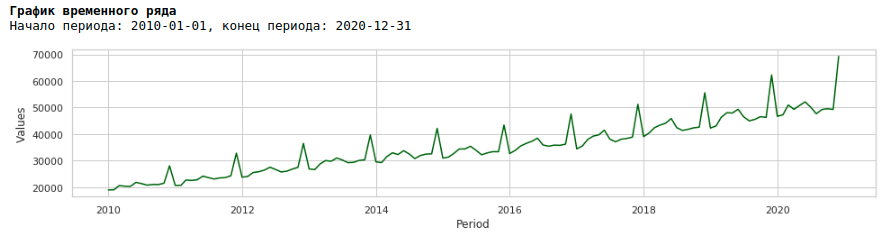
Un aumento anual en la variación de un mes a otro conduce a la heterocedasticidad. Para mejorar la calidad de los pronósticos, debemos deshacernos de esta propiedad de los datos y llevarlos a la homocedasticidad.
Para hacer esto, usaremos el logaritmo habitual y veremos cómo se ve la serie logarítmica.
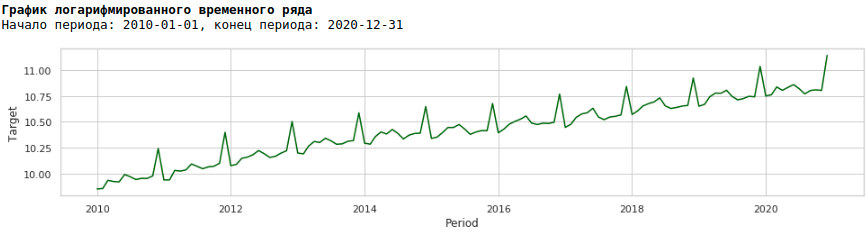
Entrenemos el modelo en la serie logarítmica.
Viendo gráficos
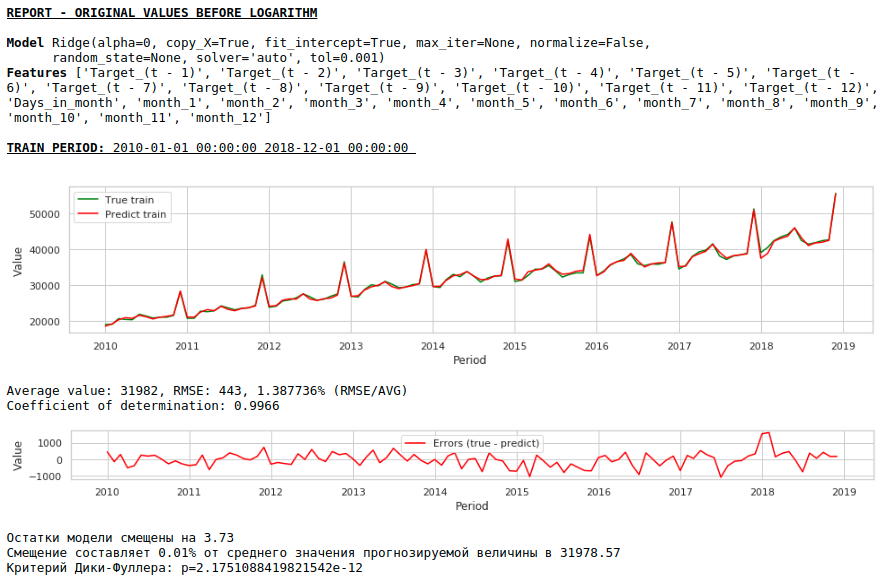
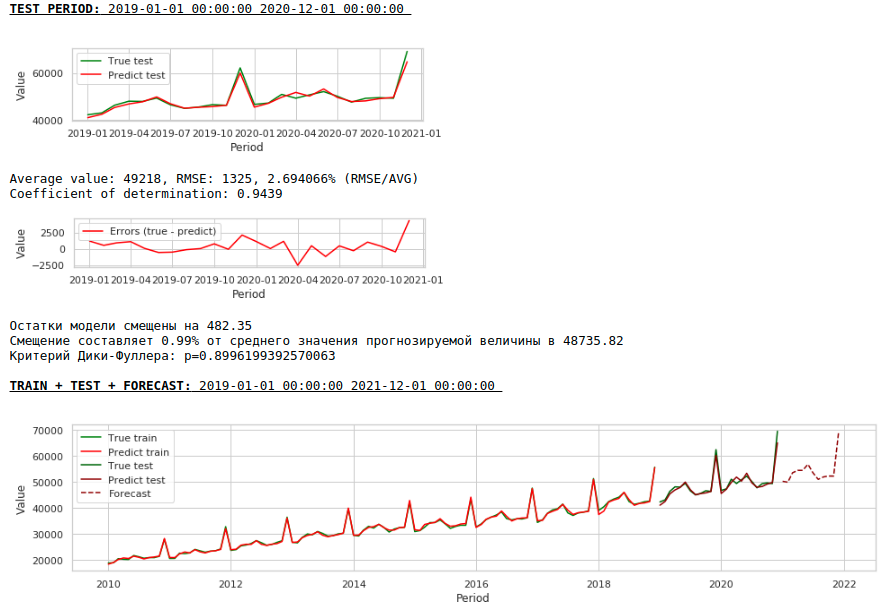
Como resultado, la calidad de las predicciones en las muestras de entrenamiento y prueba mejoró, sin embargo, el pronóstico para 2021 parece menos plausible visualmente en comparación con el pronóstico del primer modelo. Lo más probable es que el uso de factores exógenos degrade el modelo.
Llevando una fila a un estacionario
Reduciremos la serie a una estacionaria de la siguiente manera:
- Determine la diferencia entre el valor del salario objetivo y el valor de hace un año: t - (t-12) = dif_1
- Determine la diferencia entre el valor recibido y cambiado por 1 mes: dif_1 - (dif_1-1) = dif_2
Como resultado, obtenemos la siguiente serie de tiempo.
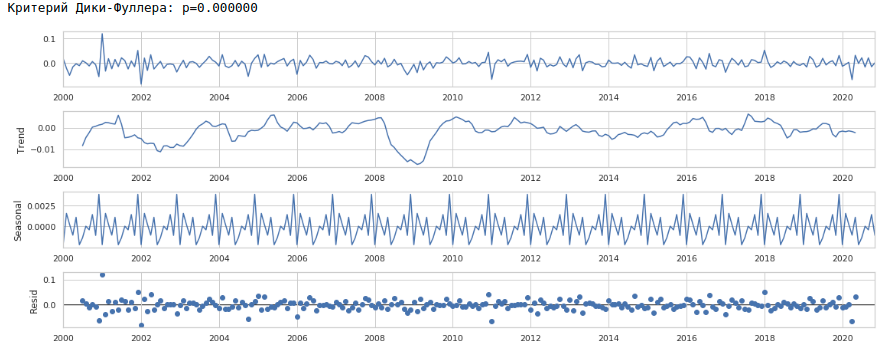
La serie realmente parece estacionaria, esto también está indicado por el valor del criterio de Dickey-Fuller.
No es necesario esperar una buena calidad de predicciones sobre las muestras de entrenamiento y prueba sobre los datos procesados, es decir, sobre una serie estacionaria, ya que de hecho, en este caso, el modelo debería predecir los valores de ruido blanco. Pero para nosotros, para predecir salarios, no es en absoluto necesario utilizar la regresión, ya que, al reducir la serie a una estacionaria, hemos determinado, en términos simples, una fórmula para aproximar la variable objetivo. Pero no nos desviaremos de los cánones y usaremos un modelo de regresión, además, tenemos factores exógenos.
Vamos a ver que pasó.
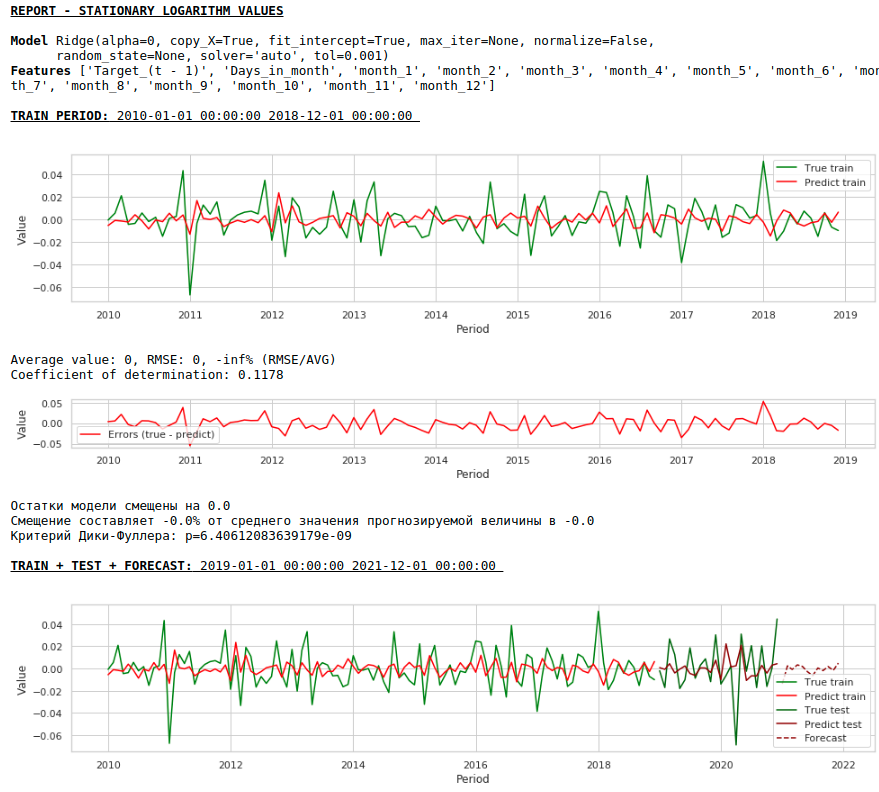
Así es como se ve la predicción de una serie estacionaria. Como se esperaba, no muy bien :)
Y aquí está la predicción y el pronóstico de los salarios.
Viendo gráficos
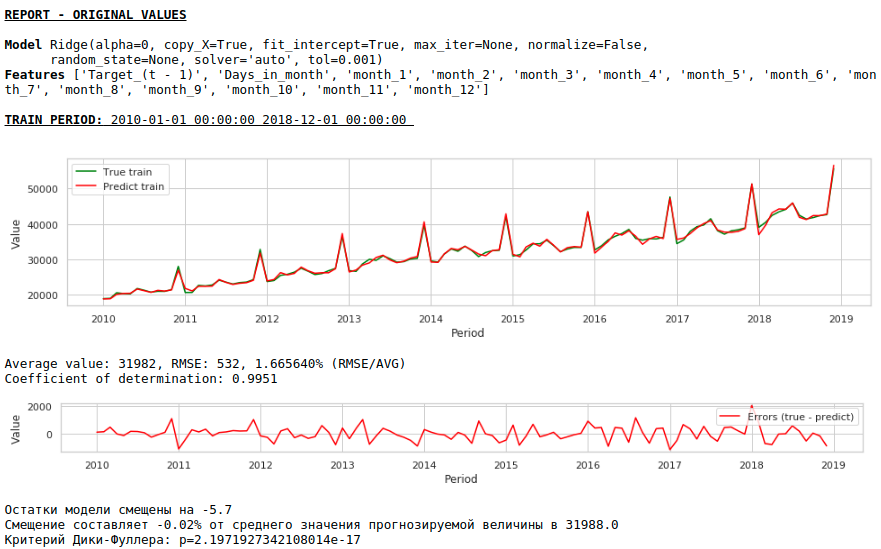
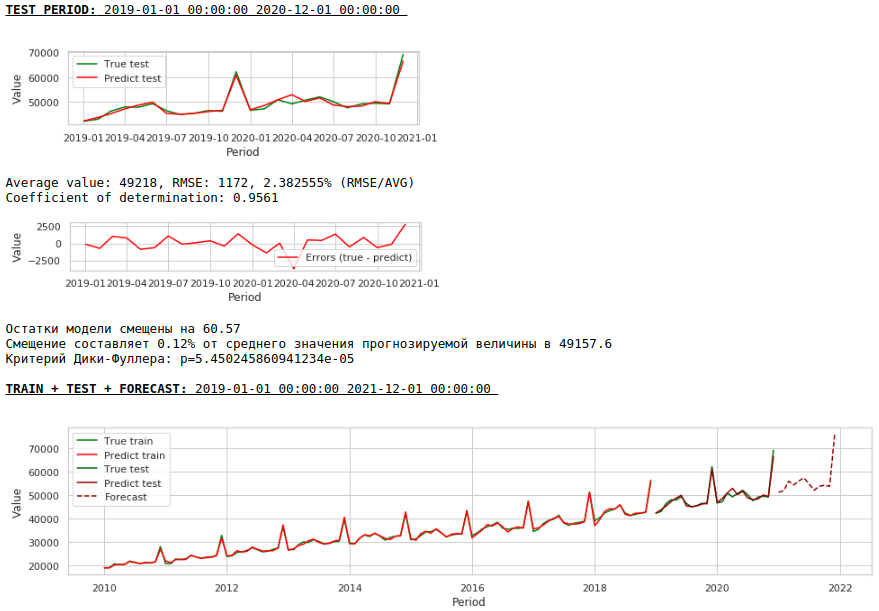
La calidad ha mejorado notablemente y el pronóstico es visualmente creíble.
Ahora hagamos un pronóstico sin usar variables exógenas.
Viendo gráficos
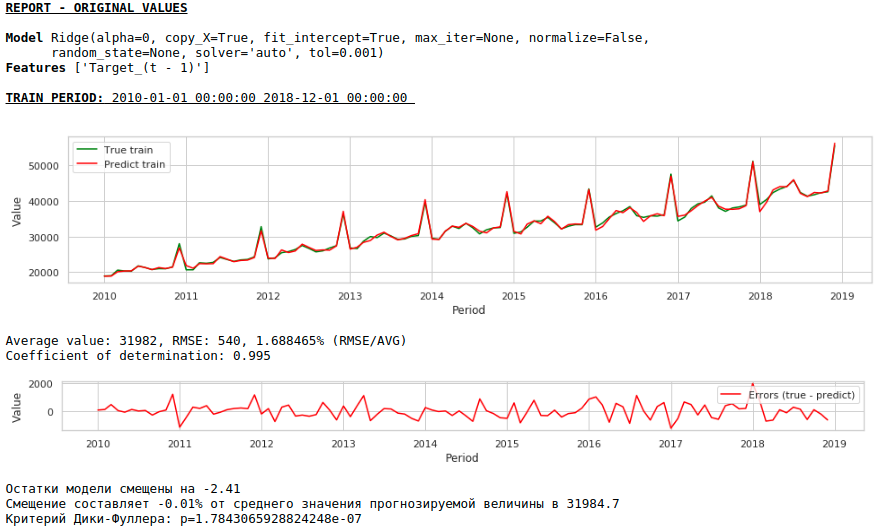
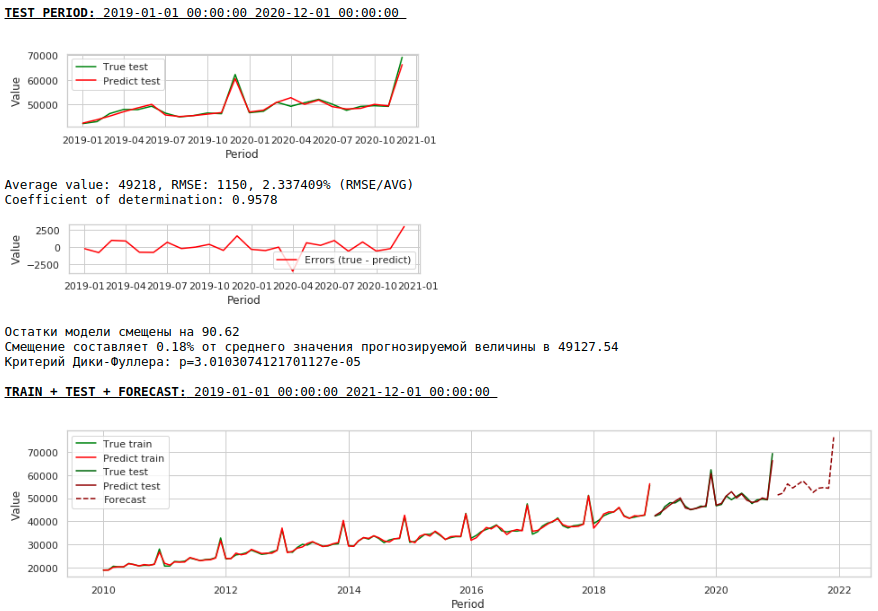
La calidad ha mejorado aún más y se conserva la plausibilidad del pronóstico :)
Pronóstico con una red neuronal de una sola capa
Alimentaremos los conjuntos de datos existentes a la entrada de la red neuronal. Dado que nuestra red es de una sola capa, de hecho, esta es la misma regresión lineal con modificaciones simples y no debe esperar una diferencia muy grande en la calidad de las predicciones.
Primero, veamos la red en sí.
Ver el codigo
class Model_1(nn.Module):
def __init__(self, input_size, output_size):
super(Model_1, self).__init__()
self.input_size = input_size
self.output_size = output_size
self.linear = nn.Linear(self.input_size, self.output_size)
def forward(self, x):
output = self.linear(x)
return output
Ahora unas palabras sobre cómo la formaremos.
- Fijamos una semilla aleatoria con el propósito de reproducir el resultado.
- Inicializando el modelo
- Configuración de la función de pérdida - MSELoss
- Seleccionar el optimizador de Adam como optimizador
- Indicamos el paso inicial del entrenamiento y determinamos la condición bajo la cual se baja el paso. Tenga en cuenta que la elección correcta de un paso y su posterior cambio (generalmente una disminución) produce buenos resultados.
- Especifique el número de épocas de aprendizaje
- Empezamos a entrenar
- Suministramos el conjunto de datos completo a la entrada de la red, ya que es muy pequeño y no tiene sentido dividirlo en lotes.
- Durante el entrenamiento, cada mil épocas formamos gráficos del valor de la función de pérdida en las muestras de entrenamiento y prueba. Esto nos permite controlar el sobreajuste o no reentrenamiento del modelo.
A continuación se muestra el código para entrenar la red en el primer conjunto de datos. Para cada conjunto de datos, los parámetros cambiaron ligeramente: el número de épocas de entrenamiento y el paso de entrenamiento.
Ver el codigo
# fix the random seed
SEED = 42
random_init(SEED)
# initialization model, loss function, optimizator
model = Model_1(len(features),1)
loss_func = nn.MSELoss()
opt = torch.optim.Adam(model.parameters(), lr=5e-2)
# set the epoch numbers, initialization list for every loss after learning on epoch
epochs = 15000
losses_train = []
losses_test = []
# initialization counter for calculation epoch numbers
counter = 0
# start the learning model
for epoch in range(epochs):
model.train()
# make prediction targets on train data
y_pred_train = model(torch.tensor(X_train.to_numpy(), dtype=torch.float))
# calculate loss
loss = loss_func(y_pred_train,
torch.reshape(torch.tensor(y_train.to_numpy(), dtype=torch.float),(-1,1)))
# bacward loss to model and calculate new parameters (coefficients) with fixed learning rate
loss.backward()
opt.step()
opt.zero_grad()
# add loss to list losses
losses_train.append(loss)
model.eval()
y_pred_test = model(torch.tensor(X_test.to_numpy(), dtype=torch.float))
loss_test = loss_func(y_pred_test,
torch.reshape(torch.tensor(y_test.to_numpy(), dtype=torch.float),(-1,1)))
losses_test.append(loss_test)
# make the mini report for every 1000 epoch
if epoch % 1000 == 0 and epoch > 0:
print ('Epoch:', epoch // 1000)
print ('Learning rate:', opt.param_groups[0]['lr'])
print ('Last loss on TRAIN data:', losses_train[-1].cpu().detach().numpy(),
' Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
# print ('Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
fig, (ax1, ax2) = plt.subplots(1, 2)
# fig.suptitle('MSE on TRAIN & TEST DATA')
fig.set_figheight(3)
fig.set_figwidth(12)
ax1.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_train][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TRAIN data")
ax2.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_test][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TEST data")
plt.show()
counter += 1000
# reduce learning rate
if epoch == 1000:
opt = torch.optim.Adam(model.parameters(), lr=7e-3)
No consideraremos la calidad de las predicciones para cada conjunto de datos por separado (aquellos que lo deseen pueden ver los detalles en el gita). Comparemos los resultados finales.
Calidad en una muestra de prueba usando la Calidad de regresión de cresta
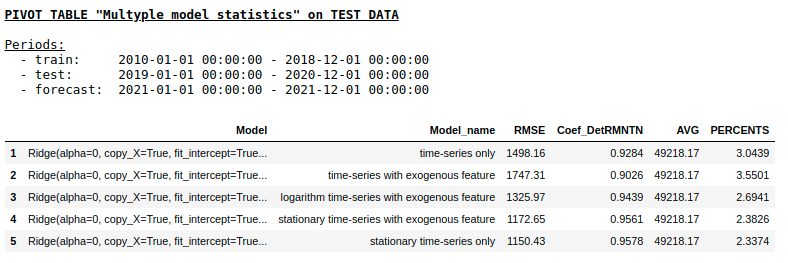
en una muestra de prueba usando NN de capa única
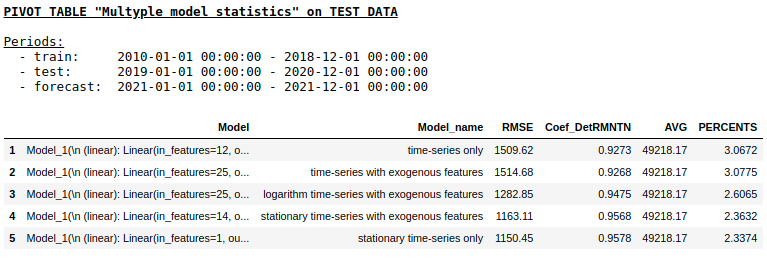
Como esperábamos, no hubo una diferencia fundamental entre la regresión regular y una red neuronal simple de una sola capa. Por supuesto, las neuronas brindan más maniobra para el aprendizaje: puede cambiar los optimizadores, ajustar los pasos de aprendizaje, usar capas ocultas y funciones de activación, puede ir aún más lejos y usar redes neuronales recurrentes: RNN. Por cierto, personalmente, no pude obtener una buena calidad en este problema usando RNN, sin embargo, en Internet, puede encontrar muchos ejemplos interesantes de predicción de series de tiempo usando LSTM.
En este punto, el artículo llegó a su fin. Espero que el material sea útil como una especie de descripción general de los enfoques de referencia utilizados en la predicción de series de tiempo y sirva como una buena adición práctica al curso "Problemas aplicados de análisis de datos" de MIPT y Yandex.
Enlaces útiles
- Fuentes en github
- Curso "Problemas aplicados de análisis de datos" de MIPT y Yandex
- Estadísticas estatales "EMISS" (datos sobre salarios)
- LSTM para la predicción de series de tiempo
- Tema 9. Pronóstico basado en un modelo de regresión. Centro de Ciencias de la Computación
- La imagen debajo del título está tomada de aquí :)