
Estoy seguro de que la mayoría de los lectores están al menos un poco familiarizados con los términos "Unicode" y "UTF-8". ¿Pero todos saben qué hay exactamente detrás de ellos? En esencia, se refieren a estándares de codificación de caracteres, también conocidos como conjuntos de caracteres. El concepto apareció en los días del telégrafo óptico, y no en la era de las computadoras, como podría pensarse. Ya en el siglo XVIII, existía la necesidad de una transmisión rápida de información a largas distancias, para lo cual se utilizaron los llamados códigos telegráficos. La información se codificó utilizando medios ópticos, electrónicos y otros.
En los cientos de años que han pasado desde la invención del primer código telegráfico, no ha habido ningún intento real de estandarización internacional de tales esquemas de codificación. Incluso las primeras décadas de la era de los teletipos y las computadoras domésticas cambiaron poco. Si bien EBCDIC (codificación de caracteres de 8 bits de IBM, que se muestra en una tarjeta perforada en la ilustración del encabezado) y ASCII mejoraron un poco las cosas, todavía no había forma de codificar una colección creciente de caracteres sin un uso significativo de la memoria.
El desarrollo de Unicode comenzó a fines de la década de 1980, cuando el crecimiento en el intercambio de información digital en todo el mundo hizo que la necesidad de un único sistema de codificación fuera más urgente. En estos días, Unicode nos permite usar un esquema de codificación único para todo, desde texto básico en inglés hasta chino tradicional, vietnamita, incluso maya, hasta los pictogramas que solíamos llamar emojis.
Del código a los gráficos
En los días del Imperio Romano, era bien sabido que la rápida transmisión de información importa. Durante mucho tiempo, esto significó la presencia de mensajeros a caballo que llevaban mensajes a grandes distancias, o su equivalente. La forma de mejorar el sistema de entrega de información se inventó en el siglo IV a. C., así es como aparecieron un telégrafo de agua y un sistema de luces de señalización. Pero no fue hasta el siglo XVIII cuando la transmisión de datos a larga distancia se volvió realmente efectiva.
Ya hemos escrito sobre el telégrafo óptico, también llamado "semáforo", en un artículo sobre la historia de la comunicación óptica. Consistía en una serie de estaciones repetidoras, cada una equipada con un sistema de señales de giro utilizado para mostrar símbolos de códigos telegráficos. El sistema de los hermanos Chappe, que fue utilizado por las tropas francesas entre 1795 y 1850, se basaba en una barra de madera con dos extremos móviles (palancas), cada uno de los cuales podía moverse a una de las siete posiciones. Junto con las cuatro posiciones de la barra transversal, el semáforo en teoría podría indicar 196 caracteres (4x7x7). En la práctica, el número se redujo a 92-94 posiciones.
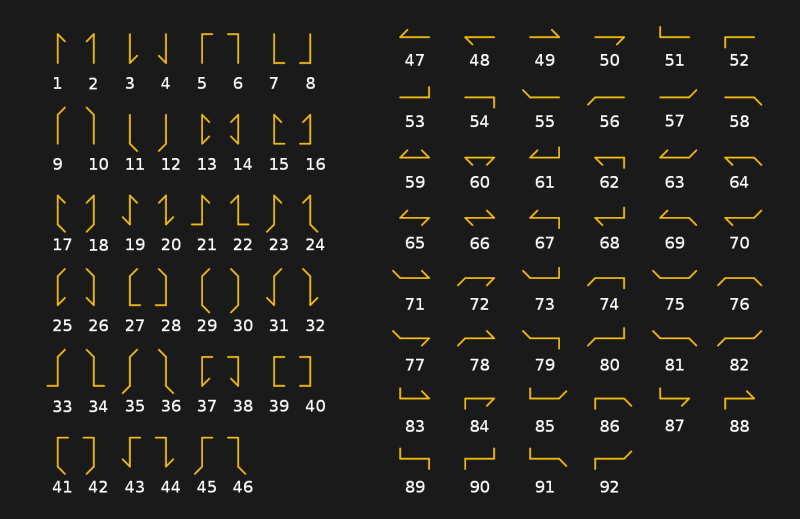
El sistema de semáforos se utilizó no tanto para codificar caracteres directamente como para denotar cadenas específicas en un libro de códigos. El método implicaba que era posible descifrar todo el mensaje utilizando varias señales de código. Esto hizo que la transmisión fuera más rápida y que no tuviera sentido interceptar mensajes.
Mejora del rendimiento
Luego, el telégrafo óptico fue reemplazado por uno eléctrico. Esto significó que los días en que las personas que miraban la torre de relevo más cercana capturaban las codificaciones habían terminado. Con dos dispositivos de telégrafo conectados por un cable metálico, la corriente eléctrica se convirtió en el instrumento para transmitir información. Este cambio condujo a nuevos códigos de telégrafo eléctrico, y el código Morse finalmente se convirtió en un estándar internacional (con la excepción de los Estados Unidos, que continuó usando el código Morse estadounidense fuera de la radiotelegrafía) desde su invención en Alemania en 1848.
El código Morse internacional tiene una ventaja sobre su contraparte estadounidense: usa más guiones que puntos. Este enfoque ralentiza la velocidad de transmisión pero mejora la recepción de mensajes en el otro extremo de la línea. Esto era necesario cuando operadores de diferentes niveles de habilidad transmitían mensajes largos a través de kilómetros de cables.
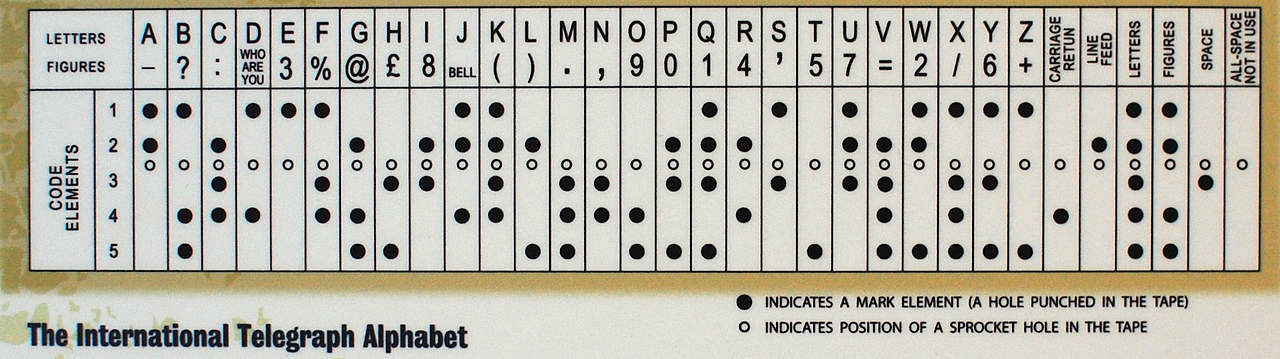
Con el desarrollo de la tecnología, el telégrafo manual fue reemplazado en Occidente por uno automático. Utilizaba el código Baudot de 5 bits, así como el código Murray derivado de él (este último se basaba en el uso de cinta de papel en la que se perforaban agujeros). El sistema de Murray hizo posible preparar una cinta de mensajes por adelantado y luego cargarla en un lector para que el mensaje se transmitiera automáticamente. El código Baudot formó la base para la Versión 1 del Alfabeto Telegráfico Internacional (ITA 1), y el código Baudot-Murray modificado formó la base para ITA 2, que se utilizó hasta la década de 1960.
En la década de 1960, ya no se requería el límite de 5 bits por carácter, lo que llevó al desarrollo de ASCII de 7 bits en los Estados Unidos y estándares como JIS X 0201 (para caracteres katakana japoneses) en Asia. En combinación con los teletipos, que entonces eran ampliamente utilizados, esto permitió la transmisión de mensajes bastante complejos, incluidos caracteres en mayúsculas y minúsculas.
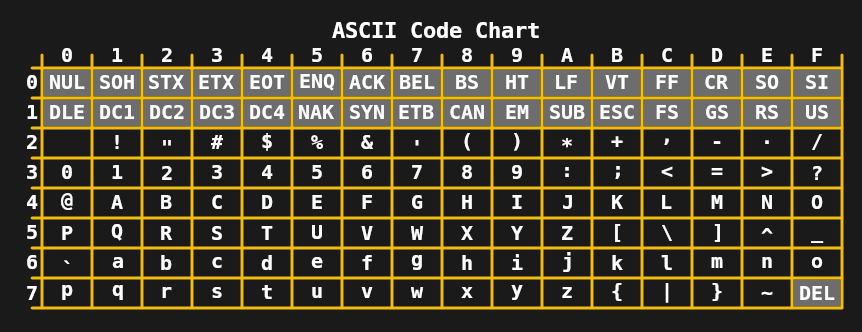
Durante la década de 1970 y principios de la de 1980, las limitaciones de las codificaciones de 7 y 8 bits como ASCII extendido (como ISO 8859-1 o Latin 1) fueron suficientes para las computadoras domésticas y las necesidades de la oficina. A pesar de esto, la necesidad de mejora era clara, ya que tareas comunes como el intercambio de documentos digitales y texto a menudo causaban estragos con las muchas codificaciones ISO 8859. El primer paso se dio en 1991 con Unicode 1.0 de 16 bits.
Desarrollo de codificaciones de 16 bits
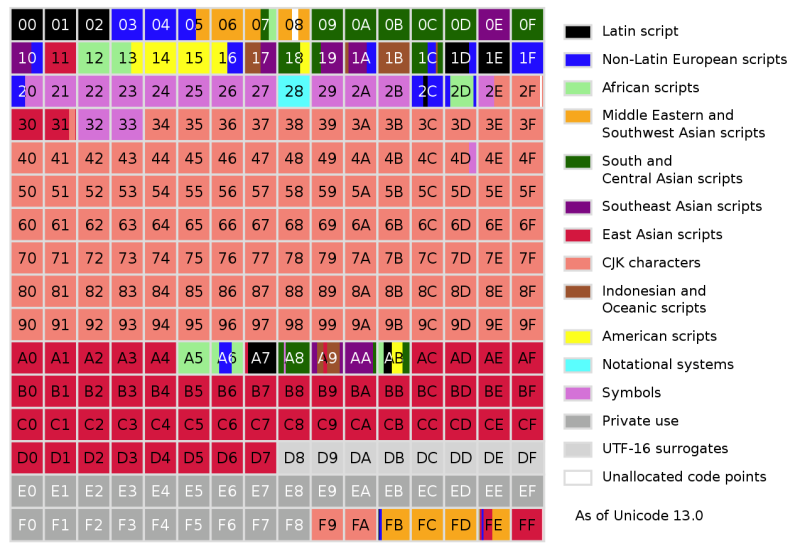
Sorprendentemente, en solo 16 bits, Unicode logró cubrir no solo todos los sistemas de escritura occidentales, sino también muchos caracteres chinos y muchos caracteres especiales utilizados, por ejemplo, en matemáticas. Con 16 bits que permiten hasta 65,536 puntos de código, Unicode 1.0 acomoda fácilmente 7,129 caracteres. Pero cuando apareció Unicode 3.1 en 2001, contenía al menos 94,140 caracteres.
Ahora, en su decimotercera versión, Unicode contiene un total de 143.859 caracteres excluyendo los caracteres de control. Inicialmente, Unicode estaba destinado a usarse solo para codificar los sistemas de notación que se utilizan actualmente. Pero para el lanzamiento de Unicode 2.0 en 1996, quedó claro que este objetivo debía repensarse para codificar incluso caracteres raros e históricos. Para lograr esto sin la codificación obligatoria de 32 bits de cada carácter, Unicode ha cambiado: permitía no solo codificar caracteres directamente, sino también usar sus componentes, o grafemas.
El concepto es algo similar a las imágenes vectoriales, donde no se especifica cada píxel, sino que se describen los elementos que componen la imagen. Como resultado, la codificación Unicode Transformation Format 8 (UTF-8) admite 2 31 punto de código, con la mayoría de los caracteres en el conjunto de caracteres Unicode actual que normalmente requiere uno o dos bytes.
Unicode para todos los gustos y colores
En este punto, es probable que muchas personas estén confundidas por los diversos términos que se utilizan cuando se trata de Unicode. Por lo tanto, es importante señalar aquí que Unicode se refiere al estándar y los diversos formatos de transformación Unicode son implementaciones del mismo. UCS-2 y USC-4 son implementaciones más antiguas de Unicode de 2 y 4 bytes, siendo UCS-4 idéntico a UTF-32 y UCS-2 reemplazando a UTF-16.
UCS-2, como la forma más temprana de Unicode, se abrió camino en muchos sistemas operativos en la década de 1990, lo que hizo que la transición a UTF-16 fuera la opción menos peligrosa. Esta es la razón por la que Windows y MacOS, los administradores de ventanas como KDE y los tiempos de ejecución de Java y .NET usan UTF-16 internamente.
UTF-32, como su nombre indica, codifica cada carácter en cuatro bytes. Es un poco derrochador, pero completamente predecible. El mismo carácter UTF-8 puede codificar un carácter en el rango de uno a cuatro bytes. En el caso de UTF-32, determinar el número de caracteres en una cadena es aritmética simple: tome el número total de bytes y divídalo por cuatro. Esto ha llevado a compiladores y algunos lenguajes, como Python, que permiten que UTF-32 represente cadenas Unicode.
Sin embargo, de todos los formatos Unicode, UTF-8 es, con mucho, el más popular. Esto ha sido facilitado en gran medida por la World Wide Web, donde la mayoría de los sitios web sirven sus documentos HTML en codificación UTF-8. Debido al diseño de los diferentes planos de puntos de código en UTF-8, Western y muchos otros sistemas de escritura comunes caben en dos bytes. En comparación con las antiguas codificaciones ISO 8859 y Shift JIS, de hecho, el mismo texto en UTF-8 no ocupa más espacio que antes.
De las torres ópticas a Internet
Se acabaron los días de los mensajeros a caballo, las torres de relevo y las pequeñas estaciones de telégrafo. La tecnología de la comunicación ha evolucionado mucho. Incluso los días en que los teletipos eran comunes en las oficinas son difíciles de recordar. Sin embargo, en cada etapa del desarrollo de la historia, la humanidad tuvo la necesidad de codificar, almacenar y transmitir información. Y esto nos llevó al punto en el que ahora podemos transmitir instantáneamente un mensaje alrededor del mundo en un sistema de símbolos que se pueden decodificar sin importar dónde se encuentre.
Para aquellos que han cambiado entre codificaciones ISO 8859 en clientes de correo electrónico y navegadores web para obtener algo que se parece al mensaje de texto original, la compatibilidad con Unicode ha sido una bendición. Puedo entender a esta gente. Cuando ASCII de 7 bits (o EBCDIC) era la tecnología indiscutible, a veces era necesario pasar horas resolviendo la confusión simbólica de un documento digital recibido de una oficina europea o estadounidense.
Incluso si Unicode no está exento de problemas, es difícil no sentirse agradecido al compararlo con lo que solía ser. Aquí están, 30 años de Unicode.
