
Muy a menudo, el uso de herramientas listas para usar en el desarrollo se convierte en una solución subóptima. Así pasó con nosotros. Para gestionar las canalizaciones de datos, decidimos desarrollar nuestro propio sistema: Wombat. Le diremos lo que resultó y lo que nos dio la negativa a usar la solución preparada.
Por qué estamos desarrollando nuestro propio sistema
Crear su propio sistema de gestión de canalización de datos no es una elección obvia. Hoy en día existen muchas soluciones listas para usar que pueden resolver el problema: Airflow, MLflow, Kubeflow, Luigi y muchas otras. Hemos experimentado con muchos de estos sistemas y hemos llegado a la conclusión de que ninguno nos conviene.
Por ejemplo, considere la solución más común: Airflow. Combina seis bloques principales: una API para describir tuberías, un recopilador de flujo de trabajo, un panel de control e interfaces, un programador de tareas y un orquestador de tareas y, finalmente, la supervisión de los componentes de Airflow. Pero para administrar pipelines, esta funcionalidad no fue suficiente en nuestro caso.
Para nosotros, características como la integración del sistema de gestión de canalizaciones con el sistema de compilación y CI, la integración con Kubernetes, la capacidad de gestionar artefactos y la validación de datos eran fundamentales.

Descubrimos lo que nos costaría construir la funcionalidad del sistema terminado al nivel requerido y nos dimos cuenta de que sería mucho más fácil y rápido desarrollar nuestro propio sistema. Lo llamamos Wombat, porque el animal es muy lindo y, en segundo lugar, porque se lo considera el salvador de la naturaleza australiana. Y para nosotros, un sistema que nos permitiera combinar el desarrollo y todas las etapas del trabajo con datos también sería una verdadera salvación.
Que problemas resolvimos
Históricamente, en nuestro equipo de desarrollo, los ingenieros de DevOps brindan soporte a los servicios en producción. Y están acostumbrados a trabajar con pipelines, que no se describen por código, sino por configuraciones en formatos como yaml. Debido a esta discrepancia, debe compartir el soporte o capacitar a los ingenieros para que trabajen con un sistema de integración continua no clásico.
Todo esto sería un trabajo redundante e innecesario, porque los pipelines en forma de gráficos acíclicos dirigidos están perfectamente descritos en el formato que se utiliza en las herramientas estándar de CI y DevOps.

El segundo problema al que nos enfrentamos fue el almacenamiento y control de versiones de los artefactos. Trabajar con artefactos en el sistema de gestión de canalización de datos le permite obtener dos oportunidades muy útiles: reutilizar los resultados de trabajar con canalizaciones y reproducir experimentos con datos, ahorrando tiempo para organizar nuevos experimentos.
Si la organización del almacenamiento de artefactos no está automatizada, tarde o temprano los nuevos artefactos comenzarán a sobrescribir los viejos, o el espacio libre comenzará a agotarse en las máquinas de producción. Además, la producción deberá aplicar requisitos específicos para garantizar la confiabilidad y la tolerancia a fallas del almacenamiento, que es otro proceso costoso.
Por lo tanto, queríamos obtener una solución que realizara todas las tareas relacionadas con la administración de canalizaciones en segundo plano, al tiempo que permitiera a los especialistas en datos trabajar con artefactos de otros proyectos y, al mismo tiempo, no pensar en el costo del almacenamiento de datos.
El tercer problema es la tipificación de los flujos de datos. Sí, Python te permite desarrollar prototipos y probar varias hipótesis a alta velocidad. Pero cuando trabaje con datos, debe prestar atención a los tipos con los que está trabajando si no desea sorpresas inesperadas. Para reducir el número de estos problemas en producción, necesitamos soporte para describir esquemas de datos, hasta describir esquemas de marcos de datos, y la tipificación de datos debe hacerse por separado para el desarrollo y para la producción.
Que pasó al final
Convencionalmente, la arquitectura de Wombat se puede representar así:

Este diagrama muestra la función del sistema. Es una capa intermedia entre la descripción de las tuberías y el sistema CI, con la ayuda de la cual puede trabajar con ellas en producción.
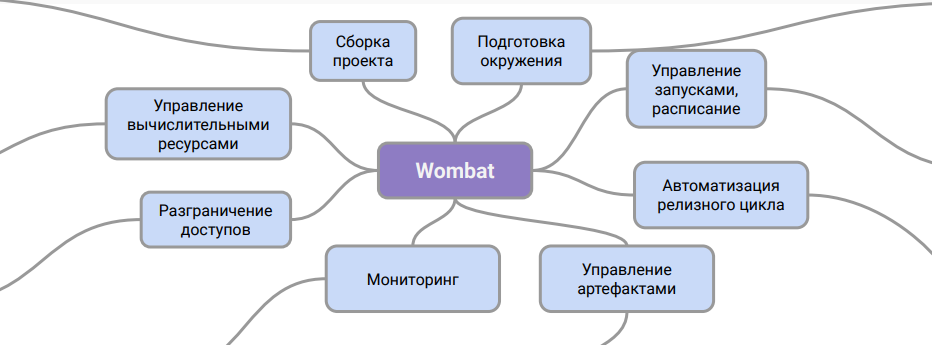
Gracias a este esquema de trabajo, podemos organizar el soporte para pipelines en el departamento de DevOps sin formación adicional para ingenieros y sin involucrar especialistas en datos en este proceso. Además, se resuelve el problema con el almacenamiento de artefactos de datos y su control de versiones.
Ahora estamos desarrollando una funcionalidad que permitirá introducir la herramienta en la etapa inicial de creación de prototipos y experimentación en una forma nativa de los científicos de datos, lo que acelerará significativamente el lanzamiento de proyectos en fase piloto y producción.
Nos estamos preparando para lanzar esta herramienta en código abierto en un futuro muy próximo. Estaremos encantados de que comparta su opinión sobre nuestro proyecto y su experiencia de trabajo con sistemas modernos de canalización de datos.
Además, al darnos cuenta de que este artículo es de naturaleza más informativa que técnica, en un futuro próximo planeamos preparar un texto más detallado y duro. Escribe en los comentarios lo que te gustaría ver y descúbrelo en términos técnicos. Tendremos en cuenta, describiremos y escribiremos. ¡Gracias por la atención!
PD: Todavía estamos interesados en programadores talentosos. ¡Ven, será interesante !