Por lo general, no es costumbre hablar de tales errores, porque solo personas celestiales y sin pecado trabajan en todos los integradores. Como saben, a nivel del ADN, no hay posibilidad de estar equivocado o equivocado.
Pero me arriesgaré. Espero que mi experiencia sea de utilidad para alguien. Tenemos un cliente importante, el comercio minorista en línea, para quien apoyamos completamente la fábrica de Cisco ACI. La empresa no cuenta con un administrador propio competente para este sistema. Una estructura de red es un grupo de conmutadores que tienen un solo centro de control. Además, hay un montón de funciones útiles de las que el fabricante está muy orgulloso, pero al final, para eliminar todo, necesita un administrador, no docenas. Y un centro de control, no decenas de consolas.
La historia comienza así: el cliente quiere transferir el núcleo de toda la red a este grupo de conmutadores. Esta decisión se debe al hecho de que la arquitectura ACI, en la que se "recopila" este grupo de conmutadores, es muy tolerante a fallos. Aunque esto no es típico y en general, una fábrica en cualquier centro de datos no se usa como red de tránsito para otras redes y solo sirve para conectar la carga final (stub network). Pero tal enfoque es bastante posible, por lo que el cliente quiere, lo hacemos.
Entonces sucedió algo banal: confundí dos botones: eliminar la política y eliminar la configuración de un fragmento de la red:
Bueno, entonces, según los clásicos, era necesario volver a ensamblar parte de la red colapsada.
En orden
La solicitud del cliente sonaba así: era necesario construir grupos de puertos separados para la transferencia de equipos directamente a esta fábrica.
Compañeros, transfiera la configuración de los puertos Leaf 1-1 101 y leaf 1-2 102, puertos 43 y 44, a Leaf 1-3 103 y leaf 1-4 104, puertos 43 y 44. A los puertos 43 y 44 en Leaf 1- 1 y 1-2, la pila 3650 está conectada, aún no se ha puesto en funcionamiento, puede transferir la configuración del puerto en cualquier momento.
Es decir, querían transferir el clúster de servidores. Era necesario configurar un nuevo grupo de puertos virtuales para el entorno del servidor. De hecho, esta es una tarea de rutina; por lo general, no hay tiempo de inactividad del servicio para tal tarea. En esencia, un grupo de puertos en la terminología APIC es una VPC que se ensambla a partir de puertos que se encuentran ubicados físicamente en diferentes conmutadores.
El problema es que en la fábrica, la configuración de estos grupos de puertos está vinculada a una entidad separada (que surge debido al hecho de que la fábrica se controla desde el controlador). Este objeto se denomina política de puerto. Es decir, al grupo de puertos que agregamos, también necesitamos aplicar una política general desde arriba como entidad que administrará estos puertos.
Es decir, fue necesario analizar qué EPG se utilizan en los puertos 43 y 44 en los nodos 101 y 102 para poder montar una configuración similar en los nodos 103-104. Después de analizar los cambios necesarios, comencé a configurar los nodos 103-104. Para configurar una nueva VPC en la política de interfaz existente para los nodos 103 y 104, era necesario crear una política en la que se incorporarían las interfaces 43 y 44.
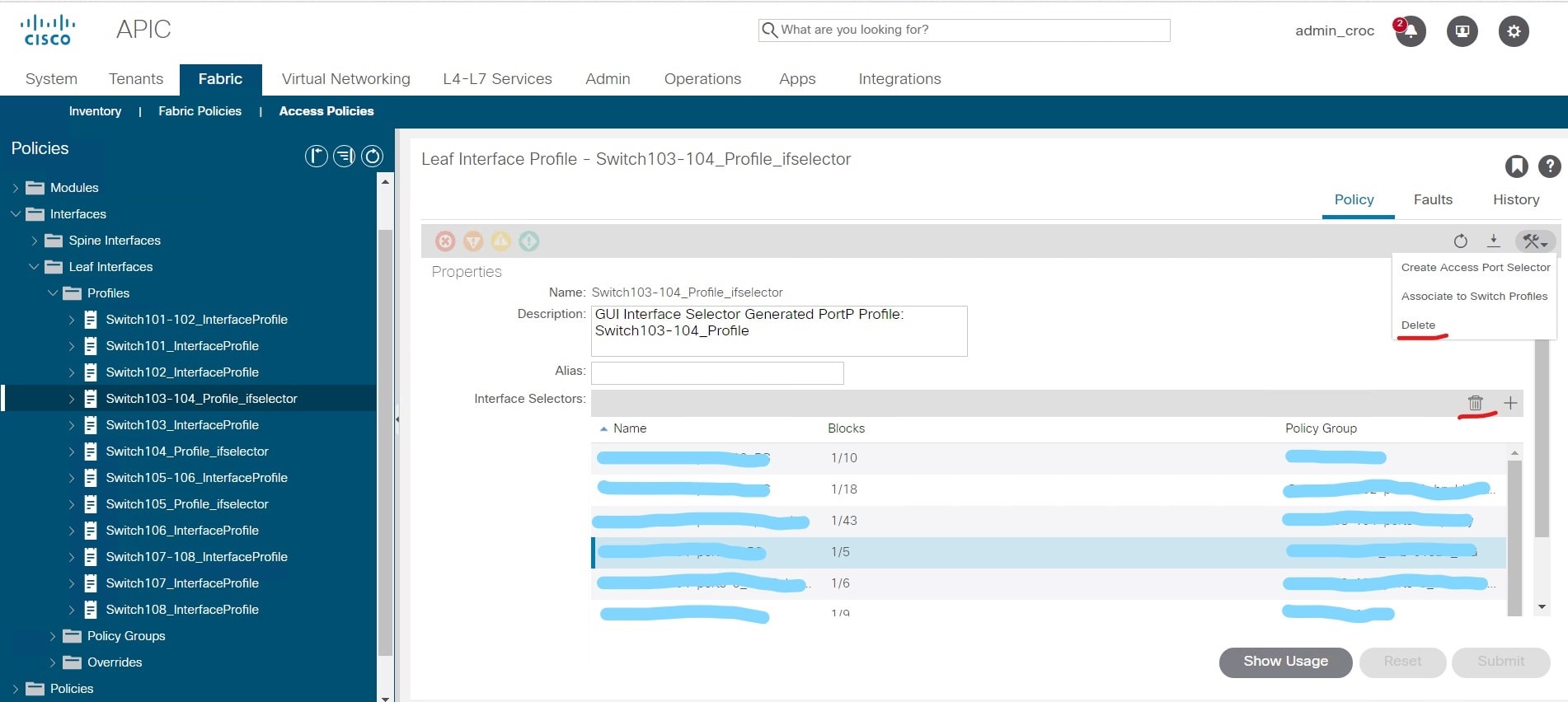
Y hay un matiz en la GUI. Creé esta política y me di cuenta de que durante el proceso de configuración cometí un pequeño error: lo nombré de manera diferente a la personalizada del cliente. Esto no es crítico, porque la política es nueva y no afecta nada. Y tuve que eliminar esta política, ya que ya no se pueden realizar cambios (el nombre no cambia); solo puede eliminar y volver a crear la política.
El problema es que la GUI tiene íconos de eliminación que se refieren a políticas de interfaz y hay íconos que se refieren a políticas de cambio. Visualmente, son casi idénticos. Y en lugar de eliminar la política que creé, eliminé toda la configuración de las interfaces en los conmutadores 103-104: en
lugar de eliminar un grupo, en realidad eliminé todas las VPC de la configuración del nodo, usé eliminar en lugar de papelera.
Estos enlaces tenían VLAN sensibles al negocio. De hecho, después de eliminar la configuración, desactivé parte de la cuadrícula. Además, esto no se notó de inmediato, porque la fábrica no se controla a través del kernel, pero tiene una interfaz de administración separada. No me echaron de inmediato, no hubo ningún error en la fábrica porque la acción fue tomada por el administrador. Y la interfaz piensa: bueno, si dijiste eliminar, entonces debería ser así. No hubo indicios de errores. El software decidió que se estaba realizando algún tipo de reconfiguración. Si el administrador borra el perfil hoja, entonces para la fábrica deja de existir y no escribe un error que indique que no funciona. No funciona, porque se eliminó deliberadamente. No debería funcionar para software.
Entonces el software decidió que yo era Chuck Norris y sabía exactamente lo que estaba haciendo. Todo esta bajo control. El administrador no puede estar equivocado, e incluso cuando se dispara en el pie, esto es parte de un plan astuto.
Pero después de unos diez minutos me expulsaron de la VPN, que inicialmente no asocié con la configuración APIC. Pero esto es al menos sospechoso y me comuniqué con el cliente para aclarar lo que estaba sucediendo. Y durante los siguientes minutos, pensé que el problema era el trabajo técnico, una excavadora repentina o un corte de energía, pero no la configuración de fábrica.
La red del cliente es compleja. Vemos solo una parte del entorno por nuestro acceso. Al restaurar los eventos, todo parece que ha comenzado el reequilibrio del tráfico, después de lo cual, después de unos segundos, el enrutamiento dinámico de los sistemas restantes simplemente no se eliminó.
La VPN en la que estaba era la VPN de administración. Los empleados ordinarios se sentaron en el otro, todo siguió funcionando para ellos.
En general, tomó un par de minutos más de negociaciones para comprender que el problema todavía está en mi configuración. La primera acción en la batalla en tal situación es retroceder a las configuraciones anteriores y solo luego leer los registros, porque esto es prod.
Restauración de fábrica
Se necesitaron 30 minutos para restaurar la fábrica, incluidas todas las llamadas y la recopilación de todos los involucrados.
Encontramos otra VPN por la que puede pasar (esto requería un acuerdo con los guardias de seguridad) y revirtí la configuración de fábrica; en Cisco ACI, esto se hace en dos clics. No hay nada complicado. El punto de restauración simplemente se selecciona. Tarda entre 10 y 15 segundos. Es decir, la recuperación en sí tomó 15 segundos. El resto del tiempo se dedicó a averiguar cómo conseguir el control remoto.
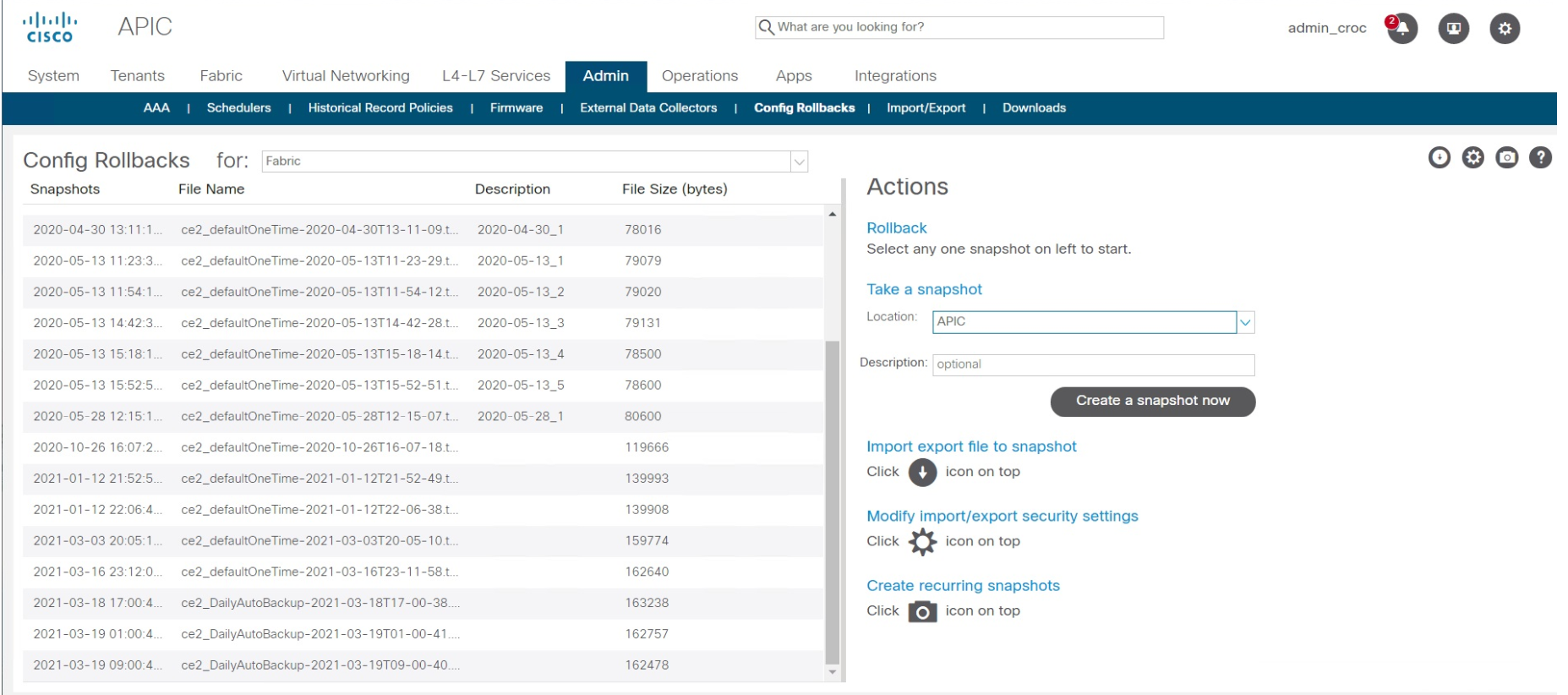
Después del incidente
Otro día analizamos los registros y restauramos la cadena de eventos. Luego montaron una llamada con el cliente, expresaron con calma la esencia y las causas del incidente, propusieron una serie de medidas para minimizar los riesgos de tales situaciones y el factor humano.
Acordamos que solo tocamos las configuraciones de la fábrica durante las horas no laborables: por la noche y por la tarde. Trabajamos con una conexión remota duplicada (hay canales VPN en funcionamiento, hay de respaldo). El cliente recibe una advertencia de nuestra parte y en este momento monitorea los servicios.
El ingeniero (es decir, yo) seguía siendo el mismo en el proyecto. Puedo decir que el sentimiento de confianza en mí se ha vuelto aún mayor que antes del incidente; creo, precisamente porque trabajamos rápidamente en la situación y no permitimos que una ola de pánico cubriera al cliente. Lo principal es que no intentaron ocultar el porro. Por la práctica, sé que en esta situación es más fácil intentar cambiar al proveedor.
Hemos aplicado políticas de redes similares a otros clientes subcontratados: es más difícil para los clientes (canales VPN adicionales, cambios de administrador adicionales fuera del horario de atención), pero muchos han entendido por qué esto es necesario.
También profundizamos en el software Cisco Network Assurance Engine (NAE), donde encontramos la oportunidad de hacer dos cosas simples pero muy importantes en la fábrica de ACI:
- primero, el NAE nos permite analizar el cambio planeado, incluso antes de que lo implementemos en la fábrica y filmemos todo por nosotros mismos, prediciendo cómo el cambio afectará positiva o negativamente la configuración existente;
- en segundo lugar, el NAE, después del cambio, le permite medir la temperatura general de la fábrica y ver cómo este cambio finalmente afectó su salud.
Si está interesado en más detalles - mañana tendremos un webinar sobre la cocina interna de soporte técnico, le diremos cómo funciona todo con nosotros y con los proveedores. También analizaremos errores)