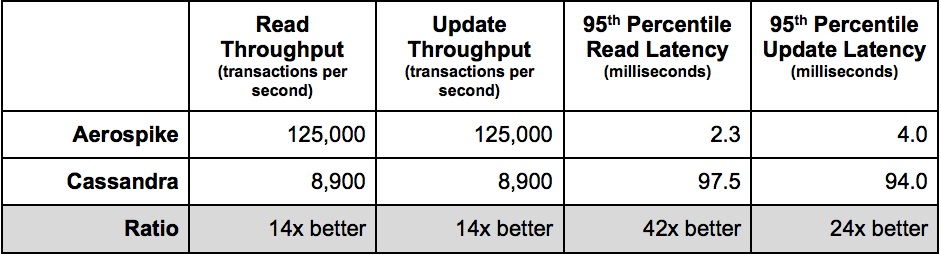
Por una sorprendente coincidencia, Scylla (en adelante SC) también vence fácilmente a CS, que anuncia con orgullo en su página de inicio:

Por lo tanto, surge naturalmente la pregunta, ¿quién cercará a quién, la ballena o el elefante?
En mi prueba, la versión optimizada de HBase (en lo sucesivo, HB) funciona con CS en pie de igualdad, por lo que aquí no será un competidor por la victoria, sino solo en la medida en que todo nuestro procesamiento se basa en HB y quiero comprender sus capacidades en comparación con los líderes.
Está claro que HB y CS son gratuitos, pero por otro lado, si necesita X veces más hardware para lograr el mismo rendimiento, es más rentable pagar por software que asignar un piso en el centro de datos por costosos almohadillas térmicas. Especialmente teniendo en cuenta que si hablamos de rendimiento, dado que los HDD, en principio, no pueden dar al menos una velocidad aceptable de lecturas de acceso aleatorio (consulte " Por qué el disco duro y las lecturas rápidas de acceso aleatorio son incompatibles "), lo que a su vez significa comprar SSD, que en los volúmenes necesarios para un BigData real, es un placer bastante caro.
Entonces, se hizo lo siguiente. Alquilé 4 servidores en la nube de AWS en la configuración i3en.6xlarge donde cada uno a bordo:
CPU - 24 vcpu
MEM - 192 GB
SSD - 2 x 7500 GB
Si alguien quiere repetirlo, inmediatamente notamos que es muy importante para la reproducibilidad tomar configuraciones donde el volumen total de discos (7500 GB). De lo contrario, habrá que compartir los discos con vecinos impredecibles, lo que seguramente arruinará tus pruebas, ya que probablemente parezcan una carga muy valiosa.
A continuación, implementé SC utilizando el constructor , que fue amablemente proporcionado por el fabricante en su propio sitio web. Luego cargué la utilidad YCSB (que es casi un estándar para las pruebas de bases de datos comparativas) para cada nodo del clúster.
Solo hay un matiz importante, en casi todos los casos usamos el siguiente patrón: leer el registro antes de cambiar + escribir el nuevo valor.
Así que modifiqué la actualización de la siguiente manera:
@Override
public Status update(String table, String key,
Map<String, ByteIterator> values) {
read(table, key, null, null); // << added read before write
return write(table, key, updatePolicy, values);
}
Luego comencé la carga simultáneamente desde los 4 hosts (los mismos donde se encuentran los servidores de la base de datos). Esto se hace deliberadamente, porque a veces los clientes de algunas bases de datos consumen más CPU que otras. Teniendo en cuenta que el tamaño del clúster es limitado, me gustaría comprender la eficiencia general de la implementación de las partes del servidor y del cliente.
Los resultados de la prueba se presentarán a continuación, pero antes de pasar a ellos, vale la pena considerar algunos matices más importantes.
En cuanto a AS, se trata de una base de datos muy atractiva, líder en la categoría de satisfacción del cliente según el recurso g2.
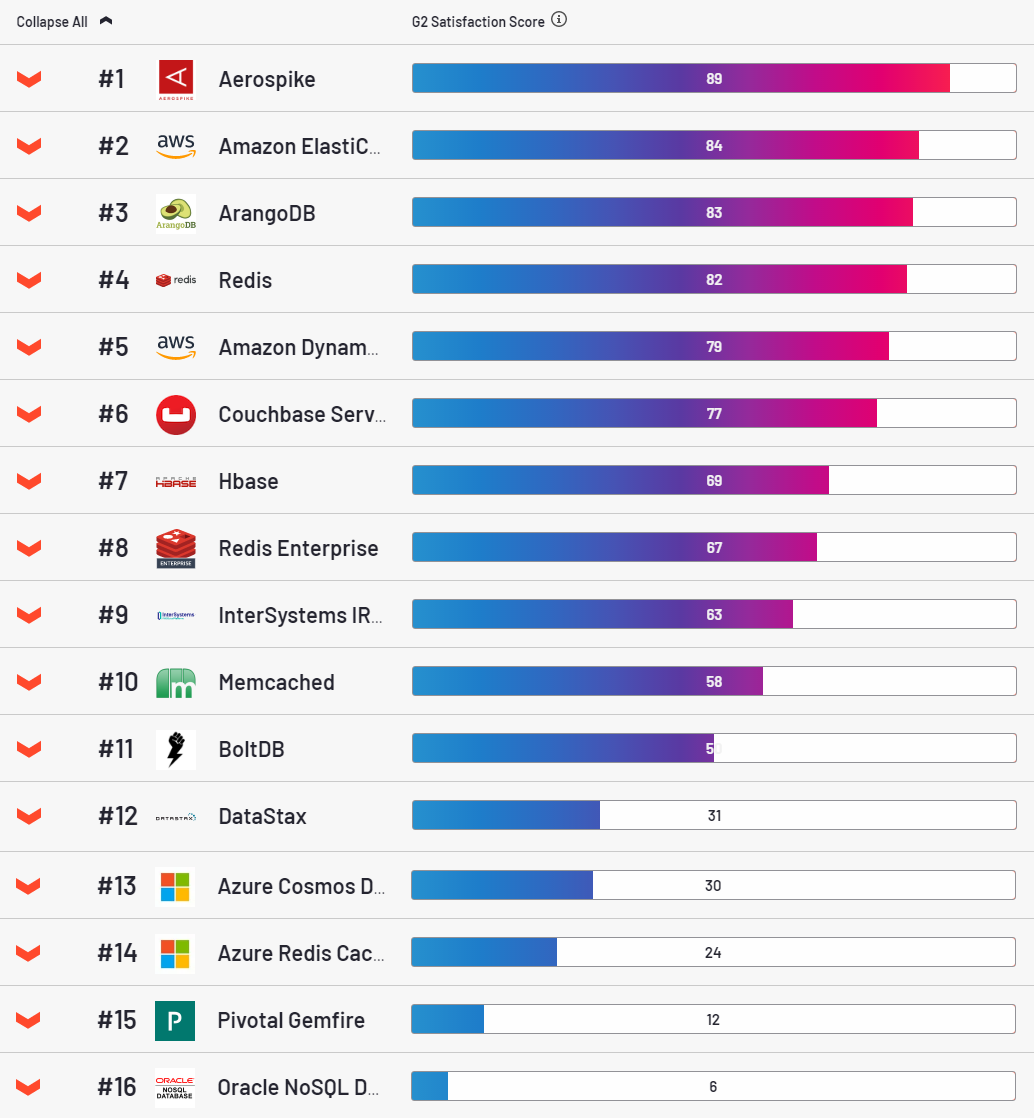
Francamente, de alguna manera también me gustó. En pocas palabras, con este script.se despliega en la nube con bastante facilidad. Estable, es un placer configurarlo. Sin embargo, tiene un gran inconveniente. Para cada clave, asigna 64 bytes de RAM. Parece un poco, pero en volúmenes industriales se convierte en un problema. Una entrada típica en nuestras tablas es de 500 bytes. Es esta cantidad de valor la que utilicé en casi * todas las pruebas (* por qué casi se dirá a continuación).
Como almacenamos 3 copias de cada registro, resulta que para almacenar 1 PB de datos limpios (3 PB de datos sucios), tendremos que asignar solo 400 TB de RAM. Continuando ... ¡¿no qué ?! Espera un segundo, ¿hay algo que puedas hacer al respecto? - le preguntamos al vendedor.
Ja, por supuesto que puedes hacer muchas cosas, dobla los dedos:
Bien, ahora tratemos con HB y ya podemos considerar los resultados de la prueba. Para instalar Hadoop, Amazon proporciona la plataforma EMR, que facilita la implementación del clúster que necesita. Solo tuve que aumentar los límites en la cantidad de procesos y archivos abiertos; de lo contrario, se bloqueó bajo carga y reemplazó hbase-server con mi ensamblaje optimizado (vea los detalles aquí ). El segundo punto, HB se ralentiza descaradamente cuando trabaja con solicitudes únicas, esto es un hecho. Por tanto, solo trabajamos por lotes. En esta prueba, lote = 100. Hay 100 regiones en la tabla.
Bueno, y en el último momento, todas las bases de datos fueron probadas en el modo de "consistencia fuerte". Para HB, está listo para usar. AS está disponible solo en la versión empresarial (es decir, se habilitó en esta prueba). SC se ejecutó en modo coherente de escritura = todo. El factor de replicación está en todas partes. 3.
Entonces, vamos. Insertar en AS:
10 seg: 360554 operaciones; 36055,4 operaciones actuales / seg;
20 s: 698872 operaciones; 33831,8 operaciones actuales / seg;
...
230 seg: 7412626 operaciones; 22938,8 operaciones actuales / seg;
240 s: 7542091 operaciones; 12946,5 operaciones actuales / seg;
250 s: 7589682 operaciones; 4759,1 operaciones actuales / seg;
260 s: 7599525 operaciones; 984,3 operaciones actuales / seg;
270 s: 7602150 operaciones; 262,5 operaciones actuales / seg;
280 s: 7602752 operaciones; 60,2 operaciones actuales / seg;
290 s: 7602918 operaciones; 16,6 operaciones actuales / seg;
300 s: 7603269 operaciones; 35,1 operaciones actuales / seg;
310 s: 7603674 operaciones; 40,5 operaciones actuales / seg;
Error al escribir la clave user4809083164780879263: com.aerospike.client.AerospikeException $ Timeout: Client timeout: timeout = 10000 iterations = 1 failedNodes = 0 failedConns = 0 lastNode = 5600000A 127.0.0.1:3000
Error al insertar, no se vuelve a intentar más. número de intentos: 1 Límite de reintentos de inserción: 0
Vaya, definitivamente eres un
Bien, continuemos. Comenzamos a cargar 200 millones de registros (INSERTAR), luego ACTUALIZAR, luego OBTENER. Esto es lo que sucedió (operaciones - operaciones por segundo):

¡IMPORTANTE! ¡Esta es la velocidad de un nodo! Hay 4 de ellos en total, es decir para obtener la velocidad total, debes multiplicar por 4.
La primera columna tiene 10 campos, esta no es una prueba del todo justa. Esos. esto es cuando el índice está en la memoria, lo cual es inalcanzable en una situación real de BigData.
La segunda columna empaqueta 10 registros en 1. ya hay ahorros de memoria reales, exactamente 10 veces. Como puede ver claramente en la prueba, este truco no es en vano, el rendimiento cae significativamente. La razón es obvia, cada vez que se procesa un registro, hay que lidiar con 9 adyacentes. La sobrecarga es más corta.
Y finalmente todo al ras, aquí hay aproximadamente la misma imagen. Las inserciones al ras son peores, pero la operación de actualización de teclas es más rápida, por lo que además solo compararemos con todo al ras.
En realidad, no tiremos del gato, de inmediato:

todo está generalmente claro, pero lo que debería agregarse aquí.
- AS , .
- SC - , :

Quizás en algún lugar haya una jamba con la configuración o ese error con el kernel surgió, no lo sé. Pero configuré todo desde y hasta el guión del proveedor, por lo que el ciclomotor no es mío, todas las preguntas son para él.
También debe comprender que se trata de una cantidad muy modesta de datos y que en grandes volúmenes la situación puede cambiar. Durante los experimentos, quemé varios cientos de dólares, por lo que el entusiasmo fue suficiente solo para una prueba de líder a largo plazo y en un modo limitado a un servidor.
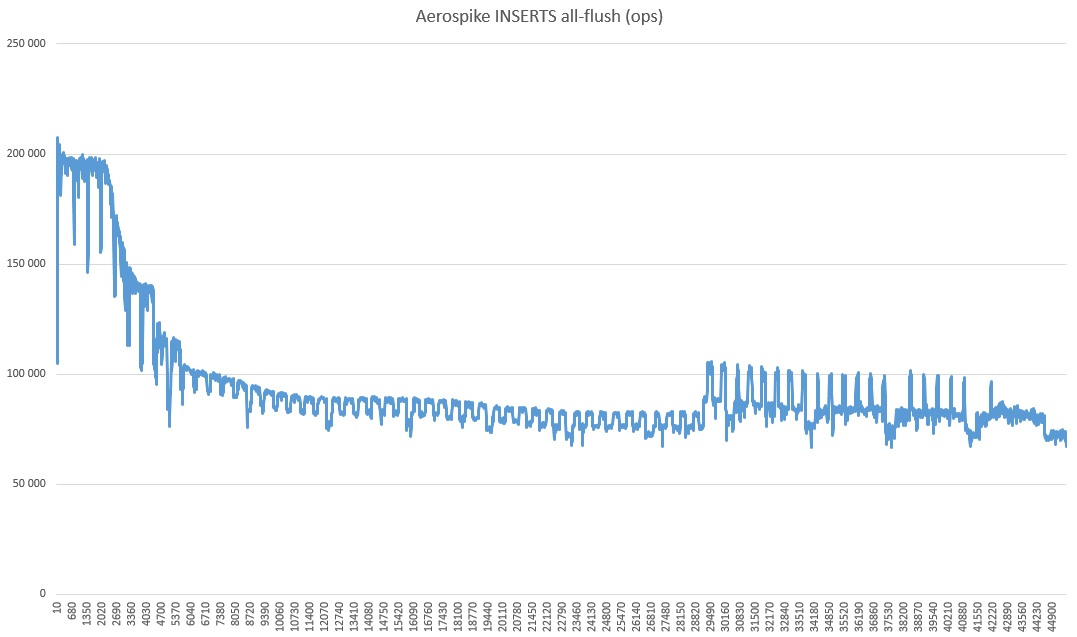
Por qué ha disminuido tanto y qué tipo de avivamiento en el último tercio es un misterio de la naturaleza. También puedes notar que la velocidad es radicalmente más alta que en las pruebas, un poco más alta. Supongo que esto se debe a que el modo de coherencia fuerte está desactivado (ya que solo hay un servidor).
Y finalmente, OBTENGA + ESCRIBA (además de más de tres mil millones de registros inundados con la prueba):
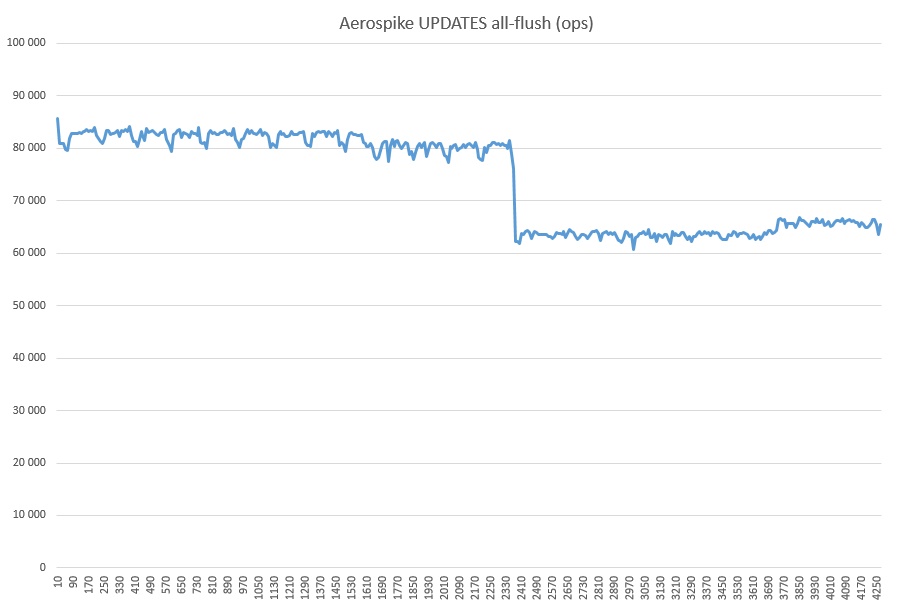
Qué tipo de reducción es esta, no creo que en mi corazón. No se iniciaron procesos ajenos. Quizás tenga algo que ver con la caché SSD, porque la utilización durante toda la prueba de AS en el modo de limpieza total fue del 100%.

Eso es todo. Las conclusiones son generalmente claras, se necesitan más pruebas. Es deseable para todas las bases de datos más populares en las mismas condiciones. En Internet, este género de alguna manera no es mucho. Y sería bueno, entonces los proveedores base estarán motivados para optimizar y elegiremos deliberadamente los mejores.