
En Playrix, se asigna una cantidad significativa de recursos para la preparación y el análisis de datos, tratamos de utilizar tecnologías avanzadas y nos tomamos en serio la capacitación de los empleados. La compañía se encuentra entre los 3 principales desarrolladores de juegos móviles del mundo, por lo que intentamos mantener el nivel adecuado en análisis de datos y específicamente en Business Intelligence. Más de 27 millones de usuarios juegan a nuestros juegos todos los días, y esta cifra puede dar una idea aproximada de la cantidad de datos que generan los dispositivos móviles todos los días. Además, los datos se toman de docenas de servicios en varios formatos, después de lo cual se agregan y se cargan en nuestros almacenes. Trabajamos con AWS S3 como Data Lake, mientras que Data Warehouse en AWS Redshift y PostgreSQL tiene un uso limitado. Usamos estas bases de datos para análisis. Redshift es más rápido pero más caropor eso almacenamos allí los datos más solicitados. PostgreSQL es más barato y lento, almacena pequeñas cantidades de datos o datos cuya velocidad de lectura no es crítica. Para los datos agregados previamente, utilizamos el clúster Hadoop e Impala.
La principal herramienta de BI de Playrix es Tableau. Este producto es bien conocido en el mundo, tiene amplias oportunidades para el análisis y visualización de datos, trabaja con diversas fuentes. Además, no tiene que escribir código para tareas de análisis simples, por lo que puede capacitar a los usuarios de diferentes departamentos para que analicen sus datos comerciales por su cuenta. El proveedor de la herramienta Tableau Software también posiciona su producto como una herramienta de autoanálisis de datos, es decir, de autoservicio.
Hay dos enfoques principales para el análisis de datos en BI:
- Fábrica de informes . Este enfoque tiene un departamento y / o personas que desarrollan informes para usuarios comerciales.
- Self-Service. - .
El primer enfoque es tradicional y la mayoría de las empresas tienen una fábrica de producción de informes para toda la empresa como esta. El segundo enfoque es relativamente nuevo, especialmente para Rusia. Es bueno porque los datos son investigados por los propios usuarios comerciales: conocen mucho mejor sus procesos locales. Esto ayuda a descargar a los desarrolladores, aliviarlos de la necesidad de sumergirse en los detalles de los procesos del equipo y crear los informes más básicos en todo momento. Esto ayuda a resolver lo que probablemente sea el mayor problema: salvar el abismo entre los usuarios comerciales y los desarrolladores. Después de todo, el principal problema del enfoque de Reporting Factory es precisamente que la mayoría de los informes pueden permanecer sin reclamar solo debido al hecho de que los programadores-desarrolladores malinterpretan los problemas de los usuarios comerciales y, en consecuencia, crean informes innecesarios.que se vuelven a trabajar más tarde o simplemente no se utilizan.
En Playrix, los programadores y analistas se involucraron inicialmente en el desarrollo de informes en la empresa, es decir, especialistas que trabajan con datos a diario. Pero la empresa se está desarrollando muy rápidamente, y a medida que crecen las necesidades de los usuarios de informes, los desarrolladores de informes han dejado de estar a tiempo para resolver todas las tareas de su creación y soporte. Entonces surgió la pregunta de expandir el grupo de desarrollo de BI o transferir competencias a otros departamentos. La dirección de autoservicio nos pareció prometedora, por lo que decidimos enseñar a los usuarios comerciales a crear sus propios proyectos y analizar los datos por su cuenta.
En Playrix, la división de Business Intelligence (BI Team) trabaja en las siguientes tareas:
- Recolección, preparación y almacenamiento de datos.
- Desarrollo de servicios de analítica interna.
- Integración con servicios externos.
- Desarrollo de interfaces web.
- Desarrollo de informes en Tableau.
Nos dedicamos a la automatización de procesos internos y análisis. De forma simplificada, nuestra estructura se puede representar mediante el diagrama:

Mini-equipos BI Team Los
rectángulos aquí representan mini-equipos. En los equipos laterales izquierdos, en los equipos delanteros derechos. Cada uno tiene las competencias suficientes para trabajar con las tareas de los equipos relacionados y asumirlas cuando los otros equipos están sobrecargados.
El equipo de BI tiene un ciclo de desarrollo completo: desde la recopilación de requisitos hasta la implementación en un entorno de producto y el soporte posterior. Cada mini equipo tiene su propio analista de sistemas, desarrolladores e ingenieros de pruebas. Sirven como la fábrica de informes , preparando datos e informes para uso interno.
Es importante señalar aquí que en la mayoría de los proyectos de Tableau no desarrollamos informes simples, que generalmente se muestran en demostraciones, sino herramientas con una gran funcionalidad, un gran conjunto de controles, amplias capacidades y conexión de módulos externos. Estas herramientas se revisan constantemente, se agregan nuevas funciones.
Sin embargo, también surgen problemas locales simples, que pueden ser resueltos por el propio cliente.
Transferencia de competencias y puesta en marcha de un proyecto piloto
Según nuestra experiencia de trabajo y comunicación con otras empresas, los principales problemas a la hora de transferir competencias de datos a los usuarios empresariales son:
- La renuencia de los propios usuarios a aprender nuevas herramientas y trabajar con datos.
- Falta de apoyo de la dirección (inversión en formación, licencias, etc.).
El apoyo de nuestra dirección es colosal, además, la dirección se ofreció a introducir el Autoservicio. Los usuarios también desean aprender a trabajar con datos y Tableau; esto es interesante para los muchachos, además, el análisis de datos ahora es una habilidad muy importante que definitivamente será útil en el futuro.
Implementar una nueva ideología a la vez en toda la empresa generalmente requiere muchos recursos y nervios, por lo que comenzamos con un piloto. El proyecto piloto de Autoservicio se puso en marcha en el departamento de Adquisición de Usuarios hace un año y medio, y durante el proceso piloto se acumularon errores y experiencia para traspasarlos a otros departamentos en el futuro.
La dirección de Adquisición de Usuarios trabaja en las tareas de aumentar la audiencia de nuestros productos, analiza las formas de comprar tráfico y elige en qué direcciones para atraer usuarios vale la pena invertir los fondos de la empresa. Anteriormente, para esta dirección, los informes eran elaborados por el equipo de BI, o los propios chicos procesaban las cargas desde la base de datos utilizando Excel o Google Sheets. Pero en un entorno de desarrollo dinámico, dicho análisis conlleva retrasos y la cantidad de datos analizados está limitada por las capacidades de estas herramientas.
Al comienzo de la prueba piloto, realizamos una capacitación básica para que los empleados trabajaran con Tableau y creamos la primera fuente de datos común: una tabla en la base de datos de Redshift, en la que había más de 500 millones de filas y las métricas necesarias. Cabe señalar que Redshift es una base de datos en columnas (o en columnas), y esta base de datos sirve datos mucho más rápido que las bases de datos relacionales. La mesa piloto en Redshift era realmente grande para las personas que nunca trabajaron con más de 1 millón de filas al mismo tiempo. Pero fue un desafío para los muchachos aprender a trabajar con datos de tales volúmenes.
Sabíamos que los problemas de rendimiento comenzarían a medida que estos informes se volvieran más complejos. No les dimos a los usuarios acceso a la base de datos en sí, pero se implementó una fuente en el servidor de Tableau, conectado en modo en vivo a una tabla en Redshift. Los usuarios tenían licencias Creator y podían conectarse a esta fuente desde el servidor de Tableau, desarrollando informes allí o desde Tableau Desktop. Debo decir que al desarrollar informes en la web (Tableau tiene un modo de edición web), existen algunas limitaciones en el servidor. Tableau Desktop no tiene tales restricciones, por lo que desarrollamos principalmente en Desktop. Además, si solo un usuario empresarial necesita análisis, no es necesario publicar dichos proyectos en el servidor; puede trabajar localmente.
Capacitación
En nuestra empresa es habitual realizar webinars e intercambio de conocimientos, en los que cada empleado puede hablar sobre nuevos productos, funcionalidades o capacidades de las herramientas con las que trabaja o que está investigando. Todas estas actividades se registran y almacenan en nuestra base de conocimientos. Este proceso también funciona en nuestro equipo, por lo que también compartimos conocimientos periódicamente o preparamos webinars de formación fundamental.
Para todos los usuarios con licencias de Tableau, organizamos y grabamos un seminario web de media hora sobre cómo trabajar con el servidor y los paneles. Hablaron de proyectos en el servidor, trabajando con los controles nativos de todos los paneles: este es el panel superior (actualizar, pausar, ...). Es imperativo informar a todos los usuarios de Tableau sobre esto para que puedan trabajar completamente con las capacidades nativas y no realizar solicitudes para el desarrollo de funciones que repiten el trabajo de los controles nativos.
El principal obstáculo para dominar una herramienta (y de hecho algo nuevo) suele ser el miedo a que no sea posible comprender y trabajar con esta funcionalidad. Por lo tanto, la capacitación es quizás el paso más importante en la implementación del enfoque de BI de autoservicio. El resultado de la implementación de este modelo dependerá en gran medida de él: si se arraigará en la empresa y, de ser así, con qué rapidez. En los seminarios web de lanzamiento, se deben eliminar las barreras para usar Tableau.
Hay dos grupos de seminarios web que realizamos para personas que no están familiarizadas con el trabajo de las bases de datos:
- Kit de conocimientos para principiantes:
- Conexión de datos, tipos de conexión, tipos de datos, transformaciones básicas de datos, normalización de datos (1 hora).
- Visualizaciones básicas, agregación de datos, cálculos básicos (1 hora).
- /, (2 ).
En este primer seminario web de lanzamiento, cubrimos todo lo relacionado con la conectividad de datos y la transformación de datos en Tableau. Dado que las personas suelen tener un nivel básico de competencia en MS Excel, es importante explicar aquí cómo trabajar en Excel es fundamentalmente diferente de trabajar en Tableau. Este es un punto muy importante, porque necesita cambiar a una persona de la lógica de las tablas con celdas coloreadas a la lógica de los datos normalizados de la base de datos. En el mismo webinar, explicamos el trabajo de JOIN, UNION, PIVOT y también tocamos Blending. En el primer seminario web, apenas tocamos la visualización de datos, su objetivo es explicar cómo trabajar y transformar sus datos para Tableau. Es importante que las personas comprendan que los datos son primarios y que la mayoría de los problemas surgen a nivel de datos, no a nivel de visualización.
El segundo seminario web sobre autoservicio tiene como objetivo hablar sobre la lógica de crear visualizaciones en Tableau. Tableau es muy diferente de otras herramientas de BI precisamente en que tiene su propio motor y su propia lógica. En otros sistemas, por ejemplo, en PowerBI, hay un conjunto de elementos visuales listos para usar (puede descargar módulos adicionales en la tienda), pero estos módulos no son personalizables. En Tableau, en realidad tiene una pizarra en blanco en la que puede crear lo que quiera. Por supuesto, Tableau tiene ShowMe, un menú de visualizaciones básicas, pero todos estos gráficos y diagramas pueden y deben construirse de acuerdo con la lógica de Tableau. En nuestra opinión, si desea enseñarle a alguien a trabajar con Tableau, no necesita usar ShowMe para crear gráficos; la mayoría de ellos no serán útiles para las personas al principio, pero debe enseñar exactamente la lógica de la construcción. visualizaciones. Para los cuadros de mando empresariales, basta con sabercómo construir:
- Series de tiempo. Gráficos de líneas / áreas (gráficos de líneas),
- Gráfica de barras
- Gráfico de dispersión,
- Mesas
Este conjunto de visualizaciones es suficiente para el autoanálisis de los datos.
Series temporales: se utilizan con mucha frecuencia en los negocios porque es interesante comparar métricas en diferentes periodos de tiempo. Probablemente, todos los empleados de la empresa estén mirando la dinámica de los resultados comerciales en nuestro país. Usamos gráficos de barras para comparar métricas por categoría. Los gráficos de dispersión rara vez se utilizan, generalmente para encontrar correlaciones entre métricas. Tablas: algo de lo que los tableros comerciales no pueden deshacerse por completo, pero siempre que sea posible intentamos minimizar su número. En tablas, recopilamos los valores numéricos de métricas por categoría.
Es decir, enviamos a las personas a flote libre después de 1 hora de entrenamiento en el trabajo con datos y 1 hora de entrenamiento en cálculos básicos y visualizaciones. Luego, los propios chicos trabajan con sus datos durante algún tiempo, se enfrentan a problemas, adquieren experiencia, simplemente ponen sus manos en ellos. Esta etapa dura de 2 a 4 semanas en promedio. Naturalmente, durante este período existe la oportunidad de consultar con el equipo de BI si algo no funciona.
Después de la primera etapa, los colegas deben mejorar sus habilidades y explorar nuevas oportunidades. Para ello, hemos preparado webinars de formación en profundidad. En ellos, mostramos cómo trabajar con funciones LOD, funciones de tabla, scripts de Python para TabPy. Trabajamos con datos de la empresa en vivo, que siempre son más interesantes que los datos falsos o del conjunto de datos básico de Tableau: Superstore. En los mismos seminarios web, hablamos sobre las principales funciones y trucos de Tableau que se utilizan en paneles de control patentados, por ejemplo:
- Intercambio de hojas (sustitución de hojas),
- Agregación de gráficos usando parámetros,
- Formatos de fecha y métrica
- Descartando períodos incompletos para agregaciones semanales / mensuales.
Todos estos trucos y funciones eran habituales hace un par de años, por lo que todos en la empresa se acostumbraron a ellos y los adoptamos en los estándares de desarrollo del tablero. Usamos scripts de Python para calcular algunas métricas internas, todos los scripts ya están listos y para el autoservicio necesitamos entender cómo insertarlos en nuestros cálculos.
Por lo tanto, solo realizamos 4 horas de seminarios web para iniciar el autoservicio, y esto suele ser suficiente para que una persona motivada comience a trabajar con Tableau y analice los datos por su cuenta. Además, para los analistas de datos, tenemos nuestros propios seminarios web, están disponibles públicamente y puede familiarizarse con ellos.
Desarrollo de fuentes de datos para autoservicio
Una vez realizado el proyecto piloto, lo consideramos exitoso y ampliamos el número de usuarios de Autoservicio. Uno de los grandes desafíos fue preparar fuentes de datos para diferentes equipos. Los chicos de Self-Service pueden trabajar con más de 200 millones de filas, por lo que el equipo de ingeniería de datos tuvo que descubrir cómo implementar dichas fuentes de datos. Para la mayoría de las tareas analíticas, utilizamos Redshift debido a la velocidad de lectura de datos y la facilidad de uso. Pero dar acceso a la base de datos a cada persona desde Self-Service era arriesgado desde el punto de vista de la seguridad de la información.
La primera idea fue crear fuentes con una conexión en vivo a la base de datos, es decir, se publicaron varias fuentes en Tableau Server que buscaban en tablas o en vistas preparadas de Redshift. En este caso, no almacenamos datos en el servidor de Tableau y los usuarios a través de estas fuentes pasaron de su Tableau Desktop (clientes) a la base de datos. Esto funciona cuando las tablas son pequeñas (millones) o las consultas de Tableau no son demasiado complejas. A medida que se desarrollaban, los chicos comenzaron a complicar sus paneles en Tableau, usar LOD, ordenaciones personalizadas y scripts de Python. Naturalmente, esto provocó una desaceleración en el trabajo de algunos paneles de autoservicio. Por lo tanto, unos meses después del inicio de Self-Service, revisamos el enfoque para trabajar con fuentes.
El nuevo enfoque que hemos estado usando hasta ahora ha implementado extractos publicados en Tableau Server. Debo decir que Autoservicio tiene constantemente nuevas tareas, y reciben solicitudes para agregar nuevos campos a la fuente, por supuesto, las fuentes de datos se modifican constantemente. Hemos desarrollado la siguiente estrategia para trabajar con fuentes:
- Según los términos de referencia para la fuente desde el lado del autoservicio, los datos se recopilan en las tablas de la base de datos.
- Se crea una vista inmaterializada en el esquema de prueba de la base de datos de Redshift.
- El equipo de control de calidad prueba la exactitud de los datos.
- En caso de un resultado positivo de la verificación, la vista se eleva sobre el esquema Prodoval Redshift.
- El equipo de ingeniería de datos tiene una perspectiva de soporte: los scripts para analizar la validez de los datos están conectados, las alarmas ETL están conectadas y los derechos de lectura se otorgan al equipo de autoservicio.
- Tableau Server (), .
- ETL .
- .
- , Self-Service.
Un poco sobre el punto 7. De forma nativa, Tableau le permite crear extractos en un horario con una diferencia mínima de 5 minutos. Si sabe con certeza que sus tablas en la base de datos siempre se actualizan a las 4 a. M., Simplemente puede configurar el extracto a las 5 a. M. Para que se recopilen sus datos. Esto cubre una variedad de tareas. En nuestro caso, las tablas se recopilan de acuerdo con los datos de varios proveedores, incluido. En consecuencia, si un proveedor o nuestro servicio interno no logró actualizar su parte de los datos, entonces toda la tabla se considera inválida. Es decir, no puede simplemente establecer un horario para un tiempo fijo. Por lo tanto, usamos la API de Tableau para ejecutar extractos cuando las tablas están listas. Las señales de lanzamiento de extractos son generadas por nuestro servicio ETL después de asegurarse de que todos los datos nuevos hayan llegado y sean válidos.
Este enfoque le permite tener datos nuevos y válidos en el extracto con una latencia mínima.
Publicación de paneles de autoservicio en Tableau Server
Deliberadamente no limitamos a las personas a experimentar con sus datos y nos permitimos publicar y compartir nuestros libros de trabajo. Dentro de cada equipo, si una persona cree que su tablero es útil para otros, o que el empleado necesita un tablero en el servidor, puede publicarlo. El equipo de BI no interfiere en los experimentos internos de los equipos, respectivamente, ellos mismos elaboran toda la lógica de los cuadros de mando y los cálculos. Hay casos en los que un proyecto interesante surge del autoservicio, que luego se transfiere completamente al soporte del equipo de BI y pasa a producción. Este es exactamente el efecto del autoservicio, cuando las personas, al tener un buen conocimiento de sus tareas comerciales, comienzan a trabajar con sus datos y forman una nueva estrategia para su trabajo. En base a esto, hicimos el siguiente esquema de proyectos en el servidor:
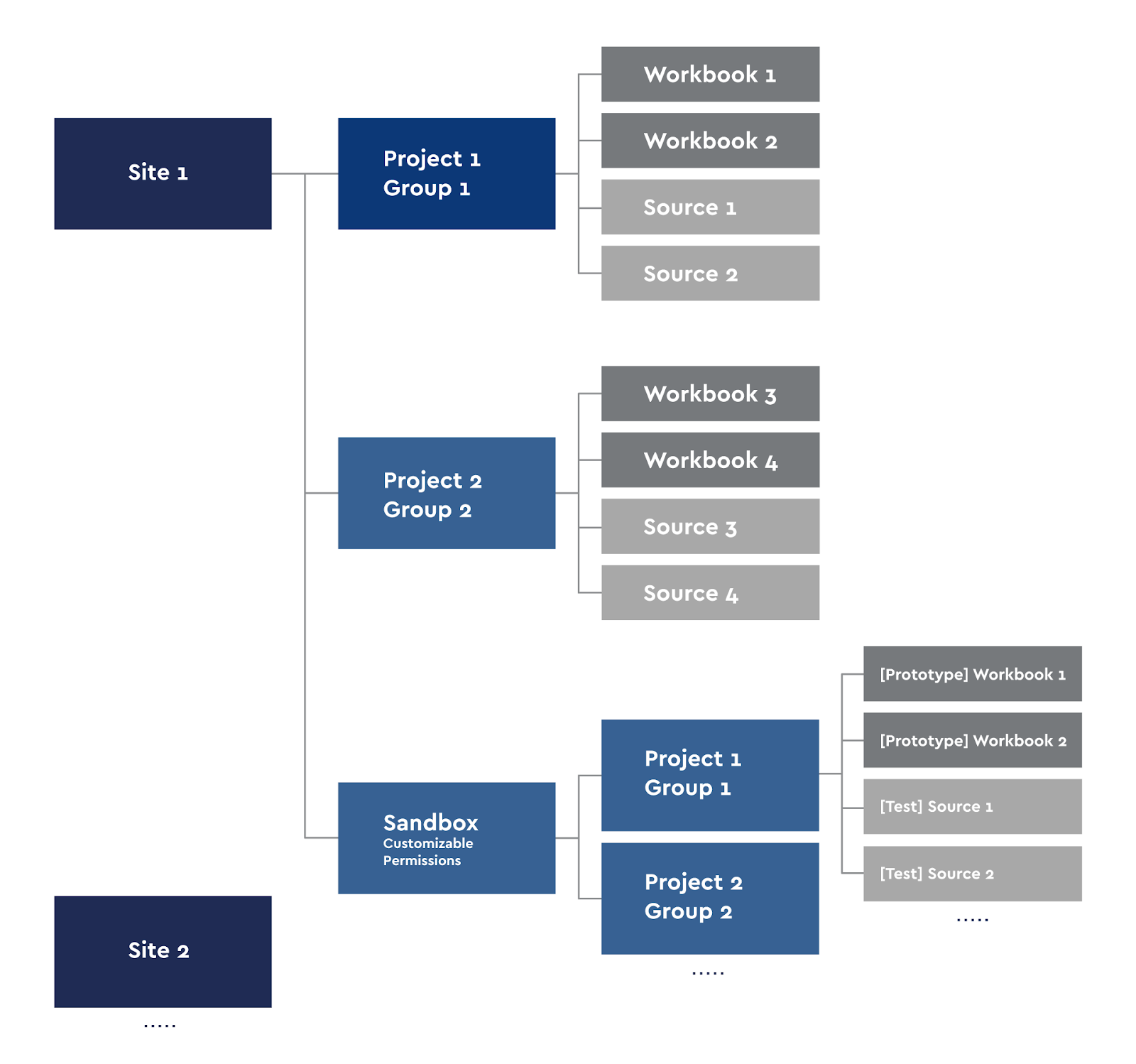
Diagrama del proyecto de Tableau Server
Cada usuario de Creator puede publicar sus libros de trabajo en el servidor o realizar el análisis localmente. Para el autoservicio, creamos nuestro propio Sandbox con nuestros grupos de proyectos.
Los sitios en Tableau están divididos ideológicamente para que los usuarios de un sitio no vean el contenido de otro, por lo que dividimos el servidor en sitios en áreas que no se superponen: por ejemplo, análisis de juegos y finanzas. Estamos usando acceso grupal. Cada sitio tiene proyectos en los que se heredan los derechos de sus libros de trabajo y fuentes. Es decir, el grupo de usuarios Grupo 1 solo ve sus libros de trabajo y fuentes de datos. La excepción a esta regla es el sitio Sandbox, que también tiene subproyectos. Usamos Sandbox para la creación de prototipos, desarrollando nuevos cuadros de mando, probándolos y para las necesidades de Autoservicio. Cualquiera con acceso de publicación a su proyecto Sandbox puede publicar sus prototipos.
Supervisión de fuentes y paneles en Tableau Server
Dado que transferimos la carga de solicitudes de paneles de autoservicio desde la base de datos a Tableau Server, trabajamos con grandes fuentes de datos y no limitamos a las personas en las solicitudes a fuentes publicadas, surgió otro problema: monitorear el rendimiento de dichos paneles y monitorear el creado fuentes.
Monitorear el rendimiento de los paneles y el rendimiento de los servidores de Tableau es una tarea que enfrentan las empresas medianas y grandes, por lo tanto, se han escrito bastantes artículos sobre el rendimiento de los paneles y su ajuste. No nos convertimos en pioneros en esta área, nuestro monitoreo consiste en varios tableros basados en la base de datos interna de PostgreSQL Tableau Server. Esta supervisión funciona con todo el contenido, pero puede seleccionar paneles de autoservicio y ver su rendimiento.
El equipo de BI resuelve problemas de optimización del tablero de vez en cuando. A los usuarios a veces se les ocurre la pregunta "¿Por qué el panel de control es lento?", Y debemos entender qué es "lento" desde el punto de vista del usuario y qué criterios numéricos pueden caracterizar este "lento". Para no entrevistar al usuario y no quitarle su tiempo de trabajo para un recuento detallado de los problemas, monitoreamos y analizamos las solicitudes http, buscamos las más lentas y averiguamos los motivos. Después de eso, optimizaremos los paneles, si esto puede llevar a un aumento en el rendimiento. Está claro que con una conexión en vivo a las fuentes, habrá retrasos asociados con la formación de una vista en la base de datos, retrasos en la recepción de datos. También hay retrasos en la red que estamos investigando con nuestro equipo de soporte para toda la infraestructura de TI, pero no nos detendremos en ellos en este artículo.
Un poco sobre las solicitudes http
Cada interacción del usuario con el tablero en el navegador inicia su propia solicitud http, transmitida a Tableau Server. El historial completo de dichas consultas se almacena en la base de datos interna de PostgreSQL Tableau Server, el período de almacenamiento predeterminado es de 7 días. Este período se puede aumentar cambiando la configuración de Tableau Server, pero no queríamos aumentar la tabla de solicitudes http, por lo que solo recopilamos un extracto incremental que solo contiene datos nuevos todos los días, mientras que los antiguos no se sobrescriben. Esta es una buena manera con un mínimo de recursos para mantener en el extracto los datos históricos del servidor que ya no están en la base de datos.
Cada solicitud http tiene su propio tipo (action_type). Por ejemplo, _bootstrap es la carga inicial de la vista, el filtro de fecha relativa es el filtro de fecha (control deslizante). La mayoría de los tipos se pueden identificar por el nombre, por lo que está claro lo que hace cada usuario con el panel: alguien mira más la información sobre herramientas, alguien cambia los parámetros, alguien crea sus propias vistas personalizadas y alguien descarga datos.
A continuación se muestra nuestro panel de servicio que nos permite definir paneles lentos, tipos de solicitudes lentas y usuarios que tienen que esperar.
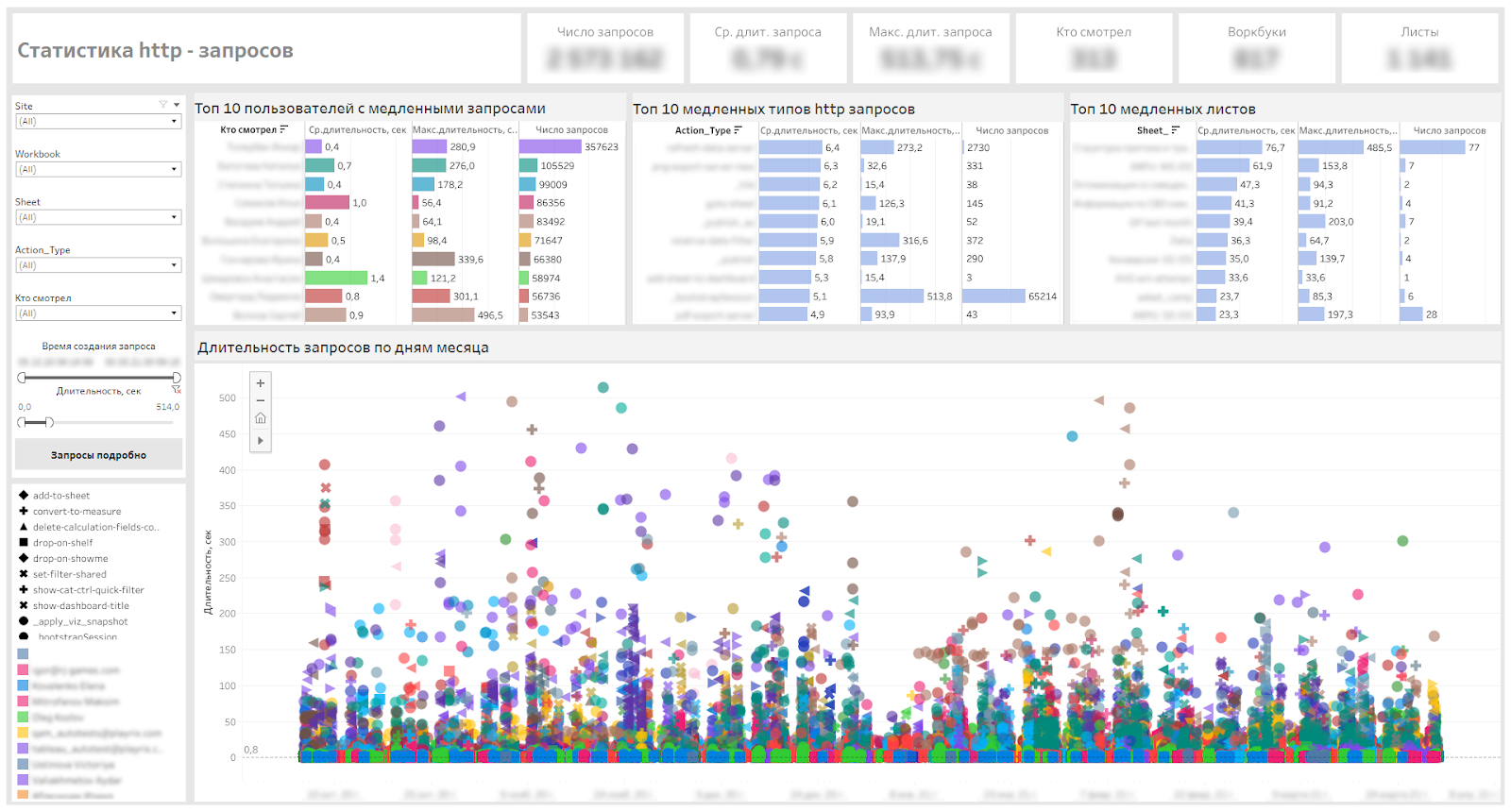
Panel de control para monitorear solicitudes http
Supervisión de sesiones de VizQL
Cuando se abre un tablero en el navegador, se inicia una sesión de VizQL en el servidor de Tableau, dentro de la cual se procesan las visualizaciones y también se asignan recursos para mantener la sesión. Estas sesiones se eliminan después de 30 minutos de inactividad de forma predeterminada.
A medida que aumentó la cantidad de usuarios en el servidor y se introdujo el autoservicio, recibimos varias solicitudes para aumentar los límites de sesión de VizQL. El problema para los usuarios era que abrían paneles, establecían filtros, miraban algo y pasaban a sus otras tareas fuera de Tableau Server, después de un tiempo volvían a abrir paneles, pero se restablecían a la vista predeterminada y tenían que hacerlo. ser reutilizado sintonizar. Nuestra tarea era hacer que la experiencia del usuario fuera más cómoda y asegurarnos de que la carga en el servidor no aumentara de manera crítica.
Los siguientes dos parámetros en el servidor se pueden cambiar, pero debe comprender que la carga en el servidor puede aumentar.
vizqlserver.session.expiry.minimum 5
Número de minutos de tiempo de inactividad después de los cuales una sesión de VizQL es elegible para descartarse si el proceso de VizQL comienza a quedarse sin memoria.
vizqlserver.session.expiry.timeout 30 Número de minutos de tiempo de inactividad después de los cuales se descarta una sesión de VizQL.
Por lo tanto, decidimos monitorear las sesiones de VizQL y rastrear:
- Número de sesiones,
- Número de sesiones por usuario,
- Duración media de las sesiones,
- La duración máxima de las sesiones.
Además, necesitábamos saber en qué días y horas se abre la mayor cantidad de sesiones.
El resultado es un tablero como este:

Tablero para monitorear sesiones VizQL
Desde principios de enero de este año, comenzamos a aumentar gradualmente los límites y monitorear la duración de las sesiones y la carga. La duración media de la sesión aumentó de 13 a 35 minutos; esto se puede ver en los gráficos de la duración media de la sesión. Los ajustes finales son los siguientes:
vizqlserver.session.expiry.minimum 120 vizqlserver.session.expiry.timeout 240
Después de eso, recibimos comentarios positivos de los usuarios, que se volvieron mucho más agradables para trabajar: las sesiones dejaron de desvanecerse.
Los mapas de calor de este panel también nos permiten programar el trabajo de servicio durante las horas de demanda mínima del servidor.
Monitoreamos el cambio en la carga en el clúster (CPU y RAM) en Zabbix y la consola de AWS. No registramos cambios significativos en la carga durante el aumento de los tiempos de espera.
Si hablamos de lo que puede doblar mucho a su servidor de Tableau, entonces puede ser, por ejemplo, un tablero no optimizado. Por ejemplo, cree una tabla en Tableau con decenas de miles de filas por categorías y la identificación de algunos eventos, y en Medir use cálculos de LOD en el nivel de identificación. Con una alta probabilidad, la visualización de la tabla en el servidor no funcionará y obtendrá un bloqueo con un Error inesperado, ya que todos los LOD en granulación mínima consumirán mucha memoria y muy pronto el proceso se ejecutará al 100%. del consumo de memoria.
Este ejemplo se da aquí para dejar en claro que un tablero no óptimo puede consumir todos los recursos del servidor, e incluso 100 sesiones VizQL de los tableros óptimos no consumirán tantos recursos.
Supervisión de fuentes de datos del servidor
Arriba, notamos que para el autoservicio, preparamos y publicamos varias fuentes de datos en el servidor. Todas las fuentes son extractos de datos. Las fuentes publicadas se guardan en el servidor y se ponen a disposición de las personas que trabajan con Tableau Desktop.
Tableau tiene la capacidad de marcar fuentes como certificadas. Esto es lo que hace el equipo de BI al preparar fuentes de datos para el autoservicio. Esto asegura que la fuente en sí haya sido probada.
Las fuentes publicadas pueden tener hasta 200 millones de líneas y 100 campos. Para el autoservicio, este es un volumen muy grande, ya que no muchas empresas tienen fuentes de tales volúmenes para análisis independientes.
Naturalmente, al recopilar los requisitos para generar una fuente, observamos cómo podemos reducir la cantidad de datos en la fuente agrupando categorías, dividiendo las fuentes por proyecto o limitando los períodos de tiempo. Pero aún así, por regla general, las fuentes se obtienen a partir de 10 millones de líneas.
Dado que las fuentes son grandes, ocupan espacio en el servidor, usan los recursos del servidor para actualizar las extracciones, todas ellas deben ser monitoreadas, para ver con qué frecuencia se usan y qué tan rápido crecen en volumen. Para esto, hicimos un monitoreo de fuentes de datos publicadas. Muestra a los usuarios que se conectan a fuentes, libros de trabajo que usan esas fuentes. Esto le permite encontrar fuentes irrelevantes o fuentes problemáticas que el extracto no puede recopilar.
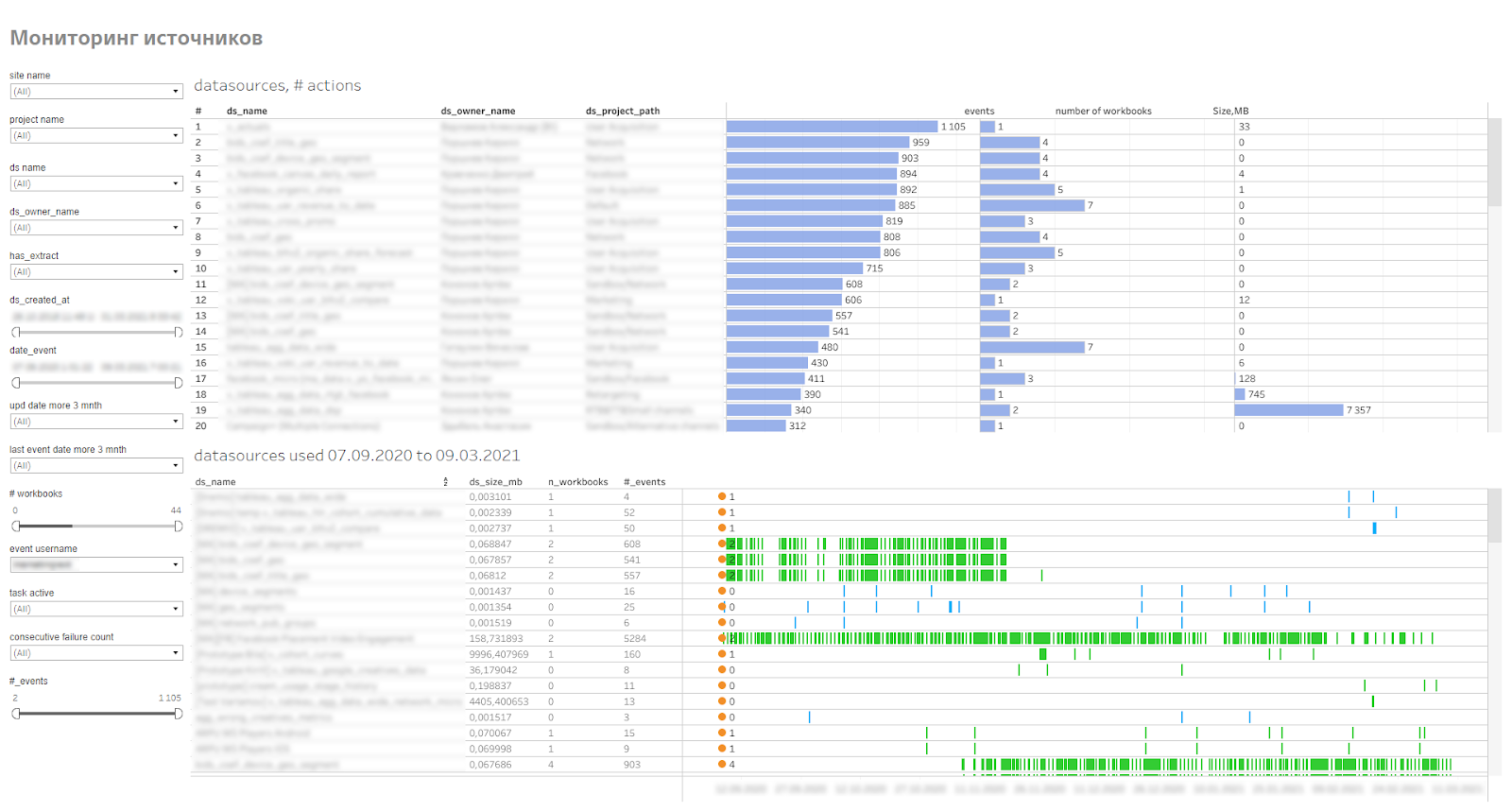
Panel de control de fuente
Salir
Hemos estado utilizando el enfoque de autoservicio durante 1,5 años. Durante este tiempo, 50 usuarios comenzaron a trabajar de forma independiente con datos. Esto redujo la carga en el equipo de BI y permitió que los chicos no esperaran hasta que el equipo de BI llegara a su tarea específica de desarrollar un tablero. Hace unos 5 meses, comenzamos a conectar otras áreas con el autoanálisis.
Estamos planeando realizar una capacitación sobre las mejores prácticas de visualización y alfabetización de datos.
Es importante comprender que el proceso de autoservicio no se puede implementar rápidamente en toda la empresa; llevará algún tiempo. Si el proceso de transición es orgánico, sin impactar a los empleados, luego de un par de años de implementación, puede obtener procesos fundamentalmente diferentes para trabajar con datos en diferentes departamentos y áreas de la empresa.