
Daniel Lemire, profesor de la Universidad por correspondencia de Quebec (TÉLUQ), que inventó una forma de analizar el doble muy rápidamente , junto con el ingeniero John Kaiser de Microsoft publicaron otro hallazgo suyo: el validador UTF-8, superando a la biblioteca CPP UTF-8. (2006) a 48..77 veces, DFA de Björn Hörmann (2009) - 20..45 veces, y Google Fuchsia (2020) - 13..35 veces. La noticia sobre esta publicación ya ha sido publicada en Habré , pero sin detalles técnicos; así que compensamos esta deficiencia.
Requisitos UTF-8
Para empezar, recuerde que Unicode permite puntos de código desde U + 0000 a U + 10FFFF, que están codificados en UTF-8 como secuencias de 1 a 4 bytes:
| El número de bytes en la codificación. | El número de bits en el punto de código. | Valor mínimo | Valor máximo |
|---|---|---|---|
| una | 1..7 | U + 0000 = 0 0000000 | U + 007F = 0 1111111 |
| 2 | 8..11 | U + 0080 = 110 00 010 10 000 000 | U + 07FF = 110 11111 10 111111 |
| 3 | 12..16 | U + 0800 = 1110 0000 10 100000 10 000000 | U + FFFF = 1110 1111 10 111111 10 111111 |
| cuatro | 17..21 | U + 010000 = 11110 000 10 010000 10 000000 10 000000 | U + 10FFFF = 11110 100 10 001 111 10 111 111 10 111 111 |
Según las reglas de codificación, los bits más significativos del primer byte de la secuencia determinan el número total de bytes en la secuencia; El bit cero más significativo solo puede estar en caracteres de un solo byte (ASCII), los dos bits más significativos denotan un carácter multibyte, 1 y cero denotan un byte de continuación> carácter multibyte.
¿Qué tipo de errores podría haber en una cadena codificada de esta manera?
- Secuencia incompleta : se encontró un byte inicial o un carácter ASCII en el lugar donde se esperaba un byte de continuación;
- Secuencia desabotonada : se esperaba un byte inicial o un carácter ASCII en el lugar donde se encontró un byte de continuación;
- Secuencia demasiado larga : el byte inicial
11111xxx
coincide con una secuencia de cinco bytes o más que no está permitida en UTF-8; - Más allá de los límites de Unicode : después de decodificar la secuencia de cuatro bytes, el punto de código es superior a U + 10FFFF.
Si la línea no contiene ninguno de estos cuatro errores, entonces se puede decodificar en una secuencia de puntos de código correctos. Sin embargo, UTF-8 requiere más: que cada secuencia de puntos de código correctos se codifique de forma única. Esto agrega dos tipos más de posibles errores:
- : code point ;
- : code points U+D800 U+DFFF UTF-16, code point U+FFFF. UTF-8 , code points , .
En la codificación CESU-8 raramente utilizada, se cancela el último requisito (y en MUTF-8 también es el penúltimo), por lo que la longitud de la secuencia está limitada a tres bytes, pero el descifrado y la validación de cadenas son complicados. Por ejemplo, el emoticón U + 1F600 GRINNING FACE se representa en UTF-16 como un par de sustitutos
0xD83D 0xDE00
, y CESU-8 / MUTF-8 lo traduce en un par de secuencias de tres bytes
0xED 0xA0 0xBD 0xED 0xB8 0x80
; pero en UTF-8 este emoticón está codificado en una secuencia de cuatro bytes
0xF0 0x9F 0x98 0x80
.
Para cada tipo de error, las siguientes son las secuencias de bits que lo conducen:
| Secuencia inacabada | Falta el segundo byte | 11xxxxxx 0xxxxxxx
|
11xxxxxx 11xxxxxx
|
||
| Falta el tercer byte | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| Falta el cuarto byte | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Secuencia sin apostar | 2do byte adicional | 0xxxxxxx 10xxxxxx
|
| 3er byte adicional | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| 4to byte adicional | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Quinto byte adicional | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Secuencia demasiado larga | 11111xxx
|
|
| Ir más allá de los límites de Unicode | U + 110000..U + 13FFFF | 11110100 1001xxxx
|
11110100 101xxxxx
|
||
| ≥ U + 140 000 | 11110101
|
|
1111011x
|
||
| Consistencia no mínima | 2 bytes | 1100000x
|
| 3 bytes | 11100000 100xxxxx
|
|
| 4 bytes | 11110000 1000xxxx
|
|
| Sustitutos | 11101101 101xxxxx
|
|
Validación de UTF-8
Con el enfoque ingenuo utilizado en la biblioteca CPP UTF-8 del serbio Nemanja Trifunovic, la validación se realiza en una cascada de ramas anidadas:
const octet_difference_type length = utf8::internal::sequence_length(it);
// Get trail octets and calculate the code point
utf_error err = UTF8_OK;
switch (length) {
case 0:
return INVALID_LEAD;
case 1:
err = utf8::internal::get_sequence_1(it, end, cp);
break;
case 2:
err = utf8::internal::get_sequence_2(it, end, cp);
break;
case 3:
err = utf8::internal::get_sequence_3(it, end, cp);
break;
case 4:
err = utf8::internal::get_sequence_4(it, end, cp);
break;
}
if (err == UTF8_OK) {
// Decoding succeeded. Now, security checks...
if (utf8::internal::is_code_point_valid(cp)) {
if (!utf8::internal::is_overlong_sequence(cp, length)){
// Passed! Return here.
Interior
sequence_length()
y
is_overlong_sequence()
también ramificado según la longitud de la secuencia. Si secuencias de diferentes longitudes se intercalan de manera impredecible en la cadena de entrada, entonces el predictor de bifurcaciones no puede evitar vaciar la tubería varias veces en cada carácter procesado.
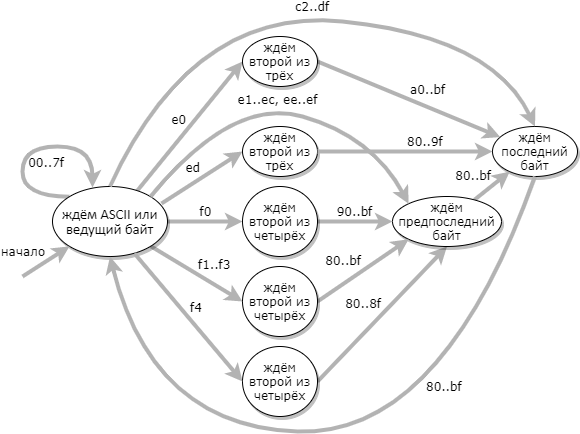
Un enfoque más eficiente para la validación de UTF-8 es usar una máquina de estado de 9 estados: (el estado de error no se muestra en el diagrama)
Cuando se construye la tabla de transición del autómata, el código del validador es muy simple:
uint32_t type = utf8d[byte];
*codep = (*state != UTF8_ACCEPT) ?
(byte & 0x3fu) | (*codep << 6) :
(0xff >> type) & (byte);
*state = utf8d[256 + *state + type];
Aquí, para cada carácter procesado, se repiten las mismas acciones, sin transiciones condicionales; por lo tanto, no se requieren reinicios de tubería; por otro lado, en cada iteración, se realiza un acceso adicional a la memoria (a la tabla de salto
utf8d
) además de leer el carácter de entrada.
Lemir y Kaiser tomaron el mismo DFA como base para su validador y lograron una aceleración diez veces mayor gracias a la aplicación de tres mejoras:
- La tabla de salto se redujo de 364 bytes a 48, de modo que cabe completamente en tres registros vectoriales (128 bits cada uno), y los accesos a la memoria son necesarios solo para leer los caracteres de entrada;
- Los bloques de 16 bytes adyacentes se procesan en paralelo;
- Si un bloque de 16 bytes consta completamente de caracteres ASCII, entonces se sabe que es correcto y no es necesario realizar una verificación más exhaustiva. Este "trozo del camino" acelera el procesamiento de textos "realistas" que contienen oraciones completas en el alfabeto latino de dos a tres veces; pero en textos aleatorios, donde el alfabeto latino, los jeroglíficos y los emoticonos se mezclan uniformemente, esto no se acelera.
Hay sutiles sutilezas en la implementación de cada una de estas mejoras, por lo que vale la pena considerarlas en detalle.
Reducir la tabla de salto
La primera mejora se basa en la observación de que para detectar la mayoría de los errores (12 secuencias de bits no válidas de las 19 enumeradas en la tabla anterior), es suficiente verificar los primeros 12 bits de la secuencia:
| Secuencia inacabada | Falta el segundo byte | 11xxxxxx 0xxxxxxx
|
0x02
|
11xxxxxx 11xxxxxx
|
|||
| Secuencia sin apostar | 2do byte adicional | 0xxxxxxx 10xxxxxx
|
0x01
|
| Secuencia demasiado larga | 11111xxx 1000xxxx
|
0x20
|
|
11111xxx 1001xxxx
|
0x40
|
||
11111xxx 101xxxxx
|
|||
| Ir más allá de los límites de Unicode | U + 1 [1235679ABDEF] xxxx | 111101xx 1001xxxx
|
|
111101xx 101xxxxx
|
|||
| U + 1 [48C] xxxx | 11110101 1000xxxx
|
0x20
|
|
1111011x 1000xxxx
|
|||
| Consistencia no mínima | 2 bytes | 1100000x
|
0x04
|
| 3 bytes | 11100000 100xxxxx
|
0x10
|
|
| 4 bytes | 11110000 1000xxxx
|
0x20
|
|
| Sustitutos | 11101101 101xxxxx
|
0x08
|
|
Para cada uno de estos posibles errores, los investigadores asignaron uno de siete bits, como se muestra en la columna de la derecha. (Los bits asignados son diferentes entre su artículo publicado y su código de GitHub ; aquí están los valores del artículo). Para arreglárselas con siete bits, las dos subcasas Unicode fuera de límites tuvieron que volver a particionarse para que la segunda está concatenado con una secuencia no mínima de 4 bytes; y el caso de secuencia demasiado larga se divide en tres subcampos y se combina con los subcampos fuera de límites de Unicode.
Por lo tanto, se realizaron los siguientes cambios con el Hörmann DKA:
- La entrada no viene por byte, sino por tétrada (nibble);
- El autómata se utiliza como no determinista : el procesamiento de cada tétrada transfiere el autómata entre subconjuntos de todos los estados posibles;
- Ocho estados correctos se combinan en uno, pero uno erróneo se divide en siete;
- Tres tétradas adyacentes se procesan no secuencialmente, sino independientemente entre sí, y el resultado se obtiene como la intersección de tres conjuntos de estados finales.
Gracias a estos cambios, tres tablas de 16 bytes son suficientes para describir todas las posibles transiciones: cada elemento de la tabla se utiliza como un campo de bits que enumera todos los posibles estados finales. Tres de estos elementos se unen con AND y, si hay bits distintos de cero en el resultado, se ha detectado un error.
| Tétrada | Valor | Posibles errores | El código |
|---|---|---|---|
| Alto en el primer byte | 0-7 | 2- | 0x01
|
| 8–11 | () | 0x00
|
|
| 12 | 2- ; 2- | 0x06
|
|
| 13 | 2- | 0x02
|
|
| 14 | 2- ; 2- ; | 0x0E
|
|
| 15 | 2- ; ; Unicode; 4- | 0x62
|
|
| 0 | 2- ; 2- ; | 0x37
|
|
| 1 | 2- ; 2- ; 2- | 0x07
|
|
| 2–3 | 2- ; 2- | 0x03
|
|
| 4 | 2- ; 2- ; Unicode | 0x43
|
|
| 5–7 | 0x63
|
||
| 8–10, 12–15 | 2- ; 2- ; | ||
| 11 | 2- ; 2- ; ; | 0x6B
|
|
| 0–7, 12–15 | Falta el segundo byte; secuencia demasiado larga; Secuencia no mínima de 2 bytes | 0x06
|
|
| 8 | 2do byte adicional; secuencia demasiado larga; ir más allá de los límites de Unicode; consistencia no mínima | 0x35
|
|
| nueve | 0x55
|
||
| 10-11 | 2do byte adicional; secuencia demasiado larga; ir más allá de los límites Unicode; Secuencia no mínima de 2 bytes; sustitutos | 0x4D
|
Quedan 7 secuencias de bits no válidas más sin procesar:
| Secuencia inacabada | Falta el tercer byte | 111xxxxx 10xxxxxx 0xxxxxxx
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| Falta el cuarto byte | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Secuencia sin apostar | 3er byte adicional | 110xxxxx 10xxxxxx 10xxxxxx
|
| 4to byte adicional | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Quinto byte adicional | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
Y aquí el bit más significativo es útil, prudentemente no utilizado en las tablas de transición: corresponderá a una secuencia de bits
10xxxxxx 10xxxxxx
, es decir, dos bytes consecutivos. Ahora, comprobar tres cuadernos puede detectar un error o dar un resultado
0x00
o
0x80
. Y este resultado del primer control, junto con el primer cuaderno, es suficiente para nosotros:
| Falta el tercer byte | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| Falta el cuarto byte | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| 3er byte adicional | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| 4to byte adicional | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Quinto byte adicional | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Combinaciones permitidas |
|
|
|
||
Esto significa que para completar la verificación, basta con asegurarse de que cada resultado
0x80
corresponde a una de las dos combinaciones válidas.
Vectorización
¿Cómo procesar bloques de 16 bytes adyacentes en paralelo? La idea central es utilizar la instrucción
pshufb
como 16 sustituciones simultáneas de acuerdo con una tabla de 16 bytes. Para la segunda verificación, debe encontrar en el bloque todos los bytes del formulario
111xxxxx
y
1111xxxx
; dado que no hay una comparación de vectores sin firmar en Intel, se reemplaza por la resta de saturación (
psubusb
).
Las fuentes de simdjson son difíciles de leer debido al hecho de que todo el código está dividido en funciones de una línea. El pseudocódigo completo del validador se parece a esto:
prev = vector(0)
while !input_exhausted:
input = vector(...)
prev1 = prev<<120 | input>>8
prev2 = prev<<112 | input>>16
prev3 = prev<<104 | input>>24
#
nibble1 = prev1.shr(4).lookup(table1)
nibble2 = prev1.and(15).lookup(table2)
nibble3 = input.shr(4).lookup(table3)
result1 = nibble1 & nibble2 & nibble3
#
test1 = prev2.saturating_sub(0xDF) # 111xxxxx => >0
test2 = prev3.saturating_sub(0xEF) # 1111xxxx => >0
result2 = (test1 | test2).gt(0) & vector(0x80)
# result1 0x80 , result2,
#
if result1 != result2:
return false
prev = input
return true
Si se encuentra una secuencia incorrecta en el borde derecho del último bloque, este código no la detectará. Para no molestar, puede complementar la cadena de entrada con cero bytes para que al final obtenga un bloque completamente cero. En cambio, simdjson eligió implementar una verificación especial para los últimos bytes: para que una cadena sea correcta, el último byte debe ser estrictamente menor
0xC0
, el penúltimo byte estrictamente menor
0xE0
y el tercero desde el final estrictamente menor
0xF0
.
La última de las mejoras que han presentado Lemierre y Kaiser es el corte ASCII. Determinar que solo hay caracteres ASCII en el bloque actual es muy simple:
input & vector(0x80) == vector(0)
... En este caso, es suficiente asegurarse de que no haya secuencias incorrectas en el límite
prev
y
input
, - y puede pasar al siguiente bloque. Esta verificación se realiza de la misma manera que al final de la cadena de entrada; la comparación de vector sin signo con
[..., 0x0, 0xE0, 0xC0]
, que no está disponible en Intel, se reemplaza por el cálculo del vector máximo (
pmaxub
) y su comparación con el mismo vector.
La verificación de ASCII resulta ser la única rama dentro de la iteración del validador, y para predecir con éxito esta rama, es suficiente que la cadena de entrada no entrelace completamente bloques ASCII con bloques que contienen caracteres que no son ASCII. Los investigadores encontraron que se pueden lograr resultados aún mejores en textos reales al verificar la concatenación OR de cuatro bloques adyacentes para ASCII y omitir los cuatro bloques en el caso de ASCII. De hecho, se puede esperar que si el autor del texto, en principio, utiliza caracteres que no son ASCII, aparecerán al menos una vez cada 64 caracteres, lo que es suficiente para predecir la transición.
