En los primeros días, los enrutadores eran computadoras comunes con tarjetas de interfaz de red (NIC) conectadas al bus.

Figura 1 - Tarjetas de interfaz de red conectadas al bus.
Hasta cierto punto, tal sistema funcionó. En esta arquitectura, los paquetes ingresaron a la NIC y fueron transferidos desde la NIC a la memoria por la CPU. La CPU tomó la decisión de reenvío y envió el paquete a la NIC externa. La CPU y la memoria son recursos centralizados con soporte de dispositivo limitado. El bus también era una limitación adicional: el ancho de banda del bus tenía que admitir el ancho de banda de todas las NIC al mismo tiempo.
Si es necesario ampliar la red, los problemas comienzan a surgir muy rápidamente. Puede comprar un procesador más rápido, pero ¿cómo aumenta la potencia del bus? Si duplica la velocidad del bus, debe duplicar la velocidad de la interfaz del bus en cada NIC y CPU. Esto aumenta el costo de todas las placas, incluso si no aumenta la capacidad de una sola NIC.
Lección uno: el costo de un enrutador debería crecer linealmente con sus capacidades
A pesar de la lección aprendida, una solución conveniente para escalar fue agregar otro bus y procesador:

Figura 2 - La solución al problema de escalar el sistema fue agregar un nuevo bus y procesador.
La Unidad Aritmética Lógica (ALU) era un chip de Procesamiento de Señal Digital (DSP) elegido por su excelente relación precio-rendimiento. El bus adicional aumentó el ancho de banda, pero la arquitectura no creció en escala de todos modos. En otras palabras, no se podrían haber agregado más ALU y autobuses para aumentar la productividad.
Dado que las ALU todavía eran una limitación significativa, el siguiente paso fue agregar una matriz de puerta programable en campo (FPGA) a la arquitectura para reducir la carga de búsqueda de coincidencia de prefijo más largo (LPM).

Figura 3: el siguiente paso fue agregar la matriz de puerta programable en campo.
Aunque esto ayudó, no resolvió completamente el problema. ALU todavía estaba abrumada. Los LPM constituían la mayor parte de la carga, pero la arquitectura centralizada aún no escalaba bien, incluso si nos deshicimos de parte del problema.
Lección dos: LPM se puede implementar en silicio y no es una barrera para el rendimiento
A pesar de esta lección, el siguiente paso se dio en una dirección diferente: hacia la sustitución de ALU y FPGA por un procesador estándar. Los diseñadores intentaron escalar agregando más CPU y más buses. Se necesitó mucho esfuerzo para incluso un pequeño aumento de potencia, y el sistema aún sufría las limitaciones de ancho de banda del bus centralizado.
En esta etapa de la evolución de Internet, entraron en juego fuerzas más serias. A medida que la web se hizo popular entre el público en general, el potencial de Internet comenzó a hacerse más evidente. Las empresas de telecomunicaciones adquirieron redes NSFnet regionales y comenzaron a construir complejos comerciales. Los circuitos integrados de aplicaciones específicas (ASIC) se han convertido en tecnologías probadas que permiten implementar más funciones directamente en el silicio. La demanda de enrutadores se ha disparado y la necesidad de mejoras significativas en la escalabilidad finalmente ha derrotado al conservadurismo de la ingeniería. Para satisfacer esta demanda, han surgido muchas empresas emergentes con una amplia gama de posibles soluciones.
El travesaño programado se convirtió en una de las alternativas:

Figura 4 - Barra transversal programada.
En esta arquitectura, cada NIC tenía una entrada y una salida. El procesador NIC tomó la decisión de reenvío, seleccionó la NIC de salida y envió una solicitud de programación al conmutador (barra cruzada). El programador recibió todas las solicitudes de las NIC, elaboró la solución óptima, programó la solución en el conmutador y dirigió las entradas para la transmisión.
El problema con este esquema era que cada salida podía "escuchar" una entrada a la vez, y el tráfico de Internet pulsaba. Si dos paquetes necesitaban llegar a la misma salida, uno de ellos tenía que esperar. La espera de un paquete hizo que otros paquetes esperaran en la misma entrada, después de lo cual el sistema comenzó a sufrir de Bloqueo de cabecera de línea (HOLB), lo que resultó en un rendimiento muy bajo del enrutador.
Lección tres: la estructura interna del enrutador no debe bloquear las señales incluso en condiciones de carga
La migración a chips especializados también motivó a los diseñadores a migrar a estructuras internas basadas en celdas, ya que cambiar celdas pequeñas de tamaño fijo es mucho más fácil que tratar con paquetes de longitud variable, que a veces son grandes. Sin embargo, el uso de las celdas de conmutación también significaba que el programador tendría que ejecutarse a una frecuencia más alta, lo que dificultaba mucho la programación.
Otro enfoque innovador fue convertir el NIC en un toro:

Figura 5 - NIC en forma de toro.
En tal esquema, cada NIC tenía conexiones a cuatro vecinos, y la NIC de entrada tenía que calcular una ruta a través de la estructura para llegar a la tarjeta de línea de salida. Este sistema tenía problemas: el ancho de banda no era el mismo. El ancho de transmisión en la dirección norte-sur fue mayor que en la dirección este-oeste. Si el patrón de tráfico entrante se moviera de este a oeste, se produciría una congestión.
Lección cuatro: la estructura interna del enrutador debe tener una distribución uniforme del ancho de banda, porque no podemos predecir la distribución del tráfico.
Un enfoque completamente diferente fue crear una red de comunicaciones NIC-NIC completa y distribuir celdas en todas las NIC:
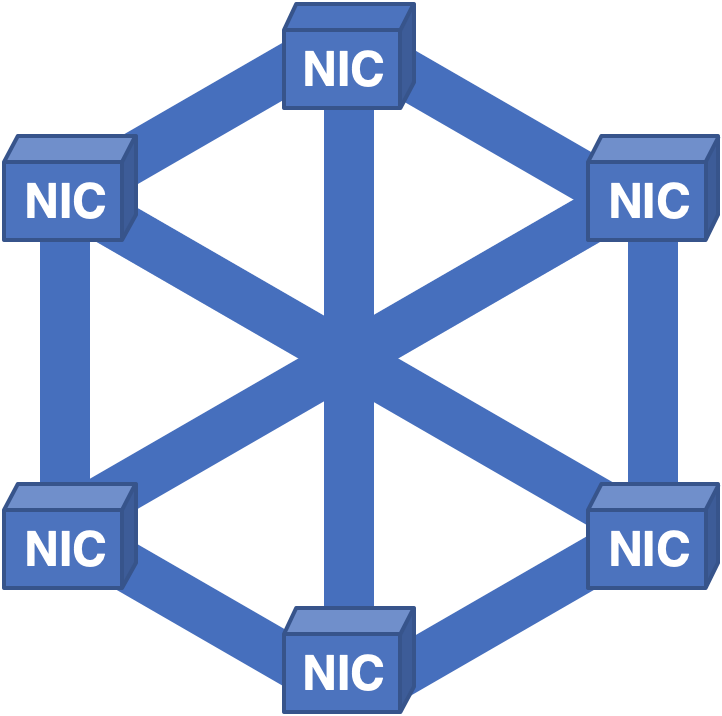
Figura 6 - Estructura completamente conectada con distribución de celdas a todas las NIC.
A pesar de aprender las lecciones anteriores, se identificaron nuevos problemas. En esta arquitectura, todo funcionó bastante bien hasta que fue necesario retirar la placa para repararla. Debido a que cada NIC contenía celdas para todos los paquetes del sistema, cuando se quitó la tarjeta, no se pudo volver a crear ninguno de los paquetes, lo que resultó en un tiempo de inactividad corto pero doloroso.
Lección cinco: los enrutadores no deben tener un solo punto de falla
Incluso tomamos esta arquitectura y la dimos vuelta:
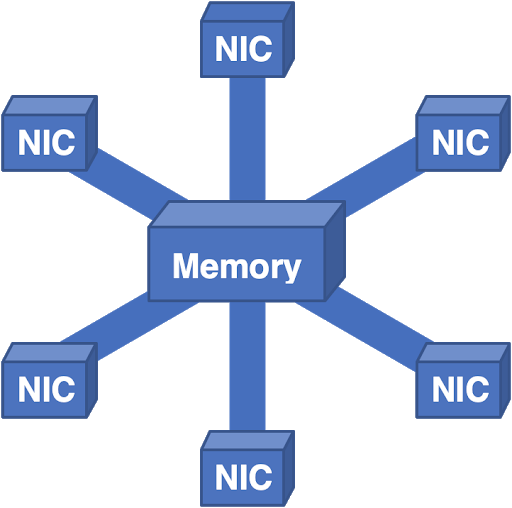
Figura 7 - Aquí todos los paquetes van a la memoria central y luego a la NIC de salida.
Este sistema funcionó bastante bien, pero el escalado de la memoria se convirtió en un problema. Puede agregar algunos controladores y bancos de memoria, pero en algún momento el ancho de banda general se vuelve demasiado complejo para el diseño físico. Ante las limitaciones físicas prácticas, nos vimos obligados a pensar en otras direcciones.
La red telefónica se ha convertido para nosotros en una fuente de inspiración. Hace mucho tiempo, Charles Close se dio cuenta de que se podían fabricar conmutadores escalables mediante la construcción de redes de conmutadores más pequeños. Al final resultó que, todas las maravillosas propiedades que necesitamos están presentes en la red de Clos:

Figura 8 - Red de Clos.
Cerrar propiedades de red:
- El poder crece con la escala.
- No tiene un solo punto de falla.
- Mantiene suficiente redundancia para tolerancia a fallas.
- Hace frente a las sobrecargas distribuyendo la carga por toda la estructura.
Siempre implementamos entradas y salidas juntas, por lo que generalmente doblamos esta imagen a lo largo de la línea de puntos. Esto da como resultado una red Clos plegada, y esto es lo que usamos hoy en día en los enrutadores de varios casos: algunos casos tienen una NIC y una capa de conmutadores, en otros, capas adicionales de conmutadores.

Figura 9 - Red de Clos colapsada.
Desafortunadamente, incluso esta arquitectura tiene sus propios problemas. El formato de las celdas utilizadas entre los conmutadores es propietario y propiedad del fabricante del chip, lo que conduce a la dependencia de los conjuntos de chips. La dependencia de un proveedor de chips no es mucho mejor que la dependencia de un solo proveedor de enrutadores, los problemas son los mismos: vincular los precios y la disponibilidad de los dispositivos a una sola fuente. Las actualizaciones de hardware son un desafío porque el nuevo conmutador de celda debe admitir simultáneamente conexiones y formatos de celda heredados para mantener la interoperabilidad, así como todas las velocidades de enlace y formatos de celda de los nuevos equipos.
Cada celda debe estar direccionada para indicar la NIC de salida a la que debe transmitir información. Dicho direccionamiento es finito, lo que crea un límite de escalabilidad. El control y la gestión en los enrutadores de varios casos sigue siendo propiedad exclusiva, lo que provoca otro problema de proveedor único en la pila de software.
Afortunadamente, podemos resolver estos problemas cambiando nuestra filosofía de arquitectura. Durante los últimos cincuenta años, nos hemos esforzado por escalar los enrutadores. Hemos aprendido de la experiencia de construir grandes nubes que la filosofía de escalamiento horizontal suele tener más éxito.
La arquitectura de escalamiento horizontal utiliza una estrategia de dividir y conquistar en lugar de crear un servidor único enorme y extremadamente rápido. Un bastidor de servidores pequeños puede hacer el mismo trabajo a la vez que es más confiable, flexible y rentable.
Este enfoque también es aplicable a los enrutadores. ¿Es posible tomar varios enrutadores pequeños y alinearlos en una topología de Clos para lograr beneficios arquitectónicos similares y evitar problemas relacionados con la malla? Al final resultó que, esto no es particularmente difícil:

Figura 10 - Reemplazo de conmutadores de celda con conmutadores de paquetes, conservando la topología de Clos para facilitar el escalado.
Al reemplazar los conmutadores de celda con conmutadores de paquetes y mantener la topología de Clos, proporcionamos facilidad de escalabilidad.
El escalado es posible en dos dimensiones: ya sea agregando nuevos enrutadores de entrada y conmutadores de paquetes en paralelo con las capas existentes, o agregando capas de conmutador adicionales. Debido a que los enrutadores individuales están bastante estandarizados hoy en día, evitamos la dependencia de un solo proveedor. Todos los enlaces utilizan Ethernet estándar, por lo que no hay problemas de compatibilidad.
Las actualizaciones son sencillas y directas: si el conmutador necesita más canales, simplemente puede reemplazarlo por un conmutador más grande. Si necesita actualizar un canal separado y ambos extremos del canal tienen esta capacidad, entonces solo necesita actualizar la óptica. Las diferentes velocidades de transmisión de enlaces diferentes dentro de una estructura no son un problema porque cada enrutador actúa como un mapeador de velocidades.
Esta arquitectura ya es popular en el mundo de los centros de datos y, según el número de capas de conmutador, se denomina arquitectura de columna vertebral o superestructura. Ha demostrado ser muy fiable, estable y flexible.
Desde el punto de vista del plano de transmisión, está claro que se trata de una alternativa viable a la arquitectura. Sigue habiendo problemas con el plano de control y el plano de control. La ampliación del plano de control requiere una mejora de un orden de magnitud en la escala de nuestros protocolos de control. Estamos tratando de implementarlo mejorando los mecanismos de abstracción mediante la creación de una representación proxy de la arquitectura que describe la topología completa como un solo nodo.
Asimismo, estamos trabajando para desarrollar abstracciones del plano de control que nos permitan controlar toda la estructura de Clos como un solo enrutador. Este trabajo se realiza como un estándar abierto, por lo que ninguna de las tecnologías involucradas es propietaria.
En el transcurso de cincuenta años, las arquitecturas de enrutadores han evolucionado a pasos agigantados, y se han cometido muchos errores en el proceso de encontrar compensaciones entre diferentes tecnologías. Evidentemente, nuestra evolución aún no está completa. En cada iteración, abordamos los problemas de la generación anterior y descubrimos nuevos desafíos.
Con suerte, al estudiar detenidamente nuestra experiencia pasada y actual, podemos avanzar hacia una arquitectura más flexible y confiable y crear mejoras futuras sin reemplazar completamente el hardware.