Limpieza de datos: problemas y enfoques actuales , 2000.
Muy a menudo, cada analista se enfrenta a una situación en la que cargó datos en la unidad de análisis y, en respuesta, en silencio, aunque todo funciona en modo de prueba. El motivo suele ser que los datos no se limpian lo suficiente, donde en esta situación el analista debería buscar una emboscada y por dónde empezar no suele ser una tarea fácil. Por supuesto, puede usar mecanismos de suavizado, pero todos saben que si se vierte un kilogramo de bolas de una caja negra con bolas rojas y verdes y en lugar de ellas se lanza un kilogramo de bolas blancas, entonces se comprende la distribución de bolas rojas y verdes esto traerá un poco más cerca.
Cuando se encuentra en una situación de "por dónde empezar", la taxonomía de datos sucios ayuda. Aunque los libros de texto dan una lista de problemas, pero por lo general está incompleta, constantemente buscaba estudios que consideraran este tema con más detalle. El trabajo de T.Gschwandtner, J.Gartner, W.Aigner, S. Miksch surgió, aunque lo hicieron para considerar formas de limpiar datos relacionados con fechas y horas, pero, en mi opinión, esto resultó ser un excepción que requería que entendieras las reglas más profundamente que en los libros de texto ... Por mi propia experiencia sé que la conjugación de fechas y horas es "remoción de cerebros" prácticamente en el sentido literal, y por eso me enganché a las investigaciones de estos autores.
En su trabajo, analizaron varios trabajos de otros autores y compilaron una poderosa lista de "contaminación de datos", la lógica de su análisis merece respeto y, por otro lado, permite mirar más "desde afuera" a cualquier limpieza de datos. tarea. Todo esto se puede ver al comparar todo el conjunto de obras para las que hacen un análisis comparativo. Por lo tanto, hice una traducción de los 5 artículos más utilizados por ellos, una lista con enlaces a estas traducciones a continuación.
Este es el segundo artículo de una serie.
1. Taxonomía de formatos de fecha y hora en datos brutos , 2012
2. Limpieza de datos: problemas y enfoques modernos 2000
3. Taxonomía de "datos sucios" 2003
4. Problemas, métodos y desafíos de la depuración compleja de datos 2003
5. 2005 .
6. 2005 .
Sorry, , , .
, , . , . ETL. .
1.
, , . , , , - , . , , , -, . , . , .

[6] [16] . , , « ». , , , . , (« , »). - . ETL (, , ), . 1, / , , . . 1, . , , .
, . , [32] [31]. , . , , , . , . , , , .
. , , . , , , . , , , , . , . , .
, . , , [11] [12] [15] [19] [22] [23]. , , , [30] [29] [1] [21]. , , [11] [19] [25].
, , . . 3 , . 4 , ETL. 5 - .
2.
, . , . [26] , . , , , .
. 2, , , . , , ; ( ), . , , . . . 2 . . 2, ( ) , .

2.1
, , . , , , , . , (, , ..), . , , , - , , , - , - , , . , , , (, ).
1. ( )

, : (), , ; 1 2. , , , , , (. 2).
2.

, - , , , . , . , , .
2.2
, , , . , -, . , , . . , , .
, . w.r.t. - [2] [24] [17]. , () (). , , , , , ..
, ( ). (, , ..). , , (, ) (, ) . , (, ) (, 1 2).
, , , (, ). [11], / [15]. , , . , , , .

. 3 , . ( / , Cid / Cno, / ) ( ). , («0» / «1» «» / «M») ( ). , , Cid/Cno , , ; (11/493) (24). ; . , , , , Gender / Sex.
3.
,
: , , . .
: , «» . ; . . / , , . , ETL (. 1).
, , , , . , . , .
: , , , . , , , .
: ETL , .
: ( ) , . . (. 1).
, , , , , , . . , [ 4]. , , . . , . 3 Customers CID Cno, .
( ), . , , [2] [24] [26]. ; .
3.1
, , , . , , () . . , ( ), [20] [9].
, . . , , , , , , , , (, ) .., . 3 , .
4.
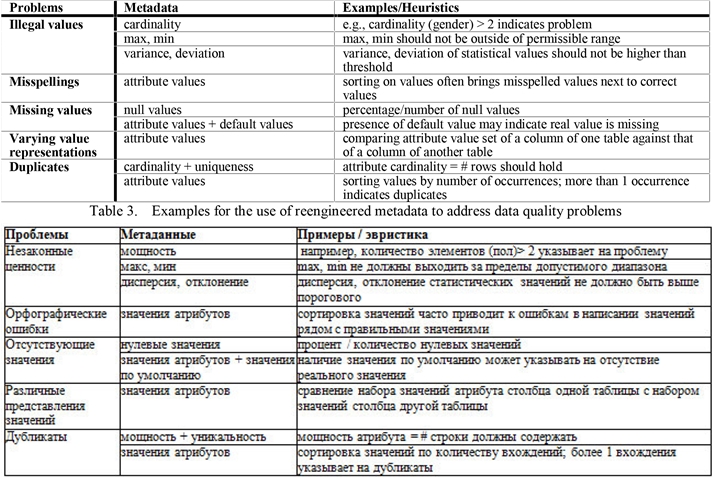
, , . , , , [10]. [28], , «-» , , , . , , . , 99% « = * » , 1% .
3.2
, (), . , , , , , .
ETL (. 4) , . - SQL , (UDF), SQL: 99 [13] [14]. UDF SQL SQL. . , , , . , UDF SQL: 99 ( ) .

. 4 , SQL 99. . 3 , . , . , . UDF ( ). UDF , , .
UDF - . . , , , , (. . 4).
(, ) . , , , SchemaSQL [18]. , Match, « » (. ). . [11] [25].
3.3
, . , . , :
( ): , , . ( 2, . 3, . 4). - .
: , . . , . ( - , - / , - . .) .
: . , ; . . , , , -. , , .
, , , , . . , . , . (.. ) , . , . , . . [22].
, , , . . . . , . « » ( ), , , [14] [11]. , , , , , . , 0 1, . , . (, , name,…) , , , , (soundex), [11] [15] [19]. , , [23]. , - . WHIRL , - [7].
. . , , . , , , . [15] , . . , , , . . .
4.
, , .1 , , , . - , . , ETL, , . ETL - (API) , [8].
, , . ETL .
4.1
3.1, . MIGRATIONARCHITECT (Evoke Software) - . : , , , , , . MIGRATIONARCHITECT . , WIZRULE (WizSoft) DATAMININGSUITE (Information Discovery), , . , WIZRULE : , «-» , , , « Edinburgh 52 « »; 2 () () () ». WIZRULE .
, INTEGRITY (Vality), , . INTEGRITY , , , . , , . INTEGRITY , (, , , ) (, , ). , . , .
1 . -, , Data Warehouse Information Center (www.dwinfocenter.org), Data Management Review (www.dmreview.com), Data Warehousing Institute (www.dwinstitute.com).
4.2
, , . , . , [21].
: . , . , IDCENTRIC (FirstLogic), PUREINTEGRATE (Oracle), QUICKADDRESS (QASSystems), REUNION (PitneyBowes) TRILLIUM (TrilliumSoftware), . , , , . , , . , () TRILLIUM 200 000 -. .
: DATACLEANSER (EDD), MERGE / PURGELIBRARY (Sagent / QMSoftware), MATCHIT (HelpITSystems) MASTERMERGE (PitneyBowes). , . ; , DATACLEANSER MERGE / PURGE LIBRARY, .
4.3 ETL
ETL , , COPYMANAGER (InformationBuilders), DATASTAGE (Informix / Ardent), EXTRACT (ETI), POWERMART (Informatica), DECISIONBASE (CA / Platinum), DATATRANSFORMATIONSERVICE. (Microsoft), METASUITE (Minerva / Carleton), SAGENTSOLUTIONPLATFORM (Sagent) WAREHOUSEADMINISTRATOR (SAS). , , , , , - . . , , , ODBC EDA. . , . , C / C ++, . , , . (, COPYMANAGER, DECISIONBASE, POWERMART, DATASTAGE, WAREHOUSEADMINISTRATOR) . , , , / .
ETL , API. . (, , , , , , . .). , (, ), (, , , , ), , . . , , .
if-then case, , , , . , . , , soundex. , , .
5.
, , . , . , . , , - . , ( API ).
, , . , . , . , , Match, Merge Mapping Composition, (), (), . , , , . , . , , , XML, , , XML-.
Acknowledgments
We would like to thank Phil Bernstein, Helena Galhardas and Sunita Sarawagi for helpful comments.
References
[1] Abiteboul, S.; Clue, S.; Milo, T.; Mogilevsky, P.; Simeon, J.: Tools for Data Translation and Integration. In [26]:3-8, 1999.
[2] Batini, C.; Lenzerini, M.; Navathe, S.B.: A Comparative Analysis of Methodologies for Database Schema Integration. In Computing Surveys 18(4):323-364, 1986.
[3] Bernstein, P.A.; Bergstraesser, T.: Metadata Support for Data Transformation Using Microsoft Repository. In [26]:9-14, 1999
[4] Bernstein, P.A.; Dayal, U.: An Overview of Repository Technology. Proc. 20th VLDB, 1994.
[5] Bouzeghoub, M.; Fabret, F.; Galhardas, H.; Pereira, J; Simon, E.; Matulovic, M.: Data Warehouse Refreshment. In [16]:47-67.
[6] Chaudhuri, S., Dayal, U.: An Overview of Data Warehousing and OLAP Technology. ACM SIGMOD Record 26(1), 1997.
[7] Cohen, W.: Integration of Heterogeneous Databases without Common Domains Using Queries Based Textual Similarity. Proc. ACM SIGMOD Conf. on Data Management, 1998.
[8] Do, H.H.; Rahm, E.: On Metadata Interoperability in Data Warehouses. Techn. Report, Dept. of Computer Science, Univ. of Leipzig. http://dol.uni-leipzig.de/pub/2000-13.
[9] Doan, A.H.; Domingos, P.; Levy, A.Y.: Learning Source Description for Data Integration. Proc. 3rd Intl. Workshop The Web and Databases (WebDB), 2000.
[10] Fayyad, U.: Mining Database: Towards Algorithms for Knowledge Discovery. IEEE Techn. Bulletin Data Engineering 21(1), 1998.
[11] Galhardas, H.; Florescu, D.; Shasha, D.; Simon, E.: Declaratively cleaning your data using AJAX. In Journees Bases de Donnees, Oct. 2000. http://caravel.inria.fr/~galharda/BDA.ps.
[12] Galhardas, H.; Florescu, D.; Shasha, D.; Simon, E.: AJAX: An Extensible Data Cleaning Tool. Proc. ACM SIGMOD Conf., p. 590, 2000.
[13] Haas, L.M.; Miller, R.J.; Niswonger, B.; Tork Roth, M.; Schwarz, P.M.; Wimmers, E.L.: Transforming Heterogeneous
Data with Database Middleware: Beyond Integration. In [26]:31-36, 1999.
[14] Hellerstein, J.M.; Stonebraker, M.; Caccia, R.: Independent, Open Enterprise Data Integration. In [26]:43-49, 1999.
[15] Hernandez, M.A.; Stolfo, S.J.: Real-World Data is Dirty: Data Cleansing and the Merge/Purge Problem. Data Mining and Knowledge Discovery 2(1):9-37, 1998.
[16] Jarke, M., Lenzerini, M., Vassiliou, Y., Vassiliadis, P.: Fundamentals of Data Warehouses. Springer, 2000.
[17] Kashyap, V.; Sheth, A.P.: Semantic and Schematic Similarities between Database Objects: A Context-Based Approach. VLDB Journal 5(4):276-304, 1996.
[18] Lakshmanan, L.; Sadri, F.; Subramanian, I.N.: SchemaSQL – A Language for Interoperability in Relational Multi-Database Systems. Proc. 26th VLDB, 1996.
[19] Lee, M.L.; Lu, H.; Ling, T.W.; Ko, Y.T.: Cleansing Data for Mining and Warehousing. Proc. 10th Intl. Conf. Database and Expert Systems Applications (DEXA), 1999.
[20] Li, W.S.; Clifton, S.: SEMINT: A Tool for Identifying Attribute Correspondences in Heterogeneous Databases Using Neural Networks. In Data and Knowledge Engineering 33(1):49-84, 2000.
[21] Milo, T.; Zohar, S.: Using Schema Matching to Simplify Heterogeneous Data Translation. Proc. 24th VLDB, 1998.
[22] Monge, A. E. Matching Algorithm within a Duplicate Detection System. IEEE Techn. Bulletin Data Engineering
23 (4), 2000 (this issue).
[23] Monge, A. E.; Elkan, P.C.: The Field Matching Problem: Algorithms and Applications. Proc. 2nd Intl. Conf. Knowledge Discovery and Data Mining (KDD), 1996.
[24] Parent, C.; Spaccapietra, S.: Issues and Approaches of Database Integration. Comm. ACM 41(5):166-178, 1998.
[25] Raman, V.; Hellerstein, J.M.: Potter's Wheel: An Interactive Framework for Data Cleaning. Working Paper, 1999. http://www.cs.berkeley.edu/~rshankar/papers/pwheel.pdf.
[26] Rundensteiner, E. (ed.): Special Issue on Data Transformation. IEEE Techn. Bull. Data Engineering 22(1), 1999.
[27] Quass, D.: A Framework for Research in Data Cleaning. Unpublished Manuscript. Brigham Young Univ., 1999
[28] Sapia, C.; Höfling, G.; Müller, M.; Hausdorf, C.; Stoyan, H.; Grimmer, U.: On Supporting the Data Warehouse
Design by Data Mining Techniques. Proc. GI-Workshop Data Mining and Data Warehousing, 1999.
[29] Savasere, A.; Omiecinski, E.; Navathe, S.: Un algoritmo eficiente para las reglas de asociación minera en grandes bases de datos . Proc. 21º VLDB, 1995.
[30] Srikant, R.; Agrawal, R .: Reglas de Asociación Generalizada de Minería . Proc. 21ª conf. VLDB, 1995.
[31] Tork Roth, M.; Schwarz, PM: ¡ No lo deseche, envuélvalo! Una arquitectura de envoltura para fuentes de datos heredadas . Proc. 23º VLDB, 1997.
[32] Wiederhold, G.: Mediadores en la arquitectura de los sistemas de información del futuro . Computadora 25 (3): 38-49,1992.