
En ForePaaS hemos estado experimentando con DevOps durante algún tiempo, primero como equipo y ahora en toda la empresa. La razón es simple: la organización está creciendo. Anteriormente, solo teníamos un equipo para todas las ocasiones. Estuvo involucrada en la arquitectura, el diseño y la seguridad de productos y respondió rápidamente a cualquier problema. Ahora estamos divididos en varios equipos por especialización: front-end, back-end, desarrollo, operación ...
Nos dimos cuenta de que nuestros métodos anteriores no serían tan efectivos y necesitamos cambiar algo, manteniendo la velocidad sin sacrificar la calidad y el vicio. al revés.
Anteriormente, solíamos llamar al equipo devops, que, de hecho, hacía Ops y también era responsable del desarrollo en el backend. Una vez a la semana, otros desarrolladores le dijeron al equipo de DevOps qué nuevos servicios debían implementarse en producción. Esto a veces generaba problemas. Por un lado, el equipo de DevOps no entendía realmente lo que estaba sucediendo con los desarrolladores, por otro lado, los desarrolladores no se sentían responsables de sus servicios.
Recientemente, los chicos de DevOps han estado tratando de despertar esta responsabilidad en los desarrolladores: la disponibilidad, confiabilidad y calidad del código de servicio. Para empezar, necesitábamos tranquilizar a los desarrolladores, que estaban alarmados por la carga que les había caído encima. Necesitaban más información para diagnosticar problemas emergentes, por lo que decidimos implementar la supervisión del sistema.
En este artículo, hablaremos sobre qué es el monitoreo y con qué se come, aprenderemos sobre las llamadas cuatro señales de oro y discutiremos cómo usar métricas y profundizar para explorar problemas actuales.
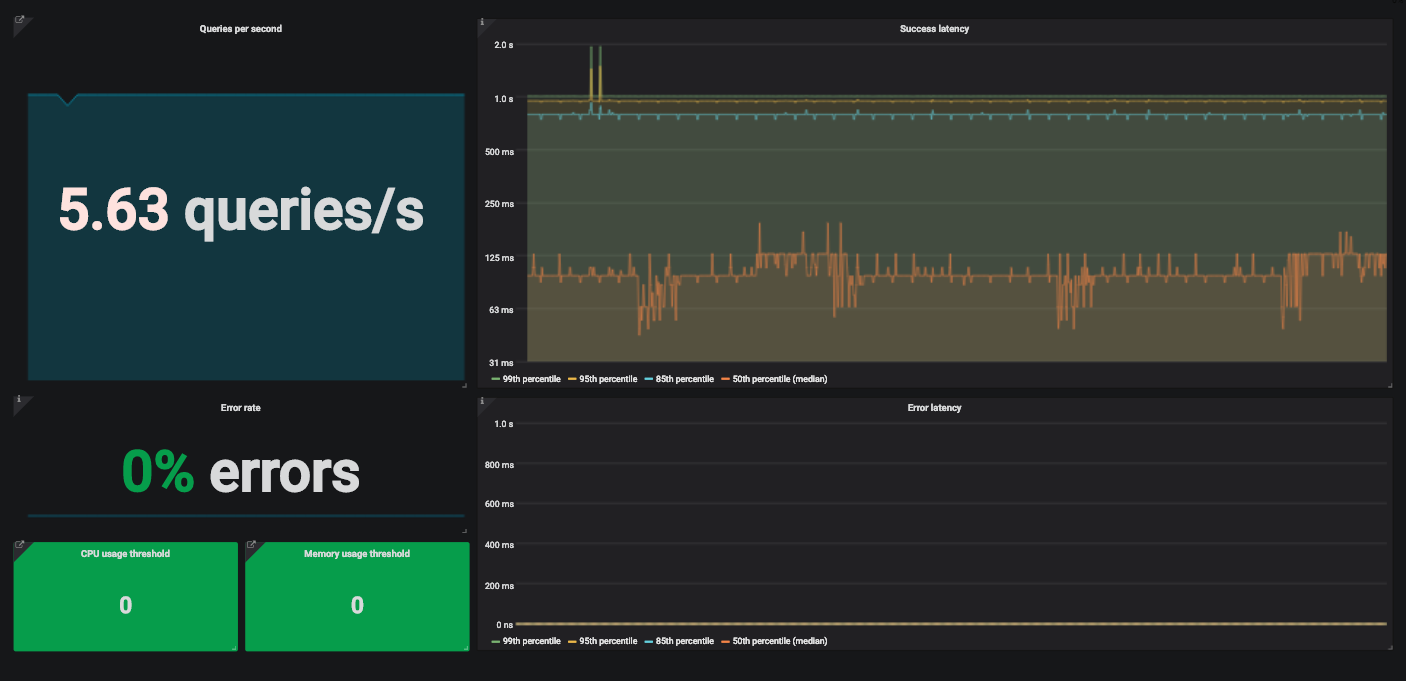
Un ejemplo de un tablero de Grafana con cuatro señales doradas para monitorear un servicio.
¿Qué es el seguimiento?
El monitoreo es la creación, recopilación, agregación y uso de métricas que brindan información sobre el estado de un sistema.
Para monitorear un sistema, necesitamos información sobre sus componentes de software y hardware. Dicha información se puede obtener a través de métricas recopiladas utilizando un programa especial o instrumentación de código.
La instrumentación está cambiando su código para que pueda medir su rendimiento. Estamos agregando código que no afecta la funcionalidad del producto en sí, sino que simplemente calcula y proporciona métricas. Digamos que queremos medir la latencia de una solicitud. Agregue un código que calculará cuánto tiempo tarda el servicio en procesar la solicitud recibida.
La métrica creada de esta manera aún debe recopilarse y combinarse con otras. Esto generalmente se hace con Metricbeat para recopilación y Logstash para indexar métricas en Elasticsearch . Entonces, estas métricas se pueden utilizar para sus propios fines. Por lo general, esta pila se complementa con Kibana , que muestra los datos indexados en Elasticsearch.
¿Por qué monitorear?
Necesita monitorear el sistema por varias razones. Por ejemplo, monitoreamos el estado actual del sistema y sus variaciones para generar alertas y completar cuadros de mando. Cuando recibimos una alerta, buscamos las razones de la falla en el tablero. A veces, la supervisión se utiliza para comparar dos versiones de un servicio o analizar tendencias a largo plazo.
¿Qué monitorear?
Site Reliability Engineering tiene un capítulo útil sobre el monitoreo de sistemas distribuidos que describe el enfoque de Google para rastrear las Cuatro Señales Doradas.

Beyer, B., Jones C., Murphy, N. y Petoff, J. (2016) Ingeniería de confiabilidad del sitio. Cómo gestiona Google los sistemas de producción. O'Reilly. Versión en línea gratuita: https://landing.google.com/sre/sre-book/toc/index.html
- — . . — , .
- — . API . , .
- . (, 500- ) . — , .
- , , . ? . . , , .
?
Tome la pila de tecnología, por ejemplo. Por lo general, elegimos herramientas estándar populares en lugar de soluciones personalizadas. Excepto cuando la funcionalidad disponible no sea suficiente para nosotros. Implementamos la mayoría de los servicios en entornos de Kubernetes e instrumentamos el código para obtener métricas sobre cada servicio personalizado. Para recopilar estas métricas y prepararlas para Prometheus, utilizamos una de las bibliotecas cliente de Prometheus . Existen bibliotecas cliente para casi todos los lenguajes populares. En la documentación, puede encontrar todo lo que necesita para escribir su propia biblioteca.
Si se trata de un servicio de código abierto de terceros, generalmente tomamos los exportadores sugeridos por la comunidad. Los exportadores son el código que recopila métricas del servicio y las formatea para Prometheus. Por lo general, se utilizan con servicios que no generan métricas de Prometheus.
Enviamos métricas por la tubería y las almacenamos en Prometheus como series de tiempo. Además, utilizamos kube-state-metrics en Kubernetes para recopilar y enviar métricas a Prometheus. Luego, podemos crear paneles y alertas en Grafana utilizando solicitudes de Prometheus. No entraremos en detalles técnicos aquí, experimente con estas herramientas usted mismo. Tienen documentación detallada, puedes resolverlo fácilmente.
Por ejemplo, veamos una API simple que recibe tráfico y procesa las solicitudes recibidas utilizando otros servicios.
Demora
La latencia es el tiempo que se tarda en procesar una solicitud. Medimos la latencia por separado para solicitudes exitosas y errores. No queremos que estas estadísticas se confundan.
Por lo general, se tiene en cuenta la latencia general, pero no siempre es una buena opción. Es mejor realizar un seguimiento de la distribución de la latencia porque está más en línea con los requisitos de disponibilidad. La proporción de solicitudes que se procesan más rápido que un umbral determinado es un indicador de nivel de servicio (SLI) común. A continuación, se muestra un ejemplo de un objetivo de nivel de servicio (SLO) para este SLI:
"En 24 horas, el 99% de las solicitudes deben procesarse en menos de 1 segundo".
La forma más visual de representar las métricas de latencia es con un gráfico de series de tiempo. Colocamos métricas en contenedores y los exportadores las recopilan cada minuto. De esta forma, se pueden calcular n-cuantiles para las latencias de servicio.
Si 0 <n <1, y el gráfico contiene q valores, el n-cuantil de este gráfico es igual a un valor que no excede n * q de q valores. Es decir, la mediana, cuantil 0,5 de una gráfica con x registros es igual a un valor que no excede la mitad de x registros.
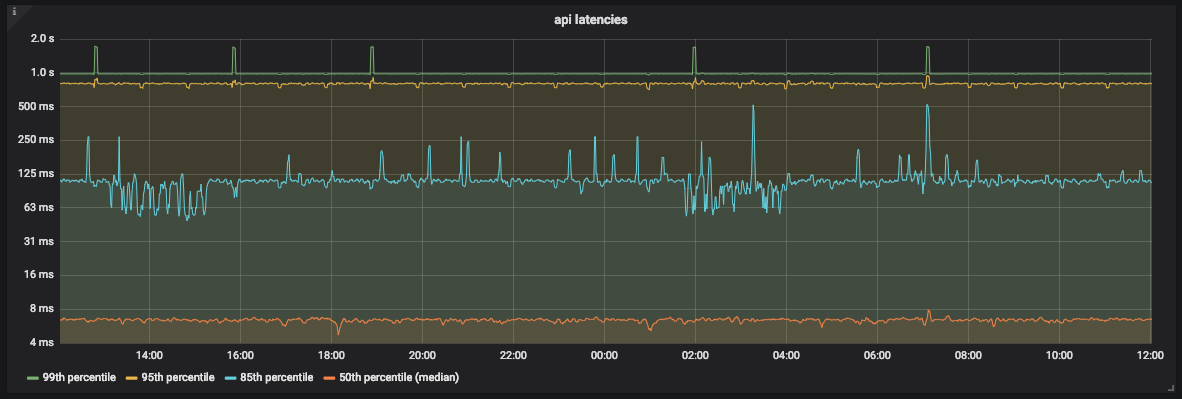
Gráfico de latencia de la API
Como puede ver en el gráfico, la mayoría de las veces la API procesa el 99% de las solicitudes en menos de 1 segundo. Sin embargo, también hay picos de alrededor de 2 segundos que no se corresponden con nuestro SLO.
Dado que usamos Prometheus, debemos tener mucho cuidado al elegir el tamaño del cubo. Prometheus permite tamaños de cucharón lineales y exponenciales. No importa cuál elijamos, siempre que se tengan en cuenta los errores de estimación .
Prometheus no proporciona un valor exacto para el cuantil. Determina en qué cubo se encuentra el cuantil y luego utiliza la interpolación lineal y calcula un valor aproximado.
Tráfico
Para medir el tráfico de una API, debe contar cuántas solicitudes recibe cada segundo. Dado que recopilamos métricas una vez por minuto, no obtendremos el valor exacto durante un segundo específico. Pero podemos calcular el número promedio de solicitudes por segundo usando las funciones de tasa y furia en Prometheus.
Para mostrar esta información, utilizamos el panel Grafana SingleStat. Muestra el promedio actual de solicitudes por segundo y tendencias.

Un ejemplo de un panel Grafana SingleStat con la cantidad de solicitudes que recibe nuestra API por segundo
Si la cantidad de solicitudes por segundo cambia repentinamente, lo veremos. Si el tráfico se reduce a la mitad en unos minutos, entenderemos que hay un problema.
Errores
Es fácil calcular el porcentaje de errores obvios: divida las respuestas HTTP 500 por el número total de solicitudes. Al igual que con el tráfico, usamos un promedio aquí.
El intervalo debe ser el mismo que para el tráfico. Esto facilitará el seguimiento del tráfico con errores en un panel.
Digamos que la tasa de error es del 10% en los últimos cinco minutos y la API está procesando 200 solicitudes por segundo. Es fácil calcular que, en promedio, hubo 20 errores por segundo.
Saturación
Para monitorear la saturación, necesita definir límites de servicio. Para nuestra API, comenzamos midiendo los recursos tanto del procesador como de la memoria, porque no sabíamos cuál afecta más. Kubernetes y kube-state-metrics proporcionan estas métricas para contenedores.
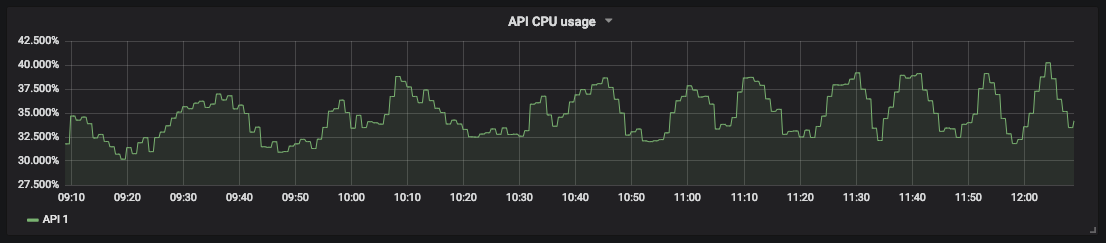
Un gráfico de la utilización de la CPU para nuestra
medición de saturación de API le permite predecir el tiempo de inactividad y programar los recursos. Por ejemplo, para el almacenamiento de bases de datos, puede medir el espacio libre en disco y la rapidez con que se llena para saber cuándo actuar.
Paneles de control detallados para monitorear servicios distribuidos
Echemos un vistazo a otro servicio. Por ejemplo, una API distribuida que actúa como proxy para otros servicios. Esta API tiene varias instancias en diferentes regiones y varios puntos finales. Cada uno de ellos depende de su propio conjunto de servicios. Pronto se vuelve bastante difícil leer gráficos con docenas de filas. Necesitamos la capacidad de monitorear todo el sistema y, si es necesario, detectar fallas individuales.
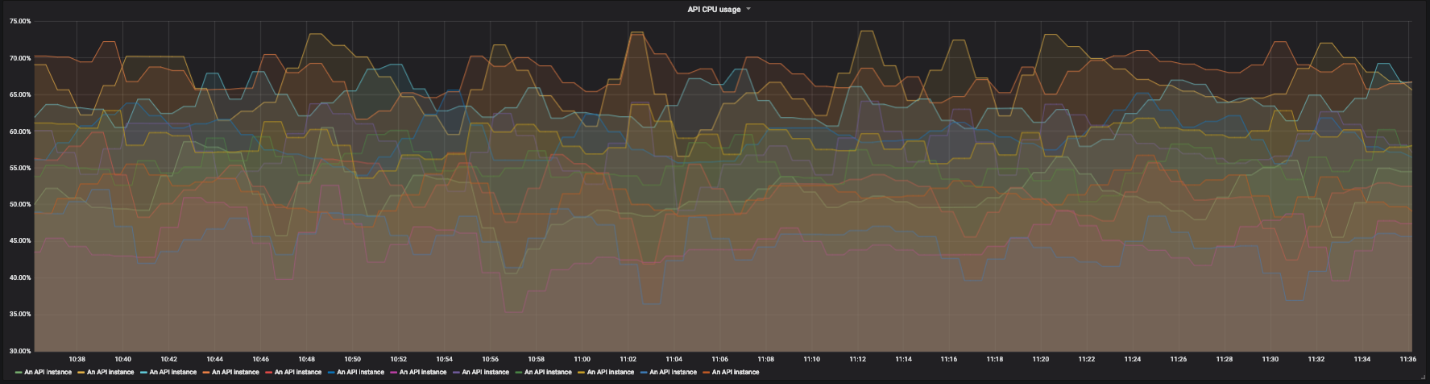
Gráfico de utilización de CPU para 12 instancias de nuestra API
Para ello utilizamos paneles de control detallados. En cada pantalla de un panel, vemos una vista global del sistema y podemos hacer clic en elementos individuales para examinar los detalles. Para la saturación, no utilizamos gráficos, sino simplemente rectángulos de colores que muestran el uso de los recursos del procesador y la memoria. Si el uso de recursos supera el umbral especificado, el rectángulo se vuelve naranja.

Indicadores de uso de CPU y memoria para
instancias de API Haga clic en el rectángulo, vaya a los detalles y vea varios rectángulos de colores que representan diferentes instancias de API.

Indicadores de uso de CPU para instancias de API
Si solo una instancia tiene un problema, podemos hacer clic en el rectángulo y obtener más detalles. Aquí vemos la región de la instancia, las solicitudes recibidas, etc.

Una vista granular del estado de una instancia de API. De izquierda a derecha, de arriba a abajo: región del proveedor, nombre de host de la instancia, fecha del último reinicio, solicitudes por segundo, utilización de CPU, utilización de memoria, solicitudes totales por ruta y porcentaje total de errores por ruta.
Hacemos lo mismo con el porcentaje de errores: hacemos clic y miramos el porcentaje de errores para cada punto final de la API para comprender dónde está el problema, en la propia API o en los servicios con los que está asociado.
Hicimos lo mismo para los retrasos y errores de solicitudes exitosas, aunque aquí hay matices. El objetivo principal es asegurarse de que el servicio sea correcto a escala global. El problema es que la API tiene muchos puntos finales diferentes, cada uno de los cuales depende de varios servicios. Cada punto final tiene sus propios retrasos y tráfico.
Es complicado configurar SLO (y SLA) separados para cada punto final de servicio. Algunos puntos finales tendrán una latencia nominal más alta que otros. En este caso, puede ser necesario realizar una refactorización. Si se requieren SLO separados, debe dividir todo el servicio en servicios más pequeños. Quizás veamos que la cobertura de nuestro servicio fue demasiado amplia.
Decidimos que sería mejor controlar la latencia general. La granularidad simplemente permite investigar el problema cuando las desviaciones de latencia son tan grandes que llaman la atención.
Conclusión
Hemos estado usando estos métodos para monitorear sistemas desde hace algún tiempo y hemos notado que la cantidad de tiempo que se necesita para encontrar problemas y el tiempo medio de recuperación (MTTR) han disminuido. Detallar nos permite encontrar la causa real de un problema global, y para nosotros esta capacidad ha cambiado mucho.
Otros equipos de desarrollo también han comenzado a utilizar estos métodos y solo ven ventajas en ellos. Ahora no solo son responsables del funcionamiento de sus servicios. Van aún más lejos y pueden determinar cómo los cambios en el código afectan el comportamiento de los servicios.
Las cuatro señales doradas no resuelven todos los problemas en absoluto, pero son muy útiles con los más comunes. Casi sin esfuerzo, pudimos mejorar significativamente el monitoreo y reducir el MTTR. Agregue tantas métricas como necesite, siempre que haya cuatro señales de oro entre ellas.