La infraestructura tecnológica de M. Video-Eldorado Group hoy es mucho más que una gigantesca cadena de cajas registradoras en más de 1000 tiendas en todo el país. Bajo el capó, tenemos una plataforma en línea que brinda interacción con el cliente, aprendizaje automático, algoritmos de búsqueda inteligente, bots de chat, un sistema de recomendación, automatización de procesos comerciales clave y flujo de documentos electrónicos. Debajo del corte, hay una historia detallada sobre lo que nos empujó a romper el monolito en microservicios.
Leyendas de la antigüedad profunda
Para que todo esto funcione como un reloj, debemos seguir el desarrollo de las tecnologías y responder con prontitud a las solicitudes comerciales. Desafortunadamente, la funcionalidad básica de los sistemas ERP globales está lejos de ser siempre capaz de responder rápidamente a las necesidades emergentes de los clientes internos. En 2016, este se convirtió en uno de los argumentos a favor de nuestra transición a una arquitectura de microservicios.
La empresa se enfrentó a una tarea bastante difícil, implementar una lógica comercial unificada de trabajar con varias mecánicas promocionales en el proceso de realizar pedidos por parte de los clientes en todos los canales de venta y puntos de contacto (en ese momento: sitio web, aplicación móvil, cajas y terminales en tiendas y operadores en call center).
Al mismo tiempo, dentro del panorama de TI, teníamos grandes sistemas monolíticos como la plataforma de comercio electrónico Oracle ATG, SAP CRM y otros. La repetición de la lógica en cada uno de ellos o la implementación en uno y la reutilización en otro de la funcionalidad necesaria, según nuestros cálculos, resultó en años de tiempo y decenas de millones de inversiones.
Por lo tanto, reunimos un pequeño equipo de desarrolladores y personas técnicamente competentes que estaban a nuestra disposición en ese momento, y pensamos en cómo podríamos hacer un servicio separado para nuestras necesidades. En el proceso de elaboración, nos dimos cuenta de que en realidad no necesitamos una, sino tres o cuatro herramientas de trabajo. Así es como llegamos al concepto de arquitectura de microservicios por primera vez.
Decidimos codificar en Java, ya que teníamos la experiencia necesaria en esto. Elegimos la versión 3.2 de Spring. Como resultado, obtuvimos una especie de micromonolito distribuido en tres o cuatro servicios, estrechamente interconectados entre sí. A pesar de que se desarrollaron de forma independiente, solo todos podían trabajar juntos.
Sin embargo, supuso un gran paso adelante en cuanto al desarrollo de su propia tecnología. Cambiamos de Java 6 a Java 8, comenzamos a dominar Spring 3, pasando sin problemas a Spring 4. Por supuesto, fue una prueba segura.
Hemos reducido con éxito el marco de tiempo de implementación del proyecto de oscuros "meses para el desarrollo", habiendo implementado la lógica empresarial requerida entre canales en casi dos meses.
Evolución tecnológica
En 2017-18, iniciamos una refactorización global del micromonolito. El concepto de desarrollo de microservicios fue del agrado tanto de los especialistas en TI como de las empresas. El flujo de tareas laborales comenzó a crecer. Además, continuamos aislando los bloques funcionales que necesitan los diferentes consumidores del panorama de TI corporativo y trasladándolos a los rieles de los microservicios.
Intentamos mantenernos al día y saltar a Java 9, pero no fue coronado por el éxito. Desafortunadamente, no obtuvimos ningún beneficio tangible de este ejercicio, por lo que nos quedamos en Java 8. Cada vez
había más servicios, tenían que ser administrados centralmente y trabajar con ellos estandarizados. Aquí es donde probamos la contenedorización por primera vez. Los contenedores de Docker eran entonces grandes y pesados, de varios cientos de megabytes cada uno.
Más tarde, tuvimos que resolver problemas con el equilibrio del tráfico y la carga de los servicios. Elegimos Consul para los clientes externos y Eureka para los internos como soluciones. Probamos diferentes herramientas de comunicación interservicios gRPC, RMI. Vivimos así durante casi un año, y nos pareció que aprendimos cómo crear microservicios con éxito y construir una arquitectura de microservicios.
Abróchense los cinturones de seguridad, ¡nos estamos ahogando!
En 2019, la cantidad de nuestros microservicios ha aumentado significativamente, superando la marca de más de 100. Aplicamos nuevas soluciones para la comunicación entre servicios, cuando fue posible, intentamos implementar enfoques basados en eventos.
Mientras tanto, los problemas de orquestación y gestión de la dependencia se estaban volviendo cada vez más agudos. Pero el mayor cambio que nos tocó ya a principios de 2019 estuvo relacionado con el cambio en la política de la empresa con respecto al uso de Java.
Tuvimos la opción de qué hacer a continuación: quedarnos con Oracle y pagarles mucho dinero, invertir en nuestra propia construcción de open jdk o tratar de encontrar algunas alternativas reales.
Elegimos la tercera opción y junto con BellSoft, que es uno de los cinco líderes mundiales involucrados en el desarrollo del proyecto OpenJDK, luego de una serie de reuniones y discusiones, formamos un plan para la transición y pilotaje de la nueva versión de Java. , y combinó esto con la transición directamente a Java 11. El proceso fue difícil, pero en todas las pruebas, no sentimos problemas serios e irresolubles.
El siguiente paso para nosotros fue la implementación de la gestión de contenedores para Kubernetes. Gracias a esto, durante algún tiempo nos pareció que todo estaba bien y que habíamos logrado un gran éxito. Pero luego aparecieron los siguientes problemas con la infraestructura. Simplemente no podía hacer frente al constante aumento de carga.
Simplemente no tuvimos tiempo de escalar. La necesidad de las próximas transformaciones técnicas cardinales se hizo evidente. Entonces comenzamos a mirar hacia las tecnologías en la nube y a esforzarnos por probarlas en nosotros mismos.
Levántate por encima de las nubes
El comienzo de 2020 nos prometió un gran paso en el desarrollo de nuestras tecnologías internas, comprensión y mejora de nuestra arquitectura de microservicios. Delante había un gran paso hacia las nubes. Por desgracia, los planes tuvieron que corregirse, como dicen, en el transcurso de la obra.
Debido a la pandemia de COVID-19, en lugar de migrar gradualmente y explorar las posibilidades de los servicios en la nube, hicimos que toda la empresa buscara nuevas herramientas para satisfacer las necesidades cambiantes de nuestros clientes debido a la pandemia. De hecho, escribimos los siguientes microservicios, introduciendo simultáneamente nuevas tecnologías y aún moviéndonos a la infraestructura de la nube.
Para nosotros, el tamaño de los contenedores se ha vuelto crítico por dos razones simples: es dinero por la potencia de computación en la nube consumida y el tiempo que el desarrollador, y por lo tanto toda la empresa, dedica a levantar contenedores, sincronizarlos y configurarlos, ejecutar autotests, etcétera. Y aquí sentimos plenamente la ventaja y la utilidad de nuestros contenedores compactos con el tiempo de ejecución Liberica JDK.
A pesar del apogeo de la pandemia, en pocos meses hemos implementado y lanzado exitosamente a la operación productiva dos docenas de microservicios, totalmente basados en la infraestructura de la nube.
A finales de 2020, nos centramos en los procesos: invertimos mucho tiempo y esfuerzo en la construcción de un enfoque de producto, en el desarrollo de microservicios, en la selección y formación de equipos separados con sus propias métricas y KPI en varias áreas de unidades de negocio. .
Aserrando el monolito en microservicios usando el ejemplo del servicio de cálculo de pedidos
Para no poner a prueba su paciencia, me gustaría demostrar ejemplos específicos y la lógica de trabajar con una infraestructura de microservicios. Tomemos un cálculo de pedido típico en un entorno de TI estándar.
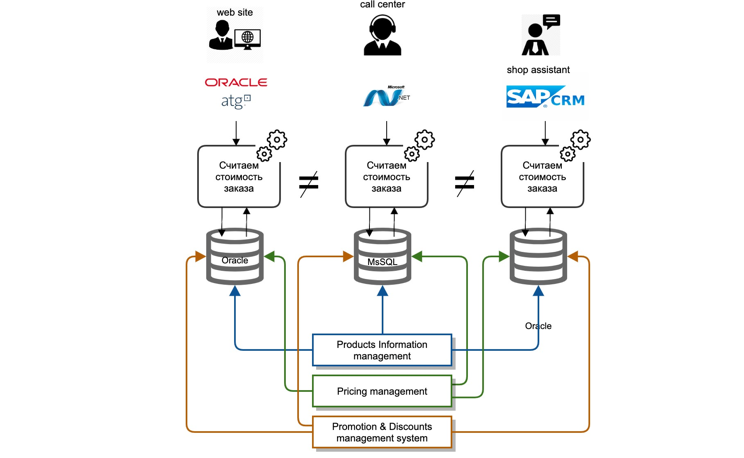
Nos enfrentamos a una amplia gama de desafíos. Nuestros datos maestros estaban profundamente arraigados en los sistemas del back office. Cada sistema de TI es un monolito clásico: base de datos, servidor de aplicaciones. La integración de los sistemas maestros con otros participantes en el panorama de TI se llevó a cabo como un "punto a punto", es decir, cada sistema de TI se integró a sí mismo, a su manera y cada vez de nuevo.
Las integraciones fueron principalmente de dos tipos: replicación a nivel de base de datos, transferencia de archivos. La lógica de cálculo se repitió en cada sistema de TI por separado, es decir, en diferentes lenguajes de desarrollo, no hay forma de reutilizar ni siquiera el código de un equipo vecino.
Era extremadamente costoso y casi imposible sincronizar la lógica de cálculo simultáneamente en todos los sistemas, debido a las diferentes hojas de ruta y los costos de recursos de varios sistemas de TI.
Además, cuando nos ocupamos de las quejas de los clientes, fue extremadamente difícil para nosotros determinar por qué no se proporcionó el precio correcto o uno u otro descuento.
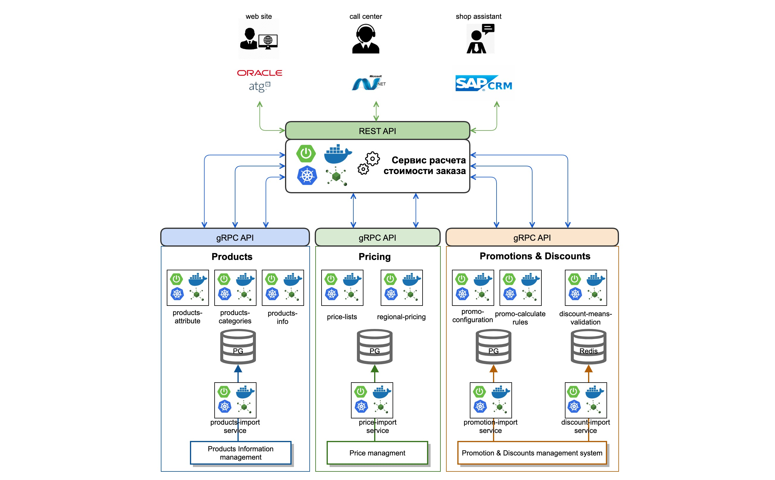
¿Qué hemos hecho? Analizamos y determinamos el contexto necesario para el correcto cálculo del valor del pedido. A continuación, seleccionamos dominios comerciales y los dividimos internamente en microservicios separados. Entonces, por ejemplo, destacamos datos sobre bienes que debían tenerse en cuenta en el proceso de cálculo del costo de un pedido.
Hemos implementado un servicio de importación de datos de sistemas maestros en línea mediante colas (Kafka). Además de los datos, hemos implementado microservicios atómicos que operan con categorías de productos y sus atributos (productos-atributo-servicio, productos-categorías-servicio). Hicimos lo mismo con los dominios en el contexto de Precio y Promoción.
Por separado, trasladamos la lógica y el procedimiento para calcular los precios de los pedidos a un motor de cálculo de pedidos separado, implementando una única lógica unificada para calcular los precios y los costos, utilizando fondos de descuento y tarjetas promocionales.
También hemos implementado una API REST estandarizada para todos los clientes que implementan la lógica de liquidación de pedidos. Para la comunicación entre servicios, elegimos el protocolo gRPC con una descripción en protobuf3.
Como resultado, un microservicio estándar hoy se parece a esto: es una aplicación de arranque de primavera, que se recopila en un contenedor docker usando GitLab CI y se implementa en el clúster de Kubernetes.
¿Cuál es el resultado final?
En el camino de nuestra evolución técnica, en primer lugar, hemos revisado el enfoque del proceso de desarrollo de los propios servicios y formación de equipos. Nos enfocamos en un enfoque de producto, reclutamos equipos basados en los máximos principios de autonomía.
Al mismo tiempo, para que los equipos correspondan a dominios y áreas de negocio específicas y, en consecuencia, puedan, junto con los responsables de las funciones de negocio, participar en el desarrollo de un área de negocio determinada.
En términos de desarrollo técnico, elegimos la conectividad asíncrona utilizando Kafka, incluidos los flujos de Kafka, como una de las herramientas de comunicación entre servicios. Esto permitió que los equipos se volvieran prácticamente independientes de los demás. También utilizamos y practicamos activamente prácticas de desarrollo reactivo, por ejemplo, el proyecto del reactor. Todavía queremos probar el proyecto Loom.
Para acelerar el desarrollo, nos enfocamos en el desarrollo de varios factores técnicos y organizacionales que nos permitieron influir significativamente en la sincronización.
El aspecto tecnológico es la transición a tecnologías en la nube, que aseguró la velocidad óptima de automatización de los procesos CI \ CD. La velocidad y la duración de la regresión completa y la implementación de un microservicio en particular son críticas aquí.
Por ejemplo, hoy en día, una ejecución completa (con todo tipo de pruebas unitarias, contractuales, de integración) CI \ CD Pipeline para una aplicación empresarial productiva en funcionamiento (y esto es aproximadamente 12-15 microservicios interconectados) es de aproximadamente 31 minutos, que es 7-8 minutos menos que los indicadores de principios de 2020.
Por lo tanto, pasamos entre un 17 y un 18% menos de tiempo esperando el resultado. Este ahorro nos permite abordar otras tareas de la compra. Esto se debe en gran parte al hecho de que utilizamos contenedores compactos basados en Alpine Linux, que son cada hora más rápidos y ligeros.
Nos hemos vuelto más eficientes en términos de desarrollo de microservicios en general. Y esto tiene un efecto positivo en la experiencia de usuario de nuestros clientes. La velocidad es una de las métricas clave de nuestros productos en línea (sitio web y aplicaciones móviles) ahora, y Liberica JDK también nos permite lograr esta ganancia, que en términos de rendimiento convertimos en una experiencia positiva para nuestros clientes.
Además, el enfoque correcto para el desarrollo de microservicios nos permitió acelerar significativamente el tiempo para lanzar nuestro producto al mercado. Aprendimos cómo llevar servicios individuales a la producción, utilizando varias estrategias para la implementación A \ B, enlatadora y otras según sea necesario. Esto permite recibir rápidamente comentarios sobre el trabajo de los microservicios.
En dos meses desarrollamos e implementamos un par de nuevos servicios en la experiencia de compra. Estamos hablando de la llamada entrega rápida de mercancías en 2 horas (utilizamos varios agregadores de taxis y entregas) y la emisión de nuestros pedidos en los lugares más inesperados (en las tiendas Pyaterochka o en las oficinas de correos rusas, incluso en estacionamientos de grandes dimensiones). centros de negocios).
Gracias a nuestros microservicios, algunos de los clientes del Grupo M.Video-Eldorado tienen la oportunidad de tomar un taxi con sus mercancías directamente a casa desde la tienda.
Planes creativos
Nuestros planes para 2021 incluyen el desarrollo activo de la infraestructura en la nube y la transición por completo al concepto de Infraestructura como código ("Infraestructura como código").
Planeamos prestar mucha atención a la construcción de soluciones transparentes para el control y la interacción de microservicios en forma de una solución Service Mesh basada en Istio y Admiral. Tenemos mucho trabajo por delante para ajustar y mejorar toda la pila de Observabilidad, supervisar el seguimiento de solicitudes y el registro de mensajes.
También planeamos probar el uso de tecnologías sin servidor, incluido el deseo de probarlo en Java. Además, existe una idea hasta ahora distante, pero no aparentemente irreal, de construir una infraestructura y un ecosistema de múltiples nubes.
Si está interesado en tocar con las manos nuestra pila de tecnología, no lo dude, hay suficiente trabajo para todos. El registro de voluntarios se realiza 24 horas al día, 7 días a la semana: aquí . De nada .
Beneficios, trucos para la vida, experiencia personal.

Dmitry Chuiko , arquitecto senior de rendimiento de BellSoft , habla sobre los secretos de los pequeños contenedores Docker para microservicios Java:
─ . , . Docker-. , : , .
Linux , . JDK. , , .
1.
CentOS CentOS slim. ? Debian. Alpine musl. BellSoft Alpine Linux, — Linux. Liberica JDK 11.0.10 + 11.0.10 Linux.
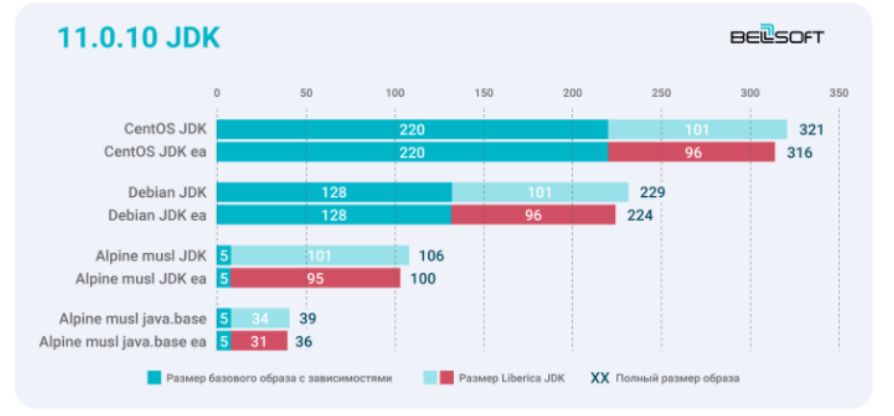
Liberica EA 3–6 14,7 % Alpine musl java.base. 7,6 %. Docker-, JRE java.base. Liberica JRE EA — 16 %.
Liberica Lite . , , — . - Java SE JVM, Standart, JIT- (C1, C2, Graal JIT Compiler), (Serial, Parallel, CMS, G1, Shenandoah, ZGC) serviceability, .
2. JDK
— jdeps JLINK. . Java (JDeps). - Java, . . JAR, , . JDeps JDK, Java-. , , .

jdeps , java.base. jlink. , BellSoft Docker- java.base. DockerHub, .
docker run –rm bellsoft/liberica – openjdk -demos- asciiduke.
CLI-like java.base. Liberica JDK Lite Alpine Linux musl 40,4 .
.
Enjoy!