Hola a todos. Estamos entrando en la recta final: hoy es el artículo final sobre lo que la ciencia de datos puede proporcionar para predecir COVID-19.
El primer artículo está aquí . El segundo está aquí .
Hoy hablamos con Alexander Zhelubenkov sobre sus decisiones para predecir la propagación del COVID-19.
Nuestras condiciones son las siguientes:
Dadas : Colosales capacidades de ciencia de datos, tres talentosos especialistas.
Buscar : formas de predecir la propagación de COVID-19 con una semana de anticipación.
Y aquí está la decisión de Alexander Zhelubenkov.
- Alexander, hola. Primero, cuéntenos un poco sobre usted y su trabajo.
- Trabajo en Lamoda como responsable del grupo de análisis de datos y aprendizaje automático. Estamos comprometidos con un motor de búsqueda y algoritmos para clasificar los productos en el catálogo. La ciencia de datos me interesó cuando estudiaba en la Universidad Estatal de Moscú en la Facultad de Matemática Computacional y Cibernética.
- El conocimiento y las habilidades fueron útiles. Hiciste un modelo de calidad: lo suficientemente simple como para no ser sobreajustado. ¿Cómo se las arregló para lograrlo?
- El problema de la predicción de series de tiempo está bien estudiado y es comprensible qué enfoques se le pueden aplicar. En nuestra tarea, las muestras son bastante pequeñas según los estándares del aprendizaje automático: varios miles de observaciones en los datos de entrenamiento y solo se deben realizar 560 predicciones para cada semana (pronóstico para 80 regiones para cada día de la próxima semana). En tales casos, se utilizan modelos más generales que funcionan bien en la práctica. De hecho, terminé con una línea de base ordenada.
Como modelo, utilicé el aumento de gradiente en árboles. Puede notar que los modelos de madera listos para usar no saben cómo predecir tendencias, pero si cambiamos a objetivos incrementales, será posible predecir la tendencia. Resulta que debe enseñarle al modelo a predecir cuánto aumentará el número de casos en relación con el día actual durante los próximos X días, donde X de 1 a 7 es el horizonte de pronóstico.
Otra característica fue que la calidad de las predicciones del modelo se evaluó en una escala logarítmica, es decir, la penalización no fue por cuánto te equivocaste, sino por cuántas veces las predicciones del modelo resultaron ser inexactas. Y esto tuvo el siguiente efecto: la calidad final de los pronósticos para todas las regiones estuvo muy influenciada por la precisión de los pronósticos en regiones pequeñas.
Se conocían los cronogramas de cada región: el número de casos en cada uno de los días pasados y, literalmente, algunas características cualitativas, como la población y la proporción de residentes urbanos. Básicamente, eso es todo. Es difícil volver a entrenar tales datos si es normal hacer la validación y determinar dónde vale la pena detenerse en el entrenamiento de refuerzo.
- ¿Qué biblioteca de aumento de gradiente usaste?
- Estoy a la antigua - XGBoost. Sé sobre LightGBM y CatBoost, pero para tal tarea, me parece que la elección no es tan importante.
- Okey. Pero sigue siendo el objetivo. ¿Qué tomaste por el objetivo? ¿Es este el logaritmo de la relación de dos días o el logaritmo del valor absoluto?
- Como objetivo, tomé la diferencia en los logaritmos del número de casos. Por ejemplo, si hoy hay 100 casos y mañana hay 200, entonces, al pronosticar un día por delante, debe aprender a predecir el logaritmo del doble crecimiento.
En general, se sabe que las primeras semanas hay un aumento exponencial de la propagación del virus. Esto significa que si usamos incrementos en una escala logarítmica como objetivos, entonces, de hecho, será posible predecir una constante multiplicada por el horizonte de pronóstico todos los días. El aumento de gradiente es un modelo versátil y se adapta bien a este tipo de tareas.
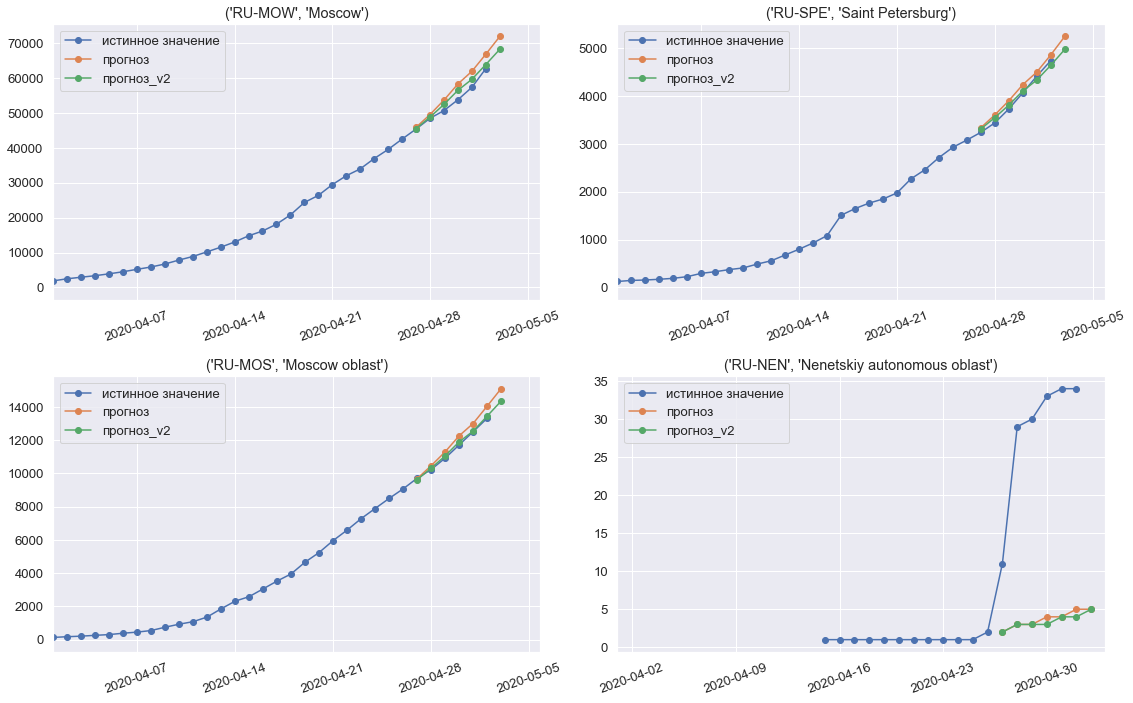
Modelo de predicciones para la tercera y última semana de la competencia
: ¿Qué muestra de entrenamiento tomó?
- Para predecir regiones, tomé información sobre la distribución por país. Parece que esto ayudó, ya que en algún lugar ya se estaba desacelerando el fuerte crecimiento y los países comenzaron a entrar en la meseta. En las regiones de Rusia, corté el período inicial, cuando hubo algunos casos aislados. Para el entrenamiento, utilicé datos de febrero.
- ¿Cómo estás validado?
- Validado en el tiempo, al igual que para series temporales y es habitual hacerlo. Usé las últimas dos semanas para la prueba. Si predecimos la última semana, para el entrenamiento usamos todos los datos anteriores. Si predecimos el penúltimo, usamos todos los datos, sin las últimas dos semanas.
- ¿Usaste algo más? Algunos días, día 10 o 20, ¿a partir de ahí?
- Los principales factores que resultaron importantes fueron diferentes estadísticas: promedios, mediana, incrementos en los últimos N días. Para cada región, se puede calcular por separado. También puede sumar los mismos factores por separado, solo calculados para todas las regiones a la vez.
- Pregunta sobre validación. ¿Buscas más estabilidad o precisión? ¿Cuál fue el criterio?
- Observé la calidad media del modelo, que se obtuvo en las últimas dos semanas seleccionado para validación. Al agregar algunos factores, obtuvimos una imagen tal que con una configuración de impulso fija y variando solo el parámetro de semilla aleatoria, la calidad de las predicciones podría saltar mucho, es decir, se obtuvo una gran variación. Para no volver a entrenarme y conseguir un modelo más estable, al final no utilicé factores tan dudosos en el modelo final.
- ¿Que recuerdas? ¿Sorprendido? ¿Una característica que funcionó o algún tipo de truco de impulso?
- Aprendí dos lecciones. Primero, cuando decidí fusionar dos modelos: lineal y de impulso, y al mismo tiempo, para cada región, los coeficientes con los que se tomaron estos dos modelos (resultaron ser diferentes) simplemente se configuraron en la última semana - es decir, durante siete días. De hecho, configuré 1-2 coeficientes para cada región durante 7 días. Pero el descubrimiento fue el siguiente: el pronóstico resultó ser mucho peor en comparación con si no hubiera realizado estos ajustes. En algunas regiones, el modelo se volvió a capacitar mucho y, como resultado, las previsiones en ellas resultaron ser malas. En la tercera etapa de la competencia, decidí no hacer esto.
Y el segundo punto: parece que el número de días desde el inicio debería servir como característica: desde el primer enfermo, desde el décimo enfermo. Traté de agregarlos, pero en la validación empeoró la situación. Lo expliqué de esta manera: la distribución de valores en muestras cambia con el tiempo. Si estudia el día 20 desde el comienzo de la propagación del virus, al predecir la distribución de los valores de esta característica se adelantará siete días y, tal vez, esto no permita que tales factores se utilicen con beneficio.
- Dijiste que la proporción de la población urbana juega algún papel. ¿Y qué más?
- Sí, siempre se ha utilizado la proporción de la población urbana de ambos países y regiones de Rusia. Este factor siempre dio un pequeño impulso a la calidad de los pronósticos. Como resultado, aparte de la serie temporal en sí, no incluí nada más en el modelo final. Intenté agregar varios pero no funcionó.
- ¿Cuál es tu opinión: SARIMA es el siglo pasado?
- Los modelos de autorregresión - media móvil - son más difíciles de configurar, y es más caro agregarles factores adicionales, aunque estoy seguro que con los modelos (S) ARIMA (X) sería posible hacer buenas predicciones, pero no tan bueno en comparación con el impulso.
- Y durante un período superior a una semana, puedes hacer predicciones, ¿qué te parece?
- Sería interesante. Inicialmente, los organizadores tuvieron la idea de recopilar pronósticos a largo plazo. El mes parece un punto de inflexión en el que todavía puedes probar los enfoques que hice.
- ¿Que crees que pasará después?
- Necesitamos reconstruir el modelo, mira. Por cierto, mi solución se puede encontrar aquí:
github.com/Topspin26/sberbank-covid19-challenge Para conocer las
últimas noticias sobre ciencia de datos de COVID de la comunidad internacional, visite https://www.kaggle.com/tags/covid19 . Y por supuesto te invitamos al canal #coronavirus en opendatascience.slack.com (invitado por ods.ai ).