¿Qué pasa con TargetEncoder de la biblioteca category_encoders?
Este artículo es una continuación del artículo anterior , que explicó cómo funciona realmente la codificación probabilística objetiva. En este artículo, veremos en qué casos la solución estándar de la biblioteca category_encoders da un resultado incorrecto y, además, estudiaremos la teoría y el ejemplo de código para una correcta codificación objetivo-probabilística multiclase. ¡Vamos!
1. ¿Cuándo está mal TargetEncoder?
Eche un vistazo a estos datos. El color es una característica y una meta es ... una meta. Nuestro objetivo es codificar el color en función del objetivo.

Hagamos la codificación objetivo-probabilística habitual para esto.
import category_encoders as ce
ce.TargetEncoder(smoothing=0).fit_transform(df.Color,df.Target)
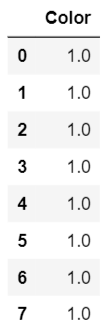
Hmm ... no se ve bien, ¿verdad? Todos los colores se han cambiado a 1. ¿Por qué? Esto se debe a que TargetEncoder toma el promedio de todos los valores objetivo para cada color, no la probabilidad.
Si bien TargetEncoder funciona correctamente cuando tiene un destino binario con 0 y 1, fallará en dos casos:
Cuando el destino es binario, pero no 0/1 (al menos, por ejemplo, 1 y 2).
Cuando el objetivo es una multiclase como en el ejemplo anterior.
Entonces lo que hay que hacer ?!
Teoría
, n . , . n , . n-1 , , . - , , .
.
.
1: - .
enc=ce.OneHotEncoder().fit(df.Target.astype(str)) y_onehot=enc.transform(df.Target.astype(str)) y_onehot
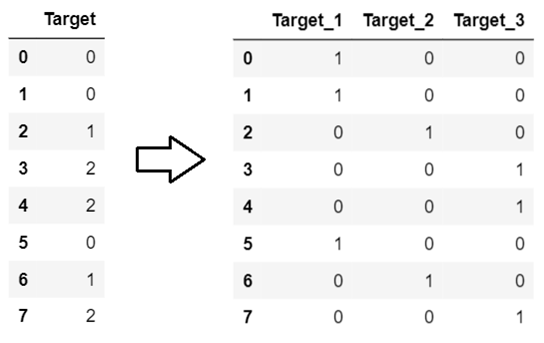
, Target_1 0 Target. 1 Target 0, 0 . Target_2 1 Target.
2: , .
class_names = y_onehot.columns
for class_ in class_names:
enc = ce.TargetEncoder(smoothing = 0)
print(enc.fit_transform(X,y_onehot[class_]))
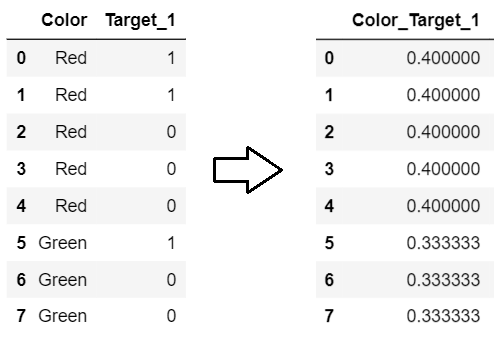
0
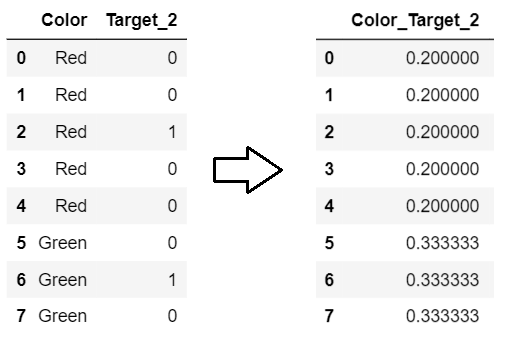
1

2
3: , , 1 2 .
!
, :

, Color_Target. , , . , , , Color_Target_3 ( - ) .
, ?!
A continuación se muestra una función que toma como entrada una tabla de datos y un objeto de etiqueta de destino de tipo Serie. La función df puede tener variables tanto numéricas como categóricas.
def target_encode_multiclass(X,y): #X,y are pandas df and series
y=y.astype(str) #convert to string to onehot encode
enc=ce.OneHotEncoder().fit(y)
y_onehot=enc.transform(y)
class_names=y_onehot.columns #names of onehot encoded columns
X_obj=X.select_dtypes('object') #separate categorical columns
X=X.select_dtypes(exclude='object')
for class_ in class_names:
enc=ce.TargetEncoder()
enc.fit(X_obj,y_onehot[class_]) #convert all categorical
temp=enc.transform(X_obj) #columns for class_
temp.columns=[str(x)+'_'+str(class_) for x in temp.columns]
X=pd.concat([X,temp],axis=1) #add to original dataset
return X
Resumen
En este artículo, mostré lo que está mal con TargetEncoder de la biblioteca category_encoder, expliqué lo que dice el artículo original sobre la orientación de variables de varias clases, lo demostré todo con un ejemplo y proporcioné un código modular funcional que puede conectar a su solicitud.