El artículo está dirigido a principiantes como yo.
Comienzo
Primero, echemos un vistazo al problema. Tomé un sitio de noticias poco conocido sobre Israel, ya que yo mismo vivo en este país y quiero leer noticias sin publicidad y sin noticias interesantes. Y así, hay un sitio donde se publican noticias: hay noticias marcadas en rojo y hay noticias ordinarias. Los que son ordinarios no son nada interesantes, y los marcados en rojo son el jugo mismo. Considere nuestro sitio.
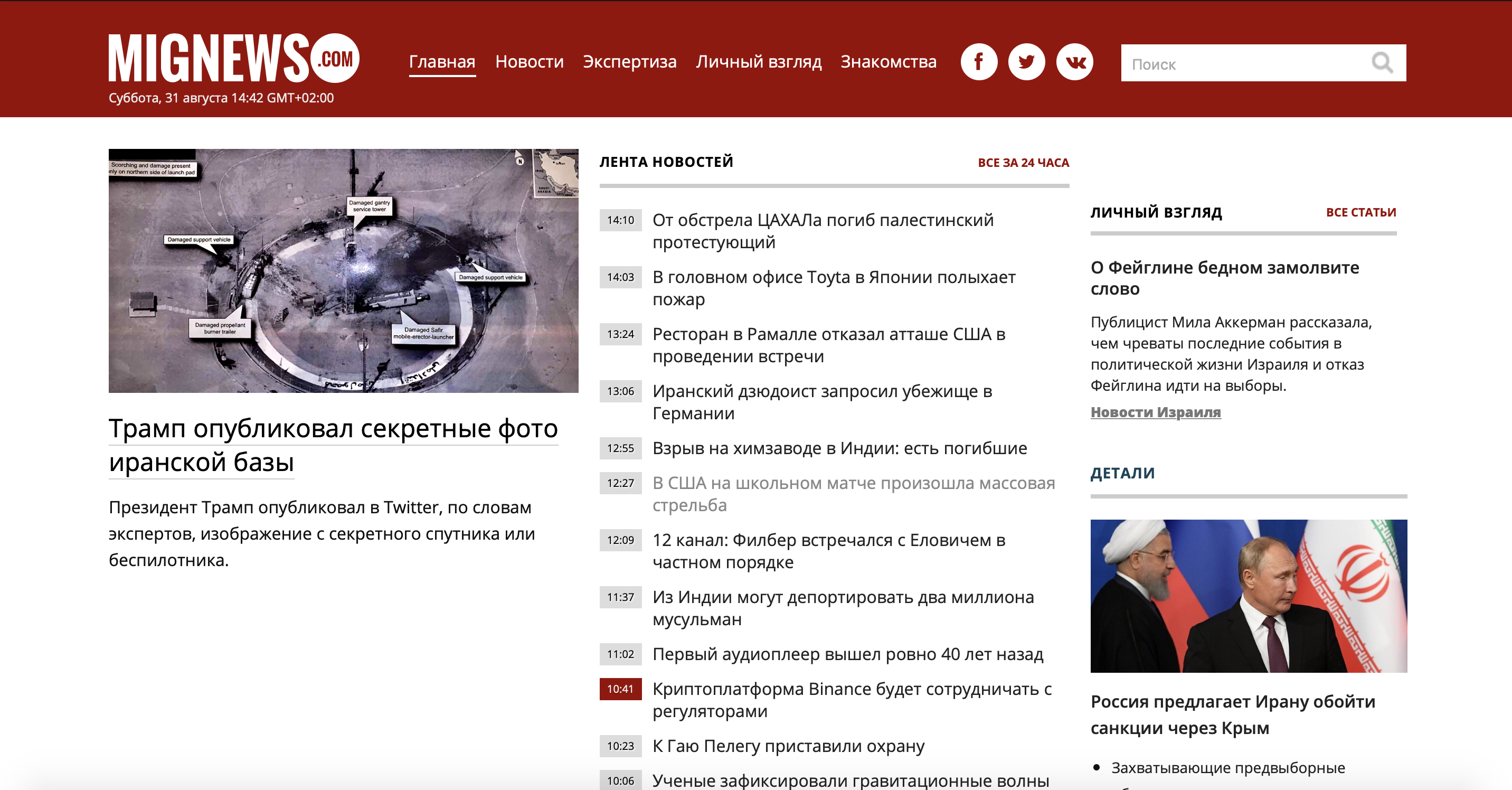
Como puede ver, el sitio es lo suficientemente grande y hay mucha información innecesaria, pero solo necesitamos usar el contenedor de noticias. Usemos la versión móvil del sitio
para ahorrarnos el mismo tiempo y esfuerzo.

Como puede ver, el servidor nos brindó un hermoso contenedor de noticias (que, por cierto, es más que en el sitio principal, que está a nuestro favor) sin anuncios ni basura.
Echemos un vistazo al código fuente para entender a qué nos enfrentamos.

Como puede ver, cada noticia se encuentra por separado en la etiqueta 'a' y tiene la clase 'lenta'. Si abrimos la etiqueta 'a', notaremos que dentro hay una etiqueta 'span', que contiene la clase 'time2' o 'time2 time3', así como la hora de publicación, y luego de cerrar la etiqueta, vemos el texto de la noticia en sí.
¿Qué separa las noticias importantes de las no importantes? La misma clase 'time2' o 'time2 time3'. Las noticias marcadas como 'time2 time3' son nuestras noticias rojas. Dado que la esencia de la tarea es clara, pasemos a la práctica.
Práctica
Para trabajar con analizadores, las personas inteligentes crearon la biblioteca "BeautifulSoup4", que tiene muchas más funciones interesantes y útiles, pero más sobre eso la próxima vez. También necesitamos la biblioteca de solicitudes que nos permite enviar varias solicitudes http. Vamos a descargarlos.
(asegúrese de tener la última versión de pip)
pip install beautifulsoup4
pip install requests
Vaya al editor de código e importe nuestras bibliotecas:
from bs4 import BeautifulSoup
import requests
Primero, guardemos nuestra URL en una variable:
url = 'http://mignews.com/mobile'
Ahora enviemos una solicitud GET () al sitio y guardemos los datos recibidos en la variable 'página':
page = requests.get(url)
Comprobemos la conexión:
print(page.status_code)
El código nos devolvió el código de estado '200', lo que significa que estamos conectados correctamente y todo está en orden.
Ahora creemos dos listas (explicaré para qué sirven más adelante):
new_news = [] news = []
Es hora de usar BeautifulSoup4 y alimentarla con nuestra página, indicando entre comillas cómo nos ayudará 'html.parcer':
soup = BeautifulSoup(page.text, "html.parser")
Si le pide que muestre lo que guardó allí:
print(soup)
Sacaremos todo el código html de nuestra página.
Ahora usemos la función de búsqueda en BeautifulSoup4:
news = soup.findAll('a', class_='lenta')
Echemos un vistazo más de cerca a lo que hemos escrito aquí.
En la lista de 'noticias' creada anteriormente (a la que prometí regresar), guarde todo con la etiqueta 'a' y la clase 'noticias'. Si pedimos enviar a la consola todo lo que encontró, nos mostrará todas las noticias que estaban en la página:

Como puede ver, junto con el texto de la noticia, las etiquetas 'a', 'span', las clases ' lenta 'y' time2 ', y también' time2 time3 ', en general, todo lo que encontró según nuestros deseos.
Continuemos:
for i in range(len(news)):
if news[i].find('span', class_='time2 time3') is not None:
new_news.append(news[i].text)
Aquí, en un bucle for, iteramos sobre toda nuestra lista de noticias. Si en las noticias bajo el índice [i] encontramos la etiqueta 'span' y la clase 'time2 time3', entonces guardamos el texto de esta noticia en la nueva lista 'new_news'.
Tenga en cuenta que estamos usando '.text' para reformatear las líneas en nuestra lista del 'bs4.element.ResultSet' que BeautifulSoup usa para sus búsquedas en texto sin formato.
Una vez que me quedé atascado en este problema durante mucho tiempo debido a un malentendido sobre cómo funcionan los formatos de datos y a no saber cómo usar la depuración, tenga cuidado. Así, ahora podemos guardar estos datos en una nueva lista y usar todos los métodos de las listas, porque ahora este es texto ordinario y, en general, hacemos con él lo que queramos.
Visualicemos nuestros datos:
for i in range(len(new_news)):
print(new_news[i])

Esto es lo que obtenemos: recibimos la hora de publicación y solo noticias interesantes.
Luego, puede crear un bot en el carrito y cargar estas noticias allí, o crear un widget en su escritorio con noticias actuales. En general, puede encontrar una forma conveniente de conocer las noticias.
Con suerte, este artículo ayudará a los principiantes a comprender lo que se puede hacer con los analizadores sintácticos y les ayudará a avanzar un poco en su aprendizaje.
Gracias por su atención, me alegró compartir mi experiencia.