Sin embargo, escribir programas completamente en lenguaje ensamblador no solo es largo, aburrido y difícil, sino también algo tonto, porque se inventaron abstracciones de alto nivel para este propósito, para reducir el tiempo de desarrollo y simplificar el proceso de programación. Por lo tanto, la mayoría de las veces, las funciones bien optimizadas tomadas por separado se escriben en lenguaje ensamblador, que luego se llaman desde lenguajes de nivel superior como C ++ y C #.
En base a esto, el entorno de programación más conveniente será Visual Studio, que ya incluye MASM. Puede conectarlo a un proyecto C / C ++ a través del menú contextual del proyecto Build Dependencies - Build Customizations ..., marcando la casilla junto a masm, y los propios programas ensambladores se ubicarán en archivos con .asm extensión (en cuyas propiedades el Tipo de elemento debe establecerse en Microsoft Macro Assembler). Esto permitirá no solo compilar y llamar a programas en lenguaje ensamblador sin gestos innecesarios, sino también realizar una depuración de un extremo a otro, "caer" en la fuente del ensamblador directamente desde c ++ o c # (incluido el punto de interrupción dentro de la lista del ensamblaje) , así como el seguimiento del estado de los registros junto con las variables habituales en la ventana Inspección.
Resaltado de sintaxis
Visual Studio no tiene resaltado de sintaxis incorporado para ensamblador y otros logros de la estructura IDE moderna; pero se puede proporcionar con extensiones de terceros.
AsmHighlighter es históricamente el primero con una funcionalidad mínima y un conjunto de comandos incompleto; no solo falta AVX, sino también algunos de los estándar, en particular fsqrt. Este hecho me impulsó a escribir mi propia extensión:
Editor avanzado de ASM . Además de resaltar y contraer secciones de código (usando comentarios "; [", "; [+" y ";]"), enlaza sugerencias a registros que aparecen al pasar el cursor por el código (también a través de comentarios). Se parece a esto:
;rdx=
o así:
mov rcx, 8;=
Las sugerencias para los comandos también están presentes, pero más bien en forma experimental: resultó que tomará más tiempo completarlas que escribir la extensión en sí.
También resultó de repente que los botones habituales para anotar / comentar la sección resaltada del código dejaron de funcionar. Por lo tanto, tuve que escribir otra extensión en la que esta funcionalidad se colgara en el mismo botón, y la necesidad de esta o aquella acción se selecciona automáticamente.
Tío asm- apareció un poco más tarde. En él, el autor tomó el camino inverso y centró sus esfuerzos en la referencia de comando incorporada y el autocompletado, incluidas las etiquetas de seguimiento. El plegado de código también está presente allí (por "#region / #end region"), pero parece que todavía no hay ningún enlace de comentarios a los registros.
32 vs. 64
Desde que apareció la plataforma de 64 bits, se ha convertido en la norma escribir 2 versiones de aplicaciones. ¡Es hora de dejar esto! ¿Cuánto legado puedes extraer? Lo mismo se aplica a las extensiones: solo puede encontrar un procesador sin SSE2 en un museo; además, sin SSE2, las aplicaciones de 64 bits no funcionarán. No habrá placer en la programación si escribe 4 variantes de funciones optimizadas para cada plataforma.
La ventaja de la plataforma de 64 bits no está en absoluto en los registros "amplios", sino en el hecho de que el número de estos registros se ha duplicado: 16 piezas cada uno, tanto de uso general como XMM / YMM. Esto no solo simplifica la programación, sino que también reduce significativamente los accesos a la memoria.
FPU
Si antes no había ningún lugar sin FPU, tk. las funciones con números reales dejaron el resultado en la parte superior de la pila, luego, en una plataforma de 64 bits, el intercambio se realiza sin su participación utilizando los registros xmm de la extensión SSE2. Intel también recomienda activamente deshacerse de las FPU a favor de SSE2 en sus pautas. Sin embargo, hay una advertencia: FPU le permite realizar cálculos con precisión de 80 bits, lo que en algunos casos puede ser crítico. Por lo tanto, el soporte de FPU no ha ido a ninguna parte y definitivamente no vale la pena considerarlo como una tecnología obsoleta. Por ejemplo, el cálculo de la hipotenusa se puede hacer "de frente" sin temor a desbordarse,
a saber
fld x fmul st(0), st(0) fld y fmul st(0), st(0) faddp st(1), st(0) fsqrt fstp hypot
La principal dificultad en la programación de FPU es su organización de pila. Para simplificar, se escribió una pequeña utilidad que genera automáticamente comentarios con el estado actual de la pila (se planeó agregar una funcionalidad similar directamente a la extensión principal para resaltar la sintaxis, pero nunca llegamos a eso)
Ejemplo de optimización: transformación de Hartley
Los compiladores modernos de C ++ son lo suficientemente inteligentes como para vectorizar automáticamente el código para tareas simples como sumar números en una matriz o rotar vectores, reconociendo los patrones correspondientes en el código. Por lo tanto, obtener una ganancia de rendimiento significativa en tareas primitivas no es algo que no funcione; por el contrario, puede resultar que su programa súper optimizado se ejecute más lento de lo que generó el compilador. Pero tampoco debe sacar conclusiones de gran alcance de esto: tan pronto como los algoritmos se vuelven un poco más complicados y no son obvios para la optimización, toda la magia de optimizar los compiladores desaparece. Todavía es posible multiplicar por diez el rendimiento mediante la optimización manual en 2021.
Entonces, como tarea, tomamos el algoritmo (lento) Hartley se transforma :
el código
static void ht_csharp(double[] data, double[] result)
{
int n = data.Length;
double phi = 2.0 * Math.PI / n;
for (int i = 0; i < n; ++i)
{
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
double w = phi * i * j;
sum += data[j] * (Math.Cos(w) + Math.Sin(w));
}
result[i] = sum / Math.Sqrt(n);
}
}
También es bastante trivial para la vectorización automática (veremos más adelante), pero da un poco más de espacio para la optimización. Bueno, nuestra versión optimizada se verá así:
código (comentarios eliminados)
ht_asm PROC local sqrtn:REAL10 local _2pin:REAL10 local k:DWORD local n:DWORD and r8, 0ffffffffh mov n, r8d mov r11, rcx xor rcx, rcx mov r9, r8 dec r9 shr r9, 1 mov r10, r8 sub r10, 2 shl r10, 3 finit fld _2pi fild n fdivp st(1), st fstp _2pin fld1 fild n fsqrt fdivp st(1), st ; mov rax, r11 mov rcx, r8 fldz @loop0: fadd QWORD PTR [rax] add rax, 8 loop @loop0 fmul st, st(1) fstp QWORD PTR [rdx] fstp sqrtn add rdx, 8 mov k, 1 @loop1: mov rax, r11 fld QWORD PTR [rax] fld st(0) add rax, 8 fld _2pin fild k fmulp st(1),st fsincos fld1;=u fldz;=v mov rcx, r8 dec rcx @loop2: fld st(1) fmul st(0),st(4) fld st(1) fmul st,st(4) faddp st(1),st fxch st(1) fmul st, st(4) fxch st(2) fmul st,st(3) fsubrp st(2),st fld st(0) fadd st, st(2) fmul QWORD PTR [rax] faddp st(5), st fld st(0) fsubr st, st(2) fmul QWORD PTR [rax] faddp st(6), st add rax, 8 loop @loop2 fcompp fcompp fld sqrtn fmul st(1), st fxch st(1) fstp QWORD PTR [rdx] fmulp st(1), st fstp QWORD PTR [rdx+r10] add rdx,8 sub r10, 16 inc k dec r9 jnz @loop1 test r10, r10 jnz @exit mov rax, r11 fldz mov rcx, r8 shr rcx, 1 @loop3:;[ fadd QWORD PTR [rax] fsub QWORD PTR [rax+8] add rax, 16 loop @loop3;] fld sqrtn fmulp st(1), st fstp QWORD PTR [rdx] @exit: ret ht_asm ENDP
Tenga en cuenta: no hay desenrollado de bucle, ni SSE / AVX, ni tablas de coseno, ni reducción de complejidad debido al algoritmo de transformación "rápida". La única optimización explícita es el cálculo iterativo seno / coseno en el bucle interno del algoritmo directamente en los registros FPU.
Dado que estamos hablando de una transformación integral, además de la velocidad, también nos interesa la precisión del cálculo y el nivel de errores acumulados. En este caso, es muy sencillo calcularlo: haciendo dos transformaciones seguidas, deberíamos obtener (en teoría) los datos iniciales. En la práctica serán ligeramente diferentes y será posible calcular el error mediante la desviación estándar del resultado obtenido del analítico.
Los resultados de la optimización automática de un programa en C ++ también pueden depender en gran medida de la configuración de los parámetros del compilador y de la elección de un conjunto de instrucciones extendido válido (SSE / AVX / etc.). Sin embargo, hay dos matices:
- Los compiladores modernos tienden a calcular todo lo posible en la etapa de compilación; por lo tanto, es bastante posible en el código compilado, en lugar del algoritmo, ver un valor precalculado que, al medir el rendimiento, le dará al compilador una ventaja de 100500. veces. Para evitar esto, mis mediciones usan la función externa cero (), que agrega ambigüedad a los parámetros de entrada.
- « AVX» — , AVX. . – , AVX .
El parámetro de optimización más interesante es el modelo de punto flotante, que toma valores precisos | estrictos | rápidos. En el caso de Fast, el compilador puede realizar cualquier transformación matemática a su discreción (incluidos los cálculos iterativos); de hecho, solo en este modo tiene lugar la vectorización automática.
Entonces, compilador de Visual Studio 2019, marco de destino AVX2, modelo de punto flotante = preciso. Para hacerlo aún más interesante, medirá desde un proyecto de c # en una matriz de 10,000 elementos:
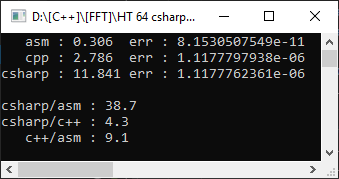
C #, como se esperaba, resultó ser más lento que C ++, ¡y la función de ensamblador resultó ser 9 veces más rápida! Sin embargo, es demasiado pronto para regocijarse, establezcamos Floating Point Model = Fast:

Como puede ver, esto ayudó a acelerar significativamente el código y el retraso de la optimización manual fue solo 1.8 veces. Pero lo que no ha cambiado es el error. Que la otra opción dio un error de 4 dígitos significativos, y esto es importante en los cálculos matemáticos.
En este caso, nuestra versión resultó ser más rápida y precisa. Pero este no es siempre el caso, y al elegir FPU para almacenar los resultados, inevitablemente perderemos la posibilidad de optimización por vectorización. Además, nadie prohíbe combinar FPU y SSE2 en los casos en que tenga sentido (en particular, utilicé este enfoque en la implementación de aritmética doble-doble , habiendo recibido una aceleración de 10 veces durante la multiplicación).
La optimización adicional de la transformada de Hartley se encuentra en un plano diferente y (para un tamaño arbitrario) requiere el algoritmo de Bluestein, que también es fundamental para la precisión de los cálculos intermedios. Bueno, este proyecto se puede descargar en GitHub y, como beneficio adicional, también hay un par de funciones para sumar / escalar arreglos para FPU / SSE2 / AVX (con fines educativos).
Que leer
Literatura sobre ensamblador a granel. Pero hay varias fuentes clave:
1. Documentación oficial de Intel . Nada superfluo, la probabilidad de errores tipográficos es mínima (que son omnipresentes en la literatura impresa).
2. Directorio en línea , extraído de la documentación oficial.
3. Sitio de Agner Fogh , un reconocido experto en optimización. También contiene ejemplos de código C ++ optimizado que utiliza intrínsecos.
4. SIMPLEMENTE FPU .
5.40 Prácticas básicas en programación en lenguaje ensamblador .
6. Todo lo que necesita saber para comenzar a programar para versiones de Windows de 64 bits .
Apéndice: ¿Por qué no usar intrínsecos?
Texto oculto
, , , - — , SIMD- . — .
:
:
- . DOS , – .
- . – .
- . , , (FPU). . , //etc.
- - – , , . , , .
- , C++ , - SIMD-. 32- XMM8 XMM0 / XMM7 – . — , , , . – , C++.
- , . , – Microsoft , C++.